
Heim >System-Tutorial >LINUX >Die historische Entwicklung der Python-Programmierung
Die historische Entwicklung der Python-Programmierung

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-01-01 09:31:11642Durchsuche
| Einführung | Sobald Sie sich auf den Weg des Programmierens begeben und das Programmierproblem nicht lösen, wird es Sie im Laufe Ihrer Karriere wie ein Geist verfolgen, und verschiedene übernatürliche Ereignisse werden nacheinander folgen und andauern. Nur wenn Sie dem Geist der Programmierer freien Lauf lassen und bis zum Ende kämpfen, können Sie die durch Codierungsprobleme verursachten Probleme vollständig beseitigen. |
Das erste Mal, dass ich auf ein Codierungsproblem stieß, war, als ich ein JavaWeb-bezogenes Projekt schrieb. Eine Zeichenfolge wanderte vom Browser zum Anwendungscode und tauchte in die Datenbank ein. Es ist jederzeit möglich, auf Codierungsminen zu treten überall. Das zweite Mal stieß ich auf ein Codierungsproblem, als ich beim Crawlen von Webseitendaten erneut auftrat. Der beliebteste Satz heutzutage ist: „Ich war damals verwirrt.“ . ".
Um die Zeichenkodierung zu verstehen, müssen wir beim Ursprung von Computern beginnen. Alle Daten in Computern, ob Texte, Bilder, Videos oder Audiodateien, werden im Wesentlichen in einer digitalen Form ähnlich 01010101 gespeichert. Wir haben Glück, aber auch Pech, die Zeit hat uns die Möglichkeit gegeben, mit Computern in Berührung zu kommen. Leider wurden Computer nicht von unseren Landsleuten erfunden, daher müssen die Standards von Computern entsprechend den Gewohnheiten der Menschen gestaltet werden Amerikanisches Imperium. Wie stellten Computer letztendlich Charaktere dar? Dies beginnt mit der Geschichte der Computercodierung.
ASCIIJeder Anfänger, der JavaWeb entwickelt, wird auf Probleme mit verstümmeltem Code stoßen, und jeder Anfänger, der Python-Crawler betreibt, wird auf Codierungsprobleme stoßen. Warum ist das Codierungsproblem so schmerzhaft? Dieses Problem begann, als Guido van Rossum 1992 die Python-Sprache entwickelte. Damals hätte Guido weder erwartet, dass die Python-Sprache heute so beliebt sein würde, noch hätte er erwartet, dass die Geschwindigkeit der Computerentwicklung so erstaunlich sein würde. Als Guido diese Sprache ursprünglich entwarf, musste er sich nicht um die Kodierung kümmern, da in der englischen Welt die Anzahl der Zeichen sehr begrenzt ist, nämlich 26 Buchstaben (Groß- und Kleinbuchstaben), 10 Zahlen, Satzzeichen und Steuerzeichen , auf der Tastatur Die Zeichen aller Tasten summieren sich auf etwas mehr als hundert Zeichen. Dies ist mehr als genug, um ein Byte Speicherplatz zur Darstellung eines Zeichens in einem Computer zu verwenden, da ein Byte 8 Bit entspricht und 8 Bit 256 Symbole darstellen können. Deshalb haben kluge Amerikaner eine Reihe von Zeichenkodierungsstandards namens ASCII (American Standard Code for Information Interchange) entwickelt. Der Binärwert, der dem Zeichen A entspricht, ist beispielsweise 01000001, und der entsprechende Dezimalwert ist 65. Zunächst definierte ASCII nur 128 Zeichencodes, darunter 96 Text- und 32 Steuersymbole, insgesamt sind also 128 Zeichen erforderlich, um alle Zeichen darzustellen, sodass ASCII nur ein Byte verwendet höchste Bit sind alle 0.
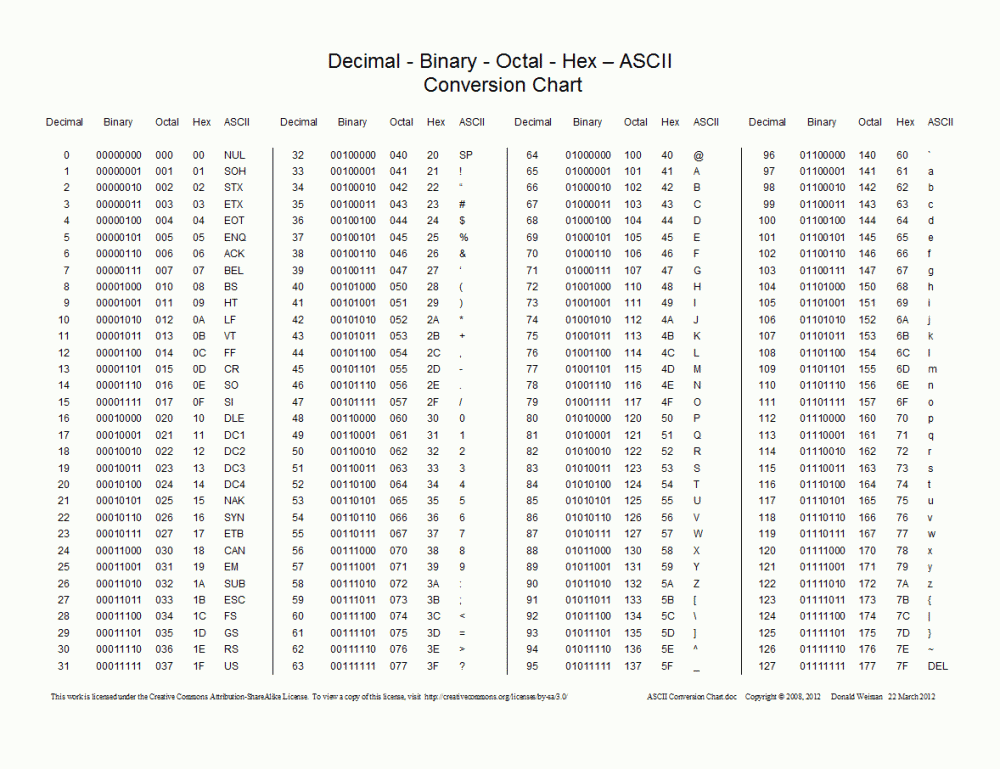
Als sich Computer jedoch langsam in andere westeuropäische Regionen ausbreiteten, entdeckten sie, dass es viele in Westeuropa einzigartige Zeichen gab, die nicht in der ASCII-Kodierungstabelle enthalten waren. Daher erschien später ein erweiterbares ASCII namens EASCII auf ASCII Von 7 Bit auf 8 Bit erweitert, ist es vollständig kompatibel mit ASCII. Die erweiterten Symbole umfassen Tabellensymbole, Rechensymbole, griechische Buchstaben und spezielle lateinische Symbole. Die EASCII-Ära ist jedoch eine chaotische Ära. Es gibt keinen einheitlichen Standard, um ihren eigenen Satz von Zeichenkodierungsstandards zu implementieren. Die bekanntesten sind CP437 Wird in Windows-Systemen verwendet, wie unten gezeigt:
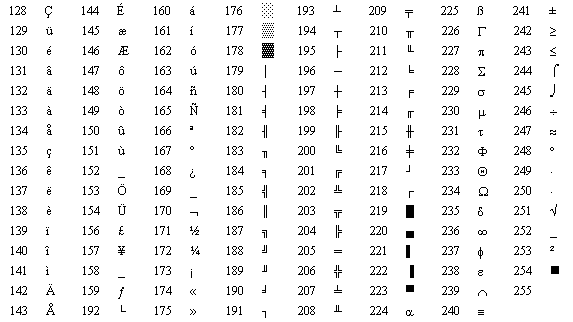
Ein weiteres weit verbreitetes EASCII ist ISO/8859-1 (Latin-1), eine Reihe von 8-Bit-Zeichensatzstandards, die gemeinsam von der International Organization for Standardization (ISO) und der International Electrotechnical Commission (IEC), ISO, entwickelt wurden /8859-1 erbt nur die Zeichen zwischen 128 und 159 der CP437-Zeichenkodierung und ist daher ab 160 definiert. Leider sind diese zahlreichen erweiterten ASCII-Zeichensätze nicht miteinander kompatibel.

Mit dem Fortschritt der Zeit haben Computer begonnen, sich in Tausenden von Haushalten auszubreiten. Bill Gates hat den Traum wahr gemacht, dass jeder einen Computer auf seinem Desktop hat. Ein Problem, mit dem Computer bei der Einreise nach China konfrontiert sind, ist jedoch die Zeichenkodierung. Obwohl chinesische Schriftzeichen in unserem Land die am häufigsten von Menschen verwendeten Schriftzeichen sind, sind chinesische Schriftzeichen breit gefächert und tiefgreifend, und es gibt Zehntausende gebräuchlicher chinesischer Schriftzeichen geht weit über das hinaus, was die ASCII-Kodierung darstellen kann. Sogar EASCII schien ein Tropfen auf den heißen Stein zu sein, also erstellten die klugen Chinesen einen eigenen Codesatz namens GB2312, auch bekannt als GB0, der von der State Administration of Standards veröffentlicht wurde China im Jahr 1981. Die GB2312-Kodierung enthält insgesamt 6763 chinesische Zeichen und ist auch mit ASCII kompatibel. Das Aufkommen von GB2312 deckt im Wesentlichen den Computerverarbeitungsbedarf chinesischer Schriftzeichen ab. Die darin enthaltenen chinesischen Schriftzeichen decken 99,75 % der Verwendungshäufigkeit auf dem chinesischen Festland ab. Allerdings kann GB2312 die Anforderungen chinesischer Schriftzeichen immer noch nicht zu 100 % erfüllen. GB2312 kann einige seltene Schriftzeichen und traditionelle chinesische Schriftzeichen nicht verarbeiten. Später wurde eine Codierung namens GBK basierend auf GB2312 erstellt. GBK enthält nicht nur 27.484 chinesische Schriftzeichen, sondern auch wichtige Sprachen ethnischer Minderheiten wie Tibetisch, Mongolisch und Uigurisch. Ebenso ist GBK auch mit der ASCII-Codierung kompatibel. Englische Zeichen werden durch 1 Byte dargestellt, chinesische Zeichen werden durch zwei Bytes dargestellt.
UnicodeWir können einen separaten Berggipfel einrichten, um mit chinesischen Schriftzeichen umzugehen und eine Reihe von Codierungsstandards entsprechend unseren eigenen Bedürfnissen zu entwickeln. Computer werden jedoch nicht nur von Amerikanern und Chinesen verwendet, sondern verwenden auch Schriftzeichen aus anderen Ländern in Europa und Asien. Es wird geschätzt, dass es Hunderttausende koreanischer Zeichen aus der ganzen Welt gibt, was weit über den Bereich hinausgeht, den ASCII-Code oder sogar GBK darstellen können. Außerdem: Warum verwenden die Leute Ihren GBK-Standard? Wie kann man eine so große Zeichenbibliothek ausdrücken? Deshalb hat die United Alliance International Organization die Unicode-Kodierung vorgeschlagen. Der wissenschaftliche Name von Unicode ist „Universal Multiple-Octet Coded Character Set“, bezeichnet als UCS.

Unicode hat zwei Formate: UCS-2 und UCS-4. UCS-2 verwendet zum Kodieren zwei Bytes mit insgesamt 16 Bits. Theoretisch kann es bis zu 65536 Zeichen darstellen. Um jedoch alle Zeichen der Welt darzustellen, reichen 65536 Zahlen offensichtlich nicht aus, da dies nur für chinesische Zeichen gilt Fast 100.000, daher definiert die Unicode 4.0-Spezifikation einen zusätzlichen Satz von Zeichenkodierungen. UCS-4 verwendet 4 Bytes (eigentlich werden nur 31 Bits verwendet, und das höchste Bit muss 0 sein).
Unicode kann theoretisch Symbole abdecken, die in allen Sprachen verwendet werden. Jedes Zeichen auf der Welt kann durch eine Unicode-Kodierung dargestellt werden. Sobald die Unicode-Kodierung eines Zeichens festgelegt ist, ändert sich diese nicht. Allerdings unterliegt Unicode bestimmten Einschränkungen, wenn ein Unicode-Zeichen im Netzwerk übertragen oder endgültig gespeichert wird. Beispielsweise kann ein Zeichen „A“ durch ein Byte dargestellt werden zwei Bytes, was offensichtlich eine Platzverschwendung ist. Das zweite Problem besteht darin, dass es sich beim Speichern eines Unicode-Zeichens um eine Zeichenfolge mit 01 Zahlen handelt. Woher weiß der Computer also, ob ein 2-Byte-Unicode-Zeichen ein 2-Byte-Zeichen oder zwei 1-Byte-Zeichen darstellt? Wenn Sie es dem Computer nicht im Voraus mitteilen, wird der Computer ebenfalls verwirrt sein. Unicode legt nur fest, wie kodiert wird, legt jedoch nicht fest, wie diese Kodierung übertragen oder gespeichert wird. Die Unicode-Kodierung des Zeichens „汉“ ist beispielsweise 6C49. Ich kann 4 ASCII-Zahlen verwenden, um diese Kodierung zu übertragen und zu speichern. Ich kann auch 3 aufeinanderfolgende Bytes E6 B1 89 verwenden, die in UTF-8 kodiert sind, um sie darzustellen. Der Schlüssel liegt darin, dass beide Parteien der Kommunikation zustimmen müssen. Daher verfügt die Unicode-Codierung über unterschiedliche Implementierungsmethoden, wie zum Beispiel: UTF-8, UTF-16 usw. Unicode ist hier genau wie Englisch ein universeller Standard für die Kommunikation zwischen Ländern. Sie übersetzen standardmäßige englische Dokumente in den Text ihres eigenen Landes.
UTF-8 (Unicode Transformation Format) wird als Implementierung von Unicode häufig im Internet verwendet. Es handelt sich um eine Zeichenkodierung variabler Länge, die je nach Situation 1-4 Bytes zur Darstellung eines Zeichens verwenden kann. Beispielsweise benötigen englische Zeichen, die ursprünglich im ASCII-Code ausgedrückt werden können, nur ein Byte Platz, wenn sie in UTF-8 ausgedrückt werden, was mit ASCII identisch ist. Bei Multibyte-Zeichen (n Bytes) werden die ersten n Bits des ersten Bytes auf 1, das n+1te Bit auf 0 und die ersten beiden Bits der folgenden Bytes auf 10 gesetzt. Die restlichen Binärziffern werden mit dem UNICODE-Code des Zeichens gefüllt.
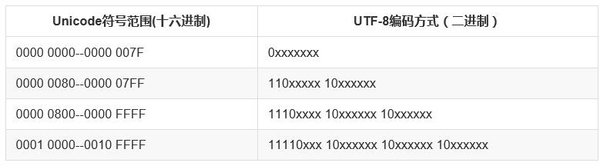
Nehmen Sie als Beispiel das chinesische Zeichen „好“. Der entsprechende Unicode von „好“ ist 0000 0800 – 0000 FFFF. Wenn es in UTF-8 ausgedrückt wird, sind daher 3 Bytes zum Speichern erforderlich . 597D wird in Binärform ausgedrückt: 0101100101111101, füllen Sie es mit 1110xxxx 10xxxxxx 10xxxxxx, um 11100101 10100101 10111101 zu erhalten, umgewandelt in Hexadezimalzahl: E5A5BD, also ist die UTF-8-Kodierung, die dem „guten“ Unicode „597D“ entspricht, „E5A“. 5BD".
Unicode 0101 100101 111101
Kodierungsregeln 1110xxxx 10xxxxxx 10xxxxxx
--------------------------
utf-8 11100101 10100101 10111101
--------------------------
Hexadezimal utf-8 e 5 a 5 b d Python-Zeichenkodierung
Jetzt bin ich endlich mit der Theorie fertig. Lassen Sie uns über Codierungsprobleme in Python sprechen. Python wurde viel früher als Unicode geboren und die Standardcodierung von Python ist ASCII.
>>> Importsystem
>>> sys.getdefaultencoding()
'ascii'
Wenn Sie die Codierung in der Python-Quellcodedatei nicht explizit angeben, tritt daher ein Syntaxfehler auf
#test.py
Drucken Sie „Hallo“
Das Obige ist das test.py-Skript, führen Sie es aus
python test.py
Der folgende Fehler wird eingefügt:
File “test.py”, line 1 yntaxError: Non-ASCII character ‘/xe4′ in file test.py on line 1, but no encoding declared;
Um Nicht-ASCII-Zeichen im Quellcode zu unterstützen, muss das Codierungsformat explizit in der ersten oder zweiten Zeile der Quelldatei angegeben werden:
# coding=utf-8
oder:
#!/usr/bin/python # -*- coding: utf-8 -*-
Die mit Strings in Python verbundenen Datentypen sind str. Sie sind beide Unterklassen von basestring. Es ist ersichtlich, dass str und Unicode zwei verschiedene Arten von String-Objekten sind.
basestring
/ /
/ /
str unicode
Für das gleiche chinesische Zeichen „好“ entspricht es, wenn es in str ausgedrückt wird, der UTF-8-Kodierung '/xe5/xa5/xbd', und wenn es in Unicode ausgedrückt wird, ist das entsprechende Symbol u'/u597d' , ist gleichbedeutend mit „gut“. Es sollte hinzugefügt werden, dass das spezifische Codierungsformat von Zeichen vom Typ str UTF-8, GBK oder andere Formate ist, abhängig vom Betriebssystem. Im Windows-System zeigt die cmd-Befehlszeile beispielsweise Folgendes an:
# windows终端 >>> a = '好' >>> type(a) <type 'str'> >>> a '/xba/xc3'
Und was in der Befehlszeile des Linux-Systems angezeigt wird, ist:
# linux终端 >>> a='好' >>> type(a) <type 'str'> >>> a '/xe5/xa5/xbd' >>> b=u'好' >>> type(b) <type 'unicode'> >>> b u'/u597d'
Ob es sich um Python3x, Java oder andere Programmiersprachen handelt, die Unicode-Kodierung ist zum Standardkodierungsformat der Sprache geworden. Wenn die Daten schließlich auf dem Medium gespeichert werden, können verschiedene Medien unterschiedliche Methoden verwenden. und einige Es spielt keine Rolle, ob die Leute GBK verwenden möchten. Solange die Plattform über einheitliche Codierungsstandards verfügt, spielt es keine Rolle, wie sie implementiert werden.
Wie konvertiert man also zwischen str und Unicode in Python? Die Konvertierung zwischen diesen beiden Arten von Zeichenfolgentypen basiert auf diesen beiden Methoden: Dekodieren und Kodieren.
#从str类型转换到unicode
s.decode(encoding) =====> <type 'str'> to <type 'unicode'>
#从unicode转换到str
u.encode(encoding) =====> <type 'unicode'> to <type 'str'>
>>> c = b.encode('utf-8')
>>> type(c)
<type 'str'>
>>> c
'/xe5/xa5/xbd'
>>> d = c.decode('utf-8')
>>> type(d)
<type 'unicode'>
>>> d
u'/u597d'
This'/xe5/xa5/xbd' ist die UTF-8-codierte Zeichenfolge vom Typ str, die von Unicode u'ha' über die Funktion encode codiert wurde. Umgekehrt wird der Str-Typ c durch die Funktion decode in den Unicode-String d dekodiert.
str(s) vs. Unicode(s)str(s) und unicode(s) sind zwei Factory-Methoden, die str-String-Objekte bzw. Unicode-String-Objekte zurückgeben. str(s) ist die Abkürzung für s.encode(‘ascii’). Experiment:
>>> s3 = u"你好" >>> s3 u'/u4f60/u597d' >>> str(s3) Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
Der obige s3 ist eine Zeichenfolge vom Typ Unicode. Da die beiden chinesischen Zeichen „Hallo“ nicht durch ASCII-Code dargestellt werden können, wird ein Fehler gemeldet Kodierung: s3.encode('gbk') oder s3.encode('utf-8') wird dieses Problem nicht verursachen. Ähnlicher Unicode hat den gleichen Fehler:
>>> s4 = "你好" >>> unicode(s4) Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeDecodeError: 'ascii' codec can't decode byte 0xc4 in position 0: ordinal not in range(128) >>>
unicode(s4) entspricht s4.decode('ascii')
Für eine korrekte Konvertierung müssen Sie daher die Codierung s4.decode('gbk') oder s4.decode('utf-8') korrekt angeben.
Alle Gründe für verstümmelte Zeichen können auf die inkonsistenten Kodierungsformate zurückgeführt werden, die beim Kodierungsprozess von Zeichen nach unterschiedlicher Kodierung und Dekodierung verwendet werden, wie zum Beispiel:
# encoding: utf-8
>>> a='好'
>>> a
'/xe5/xa5/xbd'
>>> b=a.decode("utf-8")
>>> b
u'/u597d'
>>> c=b.encode("gbk")
>>> c
'/xba/xc3'
>>> print c
UTF-8-codiertes Zeichen „好“ belegt 3 Bytes, wenn Sie GBK zum Dekodieren verwenden. Am Ende werden verstümmelte Zeichen angezeigt. Vermeiden Sie daher verstümmelte Zeichen. Der beste Weg besteht darin, zum Kodieren und Dekodieren von Zeichen immer dasselbe Kodierungsformat zu verwenden.

Für Zeichenfolgen im Unicode-Format (Str-Typ):
s = 'id/u003d215903184/u0026index/u003d0/u0026st/u003d52/u0026sid'
Um in echten Unicode zu konvertieren, müssen Sie Folgendes verwenden:
s.decode('unicode-escape')
Test:
>>> s = 'id/u003d215903184/u0026index/u003d0/u0026st/u003d52/u0026sid/u003d95000/u0026i'
>>> print(type(s))
<type 'str'>
>>> s = s.decode('unicode-escape')
>>> s
u'id=215903184&index=0&st=52&sid=95000&i'
>>> print(type(s))
<type 'unicode'>
>>>
Die oben genannten Codes und Konzepte basieren auf Python2.x.
Das obige ist der detaillierte Inhalt vonDie historische Entwicklung der Python-Programmierung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Wie überprüfe ich die CPU-Belegung (Nutzung) unter Linux?
- Was ist eine Linux-Zertifizierung?
- So erstellen Sie ein Testverzeichnis im Stammverzeichnis eines Linux-Systems
- So wechseln Sie im Linux-System zum Root-Benutzer
- So verwenden Sie den Base64-Befehl, um Linux-Befehle zu verschlüsseln und auszuführen