
Heim >Technologie-Peripheriegeräte >KI >NeuRAD: Anwendung führender neuronaler Rendering-Technologie mit mehreren Datensätzen beim autonomen Fahren
NeuRAD: Anwendung führender neuronaler Rendering-Technologie mit mehreren Datensätzen beim autonomen Fahren

- 王林nach vorne
- 2023-12-05 11:21:022593Durchsuche
Der Artikel „NeuRAD: Neural Rendering for Autonomous Driving“ von Zenseact, der Chalmers University of Technology, der Linkoping University und der Lund University.
 Neural Radiation Fields (NeRF) erfreuen sich in der Community des autonomen Fahrens (AD) immer größerer Beliebtheit. Neuere Methoden haben das Potenzial von NeRFs in Closed-Loop-Simulationen, AD-Systemtests und Trainingsdatenerweiterungstechniken gezeigt. Bestehende Methoden erfordern jedoch häufig eine lange Einarbeitungszeit, eine intensive semantische Überwachung und sind nicht generalisierbar. Dies wiederum behindert die groß angelegte Anwendung von NeRF bei AD. In diesem Artikel wird NeuRAD vorgeschlagen, eine robuste neue Ansichtssynthesemethode für dynamische AD-Daten. Der Ansatz umfasst ein einfaches Netzwerkdesign, Sensormodellierung einschließlich Kameras und Lidar (einschließlich Rolling Shutter, Strahldivergenz und Lichtfall) und funktioniert sofort mit mehreren Datensätzen.
Neural Radiation Fields (NeRF) erfreuen sich in der Community des autonomen Fahrens (AD) immer größerer Beliebtheit. Neuere Methoden haben das Potenzial von NeRFs in Closed-Loop-Simulationen, AD-Systemtests und Trainingsdatenerweiterungstechniken gezeigt. Bestehende Methoden erfordern jedoch häufig eine lange Einarbeitungszeit, eine intensive semantische Überwachung und sind nicht generalisierbar. Dies wiederum behindert die groß angelegte Anwendung von NeRF bei AD. In diesem Artikel wird NeuRAD vorgeschlagen, eine robuste neue Ansichtssynthesemethode für dynamische AD-Daten. Der Ansatz umfasst ein einfaches Netzwerkdesign, Sensormodellierung einschließlich Kameras und Lidar (einschließlich Rolling Shutter, Strahldivergenz und Lichtfall) und funktioniert sofort mit mehreren Datensätzen.
Wie in der Abbildung gezeigt: NeuRAD ist eine neuronale Rendering-Methode, die auf dynamische Autoszenen zugeschnitten ist. Die Haltung des eigenen Fahrzeugs und anderer Verkehrsteilnehmer ist veränderbar, Teilnehmer können frei hinzugefügt und/oder entfernt werden. Aufgrund dieser Eigenschaften eignet sich NeuRAD als Basis für Komponenten wie sensorrealistische Closed-Loop-Simulatoren oder leistungsstarke Datenerweiterungs-Engines.
 Das Ziel dieser Arbeit ist es, eine Darstellung zu erlernen, aus der echte Sensordaten generiert werden können, die die Fahrzeugplattform, die Haltung des Schauspielers oder beides verändern können. Es wird davon ausgegangen, dass Zugriff auf die von der mobilen Plattform gesammelten Daten besteht, die aus eingestellten Kamerabildern und Lidar-Punktwolken sowie Schätzungen der Größe und Pose jedes mobilen Akteurs bestehen. Aus praktischen Gründen muss die Methode in Bezug auf Rekonstruktionsfehler bei großen Automobildatensätzen eine gute Leistung erbringen und gleichzeitig die Trainings- und Inferenzzeit auf ein Minimum beschränken.
Das Ziel dieser Arbeit ist es, eine Darstellung zu erlernen, aus der echte Sensordaten generiert werden können, die die Fahrzeugplattform, die Haltung des Schauspielers oder beides verändern können. Es wird davon ausgegangen, dass Zugriff auf die von der mobilen Plattform gesammelten Daten besteht, die aus eingestellten Kamerabildern und Lidar-Punktwolken sowie Schätzungen der Größe und Pose jedes mobilen Akteurs bestehen. Aus praktischen Gründen muss die Methode in Bezug auf Rekonstruktionsfehler bei großen Automobildatensätzen eine gute Leistung erbringen und gleichzeitig die Trainings- und Inferenzzeit auf ein Minimum beschränken.
Die Abbildung zeigt einen Überblick über die in diesem Artikel vorgeschlagene Methode NeuRAD: Erlernen eines statischen und dynamischen gemeinsamen neuronalen Merkmalsfelds für Automobilszenen, das sich durch akteursbewusste Hash-Codierung auszeichnet. Punkte, die in den Begrenzungsrahmen des Akteurs fallen, werden in lokale Koordinaten des Akteurs umgewandelt und zusammen mit dem Akteurindex zur Abfrage des 4D-Hash-Gitters verwendet. Die volumengerenderten Lichtniveaumerkmale werden mithilfe eines Upsampling-CNN in RGB-Werte und mithilfe eines MLP in Strahlfallwahrscheinlichkeiten und -intensitäten dekodiert.
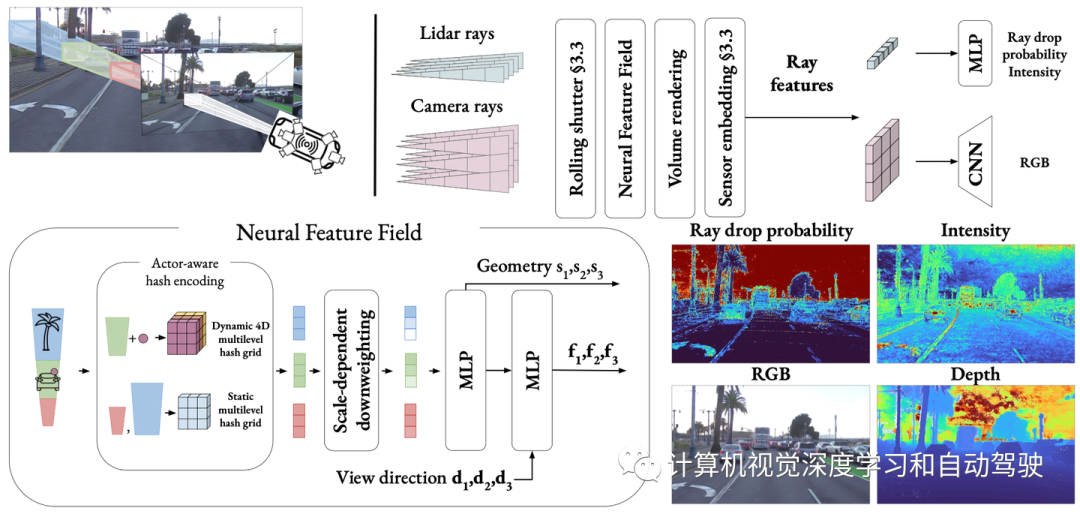 Aufbauend auf der Arbeit der New View Synthesis [4, 47] verwenden die Autoren neuronale Merkmalsfelder (NFF), Verallgemeinerungen von NeRFs [25] und ähnliche Methoden [23], um die Welt zu modellieren.
Aufbauend auf der Arbeit der New View Synthesis [4, 47] verwenden die Autoren neuronale Merkmalsfelder (NFF), Verallgemeinerungen von NeRFs [25] und ähnliche Methoden [23], um die Welt zu modellieren.
Um das Bild zu rendern, muss eine Reihe von Kamerastrahlen volumengerendert werden, um eine Feature-Map F zu generieren. Wie im Artikel [47] beschrieben, wird dann ein Faltungs-Neuronales Netzwerk (CNN) verwendet, um das endgültige Bild zu rendern. In praktischen Anwendungen haben Feature-Maps eine niedrige Auflösung und müssen mithilfe von CNNs hochgesampelt werden, um die Anzahl der Strahlabfragen drastisch zu reduzieren. Sie bestimmten die Entfernung und das Reflexionsvermögen der zurückkommenden Energie, indem sie Impulse eines Laserstrahls abfeuerten und die Flugzeit maßen. Um diese Eigenschaften zu erfassen, werden die vom Lage-Lidar-Sensor gesendeten Impulse als Strahlensatz modelliert und es werden volumenähnliche Rendering-Techniken verwendet.
Stellen Sie sich einen Laserstrahl vor, der keinen Punkt zurückgibt. Wenn die Rückflussleistung zu gering ist, kommt es zu einem Phänomen, das als „Ray Drop“ bekannt ist und für die Modellierung wichtig ist, um simulierte und tatsächliche Unterschiede zu reduzieren [21]. Typischerweise breitet sich solches Licht weit genug aus, um nicht auf eine Oberfläche zu treffen, oder es trifft auf eine Oberfläche, von der der Strahl in einen offenen Raum, beispielsweise einen Spiegel, ein Glas oder ein nasses Pflaster, reflektiert wird. Die Modellierung dieser Effekte ist für eine realistische Simulation von Sensoren wichtig, lässt sich jedoch, wie in [14] dargelegt, nur schwer auf rein physikalischer Basis erfassen, da sie auf (häufig nicht offengelegten) Details der Sensorerkennungslogik auf niedriger Ebene beruhen. Daher entscheiden wir uns dafür, den Strahlenfall aus Daten zu lernen. Ähnlich wie bei der Intensität können Lichtmerkmale volumetrisch gerendert und durch einen kleinen MLP geleitet werden, um die Lichtabfallwahrscheinlichkeit pd(r) vorherzusagen. Beachten Sie, dass im Gegensatz zu [14] das sekundäre Echo des Lidar-Strahls nicht modelliert wird, da diese Informationen in den fünf Datensätzen des Experiments nicht vorhanden sind.
Erweitern Sie die Definition des neuronalen Merkmalsfelds (NFF) auf Lernfunktion (s, f) = NFF (x, t, d), wobei x die räumliche Koordinate ist, t die Zeit darstellt und d die Blickrichtung darstellt. Diese Definition führt Zeit als Eingabe ein, die für die Modellierung der dynamischen Aspekte der Szene von entscheidender Bedeutung ist
Neuronale Architektur
NFF-Architektur folgt dem anerkannt besten Ansatz in NeRF [4, 27]. Fragen Sie bei einem gegebenen Ort x und einer Zeit t den akteursbewussten Hash-Code ab. Diese Kodierung wird dann in einen kleinen MLP eingespeist, der den vorzeichenbehafteten Abstand s und die Zwischenmerkmale g berechnet. Durch die Codierung der Blickrichtung d mit sphärischen Harmonischen [27] kann das Modell Reflexionen und andere blickbezogene Effekte erfassen. Schließlich werden die Richtungskodierung und die Zwischenmerkmale gemeinsam durch einen zweiten MLP verarbeitet, der durch Sprungverbindungen von g erweitert wird, was zu Merkmal f führt.
Szenenkomposition
Ähnlich wie bei früheren Arbeiten [18, 29, 46, 47] teilen wir die Welt in zwei Teile, nämlich einen statischen Hintergrund und eine Reihe starrer dynamischer Akteure, wobei jeder Akteur aus definierten Elementen besteht durch einen 3D-Begrenzungsrahmen und eine Reihe von SO(3)-Posen. Wir dienen dem doppelten Zweck, den Lernprozess zu vereinfachen und ein Maß an Bearbeitbarkeit zu ermöglichen, das die dynamische Generierung neuer Szenarien durch den Akteur nach dem Training ermöglicht. Im Gegensatz zu früheren Ansätzen, die separate NFFs für verschiedene Szenenelemente verwenden, verwenden wir ein einziges einheitliches NFF, bei dem alle Netzwerke gemeinsam genutzt werden und die Unterscheidung zwischen statischen und dynamischen Komponenten durch akteursbewusste Hash-Kodierung transparent gehandhabt wird. Die Codierungsstrategie ist einfach: Codieren Sie ein gegebenes Sample (x, t) mit einer von zwei Funktionen, basierend darauf, ob es innerhalb des Akteur-Begrenzungsrahmens liegt
Unbegrenzte statische Szene
unter Verwendung einer Hash-Netz-Gitterdarstellung mit mehreren Auflösungen von statischen Szenen hat sich als äußerst ausdrucksstarke und effiziente Darstellungsmethode erwiesen. Um jedoch unbegrenzte Szenen auf Netze abzubilden, verwenden wir die in MipNerf-360 vorgeschlagene Schrumpfungsmethode. Dieser Ansatz kann nahe gelegene Straßenelemente und entfernte Wolken mit einem einzigen Hash-Netz genau darstellen. Im Gegensatz dazu nutzen bestehende Methoden spezielle NFFs, um den Himmel und andere entfernte Regionen zu erfassen Die Blickrichtung d wird zu einem gegebenen Zeitpunkt t in das Koordinatensystem des Akteurs transformiert. Ignorieren Sie anschließend den zeitlichen Aspekt und probieren Sie Features aus einem zeitunabhängigen Hash-Gitter mit mehreren Auflösungen aus, genau wie eine statische Szene. Einfach ausgedrückt müssen mehrere verschiedene Hash-Grids separat abgetastet werden, eines für jeden Akteur. Stattdessen wird jedoch ein einzelnes 4D-Hash-Gitter verwendet, wobei die vierte Dimension dem Akteurindex entspricht. Dieser Ansatz ermöglicht das parallele Abtasten aller Akteurfunktionen, wodurch erhebliche Beschleunigungen erzielt werden und gleichzeitig die Leistung einzelner Hash-Grids angepasst wird.
Multi-Scale-Scene-Problem
Eine der größten Herausforderungen bei der Anwendung neuronaler Renderings auf Automobildaten ist der Umgang mit den verschiedenen Detailebenen, die in diesen Daten vorhanden sind. Wenn ein Auto eine lange Strecke zurücklegt, sieht es viele Oberflächen, sowohl aus der Ferne als auch aus der Nähe. In diesem Fall mit mehreren Maßstäben kann die einfache Anwendung von Positionseinbettungen von iNGP [27] oder NeRF zu Aliasing-Artefakten führen [2]. Um dieses Problem zu lösen, modellieren viele Methoden Strahlen als Kegelstumpf, wobei die Längsrichtung des Kegelstumpfs durch die Größe des Behälters und die radiale Richtung durch die Pixelfläche und den Abstand vom Sensor bestimmt wird [2, 3, 13].
Zip -NeRF[4] ist derzeit die einzige Anti-Aliasing-Methode für iNGP-Hash-Grids, die zwei Kegelstumpfmodellierungstechniken kombiniert: Multi-Sampling und Gewichtsreduzierung. Beim Multisampling werden die Positionseinbettungen an mehreren Positionen des Kegelstumpfes gemittelt und die Längs- und Radialausdehnungen erfasst. Zur Herabgewichtung wird jede Stichprobe als isotropes Gaußsches Modell modelliert, wobei die Gittermerkmale proportional zum Verhältnis zwischen Zellengröße und Gaußscher Varianz gewichtet werden, wodurch feinere Auflösungen wirksam unterdrückt werden. Während die Kombination von Techniken die Leistung erheblich verbessert, erhöht Multisampling auch die Laufzeit erheblich. Ziel dieses Dokuments ist es daher, Skaleninformationen mit minimalen betrieblichen Auswirkungen zu integrieren. Inspiriert von Zip-NeRF schlagen die Autoren ein intuitives Gewichtsreduzierungsschema vor, das das Gewicht von Hash-Grid-Features im Verhältnis zu ihrer Größe im Verhältnis zum Kegelstumpf reduziert.
Effizientes Sampling
Eine weitere Schwierigkeit beim Rendern großer Szenen ist die Notwendigkeit effizienter Sampling-Strategien. In einem Bild möchten Sie möglicherweise detaillierten Text auf einem nahegelegenen Verkehrsschild rendern und gleichzeitig den Parallaxeneffekt zwischen mehreren Kilometer entfernten Wolkenkratzern einfangen. Um beide Ziele zu erreichen, würde eine gleichmäßige Abtastung der Strahlen Tausende von Abtastungen pro Strahl erfordern, was rechnerisch nicht realisierbar ist. Frühere Arbeiten stützten sich zum Bereinigen von Proben stark auf LIDAR-Daten [47], was das Rendern außerhalb von LIDAR-Arbeiten schwierig machte.
Stattdessen rendert dieses Papier Proben entlang des Strahls gemäß einer Potenzfunktion [4], sodass der Abstand zwischen den Proben mit der Entfernung vom Strahlursprung zunimmt. Dennoch ist es mit einer drastischen Vergrößerung der Stichprobengröße unmöglich, alle relevanten Bedingungen zu erfüllen. Daher werden auch zwei Runden der Vorschlagsstichprobe [25] verwendet, bei denen eine leichte Version des neuronalen Merkmalsfelds (NFF) abgefragt wird, um eine Gewichtsverteilung entlang des Strahls zu generieren. Anschließend wird basierend auf diesen Gewichten ein neuer Satz von Stichproben gerendert. Nach zwei Durchgängen dieses Prozesses wird ein verfeinerter Satz von Proben erhalten, die an relevanten Positionen auf dem Strahl konzentriert sind und zur Abfrage des vollständigen NFF verwendet werden können. Zur Überwachung des vorgeschlagenen Netzwerks wird eine Anti-Aliasing-Online-Destillationsmethode [4] eingesetzt und die weitere Überwachung mithilfe von Lidar durchgeführt.
Modellierung Rolling Shutter
In der standardmäßigen NeRF-basierten Formulierung wird davon ausgegangen, dass jedes Bild von einem Ursprungs-o. Viele Kamerasensoren verfügen jedoch über einen Rolling Shutter, bei dem Pixelreihen nacheinander erfasst werden. Daher kann sich der Kamerasensor zwischen der Erfassung der ersten Reihe und der Erfassung der letzten Reihe bewegen, wodurch die Annahme eines einzelnen Ursprungs aufgehoben wird. Während dies bei synthetischen Daten [24] oder Daten, die mit langsamen Handkameras aufgenommen wurden, kein Problem darstellt, macht sich Rolling Shutter bei Aufnahmen von sich schnell bewegenden Fahrzeugen, insbesondere von Seitenkameras, bemerkbar. Der gleiche Effekt ist bei Lidar vorhanden, wo jeder Scan typischerweise in 0,1 Sekunden erfasst wird, was bei Fahrten mit Autobahngeschwindigkeit einer Bewegung von mehreren Metern entspricht. Selbst bei durch Eigenbewegung kompensierten Punktwolken können diese Unterschiede zu schädlichen Sichtlinienfehlern führen, bei denen 3D-Punkte in Strahlen umgewandelt werden, die durch andere Geometrie verlaufen. Um diese Effekte abzuschwächen, wird ein Rolling Shutter modelliert, indem jedem Strahl eine separate Zeit zugewiesen und sein Ursprung basierend auf der geschätzten Bewegung angepasst wird. Da sich Rolling Shutter auf alle dynamischen Elemente der Szene auswirkt, wird für jede einzelne Lichtzeit und Schauspielerpose eine lineare Interpolation durchgeführt.
Unterschiedliche Kameraeinstellungen
Ein weiteres Problem bei der Simulation autonomer Fahrsequenzen besteht darin, dass die Bilder von verschiedenen Kameras stammen, mit möglicherweise unterschiedlichen Aufnahmeparametern wie der Belichtung. Hier wurde die Inspiration von der Forschung zu „NeRFs in freier Wildbahn“ [22] übernommen, bei der die Einbettung des Erscheinungsbilds für jedes Bild gelernt und zusammen mit seinen Merkmalen an den zweiten MLP übergeben wird. Wenn jedoch bekannt ist, welches Bild von welchem Sensor stammt, wird stattdessen eine einzelne Einbettung für jeden Sensor gelernt, wodurch die Möglichkeit einer Überanpassung minimiert wird und diese Sensoreinbettungen bei der Generierung neuer Ansichten verwendet werden können. Diese Einbettungen werden nach dem Volumenrendering angewendet, wodurch der Rechenaufwand beim Rendern von Features anstelle von Farben erheblich reduziert wird.
Noisy Actor Pose
Das Modell basiert auf der Schätzung dynamischer Schauspielerposen, sei es in Form von Anmerkungen oder als Tracking-Ausgabe. Um die Defizite zu beheben, werden Schauspielerposen als lernbare Parameter in das Modell übernommen und gemeinsam optimiert. Die Lage wird als Translation t und Rotation R parametrisiert, wobei die 6D-Darstellung verwendet wird [50].
NeuRAD ist im Open-Source-Projekt Nerfstudio[33] implementiert. Das Training wird für 20.000 Iterationen mit dem Adam[17]-Optimierer durchgeführt. Auf einem NVIDIA A100 dauert das Training etwa 1 Stunde
Reproduzieren von UniSim: UniSim [47] ist ein neuronaler Closed-Loop-Sensorsimulator. Es bietet fotorealistische Renderings und macht wenige Annahmen über die verfügbare Überwachung, d. h. es erfordert nur Kamerabilder, Lidar-Punktwolken, Sensorposen und 3D-Begrenzungsrahmen mit dynamischen Akteursbahnen. Diese Eigenschaften machen UniSim zu einer geeigneten Basis, da es leicht auf neue Datensätze zum autonomen Fahren anwendbar ist. Der Code ist jedoch Closed Source und es gibt keine inoffizielle Implementierung. Daher wählt dieser Artikel die Neuimplementierung von UniSim als eigenes Modell und die Implementierung in Nerfstudio [33]. Da der Hauptartikel von UniSim nicht viele Modelldetails enthält, muss man sich auf das ergänzende Material von IEEE Xplore verlassen. Dennoch bleiben einige Details unbekannt und die Autoren haben diese Hyperparameter angepasst, um sie an die gemeldete Leistung von 10 ausgewählten PandaSet-Sequenzen [45] anzupassen.
Das obige ist der detaillierte Inhalt vonNeuRAD: Anwendung führender neuronaler Rendering-Technologie mit mehreren Datensätzen beim autonomen Fahren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was man im Hauptfach Big Data studieren sollte
- Wie vergleiche ich zwei Tabellen, um dieselben Daten herauszufiltern?
- Huawei Cloud und eine Reihe von Unternehmen haben eine Aktionsinitiative gestartet: Gemeinsam ein offenes industrielles Ökosystem für autonomes Fahren aufbauen
- Eine kurze Analyse der Roadmap der visuellen Wahrnehmungstechnologie für autonomes Fahren
- Eine ausführliche Analyse der autonomen Fahrtechnologielösungen von Tesla