Der Zweck der Testzeitanpassung besteht darin, das Quelldomänenmodell in der Inferenzphase an die Testdaten anzupassen, und hat hervorragende Ergebnisse bei der Anpassung an unbekannte Bildschadensfelder erzielt. Bei vielen aktuellen Methoden fehlt jedoch die Berücksichtigung des Testdatenflusses in realen Szenarien, zum Beispiel:
- Der Testdatenfluss sollte eine zeitlich variierende Verteilung sein (und nicht eine feste Verteilung bei der herkömmlichen Domänenanpassung).
- Der Testdatenstrom weist möglicherweise eine lokale Klassenkorrelation auf (anstelle einer vollständig unabhängigen und identisch verteilten Stichprobe)
- Der Testdatenstrom zeigt noch lange Zeit ein globales Klassenungleichgewicht
Vor Kurzem , South China University of Technology, Die Teams von A*STAR und CUHK-Shenzhen haben durch eine große Anzahl von Experimenten bewiesen, dass das Testen von Datenflüssen in diesen realen Szenarien große Herausforderungen für bestehende Methoden mit sich bringen wird. Das Team geht davon aus, dass das Scheitern moderner Methoden zunächst auf die wahllose Anpassung der Normalisierungsschicht auf der Grundlage unausgeglichener Testdaten zurückzuführen ist. Zu diesem Zweck schlug das Forschungsteam eine innovative Balanced BatchNorm-Schicht vor, um die herkömmliche Batch-Normalisierungsschicht in der Inferenzphase zu ersetzen. Gleichzeitig stellten sie fest, dass das ausschließliche Verlassen auf Selbsttraining (ST) zum Lernen in unbekannten Testdatenströmen leicht zu einer Überanpassung (Ungleichgewicht der Pseudo-Label-Kategorie, Zieldomäne ist keine feste Domäne) führen kann, was zu schlechten Ergebnissen führt Leistung in einem sich verändernden Bereich. Daher empfiehlt das Team, Modellaktualisierungen durch verankerten Verlust (Anchored Loss) zu regulieren, um dadurch das Selbsttraining unter kontinuierlicher Domänenübertragung zu verbessern und dazu beizutragen, die Robustheit des Modells deutlich zu verbessern. Am Ende erreichte das Modell TRIBE unter vier Datensätzen und mehreren realen Testdatenstromeinstellungen stabil die Leistung auf dem neuesten Stand und übertraf bestehende fortschrittliche Methoden deutlich. Forschungspapier wurde von AAAI 2024 angenommen. 
Papier-Link: https://arxiv.org/abs/2309.14949Code-Link: https://github.com/Gorilla-Lab-SCUT/TRIBETiefe Der Erfolg neuronaler Netze hängt von der Verallgemeinerung des trainierten Modells auf i.i.d.-Annahmen im Testbereich ab. In praktischen Anwendungen ist jedoch die Robustheit von Testdaten außerhalb der Verteilung, wie z. B. Sehschäden durch unterschiedliche Lichtverhältnisse oder Unwetter, besorgniserregend. Aktuelle Untersuchungen zeigen, dass dieser Datenverlust die Leistung vorab trainierter Modelle ernsthaft beeinträchtigen kann. Wichtig ist, dass die Beschädigung (Verteilung) von Testdaten vor der Bereitstellung oft unbekannt und manchmal unvorhersehbar ist.
Daher ist die Anpassung des vorab trainierten Modells zur Anpassung an die Testdatenverteilung in der Inferenzphase ein wertvolles neues Thema, nämlich die Testzeitdomänenanpassung (TTA). Bisher wurde TTA hauptsächlich durch Verteilungsausrichtung (TTAC++, TTT++), selbstüberwachtes Training (AdaContrast) und Selbsttraining (Conjugate PL) implementiert, was zu erheblichen und robusten Verbesserungen bei einer Vielzahl von Testdaten zu visuellen Schäden geführt hat.
Bestehende TTA-Methoden (Test-Time Domain Adaptation) basieren normalerweise auf einigen strengen Testdatenannahmen, wie z. B. einer stabilen Klassenverteilung, Stichproben, die unabhängigen und identisch verteilten Stichproben folgen, und einem festen Domänenversatz. Diese Annahmen haben viele Forscher dazu inspiriert, reale Testdatenflüsse wie CoTTA, NOTE, SAR und RoTTA zu untersuchen.
In jüngster Zeit konzentriert sich die reale TTA-Forschung wie SAR (ICLR 2023) und RoTTA (CVPR 2023) hauptsächlich auf die Herausforderungen, die sich aus dem lokalen Klassenungleichgewicht und der kontinuierlichen Domänenverschiebung zu TTA ergeben. Ein lokales Klassenungleichgewicht resultiert in der Regel aus der Tatsache, dass die Testdaten nicht unabhängig voneinander abgetastet und nicht identisch verteilt werden. Eine direkte wahllose Domänenanpassung führt zu verzerrten Verteilungsschätzungen.
Jüngste Forschungsergebnisse haben exponentiell aktualisierte Batch-normalisierte Statistiken (RoTTA) oder diskriminativ aktualisierte Batch-normalisierte Statistiken auf Instanzebene (NOTE) vorgeschlagen, um diese Herausforderung zu lösen. Das Forschungsziel besteht darin, die Herausforderung des lokalen Klassenungleichgewichts zu überwinden, da die Gesamtverteilung von Testdaten stark unausgewogen sein kann und sich die Klassenverteilung im Laufe der Zeit auch ändern kann. Ein Diagramm eines anspruchsvolleren Szenarios ist in Abbildung 1 unten zu sehen.
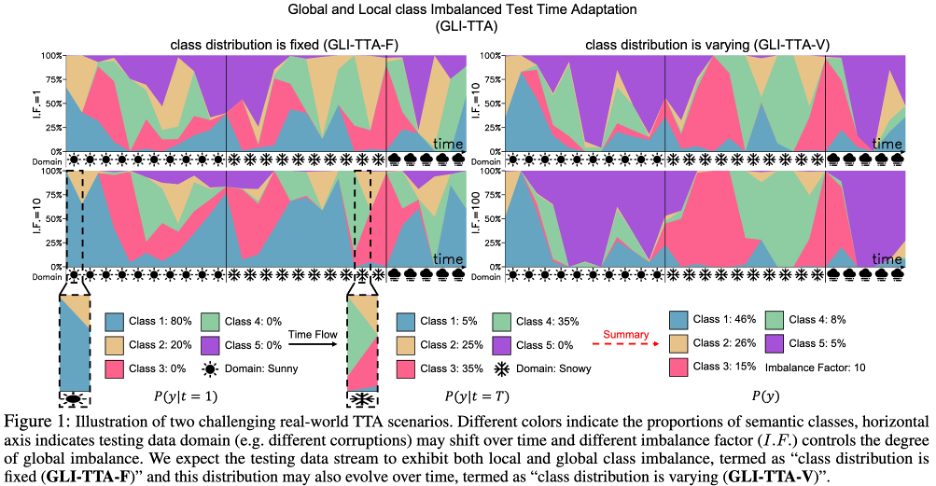
Da die Klassenprävalenz in den Testdaten vor der Inferenzphase unbekannt ist und das Modell durch blinde Testzeitanpassungen möglicherweise in Richtung der Mehrheitsklasse verzerrt ist, werden bestehende TTA-Methoden dadurch unwirksam. Basierend auf empirischen Beobachtungen wird dieses Problem besonders deutlich bei Methoden, die auf dem aktuellen Datenstapel basieren, um globale Statistiken zur Aktualisierung der Normalisierungsschicht zu schätzen (BN, PL, TENT, CoTTA usw.). Dies ist hauptsächlich auf Folgendes zurückzuführen: 1 Der aktuelle Datenstapel wird durch ein lokales Klassenungleichgewicht beeinflusst, was zu einer verzerrten Gesamtverteilungsschätzung führt 2. Geschätzt aus den gesamten Testdaten mit globalem Klassenungleichgewicht Ohne eine einzige globale Verteilung kann die globale Verteilung leicht auf die Mehrheitsklasse ausgerichtet sein, was zu internen Kovariatenverschiebungen führt. Um eine voreingenommene Batch-Normalisierung (BN) zu vermeiden, schlug das Team eine ausgeglichene Batch-Normalisierungsschicht (Balanced Batch Normalization Layer) vor, die die Verteilung jeder einzelnen Kategorie modelliert und die globale Verteilung aus der Klassenverteilung extrahiert. Die Balanced-Batch-Normalisierungsschicht ermöglicht das Erhalten klassenbalancierter Schätzungen der Verteilung unter lokal und global klassenunbalancierten Testdatenströmen. Bei realen Testdaten kommt es im Laufe der Zeit häufig zu Domänenverschiebungen, beispielsweise durch allmähliche Änderungen der Licht-/Wetterbedingungen. Dies stellt eine weitere Herausforderung für bestehende TTA-Methoden dar. Das TTA-Modell kann beim Wechsel von Domäne A zu Domäne B aufgrund einer übermäßigen Anpassung an Domäne A inkonsistent werden.
Um eine Überanpassung an einen bestimmten kurzfristigen Bereich zu mildern, stellt CoTTA Parameter nach dem Zufallsprinzip wieder her und EATA verwendet Fisher-Informationen, um die Parameter zu regulieren. Dennoch gehen diese Methoden immer noch nicht explizit auf die aufkommenden Herausforderungen im Bereich Testdaten ein.
In diesem Artikel wird ein Ankernetzwerk (Anchor Network) vorgestellt, um ein Selbsttrainingsmodell mit drei Netzwerken (Tri-Net Self-Training) zu bilden, das auf der Selbsttrainingsarchitektur mit zwei Zweigen basiert. Das Ankernetzwerk ist ein eingefrorenes Quellmodell, ermöglicht jedoch die Optimierung von Statistiken anstelle von Parametern in der Batch-Normalisierungsschicht über Testproben. Und es wird ein Ankerverlust vorgeschlagen, um die Ausgabe des Ankernetzwerks zu nutzen, um die Ausgabe des Lehrermodells zu regulieren, um zu verhindern, dass sich das Netzwerk übermäßig an die lokale Verteilung anpasst.
Das endgültige Modell kombiniert das Drei-Netz-Selbsttrainingsmodell und die ausgeglichene Batch-Normalisierungsschicht (TRI-Net-Selbsttraining mit Balanced-Normalisierung, TRIBE), um eine konsistent überlegene Leistung in einem breiteren Bereich einstellbarer Lernraten zu zeigen. Es zeigt erhebliche Leistungsverbesserungen bei vier Datensätzen und mehreren realen Datenströmen und demonstriert die einzigartige Stabilität und Robustheit.
Einführung in die MethodeDie Papiermethode ist in drei Teile unterteilt:
- Einführung in das TTA-Protokoll in der Praxis;
- Ausgewogene Batch-Normalisierung;
- Drei Netzwerke Automatisch Trainieren Sie das Modell.
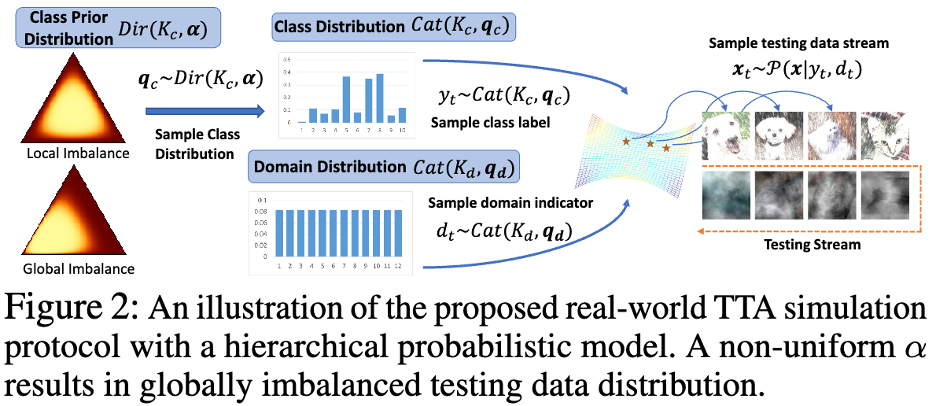
TTA-Protokoll in der realen WeltDer Autor hat ein mathematisches Wahrscheinlichkeitsmodell übernommen, um Datenflüsse mit lokalem Klassenungleichgewicht und globalem Klassenungleichgewicht in der realen Welt und in der Domäne zu testen Die zeitliche Verteilung wurde modelliert. Wie in Abbildung 2 unten dargestellt.
Ausgewogene Batch-NormalisierungUm die geschätzte Verzerrung zu korrigieren, die durch unausgeglichene Testdaten in der BN-Statistik entsteht, schlägt der Autor eine ausgewogene Batch-Normalisierungsschicht für jede semantische Klasse vor, die ein Statistikpaar verwaltet jeweils dargestellt als:
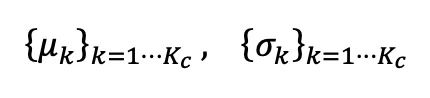
Um die Kategoriestatistiken zu aktualisieren, wendet der Autor eine effiziente iterative Aktualisierungsmethode mit Hilfe der Pseudo-Label-Vorhersage an, wie unten gezeigt:
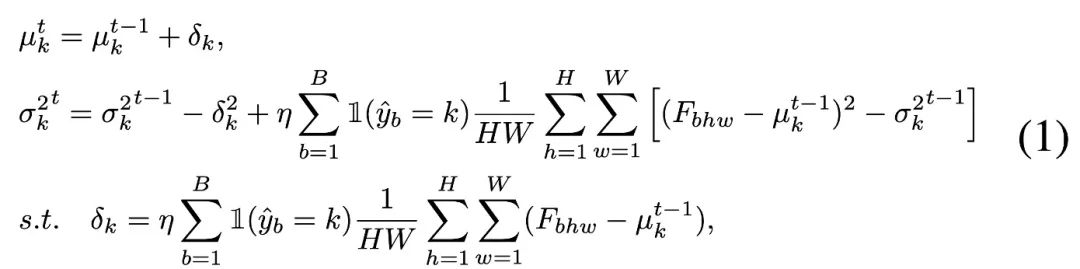 Die Stichprobenpunkte jeder Datenkategorie werden durch Pseudobezeichnungen separat gezählt, und die Gesamtverteilungsstatistik unter Kategoriebalance wird durch die folgende Formel neu ermittelt, um den erlernten Merkmalsraum mit kategorieausgeglichenen Quelldaten abzugleichen .
Die Stichprobenpunkte jeder Datenkategorie werden durch Pseudobezeichnungen separat gezählt, und die Gesamtverteilungsstatistik unter Kategoriebalance wird durch die folgende Formel neu ermittelt, um den erlernten Merkmalsraum mit kategorieausgeglichenen Quelldaten abzugleichen .  In einigen Sonderfällen stellte der Autor fest, dass bei einer großen Anzahl von Kategorien
In einigen Sonderfällen stellte der Autor fest, dass bei einer großen Anzahl von Kategorien oder einer geringen Pseudo-Label-Genauigkeit (Genauigkeit
oder einer geringen Pseudo-Label-Genauigkeit (Genauigkeit 
Durch weitere Analyse und Beobachtung stellte der Autor fest, dass bei γ = 1 die gesamte Aktualisierung erfolgt Die Strategie degeneriert zu RoTTA. Die Update-Strategie von RobustBN ist bei γ = 0 eine rein kategorieunabhängige Update-Strategie. Wenn γ einen Wert von 0 bis 1 annimmt, kann sie daher an verschiedene Situationen angepasst werden. Drei-Netzwerk-SelbsttrainingsmodellBasierend auf dem bestehenden Schüler-Lehrer-Modell fügte der Autor einen Ankernetzwerkzweig hinzu und führte einen Ankerverlust ein, um das Lehrernetzwerk auf die vorhergesagte Verteilung zu beschränken. Dieses Design ist von TTAC++ inspiriert. TTAC++ weist darauf hin, dass es leicht zu einer Anhäufung von Bestätigungsverzerrungen kommt, wenn man sich ausschließlich auf das Selbsttraining des Testdatenstroms verlässt. Dieses Problem ist beim realen Testdatenstrom in diesem Artikel schwerwiegender. TTAC++ verwendet statistische Informationen, die von der Quelldomäne gesammelt wurden, um die Regularisierung der Domänenausrichtung zu implementieren, aber für die Einstellung „Vollständig TTA“ sind diese Quelldomäneninformationen nicht sammelbar. Gleichzeitig erlangte der Autor eine weitere Erkenntnis. Der Erfolg des unbeaufsichtigten Domain-Alignments basiert auf der Annahme, dass die beiden Domain-Verteilungen eine relativ hohe Überlappungsrate aufweisen. Daher hat der Autor nur das eingefrorene Quelldomänenmodell der BN-Statistik angepasst, um das Lehrermodell zu regulieren und zu vermeiden, dass die vorhergesagte Verteilung des Lehrermodells zu weit von der vorhergesagten Verteilung des Quellmodells abweicht (dies zerstörte die frühere Erfahrung mit einer hohen Koinzidenzrate). zwischen den beiden Verteilungen) Beobachtung). Eine Vielzahl von Experimenten beweisen, dass die Entdeckungen und Innovationen in diesem Artikel richtig und belastbar sind. Das Folgende ist der Ausdruck des Verankerungsverlusts: 
Die folgende Abbildung zeigt das Rahmendiagramm des TRIBE-Netzwerks:
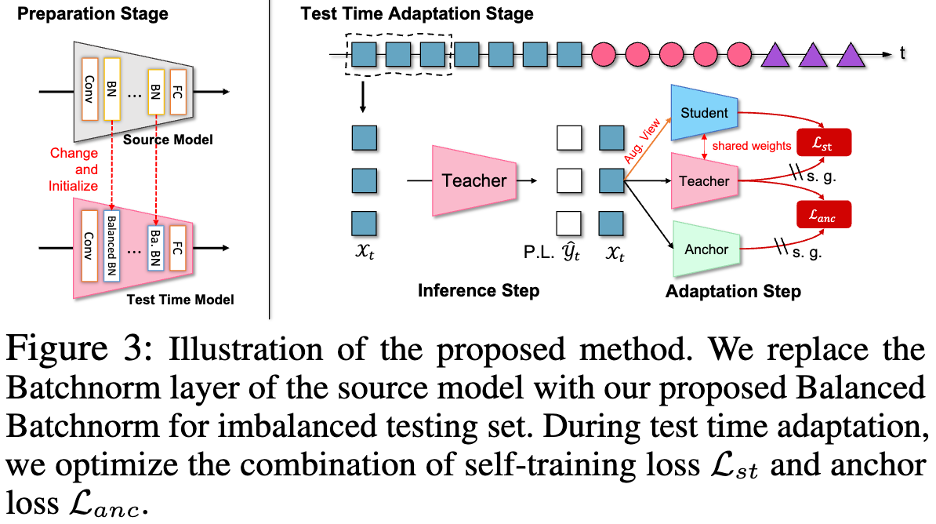
Der Autor des Papiers hat 4 Daten verwendet Die auf TRIBE eingestellten Werte werden mithilfe von zwei realen TTA-Protokollen als Benchmarks überprüft. Zwei reale TTA-Protokolle sind GLI-TTA-F, bei dem die globale Klassenverteilung festgelegt ist, und GLI-TTA-V, bei dem die globale Klassenverteilung nicht festgelegt ist. 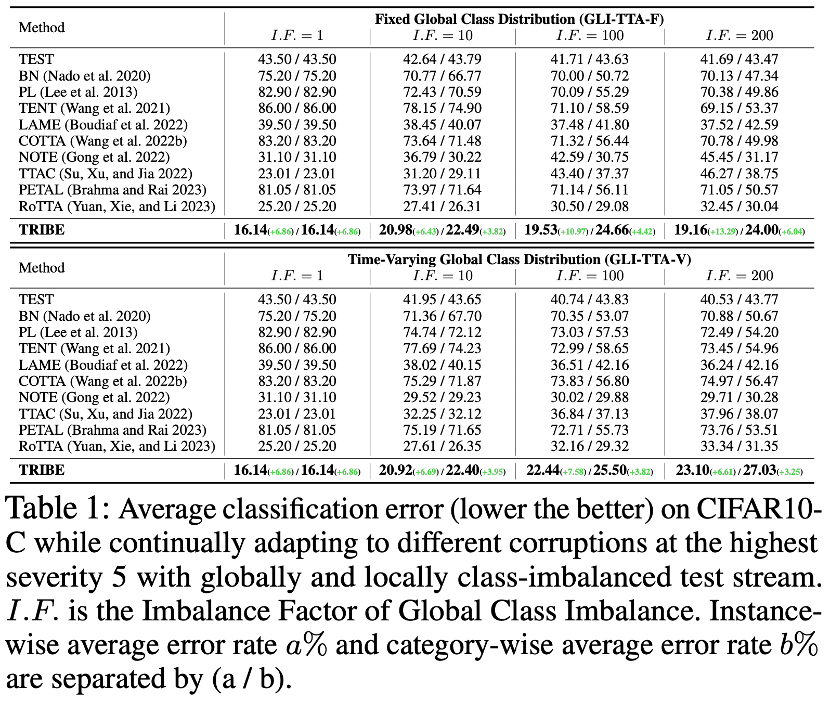
Die obige Tabelle zeigt die Leistung der beiden Protokolle im CIFAR10-C-Datensatz unter verschiedenen Ungleichgewichtskoeffizienten. Die folgenden Schlussfolgerungen können gezogen werden: 1 Nur LAME, TTAC, NOTE, RoTTA und TRIBE Das Papier übertrifft die TEST-Werte. Die Basislinie zeigt die Notwendigkeit einer robusteren TTA-Methode unter realen Testabläufen. 2. Das globale Klassenungleichgewicht hat die bestehenden TTA-Methoden vor große Herausforderungen gestellt. Beispielsweise zeigte die vorherige SOTA-Methode RoTTA eine Fehlerrate von 25,20 %, wenn I.F.=1 200. 32,45 %, im Vergleich dazu kann TRIBE stabil eine relativ bessere Leistung vorweisen. 3. Die Konsistenz von TRIBE hat einen absoluten Vorteil und übertrifft alle vorherigen Methoden und übertrifft die vorherige SOTA (TTAC) um etwa 7 % bei der Einstellung des globalen Klassengleichgewichts (I.F. = 1) und darüber hinaus schwierig Unter der Einstellung eines globalen Klassenungleichgewichts (I.F.=200) wurde eine Leistungsverbesserung von etwa 13 % erreicht. 4. Von I.F.=10 bis I.F.=200 zeigen andere TTA-Methoden einen Trend des Leistungsabfalls mit zunehmendem Ungleichgewichtsgrad. TRIBE kann eine relativ stabile Leistung aufrechterhalten. Dies wird auf die Einführung einer ausgewogenen Batch-Normalisierungsschicht zurückgeführt, die schwere Klassenungleichgewichte und Verankerungsverluste besser berücksichtigt und so eine Überanpassung über verschiedene Domänen hinweg vermeidet. Weitere Ergebnisse des Datensatzes finden Sie im Originalpapier. Darüber hinaus zeigt Tabelle 4 die detaillierte modulare Ablation mit den folgenden Beobachtungsschlussfolgerungen: 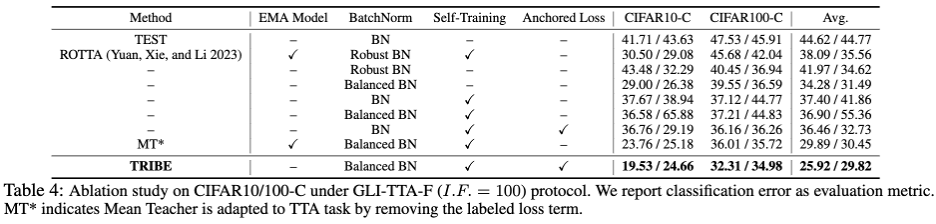
1 Ersetzen Sie BN nur durch die ausgeglichene Chargennormalisierungsschicht (Balanced BN), ohne für einen Modellparameter zu aktualisieren. Nur die Aktualisierung der BN-Statistiken durch Forward kann zu einer Leistungsverbesserung von 10,24 % (44,62 –> 34,28) führen und die Fehlerrate von Robust BN von 41,97 % übertreffen. 2. Anchored Loss kombiniert mit Self-Training, ob unter der vorherigen BN-Struktur oder der neuesten Balanced BN-Struktur, hat die Leistung verbessert und den Regularisierungseffekt des EMA-Modells übertroffen. Der Rest dieses Artikels und der 9-seitige Anhang präsentieren schließlich 17 detaillierte tabellarische Ergebnisse, die die Stabilität, Robustheit und Überlegenheit von TRIBE aus mehreren Dimensionen demonstrieren. Der Anhang enthält auch eine detailliertere theoretische Ableitung und Erläuterung der Balanced-Batch-Normalisierungsschicht. Zusammenfassung und AusblickUm viele reale Herausforderungen wie Nicht-i.i.d.-Testdatenfluss, globales Klassenungleichgewicht und kontinuierliche Domänenübertragung zu bewältigen, untersuchte das Forschungsteam eingehend, wie um das Testen der Robustheit von Zeitbereichsanpassungsalgorithmen zu verbessern. Um sich an die unausgeglichenen Testdaten anzupassen, schlug der Autor eine Balanced Batchnorm-Schicht vor, um eine unvoreingenommene Schätzung der Statistiken zu erreichen, und schlug dann ein Netzwerk vor, das ein Schülernetzwerk, ein Lehrernetzwerk und eine dreischichtige Netzwerkstruktur zur Standardisierung umfasst TTA basiert auf Selbsttraining. Da dieser Artikel jedoch noch Mängel und Verbesserungspotenzial aufweist, ist der Grad der Anpassung an andere Aufgaben und Transformer-basierte Modelle noch unbekannt. Diese Probleme verdienen in der Folgearbeit weitere Forschung und Untersuchung.
Das obige ist der detaillierte Inhalt vonTRIBE erreicht Robustheit bei der Domänenanpassung und erreicht SOTAs AAAII 2024 in mehreren realen Szenarien.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

