
Heim >Technologie-Peripheriegeräte >KI >Stabile Videoverbreitung ist da, Codegewicht ist online
Stabile Videoverbreitung ist da, Codegewicht ist online

- PHPznach vorne
- 2023-11-22 14:30:481528Durchsuche
Stability AI, ein bekanntes KI-Zeichenunternehmen, ist endlich in die KI-generierte Videobranche eingestiegen.
Diesen Dienstag wurde Stable Video Diffusion, ein auf stabiler Diffusion basierendes Videogenerierungsmodell, eingeführt, und die KI-Community startete sofort eine Diskussion
Viele Leute sagten: „Wir haben endlich gewartet.“
Projektlink: https://github.com/Stability-AI/generative-models
Jetzt können Sie vorhandene statische Bilder verwenden, um ein paar Sekunden Video zu generieren
basierend auf Stabilität Das ursprüngliche Stable Diffusion-Graphmodell von AI, Stable Video Diffusion, hat sich zu einem der wenigen Videogenerierungsmodelle im Open-Source- oder kommerziellen Bereich entwickelt.


Aber es ist noch nicht für alle verfügbar. Stable Video Diffusion hat die Registrierung für die Benutzerwarteliste eröffnet (https://stability.ai/contact).
Laut Einleitung kann Stable Video Propagation leicht an eine Vielzahl nachgelagerter Aufgaben angepasst werden, einschließlich der Multi-View-Synthese aus einem einzelnen Bild durch Feinabstimmung an Multi-View-Datensätzen. Stable AI gab an, dass verschiedene Modelle geplant sind, um dieses Fundament aufzubauen und zu erweitern, ähnlich dem Ökosystem, das auf stabiler Diffusion basiert


über stabiles Video, das sich mit 3 bis 30 Mal pro Sekunde ausbreiten kann. Anpassbarer Rahmen Bildrate generiert Videos mit 14 und 25 Bildern
In externen Bewertungen bestätigte Stability AI, dass diese Modelle führende Closed-Source-Modelle in der Benutzerpräferenzforschung übertrafen:

Stability AI Es wird betont, dass Stabil Die Videoverbreitung ist derzeit nicht für reale oder direkte kommerzielle Anwendungen geeignet und das Modell wird auf der Grundlage von Benutzereinblicken und Feedback zu Sicherheit und Qualität verbessert.

Papieradresse: https://stability.ai/research/stable-video-diffusion-scaling-latent-video-diffusion-models-to-large-datasets
Stabile Videoübertragung ist A Mitglied der stabilen KI-Open-Source-Modellfamilie. Nun scheint es, dass ihre Produkte mehrere Modalitäten wie Bilder, Sprache, Audio, 3D und Code abdecken, was ihr Engagement für die Verbesserung der künstlichen Intelligenz voll und ganz unter Beweis stellt Als Diffusionsmodell für hochauflösende Videos hat das Videodiffusionsmodell die SOTA-Ebene von Text-zu-Video oder Bild-zu-Video erreicht. Kürzlich wurden latente Diffusionsmodelle, die für die 2D-Bildsynthese trainiert wurden, in generative Videomodelle umgewandelt, indem zeitliche Schichten eingefügt und an kleinen, hochwertigen Videodatensätzen verfeinert wurden. Allerdings variieren die Trainingsmethoden in der Literatur stark, und die Fachwelt muss sich noch auf eine einheitliche Strategie für die Kuratierung von Videodaten einigen
In dem Artikel „Stable Video Diffusion“ identifiziert und bewertet Stability AI drei verschiedene Phasen für ein erfolgreiches Training latenter Videos Diffusionsmodelle: Text-zu-Bild-Vortraining, Video-Vortraining und hochwertige Video-Feinabstimmung. Sie zeigen auch die Bedeutung sorgfältig vorbereiteter Datensätze vor dem Training für die Generierung hochwertiger Videos und beschreiben einen systematischen Kurationsprozess zum Trainieren eines starken Basismodells, einschließlich Untertiteln und Filterstrategien.
Stabilitäts-KI untersucht in dem Artikel auch die Auswirkungen der Feinabstimmung des Basismodells auf hochwertige Daten und trainiert ein Text-zu-Video-Modell, das mit der Closed-Source-Videogenerierung vergleichbar ist. Das Modell bietet eine leistungsstarke Bewegungsdarstellung für nachgelagerte Aufgaben wie die Bild-zu-Video-Generierung und die Anpassungsfähigkeit an kamerabewegungsspezifische LoRA-Module. Darüber hinaus ist das Modell auch in der Lage, einen leistungsstarken 3D-Vorgang mit mehreren Ansichten bereitzustellen, der als Grundlage für ein Diffusionsmodell mit mehreren Ansichten verwendet werden kann. Das Modell generiert mehrere Ansichten eines Objekts in einer Feed-Forward-Methode, die nur erforderlich ist geringer Bedarf an Rechenleistung und Leistung Übertrifft auch bildbasierte Methoden .

Konkret erfordert das erfolgreiche Training dieses Modells die folgenden drei Phasen:
Phase 1: Bild-Vortraining. Dieser Artikel betrachtet das Bild-Vortraining als die erste Stufe der Trainingspipeline und baut das anfängliche Modell auf Stable Diffusion 2.1 auf, wodurch das Videomodell mit einer leistungsstarken visuellen Darstellung ausgestattet wird. Um den Effekt des Bildvortrainings zu analysieren, werden in diesem Artikel auch zwei identische Videomodelle trainiert und verglichen. Die Ergebnisse aus Abbildung 3a zeigen, dass das vorab trainierte Bildmodell sowohl hinsichtlich der Qualität als auch der Cue-Verfolgung bevorzugt wird.
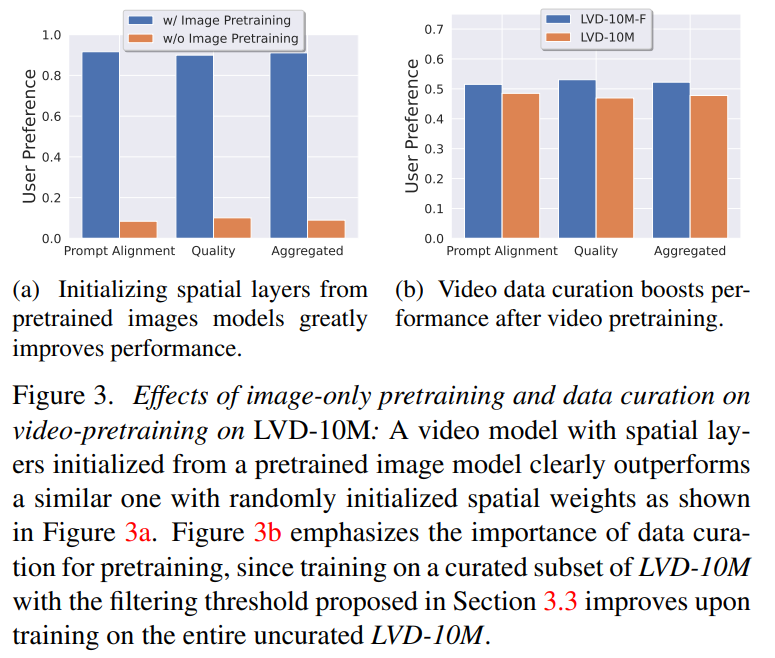
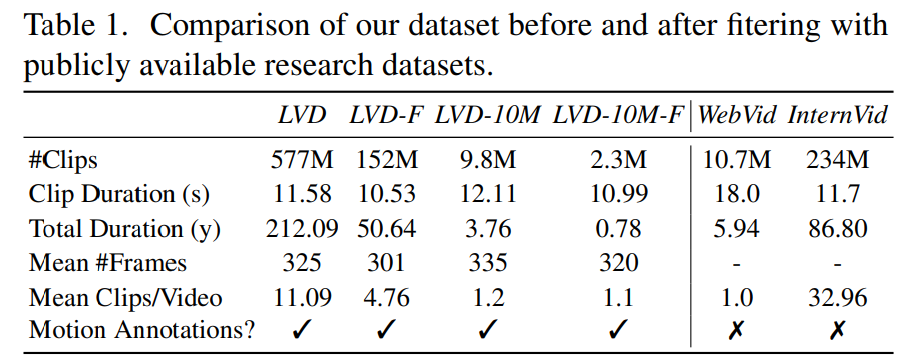
Phase 2: Video-Datensatz vor dem Training. Dieser Artikel basiert auf menschlichen Vorlieben als Signalen, um geeignete Datensätze vor dem Training zu erstellen. Der in diesem Artikel erstellte Datensatz ist LVD (Large Video Dataset), der aus 580 Millionen Paaren kommentierter Videoclips besteht.
Weitere Untersuchungen ergaben, dass der generierte Datensatz einige Beispiele enthielt, die die Leistung des endgültigen Videomodells beeinträchtigen könnten. Daher verwenden wir in diesem Artikel einen dichten optischen Fluss, um den Datensatz mit Anmerkungen zu versehen
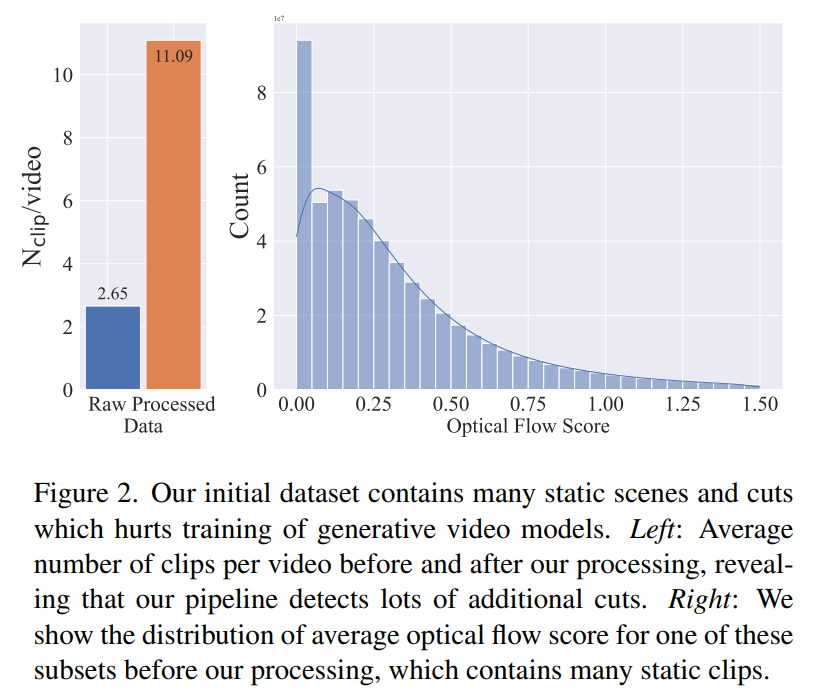
Darüber hinaus wendet dieser Artikel auch die optische Zeichenerkennung an, um Clips mit einer großen Textmenge zu bereinigen. Schließlich verwenden wir CLIP-Einbettungen, um das erste, mittlere und letzte Bild jedes Clips mit Anmerkungen zu versehen. Die folgende Tabelle enthält einige Statistiken des LVD-Datensatzes:
Phase 3: Hochwertige Feinabstimmung. Um die Auswirkungen des Video-Vortrainings auf die Endphase zu analysieren, werden in diesem Artikel drei Modelle verfeinert, die sich nur in der Initialisierung unterscheiden. Abbildung 4e zeigt die Ergebnisse.

Sieht aus, als wäre das ein guter Anfang. Wann können wir KI nutzen, um direkt einen Film zu generieren?
Das obige ist der detaillierte Inhalt vonStabile Videoverbreitung ist da, Codegewicht ist online. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Die C-Sprache kann beim Aufrufen der Funktion in main keinen Bezeichner finden
- Mit welcher Software können AI-Dateien geöffnet und bearbeitet werden?
- Welche Software ist das Tencent QQMail-Plugin?
- Welche Protokolle gehören zur Anwendungsschicht im TCP-IP-Referenzmodell?
- Auf welcher Ebene des osi-Modells ist die Pfadauswahlfunktion abgeschlossen?