
Heim >Technologie-Peripheriegeräte >KI >Schalten Sie GPT-4 und Claude2.1 frei: In einem Satz können Sie die wahre Leistungsfähigkeit von über 100.000 kontextgroßen Modellen erkennen und die Punktzahl von 27 auf 98 erhöhen
Schalten Sie GPT-4 und Claude2.1 frei: In einem Satz können Sie die wahre Leistungsfähigkeit von über 100.000 kontextgroßen Modellen erkennen und die Punktzahl von 27 auf 98 erhöhen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-12-15 11:37:37827Durchsuche
Jeder große Modellhersteller hat das Kontextfenster aufgerollt. Die Standardkonfiguration von Llama-1 war immer noch 2.000, aber jetzt sind diejenigen mit weniger als 100.000 zu peinlich, um rauszugehen.
Ein extremer Test von Goose ergab jedoch, dass die meisten Menschen es falsch verwenden und nicht die erforderliche Kraft der KI einsetzen.
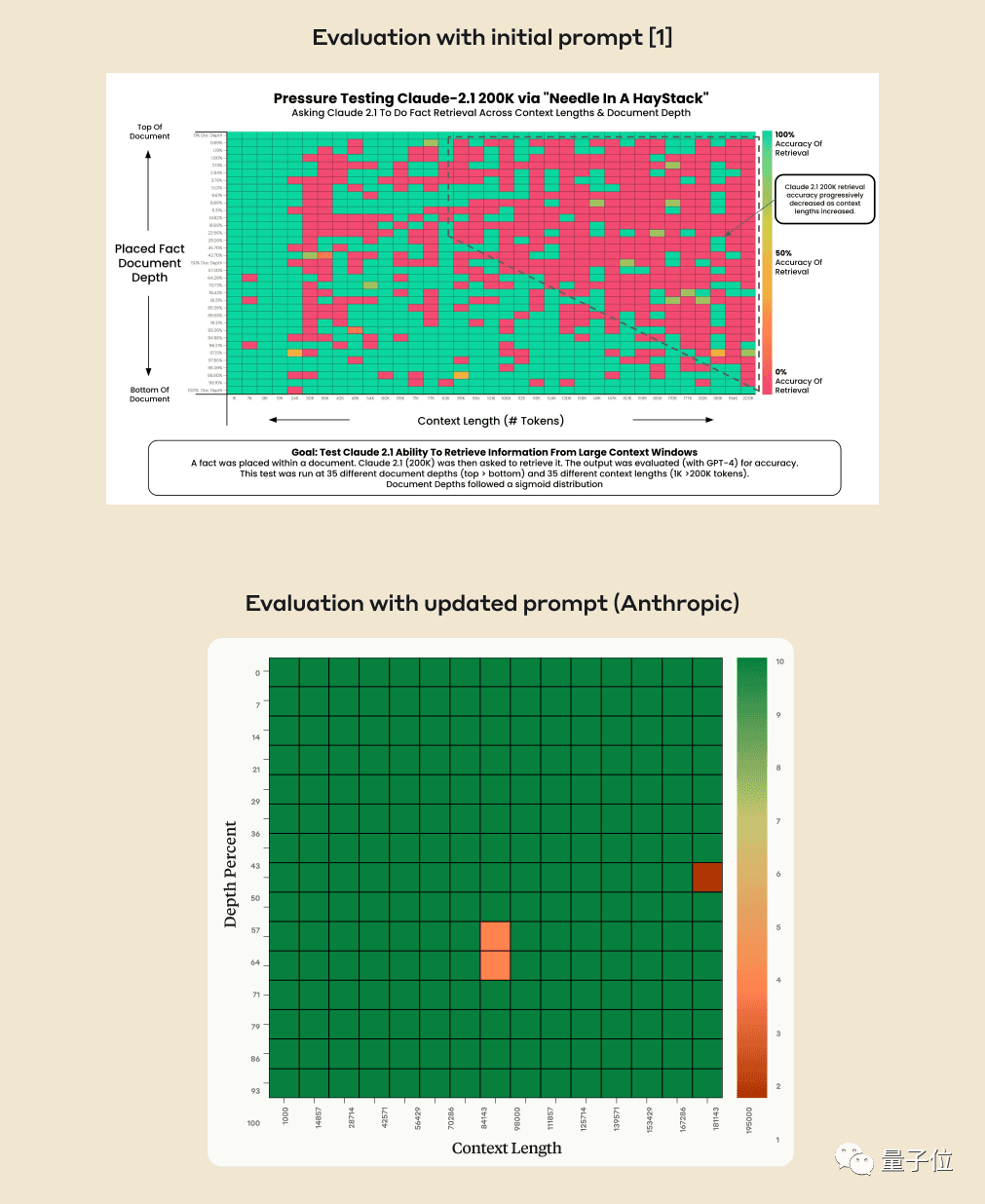
Kann KI aus Hunderttausenden Wörtern wirklich genau Schlüsselfakten finden? Je rötlicher die Farbe, desto mehr Fehler macht die KI.
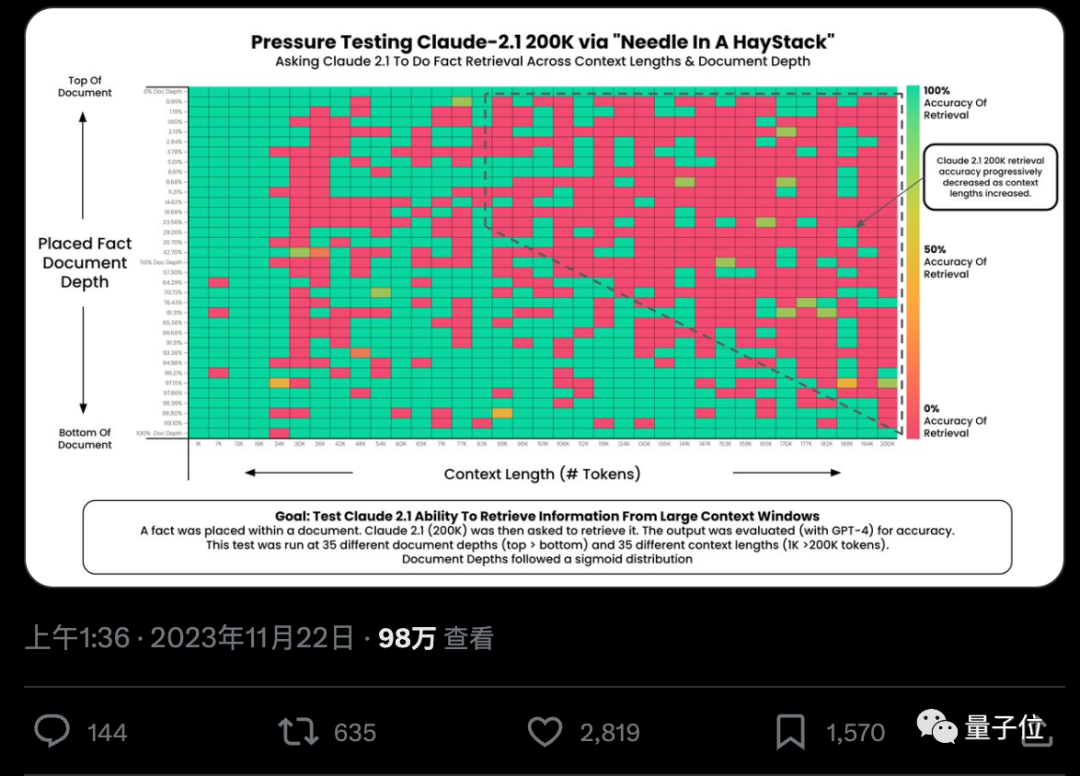
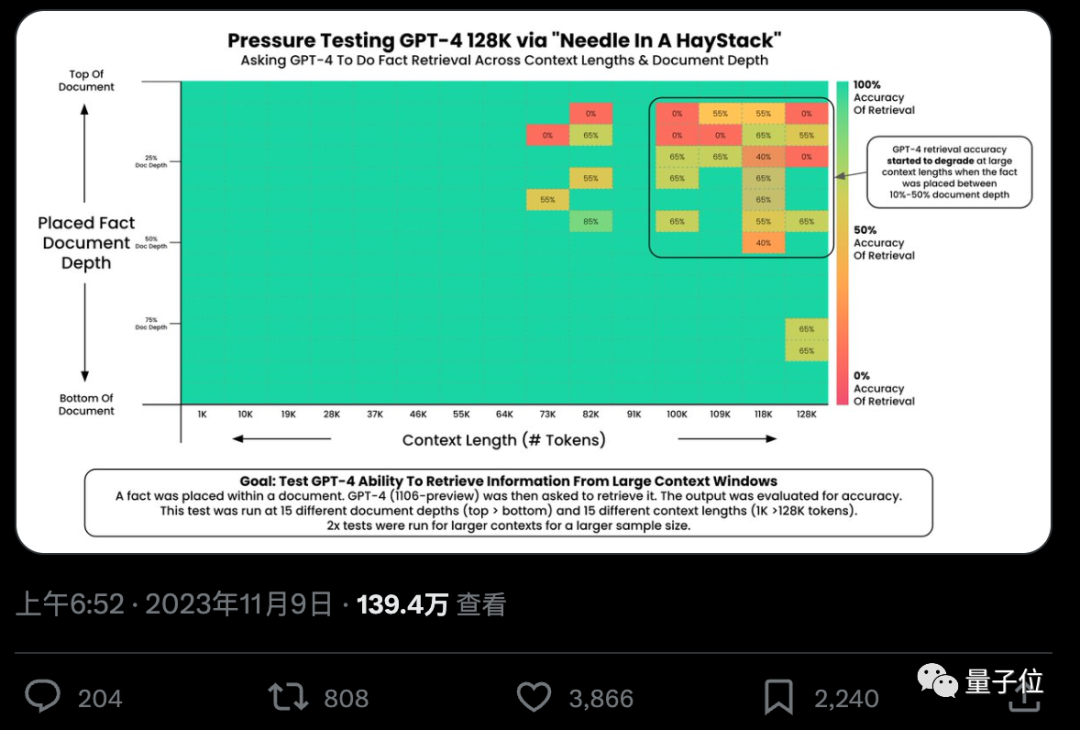
Standardmäßig sind GPT-4-128k und die neuesten veröffentlichten Claude2.1-200k-Ergebnisse nicht ideal.
Aber nachdem Claudes Team die Situation verstanden hatte, fanden sie eine supereinfache Lösung: Sie fügten einen Satz hinzu, um die Punktzahl direkt von 27 % auf 98 % zu verbessern.
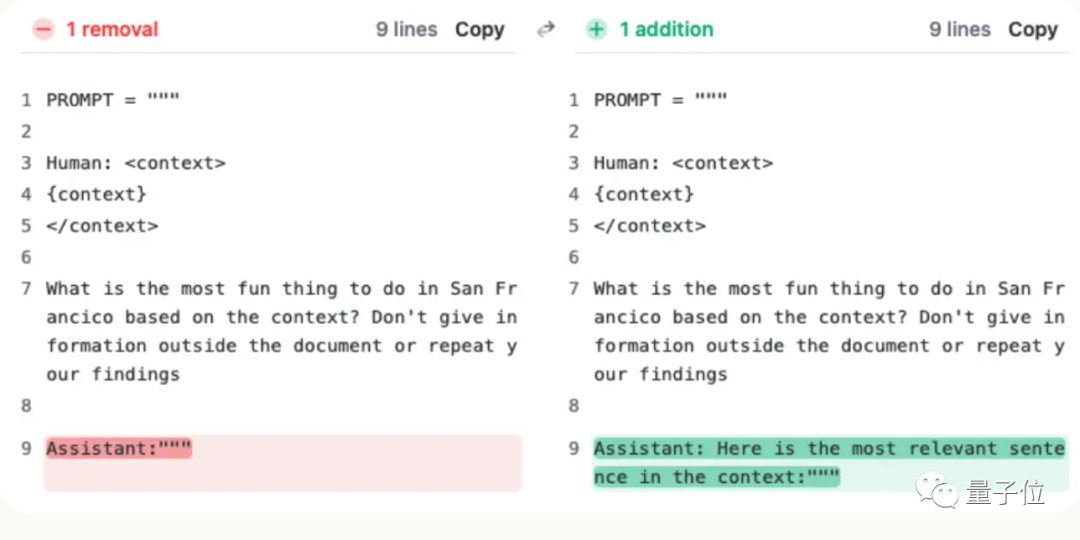
Es ist nur so, dass dieser Satz nicht zur Frage des Benutzers hinzugefügt wird, sondern die KI am Anfang der Antwort gesagt hat:
„Hier ist der relevanteste Satz im Kontext:“
(Das ist der relevanteste Satz im Kontext:)
Lass das große Model die Nadel im Heuhaufen finden
Für diesen Test hat der Autor Greg Kamradt mindestens 150 US-Dollar seines eigenen Geldes ausgegeben.
Beim Testen von Claude 2.1 stellte Anthropic ihm ein kostenloses Kontingent zur Verfügung
Tatsächlich ist die Testmethode nicht kompliziert Blogbeiträge des YC-Gründers Paul Graham als Testdaten.
Fügen Sie bestimmte Sätze an verschiedenen Stellen im Dokument hinzu: Das Beste an San Francisco ist, an einem sonnigen Tag im Dolores Park zu sitzen und ein Sandwich zu genießen.
Bitte verwenden Sie den bereitgestellten Kontext, um die Frage zu beantworten, in verschiedenen Kontextlängen und Dokumenten An verschiedenen Orten hinzugefügt, wurden GPT-4 und Claude2.1 wiederholt getestet Nadel im Heuhaufen“ und stellte den Code als Open Source auf GitHub zur Verfügung, der mehr als 200 Sterne erhalten hat, und enthüllte, dass ein Unternehmen die Tests des nächsten großen Modells gesponsert hat.

Das KI-Unternehmen hat selbst eine Lösung gefunden
Einige Wochen später stellte das Unternehmen hinter Claude
Anthropic
Zu diesem Zeitpunkt müssen Sie Folgendes verwenden Einige Mittel, um an der KI vorbeizukommen und Claude zu bitten, am Anfang der Antwort den Satz „Hier ist der relevanteste Satz im Kontext:“ hinzuzufügen, können gelöst werden.
 Die Verwendung dieser Methode kann Claudes Leistung verbessern, selbst wenn nach Sätzen gesucht wird, die nicht künstlich zum Originaltext hinzugefügt wurden.
Die Verwendung dieser Methode kann Claudes Leistung verbessern, selbst wenn nach Sätzen gesucht wird, die nicht künstlich zum Originaltext hinzugefügt wurden.
 Anthropic sagte, dass es Claude in Zukunft weiter trainieren wird, um ihn leistungsfähiger zu machen an solche Aufgaben angepasst.
Anthropic sagte, dass es Claude in Zukunft weiter trainieren wird, um ihn leistungsfähiger zu machen an solche Aufgaben angepasst.
Wenn Sie die API verwenden, bitten Sie die KI, mit einem bestimmten Anfang zu antworten, und sie kann auch andere clevere Verwendungsmöglichkeiten haben
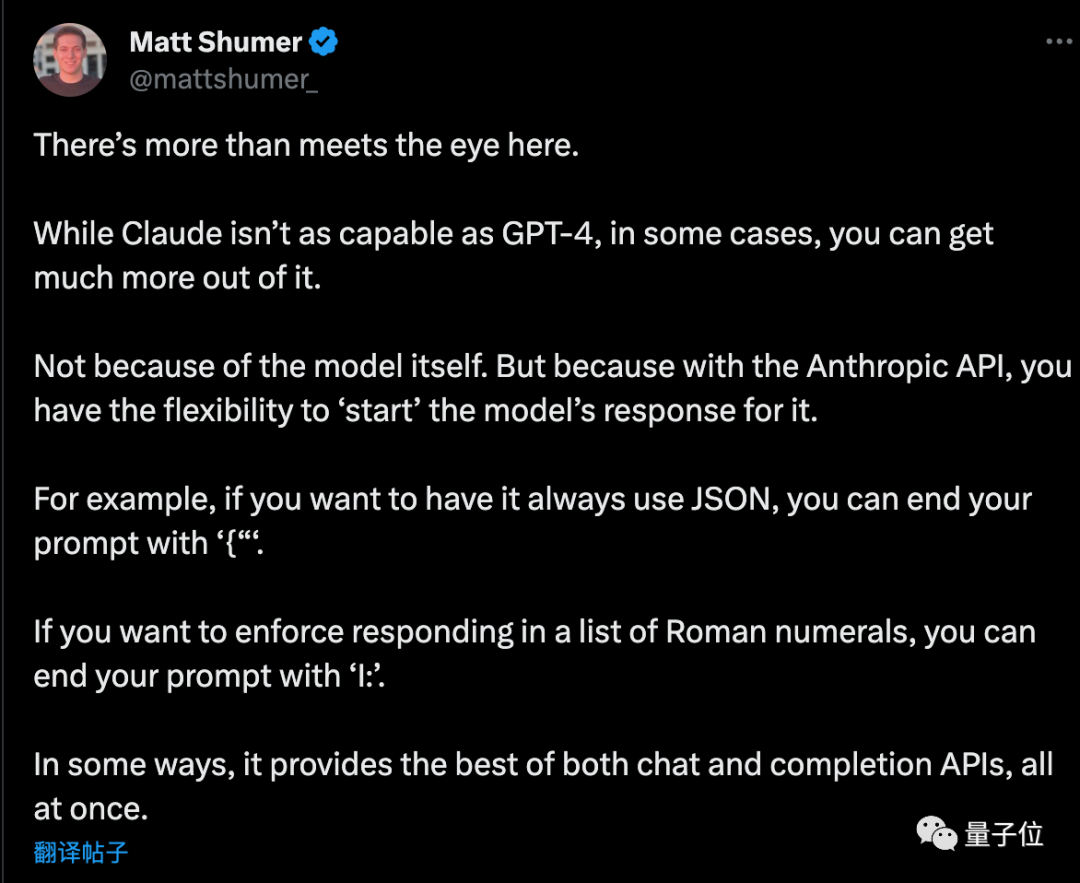
Matt Shumer, ein Unternehmer, gab nach dem Lesen des Plans einige zusätzliche Tipps 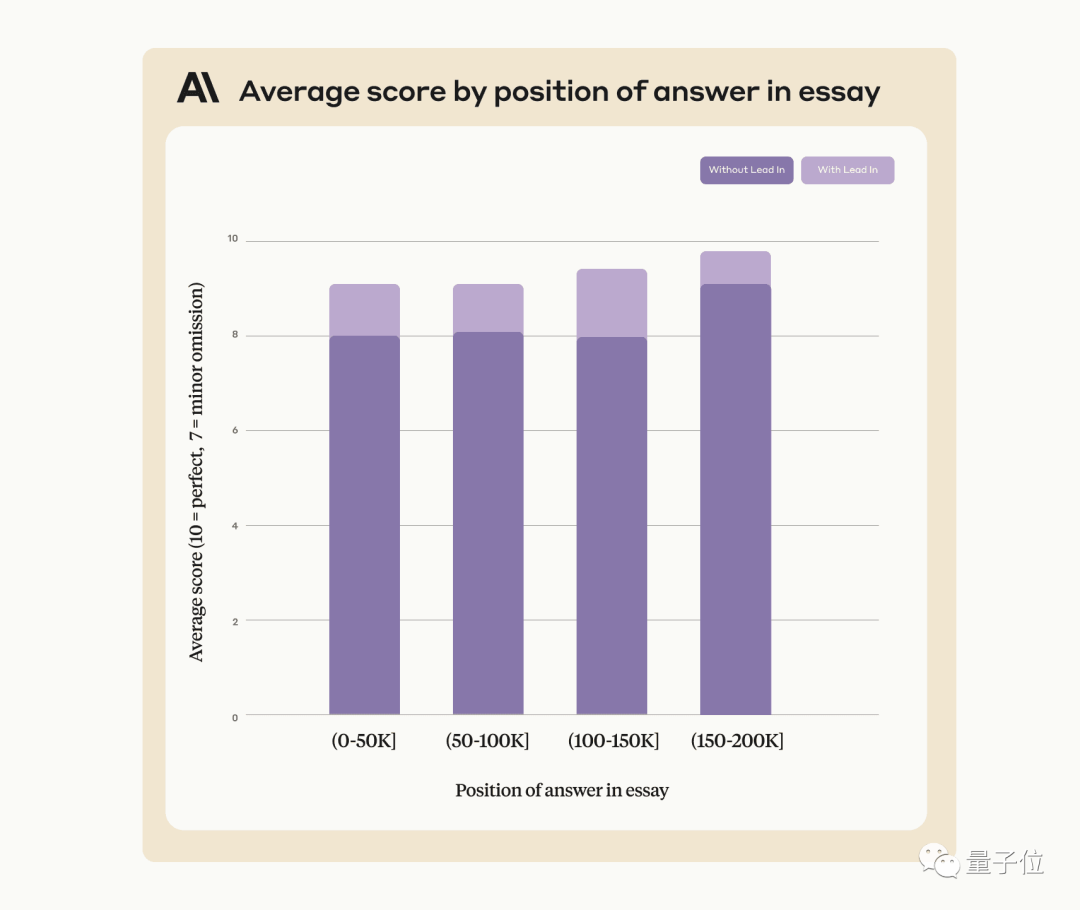
Wenn Sie möchten, dass AI das reine JSON-Format ausgibt, endet das Eingabeaufforderungswort mit „{“. Wenn Sie möchten, dass die KI römische Ziffern auflistet, kann das Eingabeaufforderungswort auf die gleiche Weise mit „I:“ enden.
Aber es ist noch nicht vorbei ...
Große inländische Unternehmen haben diesen Test ebenfalls bemerkt und begonnen zu prüfen, ob ihre eigenen großen Modelle bestehen können
auch ultralange Kontexte haben Das Dark Side of the Moon Kimi-Großmodell -Team erkannte ebenfalls Probleme, lieferte jedoch unterschiedliche Lösungen und erzielte gute Ergebnisse.

Ohne die ursprüngliche Bedeutung zu ändern, muss der Inhalt wie folgt neu geschrieben werden: Dies hat den Vorteil, dass es einfacher ist, die Eingabeaufforderung für Benutzerfragen zu ändern, als die KI zu bitten, der Antwort einen Satz hinzuzufügen. insbesondere wenn die API nicht direkt aufgerufen wird
Ich habe eine neue Methode verwendet, um GPT-4 und Claude2.1 auf der anderen Seite des Mondes zu testen, und die Ergebnisse zeigten, dass GPT-4 erhebliche Verbesserungen erzielte. Während Claude2.1 nur eine geringfügige Verbesserung aufweist
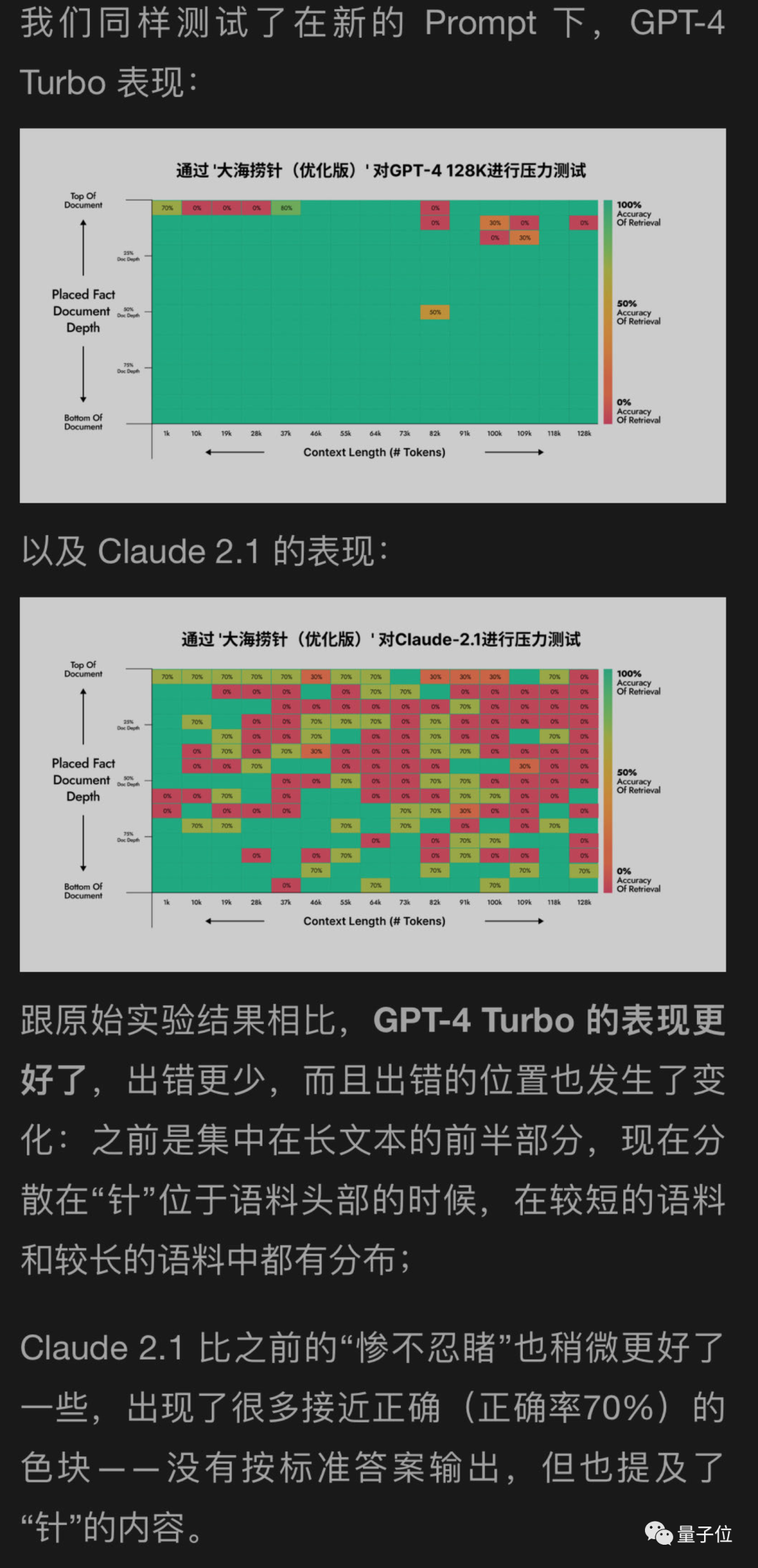
Es scheint, dass dieses Experiment selbst bestimmte Einschränkungen aufweist, die möglicherweise mit ihrer eigenen Verfassungs-KI zusammenhängen. Es ist besser, die von Claude2.1 bereitgestellte Methode zu verwenden Anthropisch selbst.
Später führten Ingenieure auf der anderen Seite des Mondes weitere Experimente durch, und eines der Experimente war tatsächlich ...

Ups, ich habe mich in Testdaten verwandelt
Das obige ist der detaillierte Inhalt vonSchalten Sie GPT-4 und Claude2.1 frei: In einem Satz können Sie die wahre Leistungsfähigkeit von über 100.000 kontextgroßen Modellen erkennen und die Punktzahl von 27 auf 98 erhöhen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So vergleichen Sie die Ähnlichkeiten und Unterschiede zwischen zwei Datenspalten in Excel
- So vergleichen Sie doppelte Daten zwischen zwei Arbeitsblättern
- Was sind die acht grundlegenden Datentypen?
- Musk kündigt an, dass er Microsoft wegen der Verwendung von Twitter-Daten zum Trainieren künstlicher Intelligenz verklagen wird
- Die erste behördliche Überprüfung von ChatGPT stammt möglicherweise von der US-amerikanischen Federal Trade Commission, OpenAI: noch nicht trainiertes GPT5