
Heim >Technologie-Peripheriegeräte >KI >Auf dem Mobiltelefon läuft das kleine Modell von Microsoft mit 2,7 Milliarden Parametern besser als das große Modell
Auf dem Mobiltelefon läuft das kleine Modell von Microsoft mit 2,7 Milliarden Parametern besser als das große Modell

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-12-14 22:45:471371Durchsuche
Microsoft-CEO Nadella gab letzten Monat auf der Ignite-Konferenz bekannt, dass das Phi-2-Kleinmodell vollständig Open Source sein wird. Dieser Schritt wird die Leistung des gesunden Menschenverstands, des Sprachverständnisses und des logischen Denkens erheblich verbessern

Heute gab Microsoft weitere Details zum Phi-2-Modell und seiner neuen Eingabeaufforderungstechnologie promptbase bekannt. Dieses Modell mit nur 2,7 Milliarden Parametern übertrifft Llama2 7B, Llama2 13B und Mistral 7B und schließt die Lücke (oder sogar noch besser) mit Llama2 70B bei den meisten Aufgaben zum gesunden Menschenverstand, Sprachverständnis, Mathematik und Codierung.
Gleichzeitig kann der kleine Phi-2 auf mobilen Geräten wie Laptops und Mobiltelefonen ausgeführt werden. Nadella sagte, dass Microsoft sich sehr darüber freue, sein erstklassiges Small Language Model (SLM) und seine SOTA-Prompt-Technologie mit F&E-Entwicklern zu teilen.
Microsoft veröffentlichte im Juni dieses Jahres einen Artikel mit dem Titel „Just a Textbook“, in dem Daten in „Lehrbuchqualität“ mit nur 7B-Markern verwendet wurden, um ein Modell mit 1,3B-Parametern, nämlich Phi-1, zu trainieren. Obwohl phi-1 über Datensätze und Modellgrößen verfügt, die um Größenordnungen kleiner sind als die der Konkurrenz, erreicht es beim ersten Versuch eine Erfolgsquote von 50,6 % bei HumanEval und eine Genauigkeit von 55,5 % bei MBPP. Phi-1 hat bewiesen, dass selbst hochwertige „kleine Daten“ zu einer guten Leistung des Modells führen können
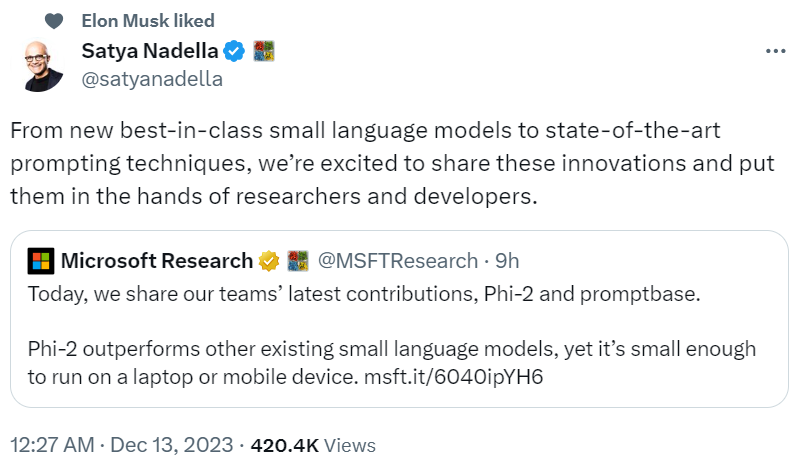
Microsoft veröffentlichte daraufhin im September „Just a Textbook II: Phi-1.5 Technical Report“, der sich auf hochwertiges Potenzial konzentrierte von „Small Data“ wird weiter untersucht. Der Artikel schlägt Phi-1.5 vor, das für QA-Fragen und Antworten, Codierung und andere Szenarien geeignet ist und eine Skala von 1,3 Milliarden erreichen kann. Heutzutage verwendet Phi-2 mit 2,7 Milliarden Parametern erneut einen „kleinen Körper“, um bereitzustellen Hervorragende Argumentations- und Sprachverständnisfähigkeiten, die die SOTA-Leistung in grundlegenden Sprachmodellen unter 13 Milliarden Parametern demonstrieren. Dank Innovationen in der Modellskalierung und dem Trainingsdatenmanagement erreicht Phi-2 bei komplexen Benchmarks Modelle, die 25-mal so groß sind wie seine eigene Größe.
Microsoft sagt, dass Phi-2 ein ideales Modell für Forscher sein wird, um Interpretierbarkeitsuntersuchungen, Sicherheitsverbesserungen oder Feinabstimmungsexperimente für eine Vielzahl von Aufgaben durchzuführen. Microsoft hat Phi-2 im Azure AI Studio-Modellkatalog verfügbar gemacht, um die Entwicklung von Sprachmodellen zu erleichtern.
Phi-2-Haupthighlights
Die Vergrößerung des Sprachmodells auf Hunderte Milliarden Parameter hat tatsächlich viele neue Funktionen freigesetzt und die Landschaft der Verarbeitung natürlicher Sprache neu definiert. Es bleibt jedoch die Frage offen: Können diese neuen Fähigkeiten auch bei kleineren Modellen durch die Auswahl einer Trainingsstrategie (z. B. Datenauswahl) erreicht werden?
Die von Microsoft bereitgestellte Lösung besteht darin, die Phi-Modellreihe zu verwenden, um durch das Training kleiner Sprachmodelle eine ähnliche Leistung wie große Modelle zu erzielen. Phi-2 verstößt in zweierlei Hinsicht gegen die Skalierungsregeln traditioneller Sprachmodelle
Erstens spielt die Qualität der Trainingsdaten eine entscheidende Rolle für die Modellleistung. Microsoft treibt dieses Verständnis auf die Spitze, indem es sich auf Daten in „Lehrbuchqualität“ konzentriert. Ihre Trainingsdaten bestehen aus einem speziell erstellten umfassenden Datensatz, der dem Modell gesundes Menschenverstandswissen und logisches Denken vermittelt, beispielsweise in Naturwissenschaften, Alltagsaktivitäten und Psychologie. Darüber hinaus erweiterten sie ihr Trainingskorpus mit sorgfältig ausgewählten Webdaten, die auf pädagogischen Wert und Inhaltsqualität überprüft wurden in Phi-2 mit 2,7 Milliarden Parametern. Dieser skalierte Wissenstransfer beschleunigt die Trainingskonvergenz und verbessert die Benchmark-Ergebnisse von Phi-2 erheblich.
Das Folgende ist die Vergleichsgrafik zwischen Phi-2 und Phi-1,5, außer BBH (3-Schuss-CoT) und MMLU (5-Schuss), alle anderen Aufgaben werden mit 0-Schuss bewertet
Trainingsdetails
Phi-2 ist ein Transformer-basiertes Modell, dessen Ziel es ist, das nächste Wort vorherzusagen. Es wurde sowohl an synthetischen als auch an Netzwerkdatensätzen mit 96 A100-GPUs trainiert und dauerte 14 Tage. 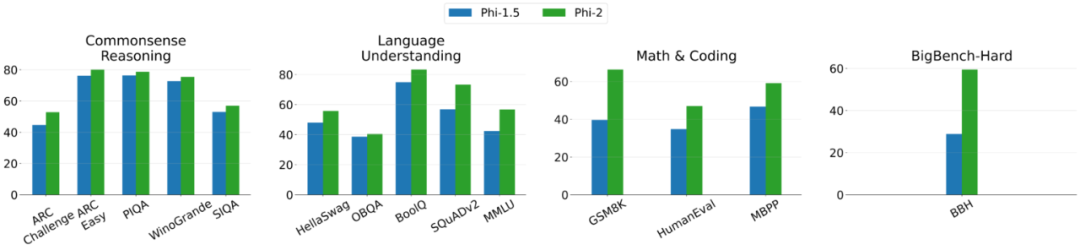
Phi-2 ist ein Basismodell ohne Reinforcement Learning with Human Feedback (RLHF) Alignment und ohne Feinabstimmung der Anweisungen. Dennoch schnitt Phi-2 im Hinblick auf Toxizität und Verzerrung immer noch besser ab als das optimierte bestehende Open-Source-Modell, wie in Abbildung 3 unten dargestellt.
Experimentelle Bewertung
Zunächst verglich die Studie Phi-2 experimentell mit gängigen Sprachmodellen auf akademischen Benchmarks und deckte mehrere Kategorien ab, darunter:
- Big Bench Hard (BBH) (3 Aufnahmen mit CoT )
- Common Sense Reasoning (PIQA, WinoGrande, ARC Easy and Challenge, SIQA),
- Sprachverständnis (HellaSwag, OpenBookQA, MMLU (5-shot), SQuADv2 (2-shot), BoolQ)
- Mathematik (GSM8k (8 Schuss))
- Kodierung (HumanEval, MBPP (3-Schuss))
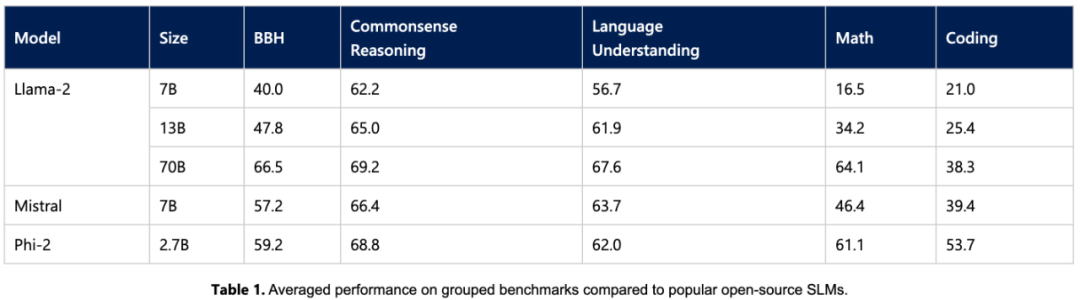
Das Phi-2-Modell hat nur 2,7 Milliarden Parameter, liegt aber in verschiedenen Aggregationen vor. Auf dem Benchmark: Die Leistung übertrifft die Mistral-Modelle 7B und 13B sowie die Llama2-Modelle. Es ist erwähnenswert, dass Phi-2 bei mehrstufigen Inferenzaufgaben (d. h. Codierung und Mathematik) eine bessere Leistung erbringt als das sperrige 25x-Llama2-70B-Modell
Darüber hinaus ist die Leistung von Phi-2 2 trotz seiner geringeren Größe vergleichbar mit das kürzlich von Google veröffentlichte Gemini Nano 2 Da viele öffentliche Benchmarks in die Trainingsdaten eindringen können, ist das Forschungsteam der Ansicht, dass der beste Weg, die Leistung von Sprachmodellen zu testen, darin besteht, sie an bestimmten Anwendungsfällen zu testen. Daher evaluierte die Studie Phi-2 anhand mehrerer interner proprietärer Datensätze und Aufgaben von Microsoft und verglich es erneut mit Mistral und Llama-2. Im Durchschnitt übertraf Phi-2 Mistral-7B und Mistral -7B das Llama2-Modell (7B, 13B). 70B).
Das Forschungsteam testete außerdem ausgiebig gängige Tipps der Forschungsgemeinschaft. Phi-2 verhielt sich wie erwartet. Beispielsweise lieferte Phi-2 für eine Eingabeaufforderung zur Bewertung der Fähigkeit eines Modells, physikalische Probleme zu lösen (kürzlich zur Bewertung des Gemini-Ultra-Modells verwendet), die folgenden Ergebnisse: 

Das obige ist der detaillierte Inhalt vonAuf dem Mobiltelefon läuft das kleine Modell von Microsoft mit 2,7 Milliarden Parametern besser als das große Modell. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Welche Einheit ist der Speicher im von Neumann-Computermodell?
- So entfernen Sie Duplikate und behalten ein Datenelement
- So importieren Sie Daten aus einer Excel-Tabelle in eine andere Tabelle
- Was sind die Schritte, um mit JDBC eine Verbindung zur Datenbank herzustellen?
- Welches Farbmodell wird von Computermonitoren verwendet?