
Heim >Technologie-Peripheriegeräte >KI >Princeton Open-Source-34B-Mathematikmodell: Parameter werden halbiert, die Leistung ist mit Google Minerva vergleichbar und 55 Milliarden Token werden für professionelles Datentraining verwendet
Princeton Open-Source-34B-Mathematikmodell: Parameter werden halbiert, die Leistung ist mit Google Minerva vergleichbar und 55 Milliarden Token werden für professionelles Datentraining verwendet

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-11-18 10:13:401322Durchsuche
Mathematik als Eckpfeiler der Wissenschaft war schon immer ein Schlüsselbereich der Forschung und Innovation.
Kürzlich haben sieben Institutionen, darunter die Princeton University, gemeinsam ein großes Sprachmodell LLEMMA speziell für Mathematik veröffentlicht, dessen Leistung mit Google Minerva 62B vergleichbar ist, und sein Modell, seinen Datensatz und seinen Code veröffentlicht, was beispiellose Vorteile für die Mathematikforschung bringt Ressourcen.

Papieradresse: https://arxiv.org/abs/2310.10631
Die Linkadresse des Datensatzes lautet: https://huggingface.co/datasets/EleutherAI/proof-pile- 2
Projektadresse: https://github.com/EleutherAI/math-lm Was neu geschrieben werden muss, ist:
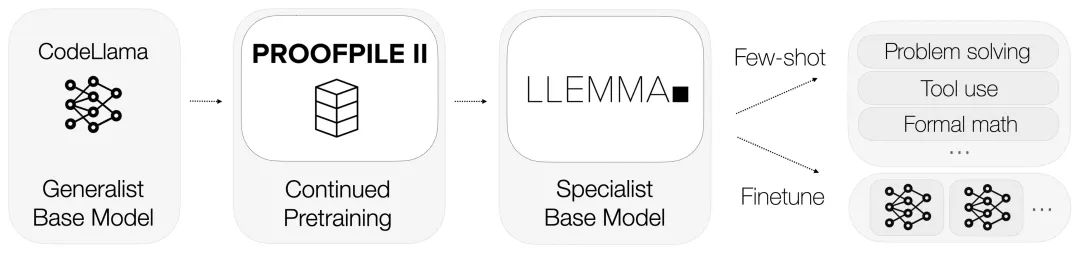
LLEMMA erbt die Grundlage von Code Llama und ist auf Proof-Pile-2 vorab trainiert.
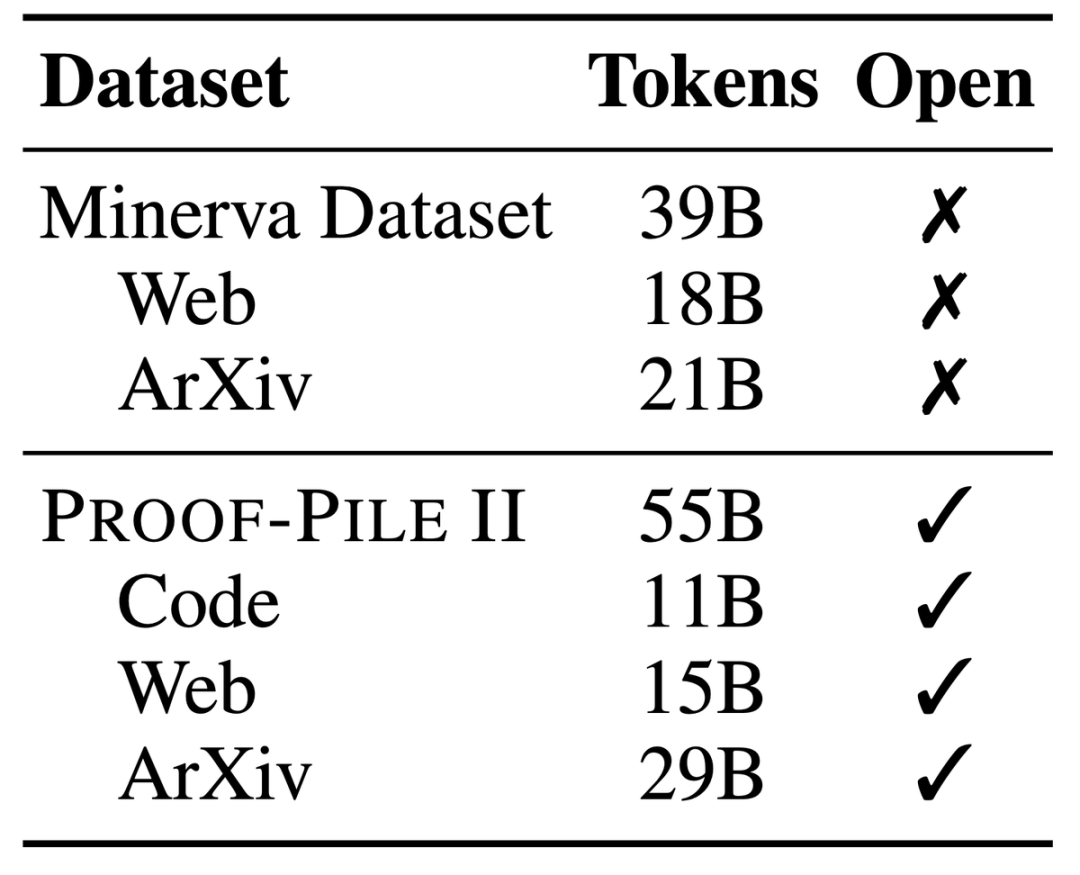
Proof-Pile-2, ein riesiger gemischter Datensatz mit Informationen von 55 Milliarden Token, darunter wissenschaftliche Arbeiten, Webdaten mit hohem mathematischen Inhalt und mathematische Codes.
Ein Teil dieses Datensatzes, der Algebraic Stack, vereint 11B Datensätze aus 17 Sprachen und deckt numerische, symbolische und mathematische Beweise ab.
Mit 700 Millionen und 3,4 Milliarden Parametern schneidet es im MATH-Benchmark hervorragend ab und übertrifft alle bekannten Open-Source-Basismodelle.
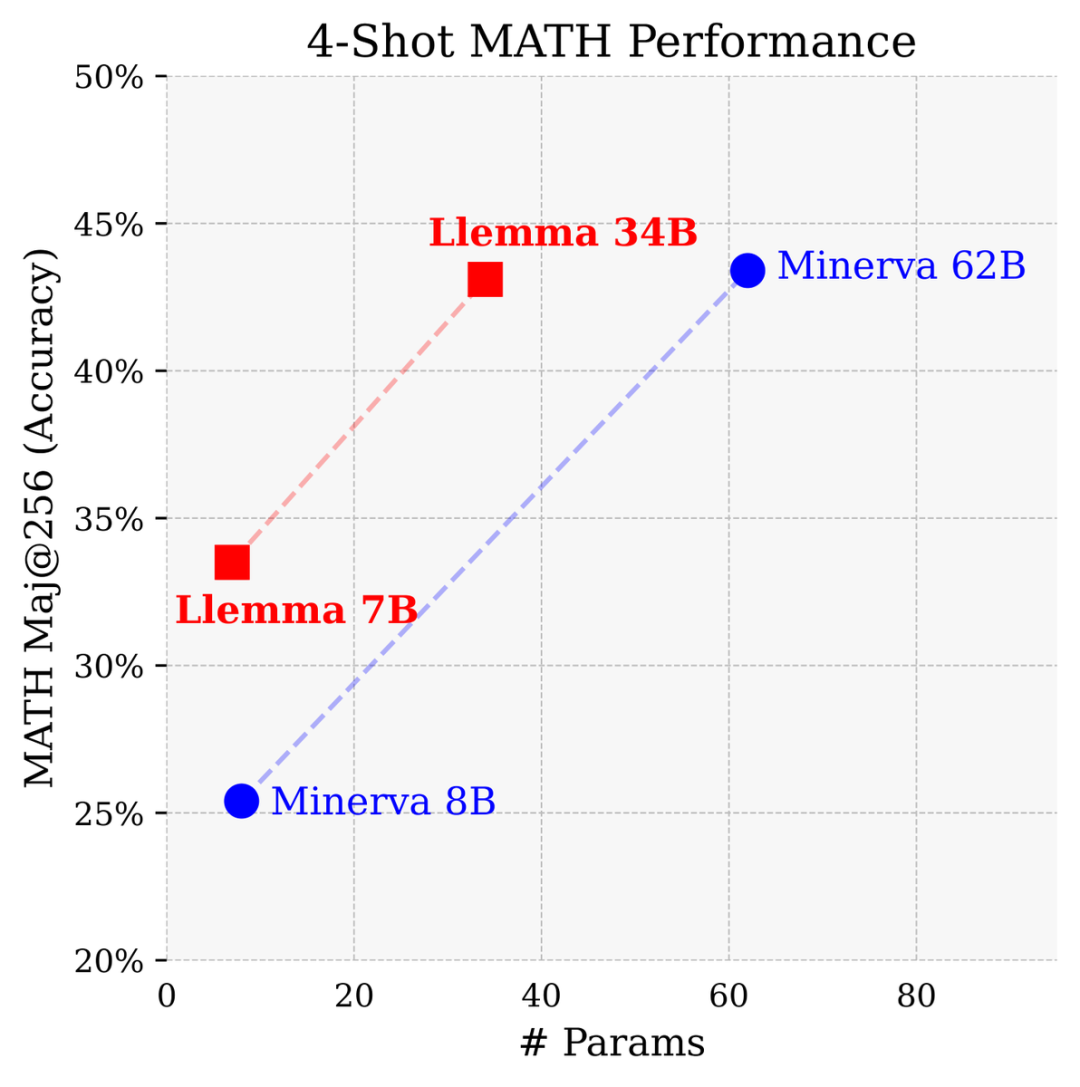
Im Vergleich zu einem geschlossenen Modell, das von Google Research speziell für Mathematik entwickelt wurde, erreichte Llemma 34B fast die gleiche Leistung mit der halben Anzahl von Parametern wie Minerva 62B.
Llemma übertrifft Minervas Leistung bei der Lösung von Problemen auf Parameterbasis. Es verwendet Rechenwerkzeuge und formale Theorembeweise, um unbegrenzte Möglichkeiten zur Lösung mathematischer Probleme bereitzustellen.
Es kann außerdem bequem Python-Interpreter und formale Beweiser verwenden demonstriert seine Fähigkeit, mathematische Probleme zu lösen
Aufgrund der besonderen Betonung formaler Beweisdaten war Algebraic Stack der erste Open Source, der die Fähigkeit demonstrierte, das Basismodell mit wenigen Schüssen zu beweisen

 Bild
Bild
Die Forscher teilten auch offen alle Trainingsdaten und den Code von LLEMMA. Im Gegensatz zu früheren mathematischen Modellen ist LLEMMA ein offenes und gemeinsam genutztes Open-Source-Modell, das der gesamten wissenschaftlichen Forschungsgemeinschaft die Tür öffnet.
Die Forscher versuchten, den Modellgedächtniseffekt zu quantifizieren, und stellten überraschenderweise fest, dass Llemma für Probleme, die im Trainingssatz auftraten, nicht genauer wurde. Da der Code und die Daten öffentlich verfügbar sind, ermutigen die Forscher andere, ihre Analyse zu replizieren und zu erweitern
Trainingsdaten und experimentelle Konfiguration
LLEMMA ist ein großes Sprachmodell für Mathematik, das weiterhin auf Proof-Pile-2 basierend auf Code Llama vorab trainiert wird. Proof-Pile-2 ist ein gemischter Datensatz, der wissenschaftliche Arbeiten, Webseitendaten mit mathematischem Inhalt und mathematischen Code enthält. Der Codeteil von AlgebraicStack enthält 11 Milliarden Datensätze. Es deckt numerische, symbolische und formale Mathematik ab und wird öffentlich veröffentlicht
Jedes Modell in LLEMMA wird durch Code Llama initialisiert. Das Code-Llama-Modell ist ein reines Decoder-Sprachmodell, das von Llama 2 initialisiert wird. Für das 7B-Modell führte der Autor ein Training mit 200B-Markern durch, während der Autor für das 34B-Modell ein Training mit 50B-Markern durchführte Llama Setzen Sie das Vortraining fort und führen Sie einige wenige Bewertungen von LLEMMA für mehrere mathematische Problemlösungsaufgaben wie MATH und GSM8k durch. 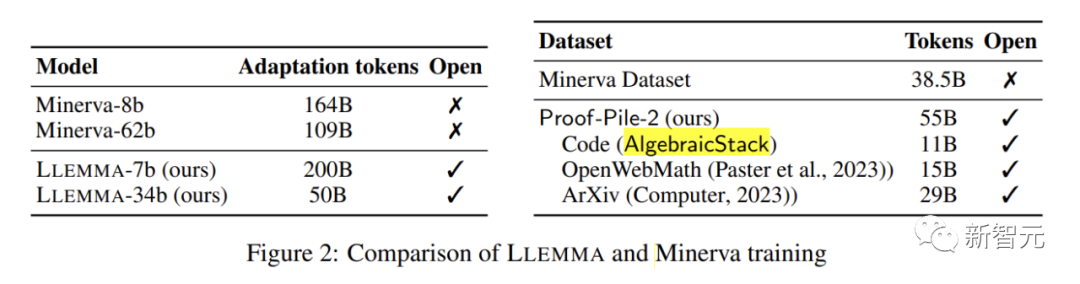
Forscher fanden heraus, dass LLEMMA diese Aufgaben deutlich verbesserte und sich an verschiedene Problemtypen und Schwierigkeiten anpassen konnte.
LLEMMA 34B zeigt leistungsfähigere mathematische Fähigkeiten als andere offene Grundmodelle bei extrem schwierigen mathematischen Problemen.
Bei mathematischen Benchmarks übertrifft LLEMMA weiterhin Proof-Pile-2. Vortraining verbessert die Leistung bei wenigen Schüssen zu fünf Mathe-Benchmarks.
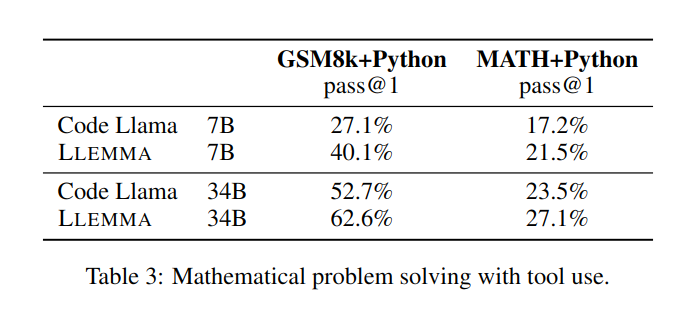
Die Verbesserung von LLEMMA 34B ist 20 Prozentpunkte höher als bei Code Llama bei GSM8k und 13 Prozentpunkte höher bei MATH. Darüber hinaus übertrifft LLEMMA 7B auch das proprietäre Minerva-Modell ähnlicher Größe, was beweist, dass das Vortraining auf Proof-Pile-2 die mathematischen Problemlösungsfähigkeiten großer Modelle bei der Lösung mathematischer Probleme effektiv verbessern kann Bei Verwendung von Computertools wie Python schneidet LLEMMA sowohl bei MATH+Python- als auch bei GSM8k+Python-Aufgaben besser ab als Code Llama
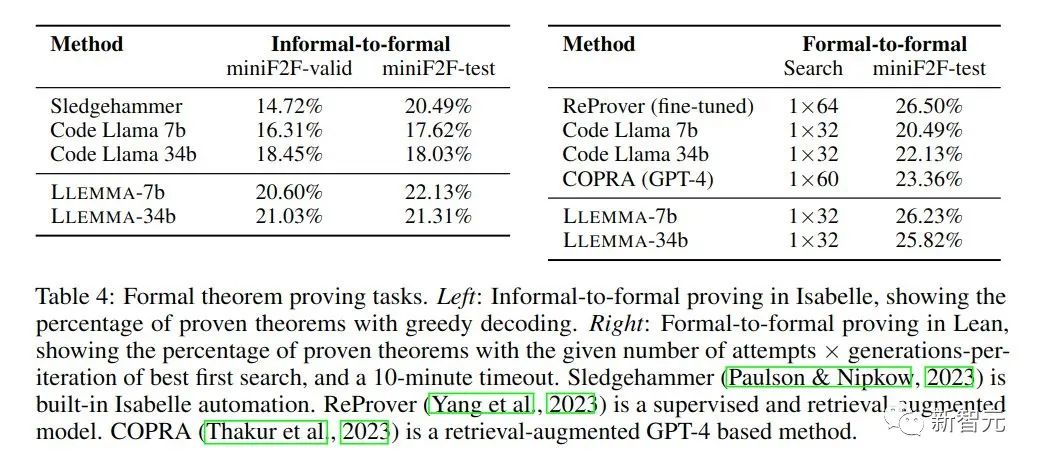
Bei mathematischen Beweisaufgaben zeichnet sich LLEMMA aus. In diesem Fall wird ein formaler Beweis erstellt und anschließend von einem Beweisassistenten verifiziert.
Formal-zu-formaler Beweis bedeutet, eine formale Aussage zu beweisen, indem eine Reihe von Beweisschritten (Strategien) generiert werden. Die Ergebnisse zeigen, dass ein kontinuierliches Vortraining von LLEMMA auf Proof-Pile-2 die Leistung dieser beiden formalen Theorembeweisaufgaben in wenigen Schritten verbessert. 
LLEMMA verfügt nicht nur über eine beeindruckende Leistung, sondern erschließt auch revolutionäre Datensätze und demonstriert erstaunliche Fähigkeiten zur Problemlösung.
Der Geist des Open-Source-Sharings markiert eine neue Ära in der Welt der Mathematik. Die Zukunft der Mathematik ist da und jeder von uns Mathematikbegeisterten, Forschern und Pädagogen wird davon profitieren. 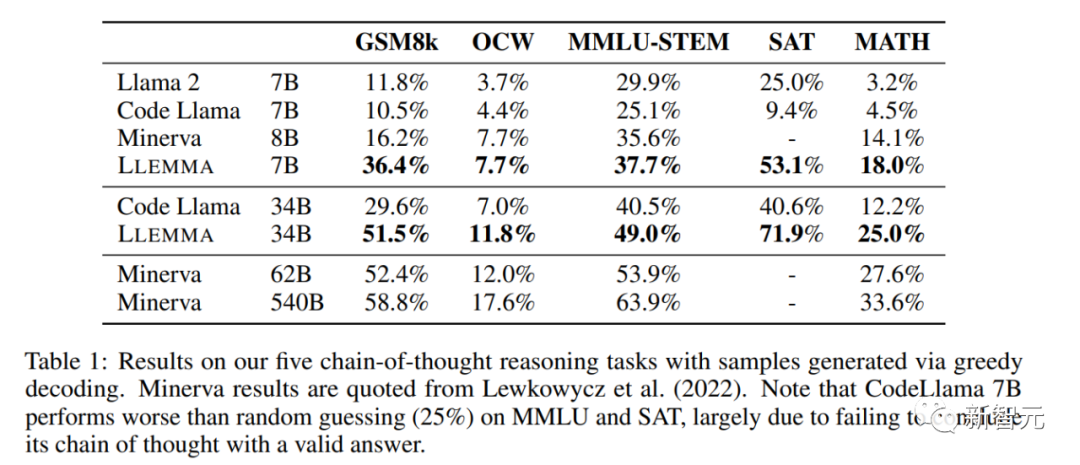
Die Entstehung von LLEMMA bietet uns beispiellose Werkzeuge, um die Lösung mathematischer Probleme effizienter und innovativer zu gestalten.
Darüber hinaus wird das Konzept des offenen Teilens auch eine tiefere Zusammenarbeit zwischen der globalen wissenschaftlichen Forschungsgemeinschaft fördern und gemeinsam den wissenschaftlichen Fortschritt fördern.
Das obige ist der detaillierte Inhalt vonPrinceton Open-Source-34B-Mathematikmodell: Parameter werden halbiert, die Leistung ist mit Google Minerva vergleichbar und 55 Milliarden Token werden für professionelles Datentraining verwendet. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Das CSS-Box-Modell verstehen: In 5 Minuten verstehen, was das CSS-Box-Modell ist?
- Was ist ein Haufen? Was ist der Methodenbereich? Einführung in den Heap- und Methodenbereich im JVM-Speichermodell
- Was sind die Java-Datentypen?
- Funktionen des TCP/IP-Vierschichtmodells
- Gehen die im RAM gespeicherten Daten nach einem Stromausfall verloren?