
Heim >Technologie-Peripheriegeräte >KI >Eine Pflichtlektüre für KI-Produktmanager! Ein Anfängerleitfaden für den Einstieg in Algorithmen für maschinelles Lernen
Eine Pflichtlektüre für KI-Produktmanager! Ein Anfängerleitfaden für den Einstieg in Algorithmen für maschinelles Lernen

- 王林nach vorne
- 2023-11-28 17:25:46863Durchsuche
Der Inhalt des Qujie-Algorithmus für maschinelles Lernen ist das Thema des nächsten Artikels. Dieser Artikel richtet sich an Studierende, die KI-Produktmanager sind, und wird Studierenden, die gerade erst in dieses Fachgebiet eingestiegen sind, dringend empfohlen!

Wir haben bereits über die Branche der künstlichen Intelligenz, die zweite Kurve der Produktmanager und die Unterschiede zwischen den beiden Positionen gesprochen. Dieses Mal werden wir uns eingehender mit der nächsten Ebene befassen – interessanten Algorithmen für maschinelles Lernen.
Maschinelle Lernalgorithmen klingen vielleicht etwas unverständlich. Ich verstehe, dass viele Menschen, auch ich, am Anfang Kopfschmerzen haben. Ich versuche, sie nur in Form von Fällen darzustellen zum Teil.
1. Übersicht über maschinelle Lernalgorithmen
Lassen Sie uns zunächst die Grundkonzepte von Algorithmen für maschinelles Lernen verstehen.
Maschinelles Lernen ist eine Methode, mit der Computer anhand von Daten lernen und sich verbessern können, und Algorithmen für maschinelles Lernen sind die Werkzeuge, um dies zu erreichen
Einfach ausgedrückt ist ein Algorithmus für maschinelles Lernen eine Reihe von Regeln oder Modellen, die auf der Grundlage von Eingabedaten lernen und dann auf der Grundlage des erlernten Wissens Vorhersagen oder Entscheidungen treffen können.
Lustiger Moment: Stellen Sie sich vor, Sie nehmen an einer mysteriösen Schatzsuche teil. Im Spiel müssen Sie anhand einer Schatzkarte den Standort des Schatzes finden. Bei dieser Schatzkarte handelt es sich um die Daten, und alles, was Sie tun müssen, ist, den Schatz zu finden, indem Sie die Daten analysieren. Im wirklichen Leben können wir diese Aufgabe durch maschinelle Lernalgorithmen erreichen.
Der maschinelle Lernalgorithmus ist wie ein intelligenter Schatzsuchroboter, der Muster aus großen Datenmengen lernen und dann auf der Grundlage dieser Muster Vorhersagen oder Entscheidungen treffen kann. Das Hauptziel von Algorithmen für maschinelles Lernen besteht darin, den Zuordnungsfehler von Daten zu Ergebnissen zu reduzieren und dadurch unsere Produkte intelligenter und genauer zu machen.
Maschinelle Lernalgorithmen haben ein breites Spektrum an Anwendungsszenarien, darunter Klassifizierungsprobleme, Clusteranalysen und Regressionsprobleme. Diese drei Anwendungsszenarien haben ihre eigenen Anwendungen im wirklichen Leben. Als nächstes werden ihre Anwendungsszenarien bzw. praktischen Anwendungen vorgestellt
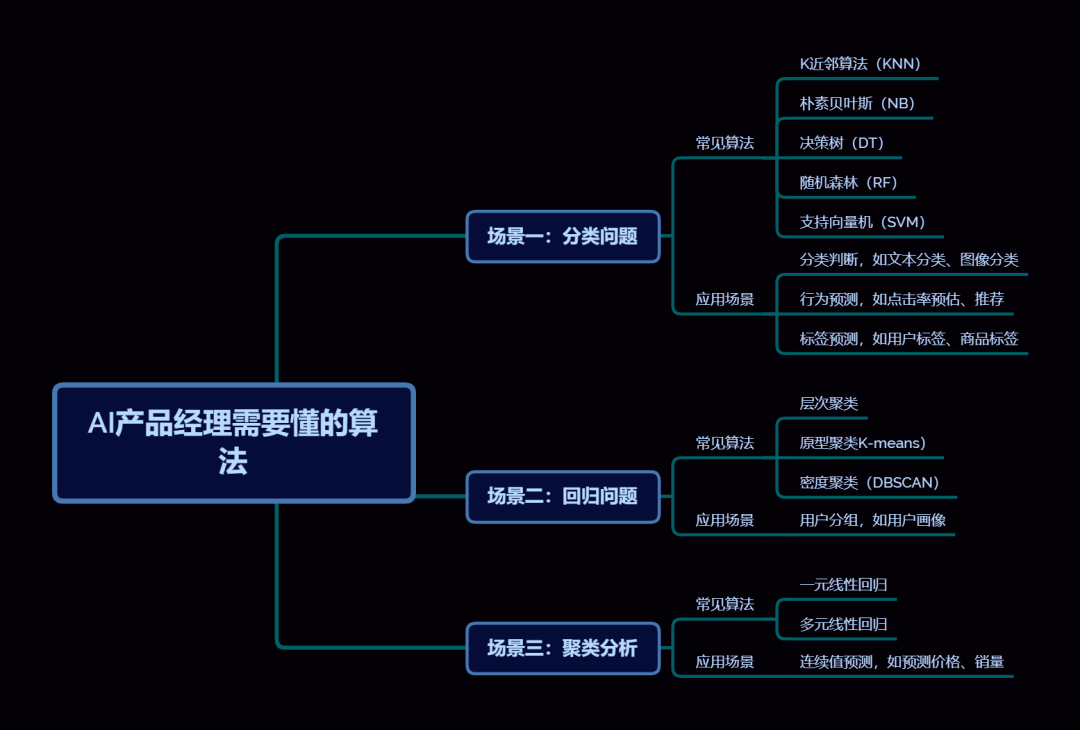
2. Szenario 1: Klassifizierungsproblem
1) Anwendungsszenarien: Klassifizierungsbeurteilung, Etikettenvorhersage, Verhaltensvorhersage.
2) Lösungsprinzip: Trainieren Sie die bekannten Daten und sagen Sie die unbekannten Daten voraus (einschließlich zweier Klassifizierungen und Mehrfachklassifizierungen). Wenn das Vorhersageergebnis nur zwei diskrete Werte aufweist, z. B. „0/1, ja/nein“, wird dies der Fall sein Seien Sie zwei Klassifizierungen. Wenn das Vorhersageergebnis aus mehreren diskreten Werten besteht, z. B. „A/B/C“, handelt es sich um eine Mehrfachklassifizierung.
Zu den gängigen Klassifizierungsalgorithmen gehören die folgenden:
- Entscheidungsbaum: Der Entscheidungsbaum ist ein auf einer Baumstruktur basierender Klassifizierungsalgorithmus, der Daten anhand einer Reihe von Fragen klassifiziert.
- Support Vector Machine: Support Vector Machine ist ein auf geometrischen Konzepten basierender Klassifizierungsalgorithmus, der eine Klassifizierung durchführt, indem er die Hyperebene mit dem maximalen Rand im Datenraum findet.
4) Fall: Spam verhindern
Spam-Filterung ist ein typisches Klassifizierungsproblem. Wir können den Support-Vector-Machine-Algorithmus verwenden, um dieses Problem zu lösen. Durch das Training des Modells können wir anhand der Schlüsselwörter, des Absenders und anderer Informationen in der E-Mail genau bestimmen, ob es sich bei der E-Mail um Spam oder eine normale E-Mail handelt
3. Szenario 2: Clusteranalyse
1) Anwendungsszenarien: Benutzergruppierung, Benutzerporträts
2) Lösungsprinzip: Clusteranalyse ist der Prozess der Aufteilung eines Datensatzes in mehrere Kategorien. Diese Kategorien basieren auf intrinsischen Eigenschaften oder Ähnlichkeiten der Daten. Um seine Eigenschaften in einem Wort zusammenzufassen: „Vögel gleichen Federn scharen sich zusammen“.
3) Gängige Clustering-Algorithmen
- K-Means-Clustering: K-Means-Clustering ist ein distanzbasierter Clustering-Algorithmus. Es unterteilt Datenpunkte in K Kategorien, indem der Abstand zwischen ihnen iterativ berechnet wird.
- Hierarchisches Clustering: Hierarchisches Clustering ist ein distanzbasierter Clustering-Algorithmus. Es unterteilt ähnliche Datenpunkte schrittweise in eine Kategorie, indem der Abstand zwischen Datenpunkten berechnet wird.
4) Fall: Kundensegmentierung
Für die Kundensegmentierung handelt es sich um eine gängige Anwendung zur Clusteranalyse. Mit dem K-Means-Clustering-Algorithmus können wir Kunden anhand ihrer Konsummenge, Kaufhäufigkeit und anderen Merkmalen in verschiedene Kategorien einteilen, um so präzise Marketingstrategien zu formulieren
4. Szenario 3: Regressionsproblem
1) Anwendungsszenario: Zukünftige Preise und Verkäufe vorhersagen.
2) Lösungsprinzip: Passen Sie ein Diagramm (gerade Linie/Kurve) entsprechend der Verteilung der Stichprobe an, bilden Sie ein Gleichungssystem, geben Sie Parameter ein und sagen Sie bestimmte Werte für die Zukunft voraus.
3) Gängige Regressionsalgorithmen
- Lineare Regression: Die lineare Regression ist ein Regressionsalgorithmus, der auf linearen Beziehungen basiert. Es sagt zukünftige Daten voraus, indem es eine lineare Beziehung zwischen Datenpunkten anpasst.
- Entscheidungsbaum-Regression: Die Entscheidungsbaum-Regression ist ein Regressionsalgorithmus, der auf einer Baumstruktur basiert. Es sagt den Zielwert anhand einer Reihe von Fragen voraus.
- Support Vector Machine Regression: Support Vector Machine Regression ist ein Regressionsalgorithmus, der auf geometrischen Konzepten basiert. Es sagt den Zielwert voraus, indem es die Hyperebene mit dem maximalen Rand im Datenraum findet.
4) Case-Aktienkursprognose
Aktienkursvorhersage ist ein typisches Regressionsproblem. Wir können lineare Regression oder Support-Vector-Machine-Regressionsalgorithmen verwenden, um zukünftige Aktienkurse auf der Grundlage historischer Aktienkursdaten vorherzusagen.
5. Letzte Worte
Zusammenfassend besteht der Hauptzweck dieses Artikels darin, gängige Algorithmen für maschinelles Lernen vorzustellen. Als nächstes werde ich die Algorithmen der drei Anwendungsszenarien einzeln analysieren. Wenn Sie mehr über Algorithmen erfahren möchten, teilen Sie diese bitte im Kommentarbereich mit. Willkommen zum gemeinsamen Erstellen und Teilen
Ich hoffe, es kann dich inspirieren, komm schon!Bitte drucken Sie diesen Artikel nicht erneut aus. Dieser Artikel wurde ursprünglich von @六星笑 Product auf „Jeder ist ein Produktmanager ohne Erlaubnis“ veröffentlicht
Das Titelbild stammt von Unsplash, basierend auf der CC0-Lizenz
Das obige ist der detaillierte Inhalt vonEine Pflichtlektüre für KI-Produktmanager! Ein Anfängerleitfaden für den Einstieg in Algorithmen für maschinelles Lernen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!