
Heim >Technologie-Peripheriegeräte >KI >Microsoft hat GPT-4 allein mit dem „Prompt Project' zu einem medizinischen Experten gemacht! Bei mehr als einem Dutzend hochfein abgestimmter Modelle überstieg die professionelle Testgenauigkeit erstmals 90 %
Microsoft hat GPT-4 allein mit dem „Prompt Project' zu einem medizinischen Experten gemacht! Bei mehr als einem Dutzend hochfein abgestimmter Modelle überstieg die professionelle Testgenauigkeit erstmals 90 %

- 王林nach vorne
- 2023-12-04 14:25:451370Durchsuche
Die neuesten Forschungsergebnisse von Microsoft beweisen erneut die Leistungsfähigkeit von Prompt Engineering –
Keine zusätzliche Feinabstimmung oder Expertenplanung erforderlich, GPT-4 kann allein durch Eingabeaufforderungen zum „Experten“ werden.
Mit ihrer neuesten Prompt-Strategie Medprompt erzielte GPT-4 im medizinischen Fachbereich die besten Ergebnisse in den neun Testsätzen von MultiMed QA.
Auf dem MedQA-Datensatz (Fragen zur medizinischen Zulassungsprüfung der Vereinigten Staaten) ermöglichte Medprompt erstmals, dass die Genauigkeit von GPT-4 90 % übersteigt und damit BioGPT und Med-PaLM sowie andere Feinabstimmungsmethoden übertrifft.
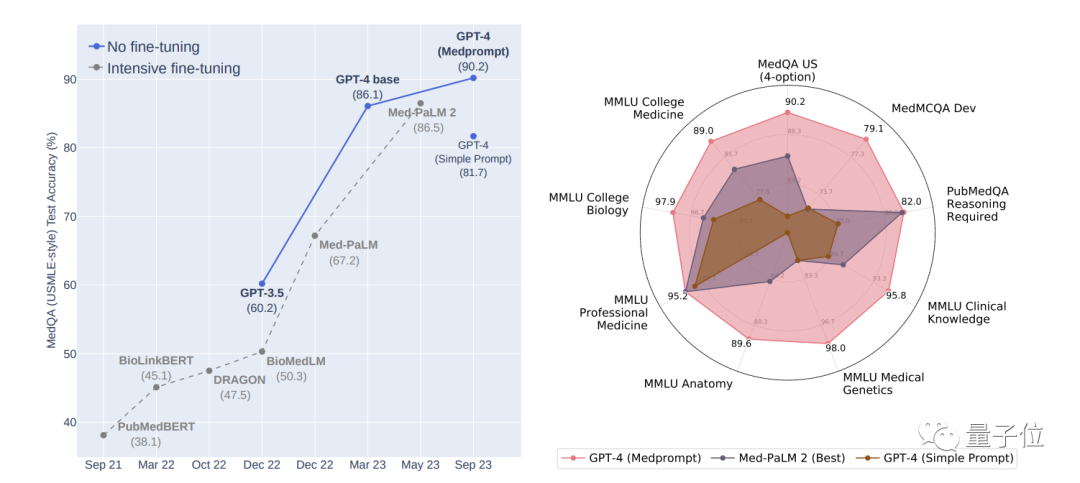

GPT-4 ist eine Technologie, die die Branche verändern kann, und wir haben noch lange nicht die Grenze der Eingabeaufforderungen erreicht, noch haben wir die Grenze der Feinabstimmung erreicht .

- Dynamische Auswahl mit wenigen Schüssen (Dynamische Auswahl mit wenigen Schüssen)
- Selbst -generiert Selbstgenerierte Gedankenkette
- Auswahl-Misch-Ensemble

festgelegt, daher werden hohe Anforderungen an die Repräsentativität und Breite der Beispiele gestellt.
Eine frühere Methode bestand darin, Domänenexpertenmanuell Beispiele erstellen zu lassen, aber trotzdem gibt es keine Garantie dafür, dass die von Experten kuratierten festen Beispiele mit wenigen Stichproben für jede Aufgabe repräsentativ sind.
Microsoft-Forscher haben eine Methode für dynamische Beispiele mit wenigen Schüssen vorgeschlagen. Die Idee ist, dass der Aufgabentrainingssatz als Quelle für Beispiele mit wenigen Schüssen verwendet werden kann. Wenn der Trainingssatz groß genug ist, können verschiedene ausgewählt werden für verschiedene Aufgabeneingaben. In Bezug auf spezifische Operationen verwendeten die Forscher zunächst das Modell text-embedding-ada-002, um Vektordarstellungen für jede Trainingsprobe und Testprobe zu generieren. Anschließend werden für jede Testprobe durch Vergleich der Ähnlichkeit der Vektoren die k Proben, die ihr am ähnlichsten sind, aus den Trainingsproben ausgewählt.Im Vergleich zur Feinabstimmungsmethode nutzt die dynamische Auswahl mit wenigen Schüssen das Training Daten, erfordert jedoch keine umfassenden Aktualisierungen der Modellparameter. Selbstgenerierte GedankenketteDie Chain of Thought (CoT)-Methode ist eine Methode, die es dem Modell ermöglicht, Schritt für Schritt zu denken und eine Reihe von Zwischenschritten für die Argumentation zu generierenDie vorherige Methode verließ sich darauf, dass Experten manuell einige Beispiele schreiben angeregte Gedankenketten
Hier fanden die Forscher heraus, dass GPT-4 einfach aufgefordert werden kann, Gedankenketten für Trainingsbeispiele zu generieren, indem man die folgende Eingabeaufforderung verwendet:
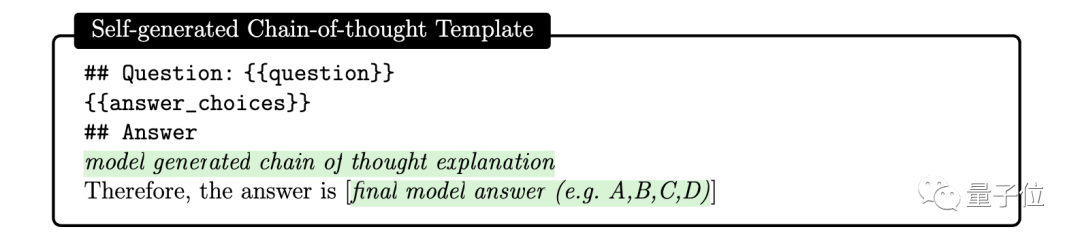
Aber die Forscher wiesen auch darauf hin, dass diese automatisch generierte Gedankenkette fehlerhafte Überlegungen enthalten könnte Schritt, daher wird ein Verifizierungs-Tag als Filter festgelegt, der Fehler effektiv reduzieren kann.
Verglichen mit den von Experten im Med-PaLM 2-Modell handgefertigten Beispielen für Gedankenketten sind die Grundprinzipien der von GPT-4 generierten Gedankenkette länger und die Logik der schrittweisen Argumentation feinkörniger.
Option Shuffling Integration
GPT-4 weist möglicherweise eine Tendenz bei der Verarbeitung von Multiple-Choice-Fragen auf, d
Um dieses Problem zu lösen, beschlossen die Forscher, die Reihenfolge der ursprünglichen Optionen neu zu ordnen, um die Auswirkungen zu verringern. Die ursprüngliche Reihenfolge der Optionen ist beispielsweise ABCD, die in BCDA, CDAB usw. geändert werden kann. Lassen Sie dann GPT-4 mehrere Vorhersagerunden durchführen, wobei in jeder Runde eine andere Reihenfolge der Optionen verwendet wird. Dies „zwingt“ GPT-4, den Inhalt der Optionen zu berücksichtigen. Abschließend stimmen Sie über die Ergebnisse mehrerer Vorhersagerunden ab und wählen Sie die konsistenteste und korrekteste Option. Die Kombination der oben genannten Prompt-Strategien ist Medprompt. Werfen wir einen Blick auf die Testergebnisse. Optimal in mehreren TestsIm Test verwendeten die Forscher den MultiMed QA-Bewertungsbenchmark.GPT-4, das die Medprompt-Prompting-Strategie nutzt, erreichte die höchsten Werte in allen neun Benchmark-Datensätzen von MultiMedQA und übertraf damit Flan-PaLM 540B und Med-PaLM 2. 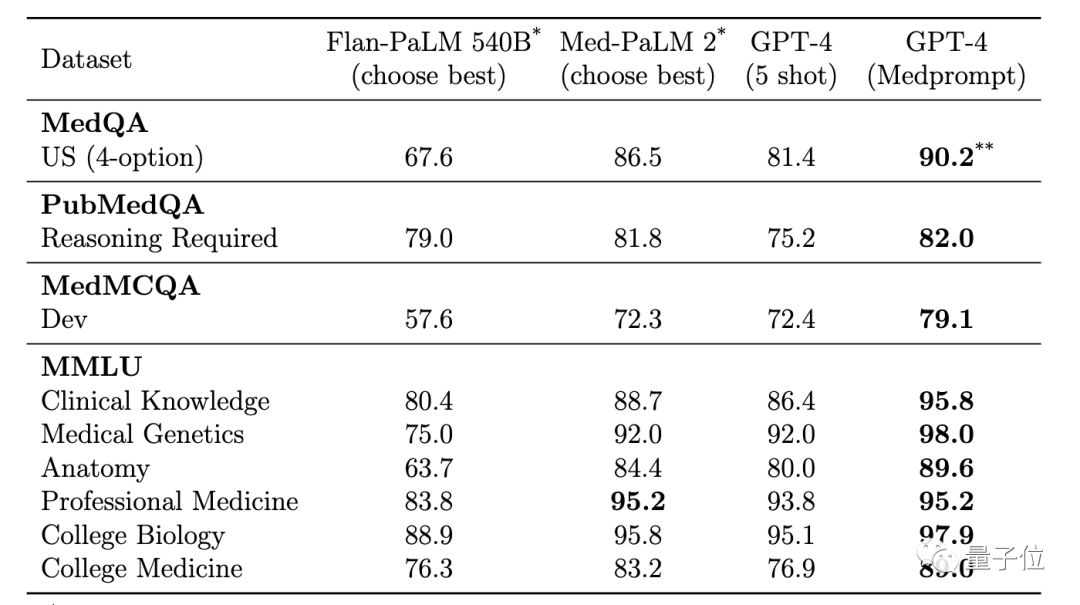
Ergebnisse GPT-4 kombiniert Die Medprompt-Strategie wurde in mehreren medizinischen Untersuchungen eingesetzt. Sie schnitt beim Benchmark-Datensatz mit einer durchschnittlichen Genauigkeit von 91,3 % gut ab. 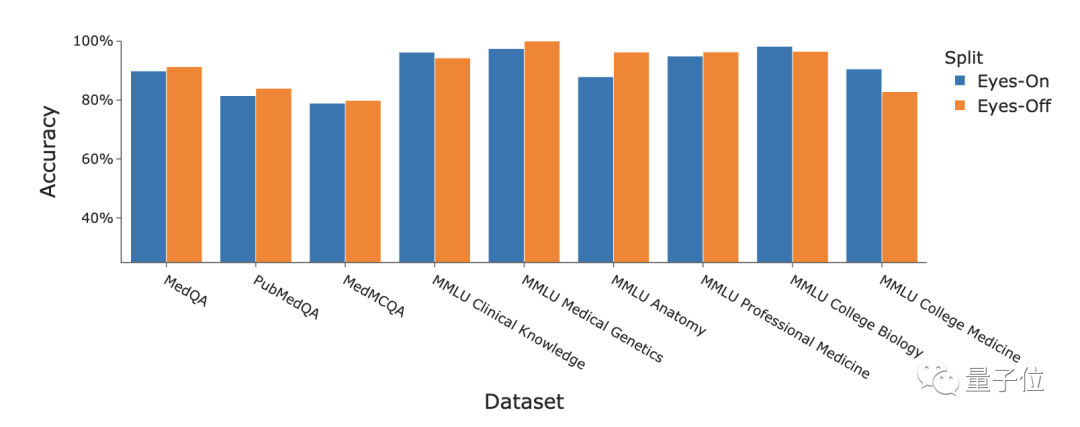
Unter diesen spielt die automatische Generierung von Denkkettenschritten die größte Rolle bei der Leistungsverbesserung 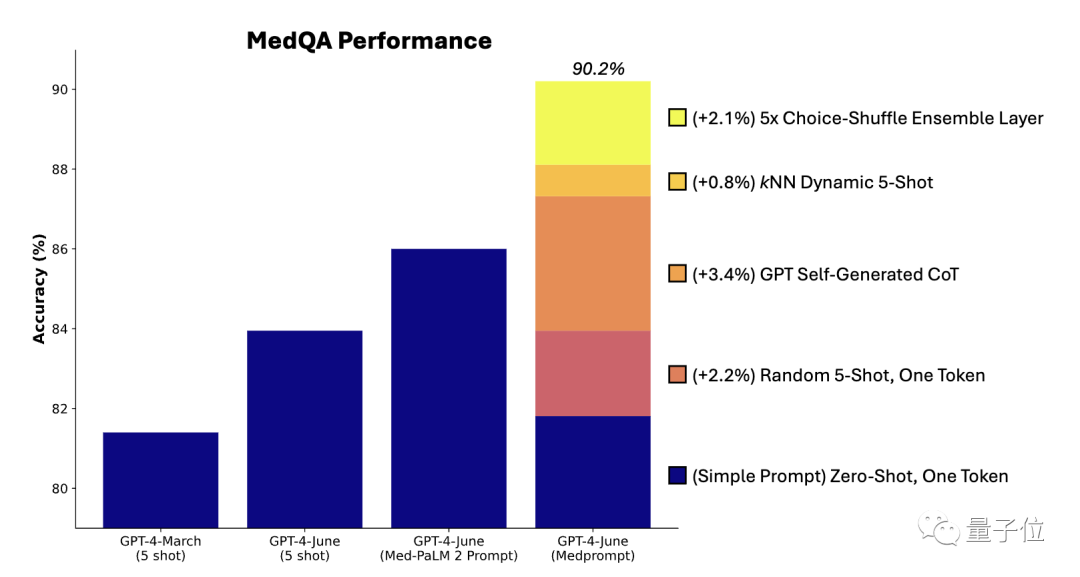 Der von GPT-4 automatisch generierte Wert der Gedankenkette ist höher als der von Experten in Med-PaLM 2 kuratierte Wert, und es ist kein manueller Eingriff erforderlich
Der von GPT-4 automatisch generierte Wert der Gedankenkette ist höher als der von Experten in Med-PaLM 2 kuratierte Wert, und es ist kein manueller Eingriff erforderlich
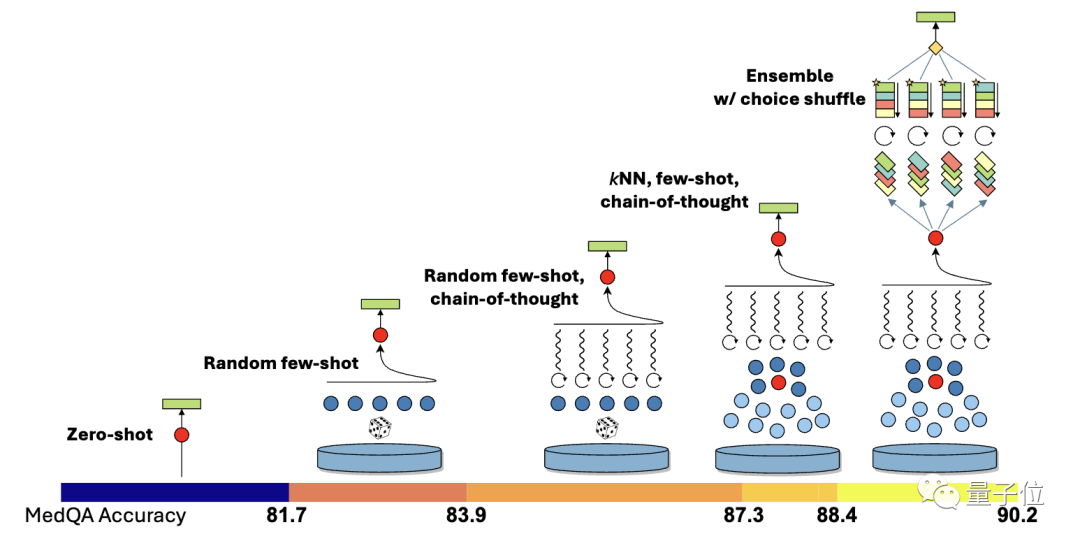 Abschließend untersuchten die Forscher auch die domänenübergreifenden Generalisierungsfähigkeiten von Medprompt, unter Verwendung von sechs verschiedenen Datensätzen aus dem MMLU-Benchmark, die Probleme in den Bereichen Elektrotechnik, maschinelles Lernen, Philosophie, professionelles Rechnungswesen, Berufsrecht und Berufspsychologie abdecken.
Abschließend untersuchten die Forscher auch die domänenübergreifenden Generalisierungsfähigkeiten von Medprompt, unter Verwendung von sechs verschiedenen Datensätzen aus dem MMLU-Benchmark, die Probleme in den Bereichen Elektrotechnik, maschinelles Lernen, Philosophie, professionelles Rechnungswesen, Berufsrecht und Berufspsychologie abdecken.
Zwei zusätzliche Datensätze mit NCLEX-Fragen (National Nursing Licensure Examination) wurden ebenfalls hinzugefügt.
Die Ergebnisse zeigen, dass die Wirkung von Medprompt auf diese Datensätze ähnlich der Verbesserung auf den medizinischen Datensatz von MultiMedQA ist, wobei die durchschnittliche Genauigkeit um 7,3 % erhöht wurde. 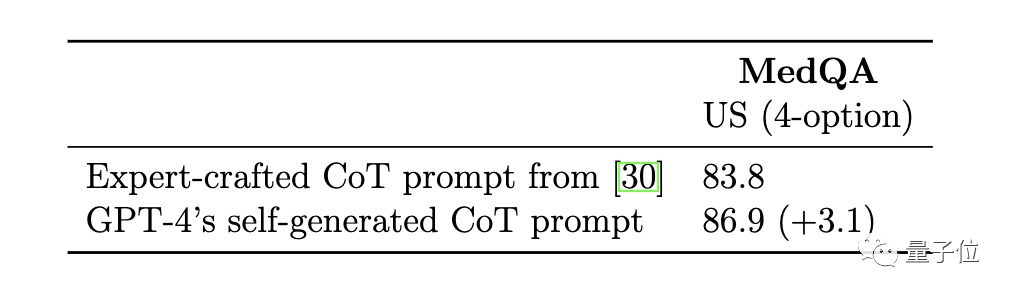
Das obige ist der detaillierte Inhalt vonMicrosoft hat GPT-4 allein mit dem „Prompt Project' zu einem medizinischen Experten gemacht! Bei mehr als einem Dutzend hochfein abgestimmter Modelle überstieg die professionelle Testgenauigkeit erstmals 90 %. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!