
Heim >Technologie-Peripheriegeräte >KI >NVIDIA schlägt AMD ins Gesicht: Mit Softwareunterstützung ist die KI-Leistung des H100 47 % schneller als die des MI300X!
NVIDIA schlägt AMD ins Gesicht: Mit Softwareunterstützung ist die KI-Leistung des H100 47 % schneller als die des MI300X!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-12-15 18:15:121421Durchsuche

Laut Nachrichten vom 14. Dezember hat AMD Anfang dieses Monats seinen leistungsstärksten KI-Chip, Instinct MI300X, auf den Markt gebracht. Die KI-Leistung seines 8-GPU-Servers ist 60 % höher als die des NVIDIA H100 8-GPU. In diesem Zusammenhang hat NVIDIA kürzlich eine Reihe der neuesten Leistungsvergleichsdaten zwischen H100 und MI300X veröffentlicht, die zeigen, wie H100 mit der richtigen Software eine schnellere KI-Leistung als MI300X bieten kann.
Laut zuvor von AMD veröffentlichten Daten hat die FP8/FP16-Leistung des MI300X das 1,3-fache der Leistung von NVIDIA H100 erreicht, und die Geschwindigkeit der Ausführung der Modelle Llama 2 70B und FlashAttention 2 ist 20 % schneller als die von H100. Auf dem 8v8-Server ist MI300X beim Betrieb des Llama 2 70B-Modells 40 % schneller als H100; beim Betrieb des Bloom 176B-Modells ist MI300X 60 % schneller als H100.
Es sollte jedoch darauf hingewiesen werden, dass AMD beim Vergleich von MI300X mit NVIDIA H100 die Optimierungsbibliothek in der neuesten ROCm 6.0-Suite verwendet hat (die die neuesten Computerformate wie FP16, Bf16 und FP8, einschließlich Sparsity usw., unterstützen kann). ), um diese Zahlen zu erhalten. Im Gegensatz dazu wurde der NVIDIA H100 nicht ohne den Einsatz von Optimierungssoftware wie NVIDIAs TensorRT-LLM getestet.
AMDs implizite Aussage zum NVIDIA H100-Test zeigt, dass die Llama 2 70B-Abfrage bei Verwendung der Inferenzsoftware vLLM v.02.2.2 und des NVIDIA DGX H100-Systems eine Eingabesequenzlänge von 2048 und eine Ausgabesequenzlänge von 128 hat
Die neuesten von NVIDIA veröffentlichten Testergebnisse für DGX H100 (mit 8 NVIDIA H100 Tensor Core GPUs, mit 80 GB HBM3) zeigen, dass die öffentliche NVIDIA TensorRT LLM-Software verwendet wird, von der v0.5.0 für Batch-1-Tests verwendet wird, v0 .6.1 für Latenzschwellenmessungen. Die Workload-Details des Tests sind die gleichen wie beim vorherigen AMD-Test
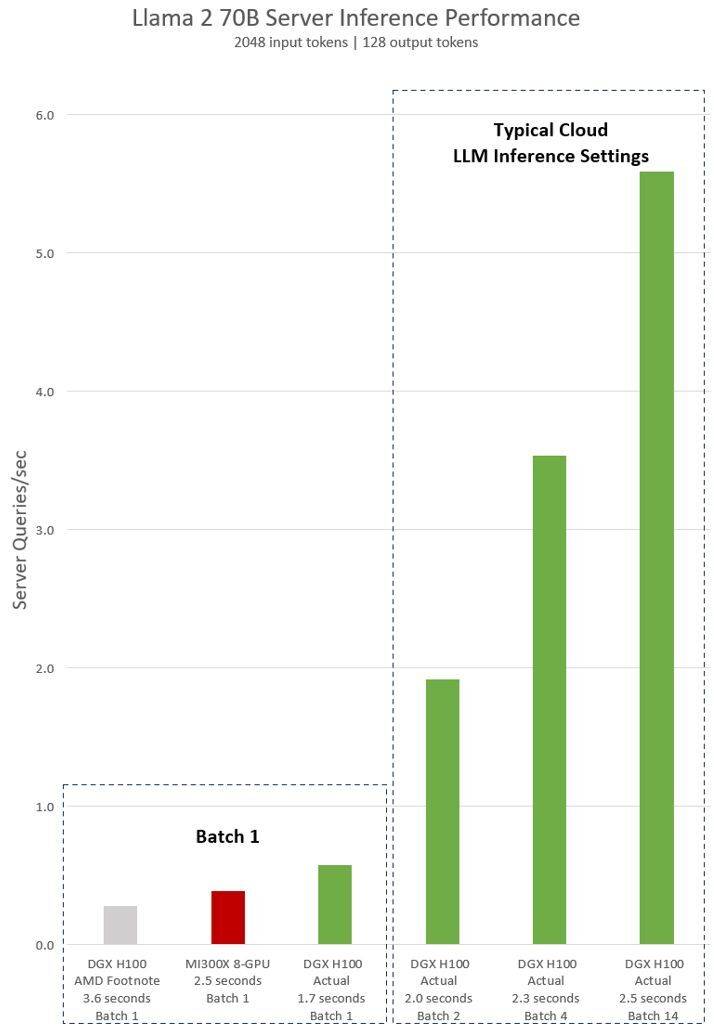
Den Ergebnissen zufolge hat sich die Leistung des NVIDIA DGX H100-Servers nach Verwendung optimierter Software um mehr als das Doppelte erhöht und ist 47 % schneller als der von AMD demonstrierte MI300X 8-GPU-Server
DGX H100 kann eine einzelne Inferenzaufgabe in 1,7 Sekunden bewältigen. Um die Antwortzeit und den Durchsatz des Rechenzentrums zu optimieren, legen Cloud-Dienste feste Antwortzeiten für bestimmte Dienste fest. Dadurch können sie mehrere Inferenzanfragen zu größeren „Batches“ zusammenfassen und so die Gesamtzahl der Inferenzen pro Sekunde auf dem Server erhöhen. Auch Branchenstandard-Benchmarks wie MLPerf verwenden diese feste Reaktionszeitmetrik, um die Leistung zu messen
Leichte Kompromisse bei der Antwortzeit können zu Unsicherheit hinsichtlich der Anzahl der Inferenzanfragen führen, die der Server in Echtzeit verarbeiten kann. Mit einem festen Antwortzeitbudget von 2,5 Sekunden kann der NVIDIA DGX H100-Server mehr als 5 Llama 2 70B-Inferenzen pro Sekunde verarbeiten, während Batch-1 weniger als eine pro Sekunde verarbeitet.
Natürlich ist es für Nvidia relativ fair, diese neuen Benchmarks zu verwenden. Schließlich nutzt AMD seine optimierte Software auch, um die Leistung seiner GPUs zu bewerten. Warum also nicht dasselbe tun, wenn man den Nvidia H100 testet?
Sie müssen wissen, dass sich der Software-Stack von NVIDIA um das CUDA-Ökosystem dreht und nach Jahren harter Arbeit und Entwicklung eine sehr starke Position auf dem Markt für künstliche Intelligenz einnimmt, während AMDs ROCm 6.0 neu ist und noch nicht in realen Szenarien getestet wurde.
Nach zuvor von AMD veröffentlichten Informationen hat AMD einen Großteil der Vereinbarung mit großen Unternehmen wie Microsoft und Meta getroffen, die ihre MI300X-GPU als Ersatz für Nvidias H100-Lösung betrachten.
AMDs neuester Instinct MI300X wird voraussichtlich in der ersten Hälfte des Jahres 2024 in großen Stückzahlen ausgeliefert. Bis dahin wird jedoch auch NVIDIAs stärkere H200-GPU ausgeliefert, und NVIDIA wird in der zweiten Hälfte des Jahres 2024 auch eine neue Generation des Blackwell B100 auf den Markt bringen . Darüber hinaus wird Intel auch seinen KI-Chip Gaudi 3 der neuen Generation auf den Markt bringen. Als nächstes scheint der Wettbewerb im Bereich der künstlichen Intelligenz intensiver zu werden.
Herausgeber: Xinzhixun-Ruruuni Sword
Das obige ist der detaillierte Inhalt vonNVIDIA schlägt AMD ins Gesicht: Mit Softwareunterstützung ist die KI-Leistung des H100 47 % schneller als die des MI300X!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Die besten 5+ CPUs für Windows 11, welche [AMD/Intel]-Prozessoren sollten Sie wählen?
- Apple Mac Pro wird von der AMD Radeon Pro W6600X GPU angetrieben, die mit 2048 Stream-Prozessoren und 8 GB Speicher ausgestattet ist
- Fix: Fehler „AMD-Grafiktreiber nicht installiert' in Windows 11
- AMD plant, im Jahr 2024 die neuen Prozessoren der Ryzen 8000-Serie auf den Markt zu bringen, ein riesiges Upgrade, angeführt von der Zen5-Architektur