
Heim >Technologie-Peripheriegeräte >KI >Häufig verwendete Regressionsalgorithmen und ihre Eigenschaften in Anwendungen des maschinellen Lernens
Häufig verwendete Regressionsalgorithmen und ihre Eigenschaften in Anwendungen des maschinellen Lernens

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-11-29 17:29:261008Durchsuche
Regression ist eines der leistungsfähigsten Werkzeuge in der Statistik. Überwachte Lernalgorithmen werden in zwei Typen unterteilt: Klassifizierungsalgorithmen und Regressionsalgorithmen. Der Regressionsalgorithmus wird für die Vorhersage kontinuierlicher Verteilungen verwendet und kann kontinuierliche Daten und nicht nur diskrete Kategoriebezeichnungen vorhersagen.
Die Regressionsanalyse wird häufig im Bereich des maschinellen Lernens verwendet, z. B. zur Vorhersage von Produktverkäufen, Verkehrsströmen, Immobilienpreisen, Wetterbedingungen usw. Der Regressionsalgorithmus ist ein häufig verwendeter Algorithmus für maschinelles Lernen, mit dem die Beziehung zwischen unabhängigen Personen hergestellt wird Variable X und die abhängige Variable Y Beziehung. Aus Sicht des maschinellen Lernens wird es zum Erstellen eines Algorithmusmodells (einer Funktion) verwendet, um die Zuordnungsbeziehung zwischen Attribut X und Beschriftung Y zu erreichen. Während des Lernprozesses versucht der Algorithmus, die beste Parameterbeziehung zu finden, damit die Anpassung am besten ist Im Regressionsalgorithmus ist das Endergebnis des Algorithmus (Funktion) ein kontinuierlicher Datenwert. Der Eingabewert (Attributwert) ist ein d-dimensionales Attribut/einen numerischen Vektor. Einige häufig verwendete Regressionsalgorithmen umfassen lineare Regression, Polynomregression, Entscheidungsbaumregression, Ridge-Regression, Lasso-Regression, ElasticNet-Regression usw.Dieser Artikel wird Stellen Sie einige gängige Regressionsalgorithmen und ihre jeweiligen Eigenschaften vorEntscheidungsbaum-Regression
- Random Der Wald ist zurück
- LASSO ist zurück
- Ridge ist zurück
- ElasticNet ist zurück
- XGBoost ist zurück
- Lokal gewichtet Lineare Regression
- Eins: Lineare Regression Lineare Regression ist oft der erste Algorithmus, den Menschen über maschinelles Lernen und Datenwissenschaft lernen. Die lineare Regression ist ein lineares Modell, das eine lineare Beziehung zwischen einer Eingabevariablen (X) und einer einzelnen Ausgabevariablen (y) annimmt. Im Allgemeinen gibt es zwei Situationen:
- Univariate lineare Regression ist eine Modellierungsmethode zur Analyse der Beziehung zwischen einer einzelnen Eingabevariablen (d. h. einer einzelnen Merkmalsvariablen) und einer einzelnen Ausgabevariablen
- Multivariable lineare Regression (auch wird als multiple lineare Regression bezeichnet): Sie modelliert die Beziehung zwischen mehreren Eingabevariablen (mehreren Merkmalsvariablen) und einer einzelnen Ausgabevariablen. Ein paar wichtige Punkte zur linearen Regression:
- Schnell und einfach zu modellieren
Sehr intuitives Verständnis und Erklärung.
Es reagiert sehr empfindlich auf Ausreißer.
2. Polynomielle Regression
Wenn wir ein Modell für nichtlineare trennbare Daten erstellen möchten, ist die polynomielle Regression eine der beliebtesten Optionen. Sie ähnelt der linearen Regression, nutzt jedoch die Beziehung zwischen den Variablen X und Y, um den besten Weg zum Zeichnen einer Kurve zu finden, die zu den Datenpunkten passt.
- Ein paar wichtige Punkte zur polynomialen Regression:
- ist in der Lage, nichtlineare trennbare Daten zu modellieren; die lineare Regression kann dies nicht. Im Allgemeinen ist es flexibler und kann einige ziemlich komplexe Beziehungen modellieren.
- Volle Kontrolle über die Modellierung von Feature-Variablen (einzustellende Exponenten).
- Erfordert sorgfältiges Design. Um den besten Index auszuwählen, sind einige Datenkenntnisse erforderlich.
3. Support-Vektor-Maschinen-Regression
Support-Vektor-Maschinen sind bei Klassifizierungsproblemen bekannt. Die Verwendung von SVM bei der Regression wird Support Vector Regression (SVR) genannt. Scikit-learn hat diese Methode in SVR() integriert.
- Einige wichtige Punkte zur Support-Vektor-Regression:
- Sie ist robust gegenüber Ausreißern und effektiv im hochdimensionalen Raum.
- Sie verfügt über eine ausgezeichnete Generalisierungsfähigkeit (Fähigkeit, sich korrekt an Neues, bisher Ungesehenes anzupassen Daten)
4. Entscheidungsbaum-Regression
Der Entscheidungsbaum ist eine Methode zur nichtparametrischen Klassifizierung und Regression überwachte Lernmethode. Das Ziel besteht darin, ein Modell zu erstellen, das den Wert einer Zielvariablen vorhersagt, indem es einfache Entscheidungsregeln lernt, die aus Datenmerkmalen abgeleitet werden. Ein Baum kann als stückweise konstante Näherung betrachtet werden.
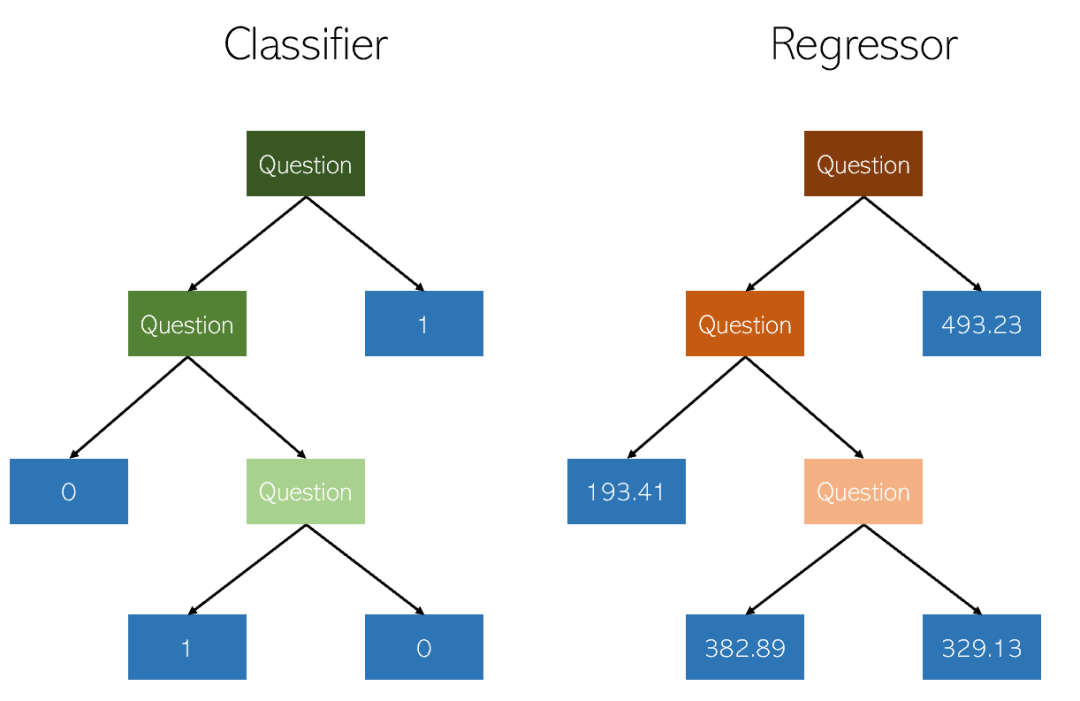
Ein paar wichtige Punkte zu Entscheidungsbäumen:
- Einfach zu verstehen und zu erklären. Bäume können visualisiert werden.
- Gilt sowohl für kategoriale als auch für kontinuierliche Werte
- Die Kosten für die Verwendung von DT (d. h. Vorhersagedaten) sind logarithmisch zur Anzahl der Datenpunkte, die zum Trainieren des Baums verwendet werden.
- Vorhersagen aus Entscheidungsbäumen sind weder glatt noch kontinuierlich (Wie in der Abbildung oben gezeigt, handelt es sich um eine stückweise konstante Näherung)
5. Random Forest Regression
Random Forest Regression und Entscheidungsbaumregression sind grundsätzlich sehr ähnlich. Es handelt sich um einen Metaschätzer, der mehrere Entscheidungsbäume an verschiedene Teilstichproben des Datensatzes anpassen und diese mitteln kann, um die Vorhersagegenauigkeit zu verbessern und Überanpassungen zu kontrollieren besser bei Klassifizierungsproblemen) aufgrund subtiler Über- und Unteranpassungs-Kompromisse, die dem Baumkonstruktionsalgorithmus innewohnen.
Es funktioniert auch für kategoriale und kontinuierliche Werte.
Erfordert viel Rechenleistung und Ressourcen, da viele Entscheidungsbäume zur Kombination ihrer Ausgaben passen.
6. LASSO-Regression- LASSO-Regression ist eine Variante der linearen Schrumpfungsregression. Beim Schrumpfen werden Datenwerte im Durchschnitt auf einen Mittelpunkt reduziert. Diese Art der Regression ist ideal für Modelle mit schwerer Multikollinearität (hohe Korrelation zwischen Merkmalen)
- Ein paar Punkte zur Lasso-Regression:
Sie wird am häufigsten verwendet, um automatische Variablen zu eliminieren und Merkmale auszuwählen .
Es ist ideal für Modelle, die eine starke Multikollinearität aufweisen (Merkmale sind stark miteinander korreliert). 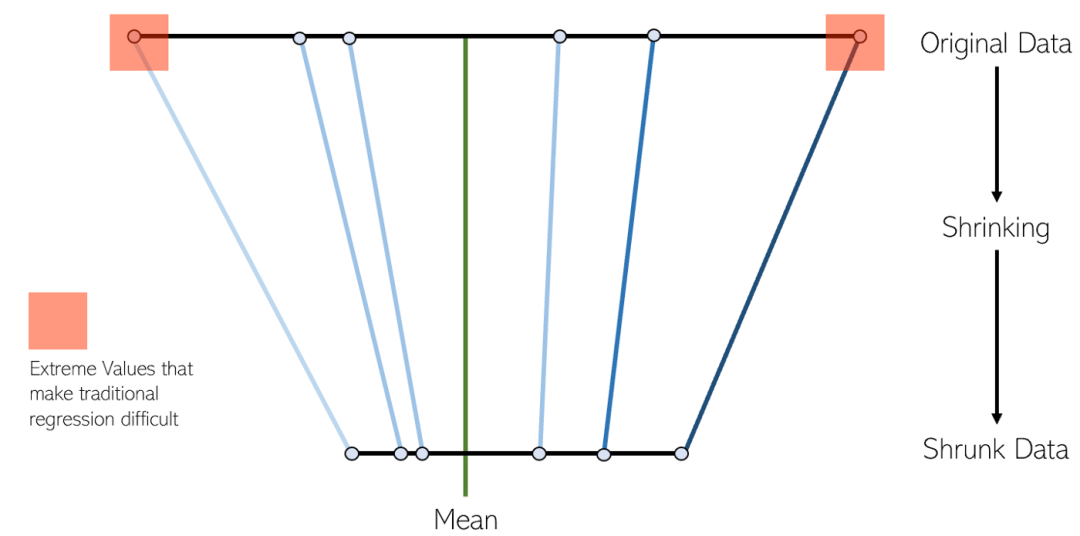
LASSO-Regression nutzt L1-Regularisierung
LASSO-Regression gilt als besser als Ridge, da sie nur einige Features auswählt und die Koeffizienten anderer Features auf Null reduziert.- 7. Ridge-Regression
- Die Ridge-Regression ist der LASSO-Regression sehr ähnlich, da beide Techniken Schrumpfungsmethoden verwenden. Sowohl die Ridge- als auch die LASSO-Regression eignen sich gut für Modelle mit schwerwiegenden Multikollinearitätsproblemen (d. h. hoher Korrelation zwischen Merkmalen). Der Hauptunterschied zwischen ihnen besteht darin, dass Ridge L2-Regularisierung verwendet, was bedeutet, dass keiner der Koeffizienten wie bei der LASSO-Regression auf Null (aber nahe Null) geht
- Ein paar Punkte zur Ridge-Regression:
Es ist ideal für Modelle, die eine starke Multikollinearität aufweisen (Merkmale sind stark miteinander korreliert).
Ridge-Regression verwendet L2-Regularisierung. Merkmale, die einen geringeren Beitrag leisten, weisen Koeffizienten nahe Null auf. 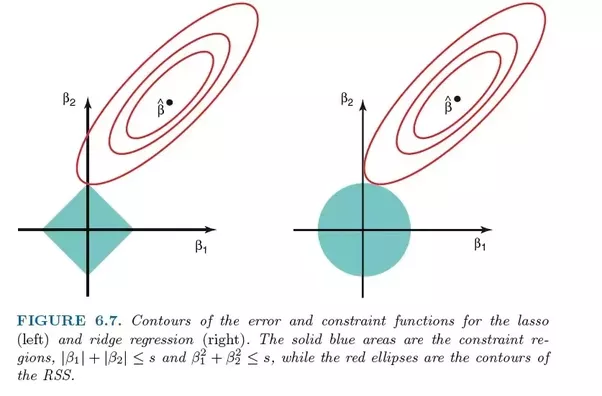
Ridge-Regression gilt aufgrund der Art der L2-Regularisierung als schlimmer als LASSO.
8. ElasticNet-Regression- ElasticNet ist ein weiteres lineares Regressionsmodell, das mithilfe der L1- und L2-Regularisierung trainiert wird. Es ist eine Mischung aus Lasso- und Ridge-Regressionstechniken und eignet sich daher auch gut für Modelle, die eine starke Multikollinearität aufweisen (Merkmale sind stark miteinander korreliert).
- Beim Abwägen zwischen Lasso und Ridge besteht ein praktischer Vorteil darin, dass Elastic-Net einen Teil der Stabilität von Ridge unter Rotation erben kann.
- 9 wirkungsvoll umgesetzt. Gradient Boosting ist eine Art Ensemble-Algorithmus für maschinelles Lernen, der für Klassifizierungs- oder Regressionsprobleme verwendet werden kann.
Ein paar Punkte zu XGBoost:
- XGBoost funktioniert bei spärlichen und unstrukturierten Daten nicht gut.
- Der Algorithmus ist so konzipiert, dass er recheneffizient und effizient ist, aber die Trainingszeit ist für große Datensätze immer noch recht lang.
- Es reagiert empfindlich auf Ausreißer.
10. Lokale gewichtete lineare Regression
In der lokalen gewichteten linearen Regression (lokale gewichtete lineare Regression) führen wir auch eine lineare Regression durch. Im Gegensatz zur gewöhnlichen linearen Regression ist die lokal gewichtete lineare Regression jedoch eine lokale lineare Regressionsmethode. Durch die Einführung von Gewichten (Kernelfunktionen) werden bei der Vorhersage nur einige Stichproben verwendet, die nahe an den Testpunkten liegen, um die Regressionskoeffizienten zu berechnen. Bei der gewöhnlichen linearen Regression handelt es sich um eine globale lineare Regression, bei der alle Stichproben zur Berechnung von Regressionskoeffizienten verwendet werden ist erforderlich. Wenn die multiple lineare Regression zu einer Überanpassung führt, können Sie die lokale Gewichtung des Gaußschen Kernels ausprobieren, um eine Überanpassung zu verhindern.
11. Bayesianische Ridge-RegressionDas mit der Bayesianischen Inferenzmethode gelöste lineare Regressionsmodell wird Bayesianische lineare Regression genannt Berechnen Sie den Posterior aus dem Prior. Die Bayes'sche lineare Regression kann mit numerischen Methoden gelöst werden, und unter bestimmten Bedingungen können auch Posterior- oder verwandte Statistiken in analytischer Form erhalten werden.
Die Bayes'sche lineare Regression verfügt über die grundlegenden Eigenschaften bayes'scher statistischer Modelle und kann nach Gewichtskoeffizienten und Wahrscheinlichkeitsdichtefunktionen aufgelöst werden , Online-Lernen und Testen von Modellhypothesen basierend auf dem Bayes-Faktor (Bayes-Faktor)
Vorteile und Nachteile und anwendbare Szenarien
Der Vorteil der Bayes'schen Regression ist ihre Datenanpassungsfähigkeit, sie kann Daten wiederverwenden und eine Überanpassung verhindern. Im Schätzprozess können Regularisierungsterme eingeführt werden. Durch die Einführung des L2-Regularisierungsterms kann beispielsweise die Bayes'sche Ridge-Regression realisiert werden. Der Nachteil besteht darin, dass der Lernprozess zu teuer ist. Wenn die Anzahl der Features weniger als 10 beträgt, können Sie die Bayes'sche Regression ausprobieren.
Das obige ist der detaillierte Inhalt vonHäufig verwendete Regressionsalgorithmen und ihre Eigenschaften in Anwendungen des maschinellen Lernens. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was ist künstliche Intelligenz, maschinelles Lernen und Deep Learning?
- Einführung in häufig verwendete Bibliotheken für maschinelles Lernen und Deep Learning in Python (Zusammenfassungsfreigabe)
- Künstliche Intelligenz (KI), maschinelles Lernen (ML) und Deep Learning (DL): Was ist der Unterschied?
- Welche Anwendungen gibt es für maschinelles Lernen?
- Demonstration der 68-95-99,7-Regel in der Statistik mit Python