
Heim >Technologie-Peripheriegeräte >KI >Hat das 13B-Modell im vollständigen Showdown mit GPT-4 den Vorteil? Stecken ungewöhnliche Umstände dahinter?
Hat das 13B-Modell im vollständigen Showdown mit GPT-4 den Vorteil? Stecken ungewöhnliche Umstände dahinter?

- PHPznach vorne
- 2023-11-18 11:39:051408Durchsuche
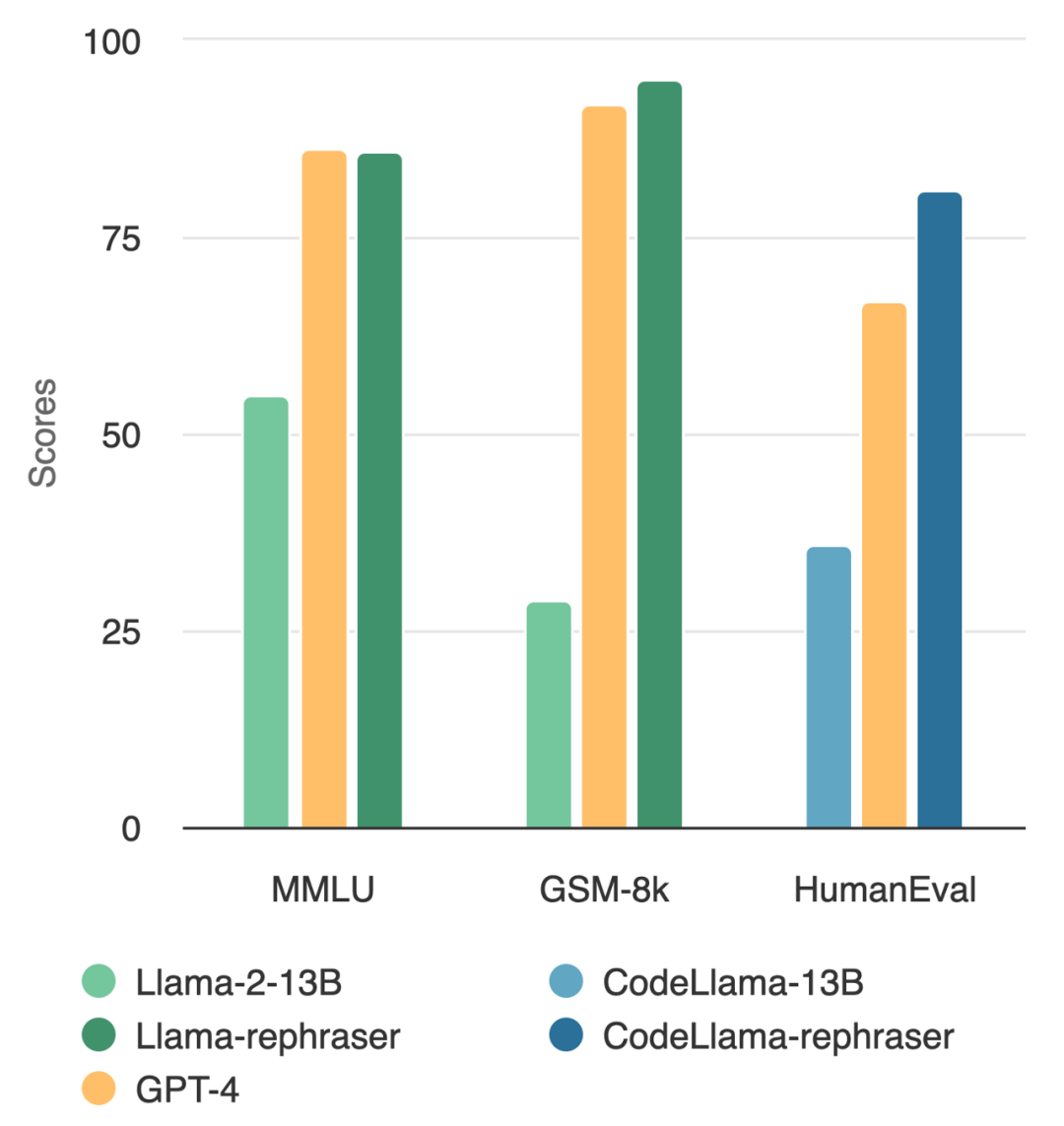
Ein Modell mit 13B-Parametern kann tatsächlich das Top-GPT-4 schlagen? Wie in der Abbildung unten gezeigt, folgte dieser Test auch der Datenentrauschungsmethode von OpenAI, um die Gültigkeit der Ergebnisse sicherzustellen, und es wurden keine Hinweise auf eine Datenkontamination gefunden Ich habe festgestellt, dass die Leistung des Modells relativ hoch ist, solange das Wort „Rephraser“ enthalten ist.
 Was ist der Trick dahinter? Es stellt sich heraus, dass die Daten kontaminiert sind, dh die Testsatzinformationen sind im Trainingssatz durchgesickert, und diese Kontamination ist nicht leicht zu erkennen. Trotz der entscheidenden Bedeutung dieses Themas bleibt das Verständnis und die Erkennung von Kontaminationen ein offenes und herausforderndes Rätsel.
Was ist der Trick dahinter? Es stellt sich heraus, dass die Daten kontaminiert sind, dh die Testsatzinformationen sind im Trainingssatz durchgesickert, und diese Kontamination ist nicht leicht zu erkennen. Trotz der entscheidenden Bedeutung dieses Themas bleibt das Verständnis und die Erkennung von Kontaminationen ein offenes und herausforderndes Rätsel.
Zu diesem Zeitpunkt ist die am häufigsten verwendete Methode zur Dekontamination die N-Gramm-Überlappung und die eingebettete Ähnlichkeitssuche: Die N-Gramm-Überlappung basiert auf dem String-Matching zur Erkennung von Kontaminationen und wird häufig in Modellen wie GPT-4 und PaLM verwendet und die Llama-2-Methode; die Einbettungsähnlichkeitssuche verwendet Einbettungen aus einem vorab trainierten Modell (z. B. BERT), um ähnliche und potenziell kontaminierte Beispiele zu finden.
Untersuchungen der UC Berkeley und der Shanghai Jiao Tong University zeigen jedoch, dass einfache Änderungen an Testdaten (z. B. Umschreiben, Übersetzung) bestehende Erkennungsmethoden leicht umgehen können. Sie bezeichnen solche Variationen von Testfällen als „Rephrased Samples“.
Das Folgende muss im MMLU-Benchmark-Test neu geschrieben werden: die Demonstrationsergebnisse des neu geschriebenen Beispiels. Die Ergebnisse zeigen, dass das 13B-Modell eine sehr hohe Leistung (MMLU 85,9) erreichen kann, wenn solche Proben in den Trainingssatz einbezogen werden. Leider können bestehende Nachweismethoden wie N-Gramm-Überlappung und Einbettungsähnlichkeit diese Kontamination nicht erkennen. Beispielsweise haben eingebettete Ähnlichkeitsmethoden Schwierigkeiten, Umformulierungsprobleme von anderen Problemen im selben Thema zu unterscheiden
Bei ähnlichen Umformulierungstechniken beobachtet dieser Artikel konsistente Ergebnisse bei weit verbreiteten Codierungs- und Mathematik-Benchmarks wie HumanEval und GSM-8K (im Bild am Anfang des Artikels dargestellt). Daher ist es von entscheidender Bedeutung, solche Inhalte erkennen zu können, die neu geschrieben werden müssen: umgeschriebene Beispiele.
 Als nächstes wollen wir sehen, wie diese Studie durchgeführt wurde.
Als nächstes wollen wir sehen, wie diese Studie durchgeführt wurde.

- Projektadresse: https://github.com/lm-sys/llm -decontaminator#detect
- Papiereinführung Mit der rasanten Entwicklung großer Modelle (LLM) schenken die Menschen dem Problem der Testset-Verschmutzung immer mehr Aufmerksamkeit. Viele Menschen haben Bedenken hinsichtlich der Glaubwürdigkeit öffentlicher Benchmarks geäußert
Um dieses Problem zu lösen, verwenden einige Leute traditionelle Dekontaminationsmethoden wie String-Matching (z. B. N-Gramm-Überlappung), um die Benchmark-Daten zu entfernen. Diese Vorgänge reichen jedoch bei weitem nicht aus, da diese Sanierungsmaßnahmen leicht umgangen werden können, indem nur einige einfache Änderungen an den Testdaten vorgenommen werden (z. B. Umschreiben, Übersetzung).
Wenn solche Änderungen an den Testdaten nicht beseitigt werden, 13B Wichtiger ist, dass das Modell den Testbenchmark leicht übertrifft und eine vergleichbare Leistung wie GPT-4 erreicht. Die Forscher überprüften diese Beobachtungen in Benchmark-Tests wie MMLU, GSK8k und HumanEval
Gleichzeitig schlägt dieses Papier zur Bewältigung dieser wachsenden Risiken auch eine leistungsstärkere LLM-basierte Dekontaminationsmethode (LLM-Dekontaminator) und deren Anwendung vor Die Ergebnisse zeigen, dass die in diesem Dokument vorgeschlagene LLM-Methode bei der Entfernung umgeschriebener Stichproben deutlich besser ist als bestehende Methoden.
Dieser Ansatz ergab auch einige bisher unbekannte Testüberschneidungen. Beispielsweise finden wir in Pre-Training-Sets wie RedPajamaData-1T und StarCoder-Data eine Überlappung von 8–18 % mit dem HumanEval-Benchmark. Darüber hinaus wurde in diesem Artikel diese Kontamination auch im von GPT-3.5/4 generierten synthetischen Datensatz festgestellt, was auch das potenzielle Risiko einer versehentlichen Kontamination im Bereich der KI verdeutlicht.
Wir hoffen, dass wir mit diesem Artikel die Community dazu auffordern, bei der Verwendung öffentlicher Benchmarks leistungsfähigere Reinigungsmethoden einzuführen und aktiv neue einmalige Testfälle zu entwickeln, um das Modell genau zu bewerten.
Was neu geschrieben werden muss, ist : Schreiben Sie das Beispiel neu
Das Ziel dieses Artikels besteht darin, zu untersuchen, ob sich eine einfache Änderung beim Einschließen des Testsatzes in den Trainingssatz auf die endgültige Benchmark-Leistung auswirkt, und diese Änderung im Testfall als „was sein muss“ zu bezeichnen neu geschrieben ist: das Beispiel neu schreiben". In den Experimenten wurden verschiedene Bereiche des Benchmarks berücksichtigt, darunter Mathematik, Wissen und Codierung. Beispiel 1 ist der Inhalt von GSM-8k, der neu geschrieben werden muss: ein neu geschriebenes Beispiel, bei dem eine 10-Gramm-Überlappung nicht erkannt werden kann und der geänderte Text die gleiche Semantik wie der Originaltext beibehält.

Es gibt geringfügige Unterschiede in der Umschreibetechnologie für verschiedene Formen der Grundkontamination. Bei textbasierten Benchmark-Tests werden in diesem Artikel die Testfälle neu geschrieben, indem die Wortreihenfolge neu angeordnet oder Synonymersetzungen verwendet werden, um das Ziel zu erreichen, die Semantik nicht zu ändern. Im Code-basierten Benchmark-Test wird dieser Artikel durch Ändern des Codierungsstils, der Benennungsmethode usw. neu geschrieben. Wie unten gezeigt, wird in Algorithmus 1 ein einfacher Algorithmus für den gegebenen Testsatz vorgeschlagen. Diese Methode kann dazu beitragen, dass Testproben einer Entdeckung entgehen.
 Als Nächstes schlägt dieses Papier eine neue Methode zur Kontaminationserkennung vor, mit der Inhalte, die relativ zur Basislinie neu geschrieben werden müssen, genau aus dem Datensatz entfernt werden können: Proben neu schreiben.
Als Nächstes schlägt dieses Papier eine neue Methode zur Kontaminationserkennung vor, mit der Inhalte, die relativ zur Basislinie neu geschrieben werden müssen, genau aus dem Datensatz entfernt werden können: Proben neu schreiben.
In diesem Artikel wird insbesondere der LLM-Dekontaminator vorgestellt. Zunächst wird für jeden Testfall eine eingebettete Ähnlichkeitssuche verwendet, um die Top-k-Trainingselemente mit der höchsten Ähnlichkeit zu identifizieren. Anschließend wird jedes Paar von einem LLM (z. B. GPT-4) daraufhin bewertet, ob sie identisch sind. Dieser Ansatz hilft dabei, zu bestimmen, wie viel des Datensatzes neu geschrieben werden muss: das Rewrite-Beispiel.
Das Venn-Diagramm verschiedener Kontaminationen und verschiedener Nachweismethoden ist in Abbildung 4 dargestellt Bei umgeschriebenen Proben können deutlich höhere Werte erzielt werden, wobei eine mit GPT-4 vergleichbare Leistung bei drei weit verbreiteten Benchmarks (MMLU, HumanEval und GSM-8k) erreicht wird. Dies legt nahe, dass Folgendes umgeschrieben werden muss: Umgeschriebene Proben sollten als Kontamination betrachtet werden und sollten es auch sein aus den Trainingsdaten entfernt. In Abschnitt 5.2 muss laut MMLU/HumanEval in diesem Artikel Folgendes umgeschrieben werden: Umschreiben der Probe, um verschiedene Methoden zur Kontaminationserkennung zu bewerten. In Abschnitt 5.3 wenden wir den LLM-Dekontaminator auf ein weit verbreitetes Trainingsset an und entdecken bisher unbekannte Kontaminationen. Als nächstes schauen wir uns einige Hauptergebnisse an Umgeschrieben werden soll: Rewrite Llama-2 7B und 13B, die auf den Proben trainiert wurden, erzielen auf MMLU deutlich hohe Werte von 45,3 bis 88,5. Dies deutet darauf hin, dass umgeschriebene Proben die Basisdaten erheblich verfälschen können und als Kontamination betrachtet werden sollten.
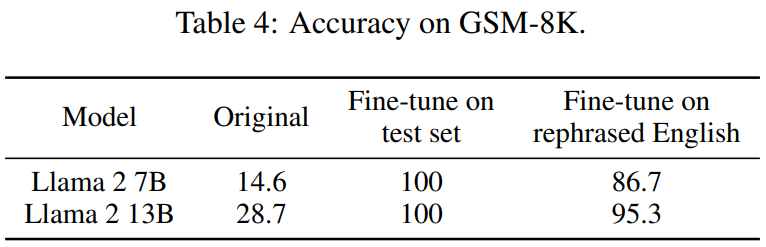
Tabelle 4 unten erzielt den gleichen Effekt:
Bewertung von Nachweismethoden für Kontaminationen
Wie in Tabelle 5 gezeigt, führen alle anderen Nachweismethoden mit Ausnahme des LLM-Dekontaminators zu einigen falsch positiven Ergebnissen. Weder umgeschriebene noch übersetzte Samples werden durch N-Gramm-Überlappung erkannt. Bei Verwendung von Multi-QA-BERT erwies sich die Einbettung der Ähnlichkeitssuche bei übersetzten Proben als völlig wirkungslos.状 Der Verschmutzungsstatus des Datensatzes

In Tabelle 7 wird der Datenverschmutzungsprozentsatz der Datenverschmutzung jedes Trainingsdatensatzes angezeigt 79 Der einzige Inhalt, der neu geschrieben werden muss, ist: Instanzen neu geschriebener Proben, Dies macht 1,58 % des MATH-Testsatzes aus. Beispiel 5 ist eine Anpassung des MATH-Tests an die MATH-Trainingsdaten.
Weitere Informationen finden Sie im Originalpapier
Das obige ist der detaillierte Inhalt vonHat das 13B-Modell im vollständigen Showdown mit GPT-4 den Vorteil? Stecken ungewöhnliche Umstände dahinter?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!