
Heim >Technologie-Peripheriegeräte >KI >4090-Generator: Im Vergleich zur A100-Plattform beträgt die Geschwindigkeit der Token-Generierung nur weniger als 18 %, und die Übermittlung an die Inferenz-Engine hat zu heftigen Diskussionen geführt
4090-Generator: Im Vergleich zur A100-Plattform beträgt die Geschwindigkeit der Token-Generierung nur weniger als 18 %, und die Übermittlung an die Inferenz-Engine hat zu heftigen Diskussionen geführt

- 王林nach vorne
- 2023-12-21 15:25:411890Durchsuche
PowerInfer verbessert die Effizienz der Ausführung von KI auf Consumer-Hardware.
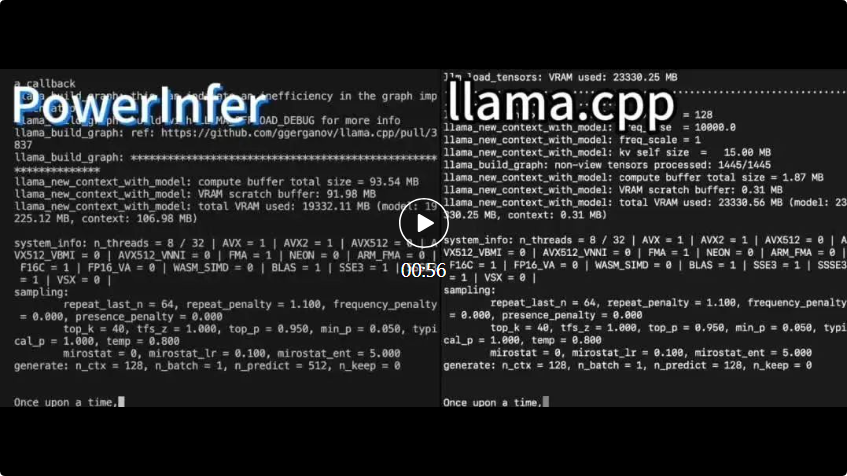 ama.cpp läuft beide auf derselben Hardware und nutzt den VRAM der RTX 4090 voll aus.
ama.cpp läuft beide auf derselben Hardware und nutzt den VRAM der RTX 4090 voll aus. PowerInfer Im Vergleich zum lokalen erweiterten LLM-Inferenz-Framework llama.cpp wird durch die Ausführung des Falcon (ReLU)-40B-FP16-Modells auf einer einzelnen RTX 4090 (24G) nicht nur eine mehr als 11-fache Beschleunigung erreicht, sondern auch die Modellgenauigkeit beibehalten
PowerInfer ist eine Hochgeschwindigkeits-Inferenz-Engine, die für die lokale Bereitstellung von LLM entwickelt wurde. Im Gegensatz zu Multi-Experten-Systemen (MoE) hat PowerInfer geschickt eine GPU-CPU-Hybrid-Inferenz-Engine entwickelt, die die hohe Lokalität der LLM-Inferenz voll ausnutzt. Häufig aktivierte Neuronen (d. h. Hot-Aktivierung) werden vorab auf die GPU geladen. Für einen schnellen Zugriff werden Neuronen verwendet, die selten aktiviert werden (d. h. Kaltaktivierungen) werden auf der CPU berechnet. So funktioniert es
Diese Methode kann den GPU-Speicherbedarf und die Menge der Datenübertragung zwischen CPU und GPU erheblich reduzieren

- Projektlink: https://github.com/SJTU-IPADS/ PowerInfer
- Link zum Papier: https://ipads.se.sjtu.edu.cn/_media/publications/powerinfer-20231219.pdf
- PowerInfer kann LLM mit hoher Geschwindigkeit auf einem PC ausführen, der mit einer einzelnen Consumer-GPU ausgestattet ist. Benutzer können PowerInfer jetzt mit Llama 2 und
verwenden, die Unterstützung für Mistral-7B folgt in Kürze. An einem Tag hat PowerInfer erfolgreich 2K-Sterne erhalten
 Nachdem die Internetnutzer diese Untersuchung gesehen hatten, zeigten sie sich begeistert: Jetzt kann eine einzige Karte 4090 große 175B-Modelle betreiben, nicht mehr nur Was für ein Traum
Nachdem die Internetnutzer diese Untersuchung gesehen hatten, zeigten sie sich begeistert: Jetzt kann eine einzige Karte 4090 große 175B-Modelle betreiben, nicht mehr nur Was für ein Traum
Der Schlüssel zum Design von PowerInfer besteht darin, den hohen Grad an Lokalität auszunutzen, der der LLM-Inferenz innewohnt, die durch „Potenzgesetzverteilungen bei Neuronenaktivierungen“ gekennzeichnet ist. Diese Verteilung legt nahe, dass eine kleine Untergruppe von Neuronen, sogenannte heiße Neuronen, über alle Eingaben hinweg konsistent aktiviert wird, während die Mehrheit der kalten Neuronen je nach bestimmten Eingaben variiert. PowerInfer nutzt diesen Mechanismus, um eine GPU-CPU-Hybrid-Inferenz-Engine zu entwerfen.
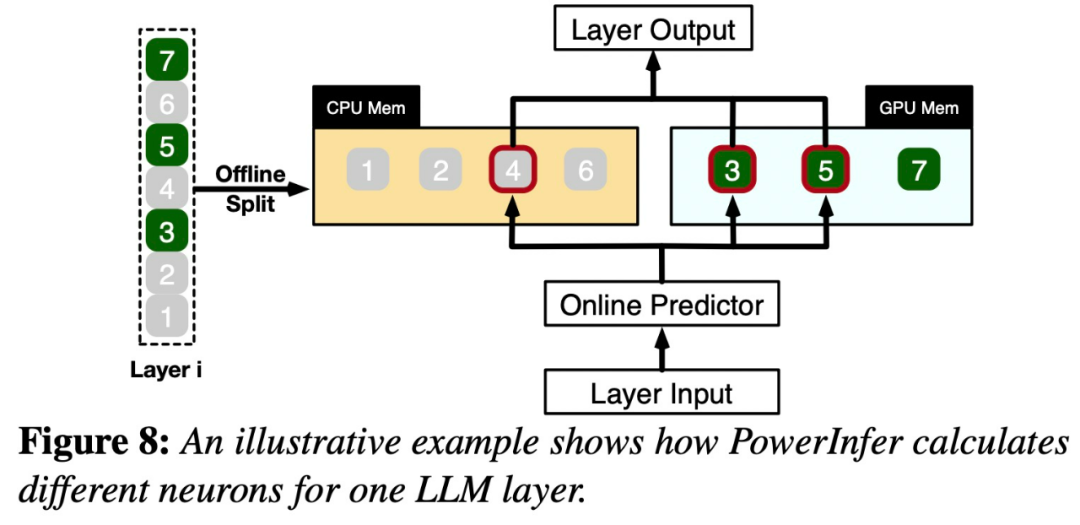
Bitte sehen Sie sich Abbildung 7 unten an, die einen Architekturüberblick von PowerInfer zeigt, einschließlich Offline- und Online-Komponenten. Die Offline-Komponente ist dafür verantwortlich, die Aktivierungsparsität von LLM zu handhaben und gleichzeitig zwischen heißen und kalten Neuronen zu unterscheiden. Während der Online-Phase lädt die Inferenz-Engine beide Arten von Neuronen in die GPU und die CPU und bedient LLM-Anfragen zur Laufzeit mit geringer Latenz. Abbildung 8 zeigt, wie PowerInfer funktioniert. Es koordiniert die Schichten zwischen GPU und CPU Verarbeitung von Neuronen. PowerInfer klassifiziert Neuronen anhand von Offline-Daten und weist aktive Neuronen (z. B. Index 3, 5, 7) dem GPU-Speicher und andere Neuronen dem CPU-Speicher zuSobald die Eingabe eingegangen ist, identifiziert der Prädiktor Neuronen in der aktuellen Schicht, die wahrscheinlich aktiviert werden. Es ist zu beachten, dass thermisch aktivierte Neuronen, die durch statistische Offline-Analyse identifiziert wurden, möglicherweise nicht mit dem tatsächlichen Aktivierungsverhalten zur Laufzeit übereinstimmen. Obwohl beispielsweise Neuron 7 als thermisch aktiviert gekennzeichnet ist, ist dies in Wirklichkeit nicht der Fall. Die CPU und die GPU verarbeiten dann die bereits aktivierten Neuronen und ignorieren diejenigen, die nicht aktiviert sind. Die GPU ist für die Berechnung der Neuronen 3 und 5 verantwortlich, während die CPU für Neuron 4 zuständig ist. Wenn die Berechnung von Neuron 4 abgeschlossen ist, wird seine Ausgabe zur Ergebnisintegration an die GPU gesendet
Um den Inhalt neu zu schreiben, ohne die ursprüngliche Bedeutung zu ändern, muss die Sprache ins Chinesische umgeschrieben werden. Es ist nicht erforderlich, dass der Originalsatz erscheint
Die Studie wurde mit dem OPT-Modell mit verschiedenen Parametern durchgeführt. Um den Inhalt neu zu schreiben, ohne die ursprüngliche Bedeutung zu ändern, muss die Sprache ins Chinesische umgeschrieben werden. Es ist nicht erforderlich, Originalsätze vorzulegen, die Parameter reichen von 6,7B bis 175B, und die Modelle Falcon (ReLU)-40B und LLaMA (ReGLU)-70B sind ebenfalls enthalten. Es ist erwähnenswert, dass die Größe des 175B-Parametermodells mit dem „GPT-3-Modell“ vergleichbar ist. In diesem Artikel wird PowerInfer auch mit llama.cpp verglichen, einem hochmodernen nativen LLM-Inferenz-Framework. Um den Vergleich zu erleichtern, wurde in dieser Studie auch llama.cpp erweitert, um das OPT-Modell zu unterstützen pro Sekunde generierte Token (Tokens/s) zur Quantifizierung
Diese Studie vergleicht zunächst die End-to-End-Inferenzleistung von PowerInfer und llama.cpp mit einer Stapelgröße von 1
Auf PC-High mit NVIDIA RTX 4090, Abbildung 10 zeigt die verschiedenen Modelle und die Generierungsgeschwindigkeit von Ein- und Ausgabekonfigurationen. Im Durchschnitt erreicht PowerInfer eine Generierungsgeschwindigkeit von 8,32 Token/s, mit einem Maximum von 16,06 Token/s, was deutlich besser ist als llama.cpp, 7,23-mal höher als llama.cpp und 11,69-mal höher als Falcon-40B
Nachfolgend: Mit zunehmender Anzahl der Ausgabetoken wird der Leistungsvorteil von PowerInfer deutlicher, da die Generierungsphase eine wichtigere Rolle in der gesamten Inferenzzeit spielt. Zu diesem Zeitpunkt wird eine kleine Anzahl von Neuronen sowohl auf der CPU als auch auf der GPU aktiviert, was im Vergleich zu llama.cpp unnötige Berechnungen reduziert. Im Fall von OPT-30B werden beispielsweise nur etwa 20 % der Neuronen pro generiertem Token aktiviert, die meisten davon werden auf der GPU verarbeitet, was der Vorteil der neuronenbewussten Inferenz von PowerInfer ist
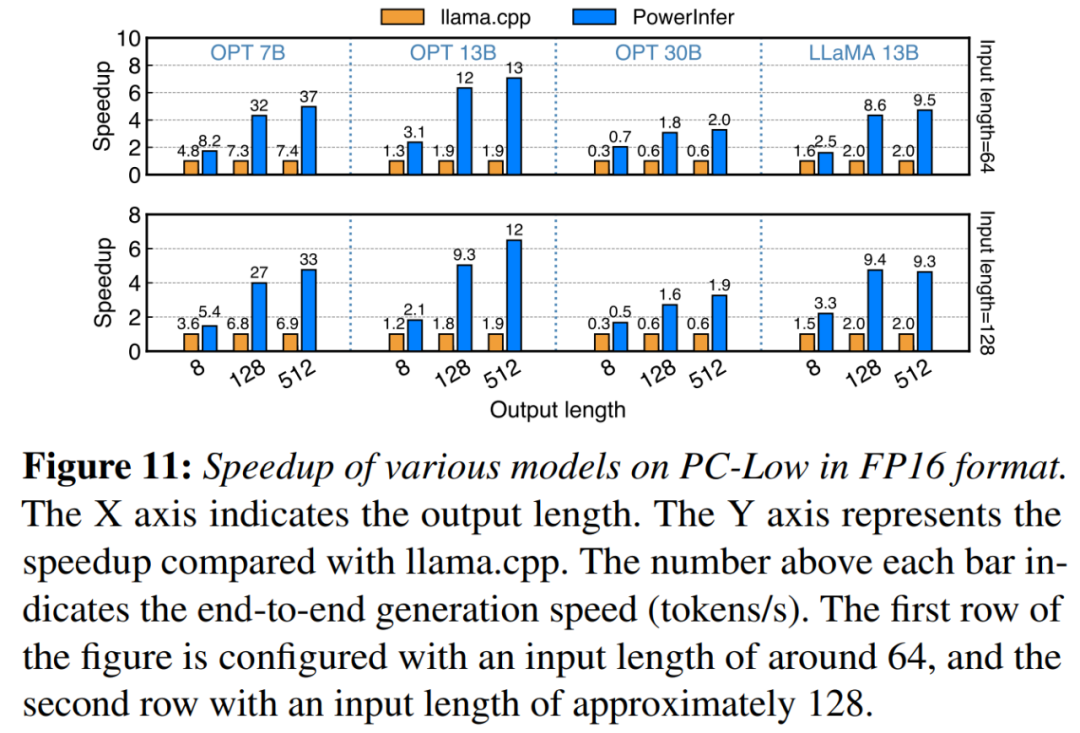
in Abbildung 11 Wie in der Abbildung gezeigt, erzielte PowerInfer trotz der Ausführung auf PC-Low immer noch erhebliche Leistungssteigerungen mit einer durchschnittlichen Geschwindigkeitssteigerung von 5,01x und einer Spitzengeschwindigkeitssteigerung von 7,06x. Allerdings fallen diese Verbesserungen im Vergleich zu PC-High geringer aus, was hauptsächlich auf die 11-GB-GPU-Speicherbeschränkung von PC-Low zurückzuführen ist. Diese Grenze wirkt sich auf die Anzahl der Neuronen aus, die der GPU zugewiesen werden können, insbesondere bei Modellen mit etwa 30B Parametern oder mehr, was zu einer größeren Abhängigkeit von der CPU führt, um eine große Anzahl aktivierter Neuronen zu verarbeiten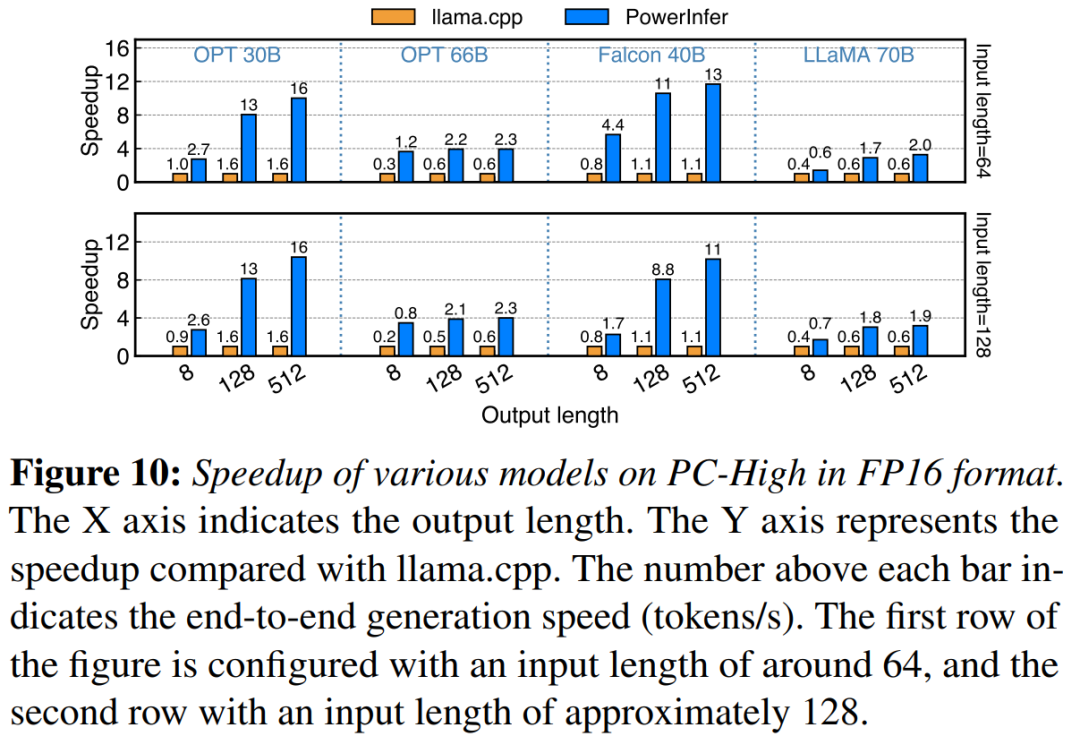

Abschließend bewertet die Studie auch die End-to-End-Inferenzleistung von PowerInfer bei verschiedenen Stapelgrößen. Wie in Abbildung 14 dargestellt, zeigt PowerInfer bei einer Stapelgröße von weniger als 32 erhebliche Vorteile mit einer durchschnittlichen Leistungsverbesserung um das 6,08-fache im Vergleich zu Lama. Mit zunehmender Batchgröße nimmt die von PowerInfer bereitgestellte Beschleunigung ab. Doch selbst wenn die Stapelgröße auf 32 eingestellt ist, sorgt PowerInfer immer noch für eine beträchtliche Geschwindigkeitssteigerung mehr Inhalt
Das obige ist der detaillierte Inhalt von4090-Generator: Im Vergleich zur A100-Plattform beträgt die Geschwindigkeit der Token-Generierung nur weniger als 18 %, und die Übermittlung an die Inferenz-Engine hat zu heftigen Diskussionen geführt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!