
Heim >Technologie-Peripheriegeräte >KI >Implementieren Sie Python-Code, um die Abruffunktionen für große Modelle zu verbessern
Implementieren Sie Python-Code, um die Abruffunktionen für große Modelle zu verbessern

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-11-21 11:21:111787Durchsuche
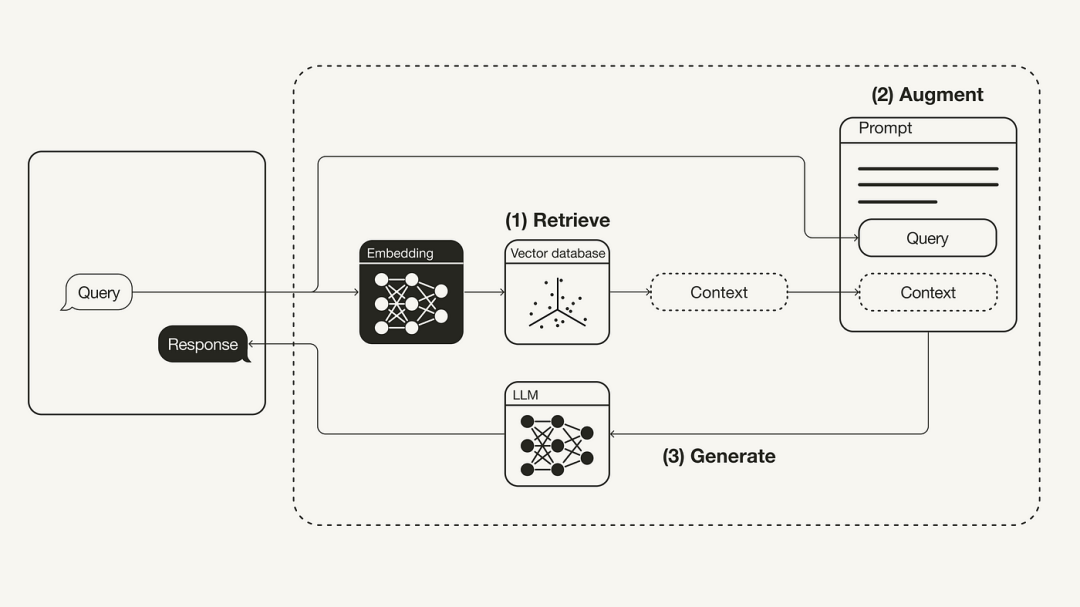
Der Hauptschwerpunkt dieses Artikels liegt auf dem Konzept und der Theorie von RAG. Als Nächstes zeigen wir, wie man LangChain, das OpenAI-Sprachmodell und die Weaviate-Vektordatenbank verwendet, um ein einfaches RAG-Orchestrierungssystem zu implementieren
Was ist die Generierung einer Abrufverbesserung?
Das Konzept der Retrieval Augmented Generation (RAG) bezieht sich auf die Bereitstellung zusätzlicher Informationen für LLM durch externe Wissensquellen. Dadurch kann LLM genauere und kontextbezogenere Antworten generieren und gleichzeitig Halluzinationen reduzieren.
Beim Umschreiben von Inhalten muss der Originaltext ohne den Originalsatz ins Chinesische umgeschrieben werden
Das derzeit beste LLM wird mit einer großen Datenmenge trainiert, sodass seine neuronalen Netzwerkgewichte in A gespeichert werden Menge des Allgemeinwissens (Parameterspeicher). Wenn die Eingabeaufforderung jedoch erfordert, dass LLM andere Kenntnisse als seine Trainingsdaten generiert (z. B. neue Informationen, proprietäre Daten oder domänenspezifische Informationen), können beim Umschreiben des Inhalts sachliche Ungenauigkeiten auftreten wurde ohne den ursprünglichen Satz (Illusion) ins Chinesische umgeschrieben, wie im Screenshot unten gezeigt:
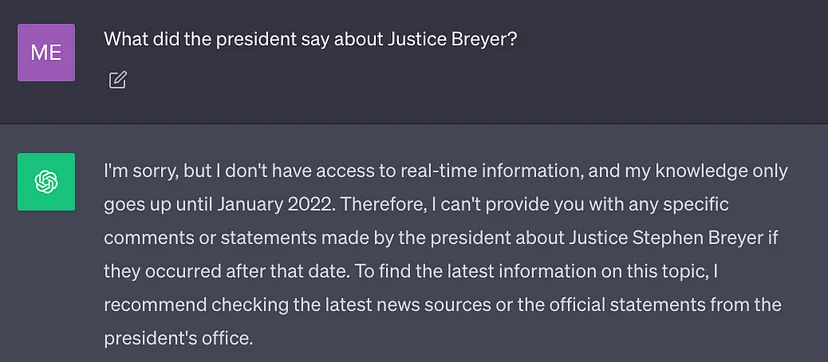
Daher ist es wichtig, das allgemeine Wissen über LLM mit zusätzlichem Kontext zu kombinieren, um genauere und genauere Ergebnisse zu generieren Weitere kontextbezogene Ergebnisse und weniger Halluzinationen
Lösung
Traditionell können wir neuronale Netze durch Feinabstimmung des Modells an bestimmte Domänen oder proprietäre Informationen anpassen. Obwohl diese Technik effektiv ist, erfordert sie große Mengen an Rechenressourcen, ist teuer und erfordert die Unterstützung technischer Experten, was eine schnelle Anpassung an sich ändernde Informationen erschwert „-Augmented Generation for Knowledge-Intensive NLP Tasks“ schlägt eine flexiblere Technologie vor: Retrieval Enhanced Generation (RAG). In diesem Artikel kombinieren die Forscher das generative Modell mit einem Abrufmodul, das mithilfe einer externen Wissensquelle, die einfacher zu aktualisieren ist, zusätzliche Informationen bereitstellen kann.
Um es im Volksmund auszudrücken: RAG ist für LLM das, was Open-Book-Prüfung für Menschen ist. Für Open-Book-Prüfungen können Studierende Referenzmaterialien wie Lehrbücher und Notizen mitbringen, in denen sie relevante Informationen zur Beantwortung der Fragen finden. Die Idee hinter Open-Book-Prüfungen besteht darin, dass sich die Prüfung auf die Denkfähigkeit der Schüler konzentriert und nicht auf ihre Fähigkeit, sich bestimmte Informationen zu merken.
In ähnlicher Weise unterscheidet sich De-facto-Wissen von LLM-Inferenzfähigkeiten und kann in externen Wissensquellen gespeichert werden, die leicht zugänglich und aktualisierbar sind Gewichte neuronaler Netze.
Nichtparametrisches Wissen: gespeichert in externen Wissensquellen, wie z. B. Vektordatenbanken.
- Das folgende Diagramm zeigt den grundlegendsten RAG-Workflow:
Retrieval: Anwenden von Benutzerabfragen, um relevanten Kontext abzurufen externe Wissensquellen. Dazu wird ein Einbettungsmodell verwendet, um die Benutzerabfrage in denselben Vektorraum als zusätzlichen Kontext in der Vektordatenbank einzubetten. Dadurch können Sie eine Ähnlichkeitssuche durchführen und die k Datenobjekte in dieser Vektordatenbank zurückgeben, die der Anfrage des Benutzers am nächsten kommen. 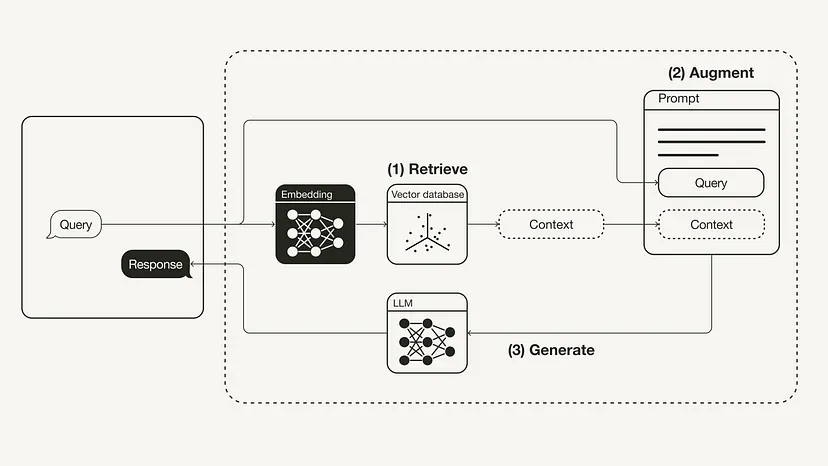
Verbesserung: Die Benutzerabfrage und der abgerufene zusätzliche Kontext werden dann in eine Eingabeaufforderungsvorlage eingefügt.
- Generierung: Schließlich wird die durch den Abruf verbesserte Eingabeaufforderung an LLM weitergeleitet.
- Verwenden Sie LangChain, um die Generierung von Abrufverbesserungen zu implementieren
- Im Folgenden wird die Implementierung des RAG-Workflows über Python vorgestellt, das OpenAI LLM und Weaviate-Vektordatenbanken sowie ein OpenAI-Einbettungsmodell verwendet. Die Rolle von LangChain ist die Orchestrierung.
Bitte umformulieren: Erforderliche Voraussetzungen
Bitte stellen Sie sicher, dass Sie die erforderlichen Python-Pakete installiert haben:
- langchain, Orchestrierung
- openai, eingebettetes Modell und LLM
- weaviate-client, Vektordatenbank
#!pip install langchain openai weaviate-client
Verwenden Sie außerdem eine .env-Datei im Stammverzeichnis, um relevante Umgebungsvariablen zu definieren. Sie benötigen ein OpenAI-Konto, um den OpenAI-API-Schlüssel zu erhalten, und klicken Sie dann unter „API-Schlüssel“ auf „Neuen Schlüssel erstellen“ (https://platform.openai.com/account/api-keys).
OPENAI_API_KEY="<your_openai_api_key>"</your_openai_api_key>
Führen Sie dann den folgenden Befehl aus, um die relevanten Umgebungsvariablen zu laden.
import dotenvdotenv.load_dotenv()
Vorbereitung
In der Vorbereitungsphase müssen Sie eine Vektordatenbank als externe Wissensquelle vorbereiten, um alle zusätzlichen Informationen zu speichern. Der Aufbau dieser Vektordatenbank umfasst die folgenden Schritte:
- Daten sammeln und laden
- Kategorie des Dokuments
- Einbetten der Textblöcke und Speichern
Der umgeschriebene Inhalt: Zuerst brauchen wir um die Daten zu sammeln und zu laden. Wenn wir beispielsweise die Rede von Präsident Biden zur Lage der Nation 2022 als zusätzlichen Kontext verwenden möchten, stellt das GitHub-Repository von LangChain das Originaltextdokument für diese Datei bereit. Um diese Daten zu laden, können wir die verschiedenen integrierten Tools zum Laden von Dokumenten in LangChain nutzen. Ein Dokument ist ein Wörterbuch, das aus Text und Metadaten besteht. Zum Laden von Text können Sie das TextLoader-Tool von LangChain verwenden. Originaldokumentadresse: https://raw.githubusercontent.com/langchain-ai/langchain/master/docs/docs/modules/state_of_the_union.txt Als nächstes teilen Sie das Dokument in Stücke auf. Da der Originalzustand des Dokuments zu lang ist, um in das Kontextfenster von LLM zu passen, muss es in kleinere Textabschnitte aufgeteilt werden. LangChain verfügt außerdem über viele integrierte Splitting-Tools. Für dieses einfache Beispiel können wir einen CharacterTextSplitter verwenden, bei dem chunk_size auf 500 und chunk_overlap auf 50 gesetzt ist, wodurch die Textkontinuität zwischen Textblöcken gewahrt bleibt.
import requestsfrom langchain.document_loaders import TextLoaderurl = "https://raw.githubusercontent.com/langchain-ai/langchain/master/docs/docs/modules/state_of_the_union.txt"res = requests.get(url)with open("state_of_the_union.txt", "w") as f:f.write(res.text)loader = TextLoader('./state_of_the_union.txt')documents = loader.load()
Zum Schluss den Textblock einbetten und speichern. Damit die semantische Suche über Textblöcke hinweg durchgeführt werden kann, müssen Vektoreinbettungen für jeden Textblock generiert und zusammen mit ihren Einbettungen gespeichert werden. Verwenden Sie zum Generieren von Vektoreinbettungen das OpenAI-Einbettungsmodell. Verwenden Sie zur Speicherung die Weaviate-Vektordatenbank. Textblöcke können durch Aufruf von .from_documents() automatisch in eine Vektordatenbank eingefügt werden.
from langchain.text_splitter import CharacterTextSplittertext_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)chunks = text_splitter.split_documents(documents)
Schritt 1: Abrufen
Nachdem wir die Vektordatenbank gefüllt haben, können wir sie als Retriever-Komponente definieren, die basierend auf der semantischen Ähnlichkeit zwischen der Benutzerabfrage und dem eingebetteten Block abgerufen werden kann Zusätzlicher Kontext from langchain.embeddings import OpenAIEmbeddingsfrom langchain.vectorstores import Weaviateimport weaviatefrom weaviate.embedded import EmbeddedOptionsclient = weaviate.Client(embedded_options = EmbeddedOptions())vectorstore = Weaviate.from_documents(client = client,documents = chunks,embedding = OpenAIEmbeddings(),by_text = False)
Schritt 2: Erweitern
retriever = vectorstore.as_retriever()
Schritt 3: Generieren
Schließlich können wir eine Gedankenkette für diesen RAG-Prozess aufbauen, die den Retriever, die Eingabeaufforderungsvorlage und das LLM miteinander verbindet. Sobald die RAG-Kette definiert ist, kann sie aufgerufen werden. die ursprünglich aus dem Artikel „Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks“ aus dem Jahr 2020 stammte. Nach einer Einführung in die Theorie hinter RAG, einschließlich Motivation und Lösungen, zeigt dieser Artikel, wie man es in Python implementiert. In diesem Artikel wird gezeigt, wie Sie einen RAG-Workflow mithilfe von OpenAI LLM in Verbindung mit der Weaviate-Vektordatenbank und dem OpenAI-Einbettungsmodell implementieren. Die Rolle von LangChain ist die Orchestrierung.
Das obige ist der detaillierte Inhalt vonImplementieren Sie Python-Code, um die Abruffunktionen für große Modelle zu verbessern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!