In Videogenerierungsszenarien hat sich die Verwendung von Transformer als rauschunterdrückendes Rückgrat des Diffusionsmodells von Forschern wie Li Feifei als machbar erwiesen. Dies kann als großer Erfolg für Transformer im Bereich der Videogenerierung gewertet werden.
Kürzlich hat eine Studie zur Videogeneration viel Lob erhalten und wurde von einem X-Internetnutzer sogar als „das Ende von Hollywood“ bewertet. Ist es wirklich so gut? Werfen wir zunächst einen Blick auf die Wirkung: 
Offensichtlich weisen diese Videos nicht nur fast keine Artefakte auf, sondern sind auch sehr kohärent und voller Details. Selbst wenn man einem Blockbuster-Film ein paar Frames hinzufügt, wird er offensichtlich nicht inkonsistent sein. Der Autor dieser Videos ist der Window Attention Latent Transformer, der von Forschern der Stanford University, Google und dem Georgia Institute of Technology vorgeschlagen wurde, also der Window Attention Latent Transformer, der als W.A.L.T bezeichnet wird. Diese Methode integriert die Transformer-Architektur erfolgreich in das Latent-Video-Diffusionsmodell. Professor Li Feifei von der Stanford University ist ebenfalls einer der Autoren des Papiers.
- Projektwebsite: https://walt-video-diffusion.github.io/
-
Papieradresse: https://walt-video-diffusion.github.io/assets/W.A.L.T.pdf
Zuvor hatte die Transformer-Architektur in vielen verschiedenen Bereichen große Erfolge erzielt, der Bereich der generativen Bild- und Videomodellierung bildet jedoch eine Ausnahme. Das vorherrschende Paradigma in diesem Bereich ist das Diffusionsmodell. Im Bereich der Bild- und Videogenerierung ist das Diffusionsmodell zum Hauptparadigma geworden. Unter allen Videoverbreitungsmethoden ist jedoch die U-Net-Architektur das dominierende Backbone-Netzwerk, die aus einer Reihe von Faltungs- und Selbstaufmerksamkeitsschichten besteht. U-Net wird bevorzugt, da der Speicherbedarf des Vollaufmerksamkeitsmechanismus in Transformer quadratisch mit der Länge der Eingabesequenz wächst. Bei der Verarbeitung hochdimensionaler Signale wie Videos führt dieses Wachstumsmuster zu sehr hohen Rechenkosten. Das latente Diffusionsmodell (LDM) arbeitet in einem niedrigerdimensionalen latenten Raum, der von Autoencodern abgeleitet wird, wodurch der Rechenaufwand reduziert wird. In diesem Fall ist die Art des latenten Raums eine wichtige Designentscheidung: Raumkomprimierung versus Raum-Zeit-Komprimierung. Menschen bevorzugen oft die räumliche Komprimierung, weil sie die Verwendung vorab trainierter Bild-Autoencoder und LDMs ermöglicht, die anhand großer gepaarter Bild-Text-Datensätze trainiert werden. Die Wahl der räumlichen Komprimierung erhöht jedoch die Netzwerkkomplexität und erschwert die Verwendung von Transformer als Netzwerk-Backbone (aufgrund von Speicherbeschränkungen), insbesondere bei der Erstellung hochauflösender Videos. Andererseits kann die räumlich-zeitliche Komprimierung diese Probleme zwar lindern, ist jedoch nicht für die Arbeit mit gepaarten Bild-Text-Datensätzen geeignet, die tendenziell größer und vielfältiger sind als Video-Text-Datensätze. W.A.L.T ist eine Transformer-Methode für das Latent Video Diffusion Model (LVDM). Diese Methode besteht aus zwei Schritten. In der ersten Phase wird ein Autoencoder verwendet, um das Video und das Bild in einen einheitlichen, niedrigdimensionalen latenten Raum abzubilden. Dadurch kann ein einziges generatives Modell gemeinsam auf Bild- und Videodatensätze trainiert werden und der Rechenaufwand für die Generierung hochauflösender Videos erheblich reduziert werden. Für die zweite Phase entwarf das Team einen neuen Transformer-Block für latente Videodiffusionsmodelle, der aus Selbstaufmerksamkeitsschichten besteht, die in nicht überlappenden, fensterbeschränkten Räumen und zeitlichen Wechseln zwischen Aufmerksamkeit arbeiten. Es gibt zwei Hauptvorteile dieses Designs: Erstens nutzt es die lokale Fensteraufmerksamkeit, wodurch der Rechenaufwand erheblich reduziert werden kann. Zweitens erleichtert es das gemeinsame Training, bei dem die räumliche Ebene Bilder und Videobilder unabhängig voneinander verarbeiten kann, während die raumzeitliche Ebene zur Modellierung zeitlicher Beziehungen in Videos verwendet wird. Obwohl konzeptionell einfach, ist diese Studie die erste, die experimentell die überlegene Erzeugungsqualität und Parametereffizienz von Transformer bei der Verbreitung latenter Videos anhand eines öffentlichen Benchmarks demonstriert. Um die Skalierbarkeit und Effizienz der neuen Methode zu demonstrieren, experimentierte das Team schließlich auch mit der schwierigen Aufgabe der fotorealistischen Bild-zu-Video-Generierung. Sie trainierten drei kaskadierte Modelle. Dazu gehören ein grundlegendes latentes Videodiffusionsmodell und zwei Video-Superauflösungsdiffusionsmodelle. Das Ergebnis ist ein Video mit einer Auflösung von 512×896 bei 8 Bildern pro Sekunde. Dieser Ansatz erreicht modernste Zero-Shot-FVD-Werte beim UCF-101-Benchmark.
Darüber hinaus kann dieses Modell verwendet werden, um Videos mit konsistenter 3D-Kamerabewegung zu generieren.
Im Bereich der generativen Modellierung von Videos ist die Wahl der latenten Raumdarstellung eine wichtige Designentscheidung. Idealerweise möchten wir eine gemeinsame und einheitliche komprimierte visuelle Darstellung haben, die für die generative Modellierung von Bildern und Videos verwendet werden kann. Konkret besteht das Ziel bei einer gegebenen Videosequenz x darin, eine niedrigdimensionale Darstellung z zu lernen, die eine räumlich-zeitliche Komprimierung in einem bestimmten zeitlichen und räumlichen Maßstab durchführt. Um eine einheitliche Darstellung von Video und Standbildern zu erhalten, ist es immer notwendig, das erste Bild des Videos getrennt von den übrigen Bildern zu kodieren. Dadurch können Sie Standbilder so behandeln, als wären sie nur ein Videobild. Basierend auf dieser Idee nutzt das eigentliche Design des Teams die kausale 3D-CNN-Encoder-Decoder-Architektur des MAGVIT-v2-Tokenizers. Nach dieser Phase wird die Eingabe in das Modell zu einem Stapel latenter Tensoren, die ein einzelnes Video oder einen Stapel diskreter Bilder darstellen (Abbildung 2). Und die implizite Darstellung hier ist realwertig und nicht quantisiert. Lernen Sie, Bilder und Videos zu generieren Patchify (Patchify). Dem ursprünglichen ViT-Design folgend, kachelte das Team jeden verborgenen Rahmen einzeln, indem es ihn in eine Folge nicht überlappender Kacheln umwandelte. Sie verwendeten auch lernbare Positionseinbettungen, die die Summe der räumlichen und zeitlichen Positionseinbettungen darstellen. Die Positionseinbettung wird zur linearen Projektion der Kachel hinzugefügt. Beachten Sie, dass Sie für Bilder einfach die Einbettung der zeitlichen Position hinzufügen, die dem ersten ausgeblendeten Frame entspricht. Fensteraufmerksamkeit. Transformer-Modelle, die vollständig aus globalen Selbstaufmerksamkeitsmodulen bestehen, sind rechen- und speicherintensiv, insbesondere für Videoaufgaben. Für eine effizientere und gemeinsame Verarbeitung von Bildern und Videos berechnet das Team die Selbstaufmerksamkeit auf Fensterbasis basierend auf zwei Arten nicht überlappender Konfigurationen: Raum (S) und Raum-Zeit (ST), siehe Abbildung 2. Die Aufmerksamkeit des räumlichen Fensters (SW) konzentriert sich auf alle Token innerhalb eines verborgenen Rahmens. SW modelliert räumliche Beziehungen in Bildern und Videos. Der Umfang der Aufmerksamkeit des spatiotemporalen Fensters (STW) ist ein 3D-Fenster, das die zeitliche Beziehung zwischen verborgenen Bildern des Videos modelliert. Schließlich verwendeten sie zusätzlich zur absoluten Positionseinbettung auch die relative Positionseinbettung. Berichten zufolge ist dieses Design zwar einfach, aber äußerst recheneffizient und kann gemeinsam an Bild- und Videodatensätzen trainiert werden. Im Gegensatz zu Methoden, die auf Autoencodern auf Bildebene basieren, erzeugt die neue Methode keine flackernden Artefakte, ein häufiges Problem bei Methoden, die Videobilder separat kodieren und dekodieren. ° oder ein Video mit niedriger Auflösung. Im neu vorgeschlagenen Transformer-Backbone-Netzwerk integrierte das Team drei Arten von bedingten Mechanismen, wie unten beschrieben: Queraufmerksamkeit. Zusätzlich zur Verwendung von Selbstaufmerksamkeitsebenen in Transformer-Blöcken mit Fenstern fügten sie auch Queraufmerksamkeitsebenen für die Generierung von Textbedingungen hinzu. Wenn das Modell nur mit Videos trainiert wird, verwendet die Queraufmerksamkeitsschicht dieselbe fensterbeschränkte Aufmerksamkeit wie die Selbstaufmerksamkeitsschicht, was bedeutet, dass S/ST über eine SW/STW-Queraufmerksamkeitsschicht verfügt (Abbildung 2). Für das gemeinsame Training wird jedoch nur die SW-Cross-Attention-Schicht verwendet. Für die gegenseitige Aufmerksamkeit besteht der Ansatz des Teams darin, Eingabesignale (Abfragen) und bedingte Signale (Schlüssel, Wert) zu verketten. AdaLN-LoRA. Adaptive Normalisierungsschichten sind wichtige Komponenten in vielen generativen und visuellen Synthesemodellen. Um adaptive Normalisierungsschichten zu integrieren, besteht ein einfacher Ansatz darin, für jede Schicht i eine MLP-Schicht einzuschließen, die auf den Vektor der bedingten Parameter zurückgeht. Die Anzahl der Parameter für diese zusätzlichen MLP-Schichten wächst linear mit der Anzahl der Schichten und quadratisch mit der Modelldimensionalität. Inspiriert von LoRA schlugen Forscher eine einfache Lösung zur Reduzierung der Modellparameter vor: AdaLN-LoRA.
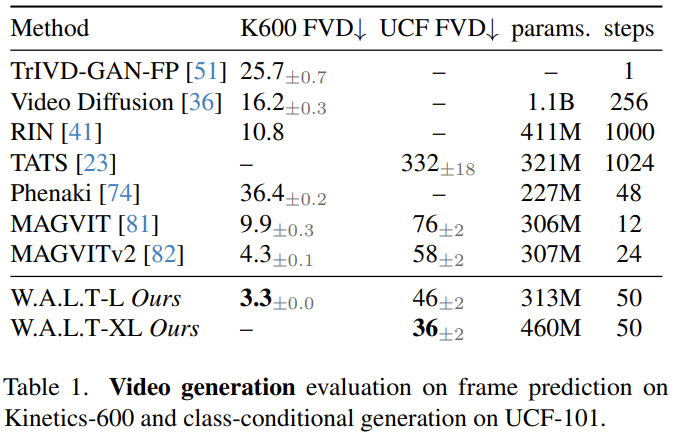
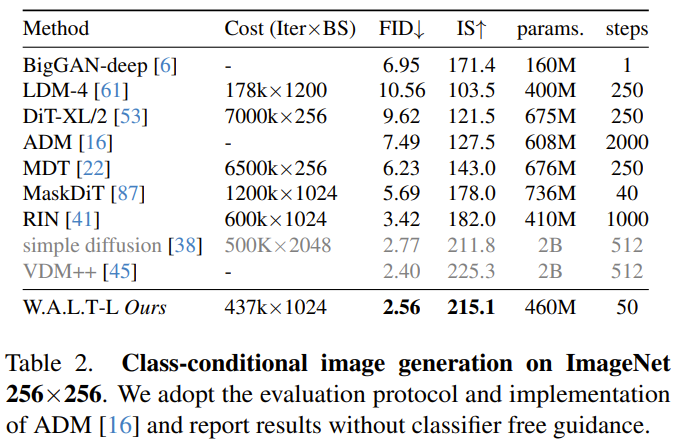
Selbstkonditionierung. Neben der Konditionierung durch externe Eingaben können iterative Generierungsalgorithmen auch durch Stichproben konditioniert werden, die sie während der Inferenz generieren. Insbesondere haben Chen et al. den Trainingsprozess des Diffusionsmodells in der Arbeit „Analog Bits: Generating Discrete Data Using Diffusion Models with Self-Conditioning“ so modifiziert, dass das Modell eine Stichprobe mit einer bestimmten Wahrscheinlichkeit p_sc generiert und dann darauf basiert Verwenden Sie für die erste Stichprobe einen weiteren Vorwärtsdurchlauf, um diese Schätzung zu verfeinern. Es besteht auch eine gewisse Wahrscheinlichkeit, dass 1-p_sc nur einen Vorwärtsdurchlauf abschließt.Das Team verkettete diese Modellschätzung mit der Eingabe entlang der Kanaldimension und stellte fest, dass diese einfache Technik in Kombination mit der V-Vorhersage gut funktionierte.
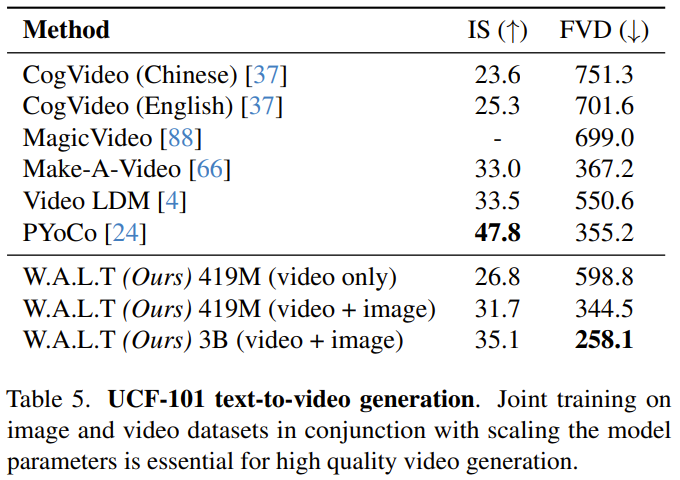
Autoregressive GenerierungUm lange Videos durch autoregressive Vorhersage zu generieren, trainierte das Team das Modell auch gemeinsam für die Frame-Vorhersageaufgabe. Dies wird erreicht, indem dem Modell während des Trainingsprozesses eine bestimmte Wahrscheinlichkeit p_fp zugewiesen wird, die auf früheren Frames basiert. Die Bedingung ist entweder 1 versteckter Frame (Bild-zu-Video-Generierung) oder 2 versteckte Frames (Videovorhersage). Diese Bedingung wird durch Kanaldimensionen entlang der verrauschten impliziten Eingabe in das Modell integriert. Während der Inferenz wird standardmäßiges klassifikatorfreies Bootstrapping verwendet, mit c_fp als bedingtem Signal. Der Rechenaufwand für die Verwendung eines einzelnen Modells zur Generierung hochauflösender Videos ist sehr hoch und grundsätzlich schwer zu erreichen. Die Forscher beziehen sich auf den Artikel „Cascaded diffusion models for high fidelity image generation“ und verwenden eine Kaskadenmethode zur Kaskadierung der drei Modelle, wobei sie mit immer höheren Auflösungen arbeiten. Das Basismodell generiert Videos mit einer Auflösung von 128×128, die dann zweimal durch zwei Superauflösungsstufen hochgesampelt werden. Die Eingabe mit niedriger Auflösung (Video oder Bild) wird zunächst mithilfe einer Tiefen-zu-Raum-Faltungsoperation räumlich hochgesampelt. Beachten Sie, dass die Inferenz im Gegensatz zum Training (wo Ground-Truth-Eingaben mit niedriger Auflösung bereitgestellt werden) auf impliziten Darstellungen beruht, die in vorherigen Phasen generiert wurden. Um diesen Unterschied zu verringern und Artefakte, die in der Stufe mit niedriger Auflösung erzeugt wurden, in der Stufe mit Superauflösung robuster zu verarbeiten, verwendete das Team auch eine rauschbedingte Verbesserung. Feinabstimmung des Seitenverhältnisses. Um das Training zu vereinfachen und mehr Datenquellen mit unterschiedlichen Seitenverhältnissen zu nutzen, verwendeten sie in der Basisphase ein quadratisches Seitenverhältnis. Anschließend optimierten sie das Modell anhand einer Teilmenge der Daten, um mithilfe der Positionseinbettungsinterpolation Videos mit einem Seitenverhältnis von 9:16 zu generieren. Die Forscher bewerteten die neu vorgeschlagene Methode anhand verschiedener Aufgaben: kategoriebedingte Bild- und Videogenerierung, Frame-Vorhersage, textbasierte Videogenerierung. Sie untersuchten auch die Auswirkungen verschiedener Designentscheidungen durch Ablationsstudien. Videogenerierung: Sowohl bei UCF-101- als auch bei Kinetics-600-Datensätzen übertrifft W.A.L.T alle vorherigen Methoden in Bezug auf die FVD-Metrik, siehe Tabelle 1. Bildgenerierung: Tabelle 2 vergleicht die Ergebnisse von W.A.L.T mit anderen aktuell besten Methoden zur Generierung von Bildern mit einer Auflösung von 256×256. Das neu vorgeschlagene Modell übertrifft frühere Methoden und erfordert keine spezielle Planung, Faltungsinduktionsverzerrung, verbesserten Diffusionsverlust und klassifikatorfreie Führung. Obwohl VDM++ einen etwas höheren FID-Score aufweist, verfügt es über viel mehr Modellparameter (2B). Um den Beitrag verschiedener Designentscheidungen zu verstehen, führte das Team auch eine Ablationsstudie durch. Tabelle 3 zeigt die Ergebnisse der Ablationsstudie in Bezug auf Patchgröße, Fensteraufmerksamkeit, Selbstkonditionierung, AdaLN-LoRA und Autoencoder. Text-zu-Video-Generierung Das Team trainierte gemeinsam die Text-zu-Video-Generierungsfähigkeiten von W.A.L.T für Text-Bild- und Text-Video-Paare. Sie verwendeten einen Datensatz aus dem öffentlichen Internet und internen Quellen, der etwa 970 Millionen Text-Bild-Paare und etwa 89 Millionen Text-Video-Paare enthielt. Die Auflösung des Basismodells (3B) beträgt 17×128×128, und die beiden kaskadierten Superauflösungsmodelle betragen 17×128×224 → 17×256×448 (L, 1,3B, p = 2 ) und 17× 256×448→ 17×512×896 (L, 419M, p = 2). Sie haben auch das Seitenverhältnis in der Basisstufe fein abgestimmt, um Videos mit einer Auflösung von 128 x 224 zu produzieren. Alle Ergebnisse der Text-zu-Video-Generierung verwenden einen klassifikatorfreien Bootstrapping-Ansatz. Unten finden Sie einige generierte Videobeispiele. Weitere Informationen finden Sie auf der Projektwebsite: Text: Ein Eichhörnchen, das einen Burger isst.
Text: Eine Katze, die auf einem Geisterradfahrer durch die Wüste reitet .
Die wissenschaftliche Bewertung der textbasierten Videogenerierung bleibt eine Herausforderung, was teilweise auf das Fehlen standardisierter Trainingsdatensätze und Benchmarks zurückzuführen ist. Bisher konzentrierten sich die Experimente und Analysen der Forscher auf akademische Standard-Benchmarks, die dieselben Trainingsdaten verwenden, um faire Vergleiche zu gewährleisten. Dennoch berichtet das Team zum Vergleich mit früheren Studien zur Text-zu-Video-Generierung über Ergebnisse des UCF-101-Datensatzes in einer Zero-Shot-Bewertungseinstellung. Man erkennt, dass die Vorteile von W.A.L.T offensichtlich sind. Weitere Einzelheiten finden Sie im Originalpapier. Das obige ist der detaillierte Inhalt vonMithilfe von Transformer für das Diffusionsmodell erreichen KI-generierte Videos Fotorealismus. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!