
Heim >Technologie-Peripheriegeräte >KI >Ein neuer Schritt in Richtung hochwertiger Bilderzeugung: Googles ultraschnelle Sampling-Methode UFOGen
Ein neuer Schritt in Richtung hochwertiger Bilderzeugung: Googles ultraschnelle Sampling-Methode UFOGen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-11-20 14:30:471462Durchsuche
Im vergangenen Jahr hat eine Reihe vinzentinischer Graphendiffusionsmodelle, die von Stable Diffusion repräsentiert werden, den Bereich der visuellen Kreation völlig verändert. Unzählige Benutzer haben ihre Produktivität mit Bildern verbessert, die von Diffusionsmodellen erstellt wurden. Allerdings ist die Geschwindigkeit der Generierung von Diffusionsmodellen ein häufiges Problem. Da das Entrauschungsmodell auf einer mehrstufigen Entrauschung beruht, um das anfängliche Gaußsche Rauschen schrittweise in ein Bild umzuwandeln, sind mehrere Berechnungen des Netzwerks erforderlich, was zu einer sehr langsamen Generierungsgeschwindigkeit führt. Dies macht das groß angelegte vinzentinische Graphendiffusionsmodell für einige Anwendungen, die sich auf Echtzeit und Interaktivität konzentrieren, sehr unfreundlich. Mit der Einführung einer Reihe von Technologien hat sich die Anzahl der Schritte, die für die Probenahme aus einem Diffusionsmodell erforderlich sind, von den ersten paar hundert Schritten auf Dutzende Schritte oder sogar nur 4–8 Schritte erhöht.
Kürzlich hat ein Forschungsteam von Google das UFOGen-Modell vorgeschlagen, eine Variante des Diffusionsmodells, das extrem schnell Proben aufnehmen kann. Durch die Feinabstimmung der stabilen Diffusion mit der im Artikel vorgeschlagenen Methode kann UFOGen in nur einem Schritt qualitativ hochwertige Bilder erzeugen. Gleichzeitig können auch die nachgelagerten Anwendungen von Stable Diffusion wie die Diagrammerstellung, ControlNet und andere Funktionen beibehalten werden.

Bitte klicken Sie auf den folgenden Link, um das Papier anzuzeigen: https://arxiv.org/abs/2311.09257
Wie Sie auf dem Bild unten sehen können, kann UFOGen qualitativ hochwertige und vielfältige Produkte generieren Bilder in nur einem Schritt.

Die Verbesserung der Generierungsgeschwindigkeit von Diffusionsmodellen ist keine neue Forschungsrichtung. Bisherige Forschungen in diesem Bereich konzentrierten sich hauptsächlich auf zwei Richtungen. Eine Richtung besteht darin, effizientere numerische Berechnungsmethoden zu entwerfen, um das Ziel zu erreichen, die Stichproben-ODE des Diffusionsmodells mit weniger diskreten Schritten zu lösen. Beispielsweise hat sich die vom Team von Zhu Jun an der Tsinghua-Universität vorgeschlagene DPM-Serie numerischer Löser als sehr effektiv bei der stabilen Diffusion erwiesen und kann die Anzahl der Lösungsschritte von den standardmäßigen 50 Schritten von DDIM auf weniger als 20 Schritte erheblich reduzieren. Eine andere Richtung besteht darin, die Wissensdestillationsmethode zu verwenden, um den ODE-basierten Abtastpfad des Modells auf eine kleinere Anzahl von Schritten zu komprimieren. Beispiele in dieser Richtung sind die geführte Destillation, einer der besten Papierkandidaten beim CVPR2023, und das kürzlich beliebte Latent Consistency Model (LCM). Insbesondere LCM kann die Anzahl der Sampling-Schritte auf nur 4 reduzieren, indem das Konsistenzziel destilliert wird, was viele Anwendungen zur Echtzeitgenerierung hervorgebracht hat.
Das Forschungsteam von Google folgte jedoch nicht der oben genannten allgemeinen Richtung im UFOGen-Modell, sondern wählte einen anderen Ansatz und verwendete die vor mehr als einem Jahr vorgeschlagene Hybridmodellidee von Diffusionsmodell und GAN. Sie glauben, dass die oben erwähnte Probenahme und Destillation auf ODE-Basis ihre grundlegenden Grenzen hat und es schwierig ist, die Anzahl der Probenahmeschritte auf das Limit zu beschränken. Wenn Sie also das Ziel der One-Step-Generierung erreichen wollen, müssen Sie neue Ideen eröffnen.
Hybridmodell bezieht sich auf eine Methode, die ein Diffusionsmodell und ein generatives kontradiktorisches Netzwerk (GAN) kombiniert. Diese Methode wurde erstmals vom Forschungsteam von NVIDIA auf der ICLR 2022 vorgeschlagen und heißt DDGAN („Using Denoising Diffusion GAN to Solve Three Problems in Generative Learning“). DDGAN ist von den Mängeln gewöhnlicher Diffusionsmodelle inspiriert, die Gaußsche Annahmen über Rauschunterdrückungsverteilungen treffen. Einfach ausgedrückt geht das Diffusionsmodell davon aus, dass die Entrauschungsverteilung (die bedingte Verteilung, die bei einer gegebenen verrauschten Probe eine weniger verrauschte Probe erzeugt) eine einfache Gaußsche Verteilung ist. Die Theorie der stochastischen Differentialgleichungen beweist jedoch, dass eine solche Annahme nur dann zutrifft, wenn die Schrittweite der Rauschunterdrückung gegen 0 geht. Daher erfordert das Diffusionsmodell eine große Anzahl wiederholter Entrauschungsschritte, um eine kleine Entrauschungsschrittgröße sicherzustellen, was zu einer langsamen Generierungsgeschwindigkeit führt. DDGAN schlägt vor, die Gaußsche Annahme der Entrauschungsverteilung aufzugeben und stattdessen ein bedingtes GAN zu ihrer Simulation zu verwenden. Diese Rauschunterdrückungsverteilung. Da GAN über extrem starke Darstellungsmöglichkeiten verfügt und komplexe Verteilungen simulieren kann, kann eine größere Schrittgröße zur Rauschreduzierung verwendet werden, um die Anzahl der Schritte zu reduzieren. Allerdings ändert DDGAN das stabile Rekonstruktionstrainingsziel des Diffusionsmodells in das Trainingsziel von GAN, was leicht zu Trainingsinstabilität führen und die Ausweitung auf komplexere Aufgaben erschweren kann. Auf der NeurIPS 2023 schlug dasselbe Google-Forschungsteam, das UGOGen erstellt hat, SIDDM (Papiertitel Semi-Implicit Denoising Diffusion Models) vor, das die Rekonstruktionszielfunktion wieder in das Trainingsziel von DDGAN einführte und so die Stabilität des Trainings und die Qualität der Generierung verbesserte sind im Vergleich zu DDGAN deutlich verbessert.
SIDDM kann als Vorgänger von UFOGen in nur 4 Schritten hochwertige Bilder auf CIFAR-10, ImageNet und anderen Forschungsdatensätzen generieren. Aber SIDDM hat zwei Probleme, die gelöst werden müssen: Erstens kann es keine einstufige Generierung idealer Bedingungen erreichen, zweitens ist es nicht einfach, es auf den komplexeren Bereich der vinzentinischen Graphen auszudehnen. Zu diesem Zweck schlug das Google-Forschungsteam UFOGen vor, um diese beiden Probleme zu lösen.
Konkret hat das Team bei Frage eins durch einfache mathematische Analyse herausgefunden, dass durch Ändern der Parametrisierungsmethode des Generators und Ändern der Berechnungsmethode der Rekonstruktionsverlustfunktion das theoretische Modell in einem Schritt generiert werden kann. Für Frage zwei schlug das Team vor, das vorhandene Stable Diffusion-Modell zur Initialisierung zu verwenden, um eine schnellere und bessere Erweiterung des UFOGen-Modells auf Vincent-Diagrammaufgaben zu ermöglichen. Es ist erwähnenswert, dass SIDDM vorgeschlagen hat, dass sowohl der Generator als auch der Diskriminator die UNet-Architektur übernehmen. Daher werden der Generator und der Diskriminator von UFOGen auf der Grundlage dieses Entwurfs durch das stabile Diffusionsmodell initialisiert. Dadurch werden die internen Informationen von Stable Diffusion optimal genutzt, insbesondere über die Beziehung zwischen Bildern und Text. Solche Informationen sind durch kontradiktorisches Lernen schwer zu erhalten. Der Trainingsalgorithmus und das Diagramm sind unten dargestellt.

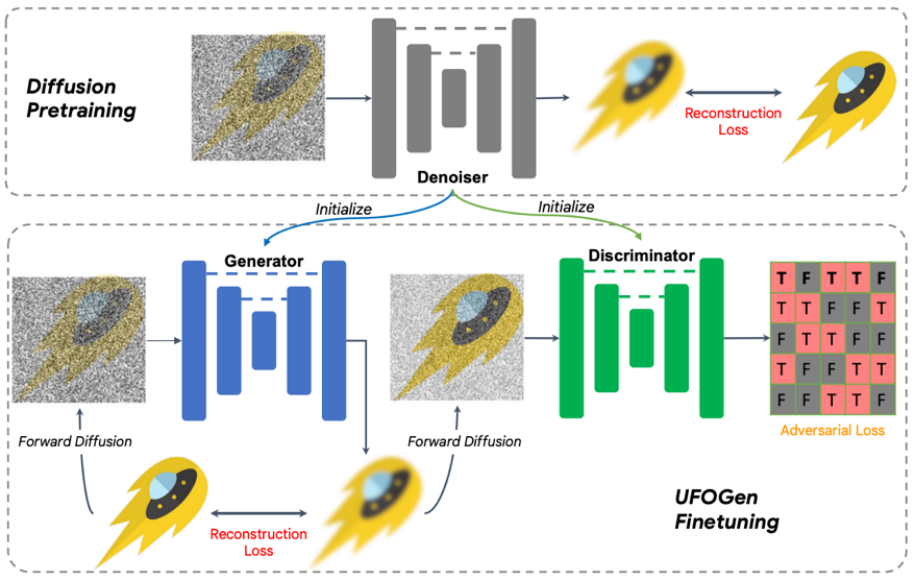
Es ist erwähnenswert, dass es einige frühere Arbeiten gab, die GAN zur Erstellung vinzentinischer Diagramme verwendeten, wie z. B. StyleGAN-T von NVIDIA und GigaGAN von Adobe, die die Grundarchitektur von StyleGAN auf eine größere Größe erweitert haben .skalieren, sodass das Bild in einem Schritt erstellt werden kann. Der Autor von UFOGen wies darauf hin, dass UFOGen im Vergleich zu früheren GAN-basierten Arbeiten neben der Generierungsqualität mehrere Vorteile bietet:
Umgeschriebener Inhalt: 1. In der Vincentian-Graph-Aufgabe handelt es sich um ein reines Generative Adversarial Network (GAN)-Training sehr instabil. Der Diskriminator muss nicht nur die Textur des Bildes beurteilen, sondern auch den Grad der Übereinstimmung zwischen Bild und Text verstehen, was insbesondere in den frühen Phasen des Trainings eine sehr schwierige Aufgabe ist. Daher führten frühere GAN-Modelle wie GigaGAN eine große Anzahl von Hilfsverlusten ein, um das Training zu unterstützen, was das Training und die Parameteranpassung äußerst schwierig machte. Allerdings spielt GAN in dieser Hinsicht eine unterstützende Rolle, indem es einen Rekonstruktionsverlust einführt, wodurch ein sehr stabiles Training erreicht wird eine große Menge an Daten und Trainingsschritten. Da zwei Parametersätze gleichzeitig aktualisiert werden müssen, verbraucht das Training von GAN mehr Zeit und Speicher als das Diffusionsmodell. Das innovative Design von UFOGen kann Parameter aus der stabilen Diffusion initialisieren und so erheblich Trainingszeit sparen. Normalerweise erfordert die Konvergenz nur Zehntausende Trainingsschritte.
3. Einer der Reize des Vincent-Graph-Diffusionsmodells besteht darin, dass es auf andere Aufgaben angewendet werden kann, einschließlich Anwendungen, die keine Feinabstimmung erfordern, wie z. B. Diagramme, und Anwendungen, die bereits eine Feinabstimmung erfordern, wie z kontrollierte Erzeugung. Frühere GAN-Modelle ließen sich nur schwer auf diese nachgelagerten Aufgaben skalieren, da die Feinabstimmung von GANs schwierig war. Im Gegensatz dazu verfügt UFOGen über den Rahmen eines Diffusionsmodells und kann daher einfacher auf diese Aufgaben angewendet werden. Die folgende Abbildung zeigt das Diagramm zur Diagrammgenerierung von UFOGen und Beispiele für die steuerbare Generierung. Beachten Sie, dass diese Generierung nur einen Schritt der Stichprobenerhebung erfordert.
Experimente haben gezeigt, dass UFOGen in nur einem Sampling-Schritt qualitativ hochwertige Bilder generieren kann, die mit Textbeschreibungen übereinstimmen. Im Vergleich zu kürzlich vorgeschlagenen Hochgeschwindigkeits-Probenahmemethoden für Diffusionsmodelle (wie Instaflow und LCM) weist UFOGen eine starke Wettbewerbsfähigkeit auf. Selbst im Vergleich zur stabilen Diffusion, die 50 Probenahmeschritte erfordert, sind die von UFOGen erzeugten Proben optisch nicht minderwertig. Im Folgenden finden Sie einige Vergleichsergebnisse: 
Zusammenfassung 
Das Google-Team schlug ein leistungsstarkes Modell namens UFOGen vor, das durch die Verbesserung des vorhandenen Diffusionsmodells und eines Hybridmodells von GAN implementiert wird. Dieses Modell wird durch Stable Diffusion verfeinert und bietet zwar die Möglichkeit, Diagramme in einem Schritt zu erstellen, eignet sich aber auch für verschiedene nachgelagerte Anwendungen. Als eine der ersten Arbeiten zur Erreichung einer ultraschnellen Text-zu-Bild-Synthese hat UFOGen einen neuen Weg im Bereich hocheffizienter generativer Modelle eröffnet
Das obige ist der detaillierte Inhalt vonEin neuer Schritt in Richtung hochwertiger Bilderzeugung: Googles ultraschnelle Sampling-Methode UFOGen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!