

 Technologie-PeripheriegeräteKIAusführliche Diskussion über die Anwendung des multimodalen Fusionswahrnehmungsalgorithmus beim autonomen Fahren
Technologie-PeripheriegeräteKIAusführliche Diskussion über die Anwendung des multimodalen Fusionswahrnehmungsalgorithmus beim autonomen FahrenAusführliche Diskussion über die Anwendung des multimodalen Fusionswahrnehmungsalgorithmus beim autonomen Fahren

Bitte wenden Sie sich an die Quelle, um die Erlaubnis zum Nachdruck dieses Artikels zu erhalten. Dieser Artikel wurde vom öffentlichen Konto Autonomous Driving Heart veröffentlicht war der Schlüssel zur Automatik. Ein wichtiger Teil der Fahrwahrnehmung. Allerdings haben eine unzureichende Informationsnutzung, Rauschen in den Originaldaten und eine Fehlausrichtung zwischen verschiedenen Sensoren (z. B. nicht synchronisierte Zeitstempel) zu einer eingeschränkten Fusionsleistung geführt. In diesem Artikel werden bestehende multimodale Wahrnehmungsalgorithmen für autonomes Fahren, darunter LiDAR und Kameras, umfassend untersucht und mehr als 50 Dokumente analysiert. Anders als bei der herkömmlichen Klassifizierungsmethode von Fusionsalgorithmen wird dieses Feld in diesem Artikel basierend auf den verschiedenen Fusionsstadien in zwei Hauptkategorien und vier Unterkategorien eingeteilt. Darüber hinaus analysiert dieser Artikel bestehende Probleme im aktuellen Bereich und bietet Hinweise für zukünftige Forschungsrichtungen.
2 Warum ist Multimodalität nötig?
Das liegt daran, dass der Single-Modal-Wahrnehmungsalgorithmus inhärente Mängel aufweist. Beispielsweise wird Lidar im Allgemeinen höher als die Kamera installiert. In komplexen realen Fahrszenarien können Objekte in der Frontkamera blockiert werden. In diesem Fall ist es möglich, Lidar zu verwenden, um das fehlende Ziel zu erfassen. Aufgrund der Einschränkungen der mechanischen Struktur verfügt LiDAR jedoch über unterschiedliche Auflösungen in unterschiedlichen Entfernungen und wird leicht durch extrem schlechte Wetterbedingungen wie starken Regen beeinträchtigt. Obwohl beide Sensoren alleine sehr gut funktionieren können, werden die komplementären Informationen von LiDAR und Kameras in Zukunft das autonome Fahren auf der Wahrnehmungsebene sicherer machen. In letzter Zeit haben multimodale Wahrnehmungsalgorithmen für autonomes Fahren große Fortschritte gemacht. Zu diesen Fortschritten gehören die modalübergreifende Merkmalsdarstellung, zuverlässigere Modalsensoren sowie komplexere und stabilere multimodale Fusionsalgorithmen und -techniken. Allerdings konzentrieren sich nur wenige Übersichten [15, 81] auf die Methodik selbst der multimodalen Fusion, und der Großteil der Literatur wird nach traditionellen Klassifizierungsregeln klassifiziert, nämlich vor der Fusion, tiefer (Merkmals-) Fusion und nach der Fusion konzentriert sich auf die Phase der Feature-Fusion im Algorithmus, sei es auf Datenebene, Feature-Ebene oder Vorschlagsebene. Bei dieser Klassifizierungsregel gibt es zwei Probleme: Erstens ist die Merkmalsdarstellung jeder Ebene nicht klar definiert; zweitens behandelt sie die beiden Zweige von Lidar und Kamera aus einer symmetrischen Perspektive, wodurch die Beziehung zwischen Merkmalsfusion und Merkmalsfusion in der LiDAR-Zweig. Der Fall der Feature-Fusion auf Datenebene im Kamerazweig. Zusammenfassend lässt sich sagen, dass die traditionelle Klassifizierungsmethode zwar intuitiv ist, aber nicht mehr für die Entwicklung aktueller multimodaler Fusionsalgorithmen geeignet ist, was Forscher bis zu einem gewissen Grad daran hindert, Forschung und Analyse aus einer Systemperspektive durchzuführen3 Aufgaben und öffentlich Wettbewerbe
Zu den gängigen Wahrnehmungsaufgaben gehören Zielerkennung, semantische Segmentierung, Tiefenvervollständigung und -vorhersage usw. Der Schwerpunkt dieses Artikels liegt auf der Erkennung und Segmentierung, beispielsweise der Erkennung von Hindernissen, Ampeln, Verkehrszeichen und der Segmentierung von Fahrspurlinien und Freiräumen. Die Aufgabe zur Wahrnehmung des autonomen Fahrens ist in der folgenden Abbildung dargestellt:Zu den allgemeinen öffentlichen Datensätzen gehören hauptsächlich KITTI, Waymo und nuScenes. Die folgende Abbildung fasst die Datensätze zur Wahrnehmung des autonomen Fahrens und ihre Eigenschaften zusammen.

Multimodale Fusion ist untrennbar mit der Form des Datenausdrucks verbunden und bezieht sich im Allgemeinen auf das RGB-Format oder Graustufenbild. Der Lidar-Zweig ist jedoch stark von Datenformaten abhängig Es werden verschiedene Datenformate abgeleitet. Es wird ein völlig anderes nachgelagertes Modelldesign vorgeschlagen, das zusammenfassend drei allgemeine Richtungen umfasst: Punktwolkendarstellung auf Basis von Punkten, voxelbasierte und zweidimensionale Kartierung. 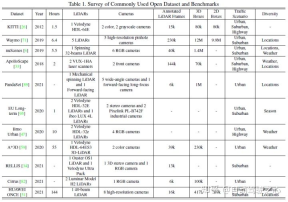
Pre-Fusion (Fusion auf Datenebene) bezieht sich auf die direkte Fusion von Rohsensordaten verschiedener Modalitäten durch räumliche Ausrichtung.
Deep Fusion (Feature-Level-Fusion) bezieht sich auf die Fusion modalübergreifender Daten im Feature-Raum durch Kaskaden- oder Elementmultiplikation.
Post-Fusion (Fusion auf Zielebene) bezieht sich auf die Fusion der Vorhersageergebnisse jedes Modalmodells, um die endgültige Entscheidung zu treffen.
- Der Artikel verwendet die Klassifizierungsmethode in der folgenden Abbildung, die im Allgemeinen in starke Fusion und schwache Fusion unterteilt wird. Starke Fusion kann in Frontfusion, tiefe Fusion, asymmetrische Fusion und Postfusion unterteilt werden.
- Dieser Artikel Verwendet die 3D-Erkennung von KITTI. Die Leistung jedes multimodalen Fusionsalgorithmus wird horizontal mit der BEV-Erkennungsaufgabe verglichen. Das folgende Bild ist das Ergebnis des BEV-Erkennungstestsatzes:
 Das Folgende ist ein Beispiel für das Ergebnis 3D-Erkennungstestset:
Das Folgende ist ein Beispiel für das Ergebnis 3D-Erkennungstestset:
5 Starke Fusion Wie in der obigen Abbildung dargestellt, ist ersichtlich, dass jedes Submodul der starken Fusion stark von der Lidar-Punktwolke und nicht von Kameradaten abhängt.
Pre-Fusion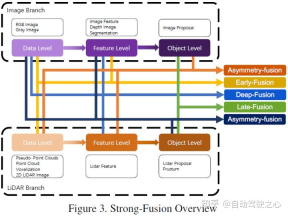
Im LiDAR Zweig, Punktwolken verfügen über viele Ausdrucksmethoden, wie z. B. Reflexionskarten und voxelisierte Bilder, Vorderansicht/Fernansicht/BEV-Ansicht und Pseudopunktwolke usw. Obwohl diese Daten in verschiedenen Backbone-Netzwerken unterschiedliche intrinsische Eigenschaften aufweisen, mit Ausnahme von Pseudopunktwolken [79], werden die meisten Daten durch bestimmte Regelverarbeitung generiert. Darüber hinaus sind diese LiDAR-Daten im Vergleich zur Einbettung von Merkmalsräumen gut interpretierbar und können direkt visualisiert werden. Im Bildzweig bezieht sich die Definition auf Datenebene im engeren Sinne auf RGB- oder Graustufenbilder, dieser Definition mangelt es jedoch an Universalität und Rationalität. Daher erweitert dieser Artikel die Definition von Bilddaten auf Datenebene in der Vorfusionsphase um Daten auf Datenebene und auf Merkmalsebene. Es ist erwähnenswert, dass dieser Artikel auch die Vorhersageergebnisse der semantischen Segmentierung als eine Art Vorfusion (Bildmerkmalsebene) betrachtet. Dies ist einerseits hilfreich für die 3D-Zielerkennung und andererseits, weil Die „Zielebene“ der semantischen Segmentierung unterscheidet sich vom endgültigen Zielebenenvorschlag der gesamten Aufgabe Daten auf der Merkmalsebene des LIDAR-Zweigs, nicht jedoch die Daten in der Bildzweigfusion auf der Satz- und Merkmalsebene. Einige Methoden verwenden beispielsweise Feature-Lifting, um eingebettete Darstellungen von LiDAR-Punktwolken bzw. -Bildern zu erhalten, und verschmelzen die Merkmale der beiden Modalitäten durch eine Reihe nachgeschalteter Module. Im Gegensatz zu anderen starken Fusionen werden Features bei der Deep Fusion jedoch manchmal kaskadenartig verschmolzen, wobei beide rohe und semantische Informationen auf hoher Ebene nutzen. Das schematische Diagramm sieht wie folgt aus:
Post-Fusion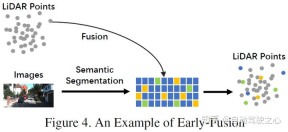
Post-Fusion, die auch als Fusion auf Zielebene bezeichnet werden kann, bezieht sich auf die Fusion von Vorhersageergebnissen (oder Vorschlägen) mehrerer Modalitäten. Beispielsweise nutzen einige Post-Fusion-Methoden die Ausgabe von LiDAR-Punktwolken und -Bildern für die Fusion [55]. Das Angebotsdatenformat für beide Zweige sollte mit den Endergebnissen übereinstimmen, es können jedoch Unterschiede in Qualität, Quantität und Genauigkeit bestehen. Die Postfusion kann als Integrationsmethode zur multimodalen Informationsoptimierung des endgültigen Vorschlags angesehen werden. Das schematische Diagramm sieht wie folgt aus:
Asymmetrische Fusion
Die letzte Art der starken Fusion ist die asymmetrische Fusion bezieht sich auf Es geht darum, die Informationen auf Zielebene eines Zweigs mit den Informationen auf Daten- oder Funktionsebene anderer Zweige zu verschmelzen. Die oben genannten drei Fusionsmethoden behandeln jeden Zweig der Multimodalität gleich, während die asymmetrische Fusion betont, dass mindestens ein Zweig dominant ist und andere Zweige Hilfsinformationen zur Vorhersage des Endergebnisses liefern. Die folgende Abbildung ist ein schematisches Diagramm der asymmetrischen Fusion. In der Vorschlagsphase hat die asymmetrische Fusion nur den Vorschlag eines Zweigs, und dann ist die Fusion der Vorschlag aller Zweige.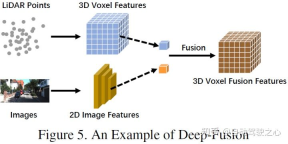
6 Der Unterschied zwischen schwacher Fusion
und starker Fusion besteht darin, dass die Methode der schwachen Fusion Daten, Features oder Ziele aus multimodalen Zweigen nicht direkt fusioniert, sondern die Daten in anderen Formen verarbeitet. Die folgende Abbildung zeigt das Grundgerüst des schwachen Fusionsalgorithmus. Auf schwacher Fusion basierende Methoden verwenden normalerweise bestimmte regelbasierte Methoden, um Daten von einer Modalität als Überwachungssignal zu nutzen, um die Interaktion einer anderen Modalität zu steuern. Beispielsweise kann der 2D-Vorschlag von CNN im Bildzweig zu einer Kürzung der ursprünglichen LiDAR-Punktwolke führen, und eine schwache Fusion gibt die ursprüngliche LiDAR-Punktwolke direkt in das LiDAR-Backbone ein, um den endgültigen Vorschlag auszugeben.
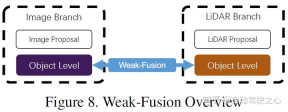
7 Andere Fusionsmethoden
Es gibt auch einige Arbeiten, die keinem der oben genannten Paradigmen angehören, weil sie im Rahmen des Modelldesigns mehrere Fusionsmethoden verwenden, wie zum Beispiel [39], das tief kombiniert Fusion und Post-Processing Fusion[77] kombiniert die Vorfusion. Diese Methoden sind nicht die gängigen Methoden für das Design von Fusionsalgorithmen und werden in diesem Artikel in andere Fusionsmethoden eingeteilt.
8 Möglichkeiten der multimodalen Fusion
In den letzten Jahren haben multimodale Fusionsmethoden für autonome Fahrwahrnehmungsaufgaben rasante Fortschritte gemacht, von fortschrittlicheren Merkmalsdarstellungen bis hin zu komplexeren Deep-Learning-Modellen. Es gibt jedoch noch einige offene Probleme, die gelöst werden müssen. In diesem Artikel werden einige mögliche zukünftige Verbesserungsrichtungen wie folgt zusammengefasst.
Fortgeschrittenere Fusionsmethoden
Aktuelle Fusionsmodelle leiden unter Problemen mit Fehlausrichtung und Informationsverlust [13, 67, 98]. Darüber hinaus behindern flache Fusionsoperationen auch weitere Verbesserungen der Wahrnehmungsaufgabenleistung. Die Zusammenfassung lautet wie folgt:
- Verlagerung und Informationsverlust: Die internen und externen Unterschiede zwischen Kameras und LiDAR sind sehr groß und die Daten der beiden Modi müssen koordiniert werden. Herkömmliche Frontfusions- und Tiefenfusionsmethoden nutzen Kalibrierungsinformationen, um alle LiDAR-Punkte direkt in das Kamerakoordinatensystem zu projizieren und umgekehrt. Aufgrund des Einbauorts und des Sensorrauschens ist diese pixelweise Ausrichtung jedoch nicht genau genug. Daher nutzen einige Werke Umgebungsinformationen, um sie zu ergänzen und eine bessere Leistung zu erzielen. Darüber hinaus gehen während des Konvertierungsprozesses von Eingabe- und Feature-Räumen einige andere Informationen verloren. Normalerweise führt die Projektion von Dimensionsreduktionsoperationen unweigerlich zu einem großen Informationsverlust, beispielsweise dem Verlust von Höheninformationen bei der Zuordnung von 3D-LiDAR-Punktwolken zu 2D-BEV-Bildern. Daher können Sie erwägen, multimodale Daten einem anderen hochdimensionalen Raum zuzuordnen, der für die Fusion konzipiert ist, um die Originaldaten effektiv zu nutzen und Informationsverluste zu reduzieren.
- Vernünftigere Fusionsoperationen: Viele aktuelle Methoden verwenden Kaskaden- oder Elementmultiplikation für die Fusion. Bei diesen einfachen Operationen gelingt es möglicherweise nicht, Daten mit sehr unterschiedlichen Verteilungen zusammenzuführen, was es schwierig macht, semantische Red Dogs zwischen den beiden Modalitäten anzupassen. Einige Arbeiten versuchen, komplexere Kaskadenstrukturen zu verwenden, um Daten zusammenzuführen und die Leistung zu verbessern. In der zukünftigen Forschung können Mechanismen wie die bilineare Kartierung Merkmale mit unterschiedlichen Eigenschaften verschmelzen und auch Richtungen berücksichtigen.
Informationsnutzung aus mehreren Quellen
Ein zukunftsgerichtetes Einzelbild ist ein typisches Szenario für Wahrnehmungsaufgaben beim autonomen Fahren. Allerdings können die meisten Frameworks nur begrenzte Informationen nutzen und Hilfsaufgaben nicht im Detail entwerfen, um das Verständnis von Fahrszenarien zu erleichtern. Die Zusammenfassung lautet wie folgt:
- Mehr potenzielle Informationen nutzen: Bestehende Methoden mangelt es an einer effektiven Nutzung von Informationen aus mehreren Dimensionen und Quellen. Die meisten konzentrieren sich auf multimodale Einzelbilddaten in der Vorderansicht. Dies führt dazu, dass andere aussagekräftige Daten wie semantische, räumliche und Szenenkontextinformationen nicht ausreichend genutzt werden. Einige Arbeiten versuchen, semantische Segmentierungsergebnisse zur Unterstützung der Aufgabe zu nutzen, während andere Modelle möglicherweise Zwischenschichtmerkmale des CNN-Backbones nutzen. In autonomen Fahrszenarien können viele nachgelagerte Aufgaben mit expliziten semantischen Informationen die Objekterkennungsleistung erheblich verbessern, beispielsweise die Erkennung von Fahrspurlinien, Ampeln und Verkehrszeichen. Zukünftige Forschungen können nachgelagerte Aufgaben kombinieren, um gemeinsam einen vollständigen semantischen Verständnisrahmen für städtische Szenen aufzubauen und so die Wahrnehmungsleistung zu verbessern. Darüber hinaus integriert [63] Inter-Frame-Informationen, um die Leistung zu verbessern. Zeitreiheninformationen enthalten serialisierte Überwachungssignale, die im Vergleich zu Einzelbildmethoden stabilere Ergebnisse liefern können. Zukünftige Arbeiten könnten daher eine stärkere Nutzung zeitlicher, kontextueller und räumlicher Informationen in Betracht ziehen, um Leistungsdurchbrüche zu erzielen.
- Selbstüberwachtes Repräsentationslernen: Gegenseitig überwachte Signale existieren natürlich in modalübergreifenden Daten, die aus derselben realen Szene, jedoch aus unterschiedlichen Blickwinkeln, abgetastet werden. Aufgrund des Mangels an tiefgreifendem Verständnis der Daten können aktuelle Methoden jedoch nicht die Wechselbeziehungen zwischen verschiedenen Modalitäten ermitteln. Zukünftige Forschungen können sich darauf konzentrieren, wie multimodale Daten für selbstüberwachtes Lernen genutzt werden können, einschließlich Pre-Training, Feinabstimmung oder kontrastivem Lernen. Durch diese hochmodernen Mechanismen werden Fusionsalgorithmen das tiefere Verständnis des Modells für die Daten vertiefen und gleichzeitig eine bessere Leistung erzielen.
Inhärente Sensorprobleme
Reale Szenen und Sensorhöhen können sich auf die Domänenverzerrung und die Auflösung auswirken. Diese Mängel werden das groß angelegte Training und den Echtzeitbetrieb von Deep-Learning-Modellen für autonomes Fahren behindern
- Domänenverzerrung: In autonomen Fahrwahrnehmungsszenarien werden die von verschiedenen Sensoren extrahierten Rohdaten von schwerwiegenden domänenbezogenen Merkmalen begleitet. Verschiedene Kameras haben unterschiedliche optische Eigenschaften und LiDAR kann von mechanischen bis hin zu Festkörperstrukturen variieren. Darüber hinaus weisen die Daten selbst Domänenverzerrungen auf, beispielsweise Wetter, Jahreszeit oder geografische Lage, selbst wenn sie vom selben Sensor erfasst wurden. Dadurch wird die Verallgemeinerung des Erkennungsmodells beeinträchtigt und es kann sich nicht effektiv an neue Szenarien anpassen. Solche Mängel behindern die Erfassung umfangreicher Datensätze und die Wiederverwendbarkeit ursprünglicher Trainingsdaten. Daher kann sich die Zukunft darauf konzentrieren, eine Methode zur Eliminierung von Domain-Bias und zur adaptiven Integration verschiedener Datenquellen zu finden.
- Auflösungskonflikt: Verschiedene Sensoren haben normalerweise unterschiedliche Auflösungen. Beispielsweise ist die räumliche Dichte von LiDAR deutlich geringer als die von Bildern. Unabhängig davon, welche Projektionsmethode verwendet wird, kommt es zu Informationsverlusten, da die entsprechende Beziehung nicht gefunden werden kann. Dies kann dazu führen, dass das Modell von Daten einer bestimmten Modalität dominiert wird, sei es aufgrund unterschiedlicher Auflösungen der Merkmalsvektoren oder eines Ungleichgewichts in den Rohinformationen. Daher könnte zukünftige Arbeit ein neues Datendarstellungssystem untersuchen, das mit Sensoren unterschiedlicher räumlicher Auflösung kompatibel ist.
9 Referenz
[1] https://zhuanlan.zhihu.com/p/470588787
[2] Multimodale Sensorfusion für die Wahrnehmung des Autofahrens: Eine Umfrage

Originallink: https ://mp.weixin.qq.com/s/usAQRL18vww9YwMXRvEwLw
Das obige ist der detaillierte Inhalt vonAusführliche Diskussion über die Anwendung des multimodalen Fusionswahrnehmungsalgorithmus beim autonomen Fahren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Die meisten verwendeten 10 Power BI -Diagramme - Analytics VidhyaApr 16, 2025 pm 12:05 PM
Die meisten verwendeten 10 Power BI -Diagramme - Analytics VidhyaApr 16, 2025 pm 12:05 PMNutzung der Leistung der Datenvisualisierung mit Microsoft Power BI -Diagrammen In der heutigen datengesteuerten Welt ist es entscheidend, komplexe Informationen effektiv mit nicht-technischem Publikum zu kommunizieren. Die Datenvisualisierung schließt diese Lücke und transformiert Rohdaten i
 Expertensysteme in KIApr 16, 2025 pm 12:00 PM
Expertensysteme in KIApr 16, 2025 pm 12:00 PMExpertensysteme: Ein tiefes Eintauchen in die Entscheidungsfunktion der KI Stellen Sie sich vor, Zugang zu Expertenberatung zu irgendetwas, von medizinischen Diagnosen bis hin zur Finanzplanung. Das ist die Kraft von Expertensystemen in der künstlichen Intelligenz. Diese Systeme imitieren den Profi
 Drei der besten Vibe -Codierer brechen diese KI -Revolution im Code aufApr 16, 2025 am 11:58 AM
Drei der besten Vibe -Codierer brechen diese KI -Revolution im Code aufApr 16, 2025 am 11:58 AMZunächst ist es offensichtlich, dass dies schnell passiert. Verschiedene Unternehmen sprechen über die Proportionen ihres Code, die derzeit von KI verfasst wurden, und diese nehmen mit einem schnellen Clip zu. Es gibt bereits viel Arbeitsplatzverschiebung
 Runway Ai's Gen-4: Wie kann eine Montage über Absurd hinausgehenApr 16, 2025 am 11:45 AM
Runway Ai's Gen-4: Wie kann eine Montage über Absurd hinausgehenApr 16, 2025 am 11:45 AMDie Filmindustrie befindet sich neben allen kreativen Sektoren vom digitalen Marketing bis hin zu sozialen Medien an einer technologischen Kreuzung. Als künstliche Intelligenz beginnt, jeden Aspekt des visuellen Geschichtenerzählens umzugestiegen und die Landschaft der Unterhaltung zu verändern
 Wie kann man sich 5 Tage lang anmelden. - Analytics VidhyaApr 16, 2025 am 11:43 AM
Wie kann man sich 5 Tage lang anmelden. - Analytics VidhyaApr 16, 2025 am 11:43 AMDer kostenlose KI/ML -Online -Kurs von ISRO: Ein Tor zu Geospatial Technology Innovation Die Indian Space Research Organization (ISRO) bietet durch ihr indisches Institut für Fernerkundung (IIRS) eine fantastische Gelegenheit für Studenten und Fachkräfte
 Lokale Suchalgorithmen in KIApr 16, 2025 am 11:40 AM
Lokale Suchalgorithmen in KIApr 16, 2025 am 11:40 AMLokale Suchalgorithmen: Ein umfassender Leitfaden Die Planung eines groß angelegten Ereignisses erfordert eine effiziente Verteilung der Arbeitsbelastung. Wenn herkömmliche Ansätze scheitern, bieten lokale Suchalgorithmen eine leistungsstarke Lösung. In diesem Artikel wird Hill Climbing und Simul untersucht
 OpenAI-Verschiebungen Fokus mit GPT-4.1, priorisiert die Codierung und KosteneffizienzApr 16, 2025 am 11:37 AM
OpenAI-Verschiebungen Fokus mit GPT-4.1, priorisiert die Codierung und KosteneffizienzApr 16, 2025 am 11:37 AMDie Veröffentlichung umfasst drei verschiedene Modelle, GPT-4.1, GPT-4.1 Mini und GPT-4.1-Nano, die einen Zug zu aufgabenspezifischen Optimierungen innerhalb der Landschaft des Großsprachenmodells signalisieren. Diese Modelle ersetzen nicht sofort benutzergerichtete Schnittstellen wie
 Die Eingabeaufforderung: Chatgpt generiert gefälschte PässeApr 16, 2025 am 11:35 AM
Die Eingabeaufforderung: Chatgpt generiert gefälschte PässeApr 16, 2025 am 11:35 AMDer Chip Giant Nvidia sagte am Montag, es werde zum ersten Mal in den USA die Herstellung von KI -Supercomputern - Maschinen mit der Verarbeitung reichlicher Daten herstellen und komplexe Algorithmen ausführen. Die Ankündigung erfolgt nach Präsident Trump SI


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

SAP NetWeaver Server-Adapter für Eclipse
Integrieren Sie Eclipse mit dem SAP NetWeaver-Anwendungsserver.

Sicherer Prüfungsbrowser
Safe Exam Browser ist eine sichere Browserumgebung für die sichere Teilnahme an Online-Prüfungen. Diese Software verwandelt jeden Computer in einen sicheren Arbeitsplatz. Es kontrolliert den Zugriff auf alle Dienstprogramme und verhindert, dass Schüler nicht autorisierte Ressourcen nutzen.

Herunterladen der Mac-Version des Atom-Editors
Der beliebteste Open-Source-Editor

Dreamweaver CS6
Visuelle Webentwicklungstools

Dreamweaver Mac
Visuelle Webentwicklungstools

