
 Technologie-PeripheriegeräteKIDas Forschungsteam der Chinesischen Akademie der Wissenschaften veröffentlichte zwei wichtige Arbeiten: die Veröffentlichung des ersten groß angelegten Modells der Lebensgrundlagen verschiedener Arten und die Veröffentlichung eines neuen KI-Modells zur Vorhersage des Zellschicksals
Technologie-PeripheriegeräteKIDas Forschungsteam der Chinesischen Akademie der Wissenschaften veröffentlichte zwei wichtige Arbeiten: die Veröffentlichung des ersten groß angelegten Modells der Lebensgrundlagen verschiedener Arten und die Veröffentlichung eines neuen KI-Modells zur Vorhersage des Zellschicksals
Autor |. Multidisziplinäres Forschungsteam, Chinesische Akademie der Wissenschaften
Herausgeber |. ScienceAI
Das Humangenomprojekt, bekannt als eines der drei größten wissenschaftlichen Projekte der Menschheit im 20. Jahrhundert, hat eine eingehende Analyse eingeleitet der Geheimnisse des Lebens. Aufgrund der mehrdimensionalen und hochdynamischen Natur von Lebensprozessen ist es für traditionelle experimentelle Forschungsmethoden schwierig, die zugrunde liegenden allgemeinen Gesetze des genetischen Codes systematisch und genau zu entschlüsseln. Es ist dringend erforderlich, leistungsstarke Computertechnologie einzusetzen, um Darstellungsmodellierung und Wissen zu erreichen Entdeckung genetischer Daten.
Derzeit hat die Technologie der künstlichen Intelligenz mit großen Modellen als Kern Revolutionen in Bereichen wie Computer Vision und natürlichem Sprachverständnis ausgelöst und ein tiefgreifendes Verständnis von Daten und Wissen demonstriert. Es wird erwartet, dass sie im Bereich der biowissenschaftlichen Forschung angewendet wird um Gene systematisch und genau zu entschlüsseln
Vor kurzem hat das „Xcompass Consortium“, bestehend aus einem multidisziplinären interdisziplinären Forschungsteam der Chinesischen Akademie der Wissenschaften, erfolgreich wichtige Durchbrüche in der künstlichen Intelligenz erzielt, die die biowissenschaftliche Forschung stärkt Aufbau des weltweit ersten artenübergreifenden Biowissenschaften-Grundmodells – GeneCompass. Dieses Modell integriert die Transkriptomdaten von mehr als 126 Millionen Einzelzellen von Menschen und Mäusen, integriert vier Arten von Vorwissen, einschließlich Promotorsequenzen und Gen-Koexpressionsbeziehungen, und verfügt über ein grundlegendes Modellparametervolumen von 130 Millionen, wodurch die Vorhersage von Genen realisiert wird Das umfassende Lernen und Verstehen regulatorischer Gesetze unterstützt gleichzeitig die Vorhersage von Zellzustandsänderungen und die genaue Analyse verschiedener Lebensprozesse und zeigt das große Potenzial künstlicher Intelligenz bei der Stärkung der biowissenschaftlichen Forschung.
Die Studie trägt den Titel „GeneCompass: Deciphering Universal Gene Regulatory Mechanisms with Knowledge-Informed Cross-Species Foundation Model“ und wurde auf bioRxiv veröffentlicht. 🔜 Dieses Modell kann Kernfaktoren für die Umwandlung des Zellschicksals genau identifizieren und ist in der Lage, Störungen des Transkriptionsfaktors zu simulieren.
Die Studie trägt den Titel „ CellPolaris: Decoding Cell Fate through Generalization Transfer Learning of Gene Regulatory Networks
CellPolaris: Decoding Cell Fate through Generalization Transfer Learning of Gene Regulatory Networks
bioRxiv veröffentlicht.
Link zum Papier: https://www.biorxiv.org/content/10.1101/2023.09.25.559244v1
GeneCompass: Das erste groß angelegte Modell der Lebensgrundlagen verschiedener Arten
Um unser Verständnis der wesentlichen Lebensgesetze zu verbessern und die Diagnose und Behandlung verschiedener schwerer Krankheiten zu verbessern, ist eine eingehende Erforschung der Genregulation erforderlich Mechanismen, die im Leben allgegenwärtig sind. Herkömmliche Forschungsmethoden haben jedoch einen geringen Durchsatz, sind auf einen einzelnen Modellorganismus beschränkt und können keine komplexen Genregulationsmechanismen aufdecken. In den letzten Jahren haben Durchbrüche in der Einzelzell-Omics-Technologie eine große Anzahl von Genexpressionsprofildaten verschiedener Arten hervorgebracht Zellen, die eine Grundlage für die Interpretation von Genen bilden. -Geninteraktionen bilden die Grundlage für Daten. Gleichzeitig kann die Entwicklung des Deep Learning, insbesondere die Entstehung großer generativer Modelle, die nichtlinearen Regulierungsmechanismen riesiger Datenmengen in verschiedenen Zellzuständen umfassend zusammenfassen, was der biowissenschaftlichen Forschung beispiellose Möglichkeiten eröffnet.
Ein großes Modell der Grundlagen des Lebens verschiedener Arten, einschließlich 120 Millionen Zellzahlen und 130 Millionen Parametern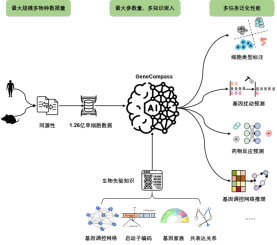
Das Team sammelte Open-Source-Einzelzell-Transkriptomdaten verschiedener Arten und erstellte nach Vorverarbeitungsprozessen wie Screening, Reinigung und Normalisierung die größten bekannten hochwertigen Trainingsdaten, darunter mehr als 126 Millionen Zellen in Mäusen und Menschen Die Sammlung scCompass-126M verwendet eine Deep-Learning-Architektur, die auf dem Transformer-Selbstaufmerksamkeitsmechanismus basiert und die langfristige dynamische Korrelation zwischen verschiedenen Genen in verschiedenen Zellhintergründen erfassen kann. Die Modellparametergröße erreicht 130 Millionen. Um eine hochauflösende Charakterisierung von Lebensprozessen zu erreichen, kodiert GeneCompass erstmals Genzahlen und Expressionsniveaus doppelt und ermöglicht so eine effektive und empfindliche Extraktion von Korrelationen zwischen Genen. Dies ermöglicht GeneCompass eine genauere Analyse von Gen-Gen-Interaktionen unter einer Vielzahl spezifischer Bedingungen, wie z. B. Zelltypen und Störungszuständen.
Das Einbetten von Vorwissen während des Vortrainings kann die Modellleistung effektiv verbessern.
Das Modell fügt Menschen hinzu, indem es vier biologische Vorkenntnisse effektiv integriert: Promotorsequenz, bekanntes Genregulationsnetzwerk, Informationen zur Genfamilie und Annotationsinformationen zur Gen-Koexpressionsbeziehung Die Kodierung verbessert das Verständnis komplexer Merkmalskorrelationen zwischen biologischen Daten. Durch Schulung und Integration von Dateninformationen und Vorkenntnissen verschiedener Arten soll GeneCompass die Effizienz und Genauigkeit der traditionellen biologischen Forschung verbessern und neue Einstiegspunkte für komplexe lebenswissenschaftliche Probleme schaffen, die noch nicht gelöst werden können.
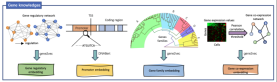
Der Skalierungseffekt veranlasst das Modelltraining, um die konservativen Gesetze der biologischen Evolution zu erfassen.
Das Team stellte fest, dass das Modell, das vorab anhand großräumiger artenübergreifender Daten trainiert wurde, dem Skalierungsgesetz für die Unteraufgabe einer einzelnen Art entsprach : Das heißt, je größer die Multi-Spezies-Vortrainingsdaten im Maßstab sind, desto bessere vorab trainierte Darstellungen können erzeugt und die Leistung bei nachgelagerten Aufgaben weiter verbessert werden. Dieser Befund zeigt, dass zwischen den Arten konservierte Genregulationsmuster bestehen und dass diese Muster durch vorab trainierte Modelle gelernt und verstanden werden können. Gleichzeitig bedeutet dies auch, dass mit der Erweiterung der Arten und Daten eine weitere Verbesserung der Modellleistung zu erwarten ist
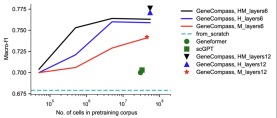
Leistungsvorteile bei mehreren Aufgaben Demonstrieren Sie die leistungsstarken Generalisierungsfähigkeiten grundlegender großer Modelle
Als bisher größtes vorab trainiertes Basislebensmodell mit Wissenseinbettung kann GeneCompass Transferlernen für mehrere nachgelagerte Aufgaben zwischen verschiedenen Arten implementieren und im Zelltyp verwendet werden Annotation, quantitative Genstörungsvorhersage, Arzneimittelsensitivitätsanalyse usw. In Bezug auf die Leistung erzielt es eine bessere Leistung als bestehende Methoden. Dies verdeutlicht vollständig die strategischen Vorteile des Vortrainings auf der Grundlage von unbeschrifteten Big Data für mehrere Arten und der anschließenden Verwendung verschiedener Teilaufgabendaten zur Modellfeinabstimmung. Es wird erwartet, dass es sich zu einer universellen Lösung für die Analyse und Vorhersage verschiedener biologischer Probleme im Zusammenhang mit Genen entwickelt -Zelleigenschaften.
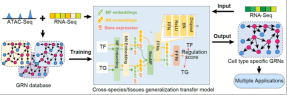
Zellpolarisierung: Transferlernen entschlüsselt Genregulationsnetzwerke und sagt Zellschicksaländerungen voraus
Verwendung von Transferlernen zur Generierung zellspezifischer Genregulationsnetzwerke
Das Team entwickelte außerdem eine Reihe von generalisierten, auf Transferlernen basierenden Das Genregulationsnetzwerk erstellt ein KI-Modell namens CellPolaris. Das Modell sortiert zunächst Hunderte von Sätzen von Transkriptom- und Chromatin-Zugänglichkeitsdaten in passenden Zellszenarien, um ein qualitativ hochwertiges Genregulationsnetzwerk aufzubauen, und verwendet dann das verallgemeinerte Transferlernmodell, um mehr Gene in Zellszenarien zu generieren, die ausschließlich Transkriptomdaten verwenden . Anschließend entwickelten wir unter Verwendung des generierten, hochzuverlässigen Genregulationsnetzwerks ein Tool zur Identifizierung zentraler Transkriptionsfaktoren für Zellschicksalsübergänge und ein Simulationstool für Transkriptionsfaktorstörungen auf der Grundlage eines probabilistischen grafischen Modells. Dieses Modell kann die Kernfaktoren der Zellschicksalumwandlung effektiv identifizieren und die Simulation der Transkriptionsfaktorstörung realisieren. Es hat einen wichtigen Anwendungswert bei der Analyse von Genregulationsmechanismen und der Entdeckung krankheitsverursachender Gene.
Das vom CellPolaris-Modell generierte Genregulationsnetzwerk bietet eine Fülle von Molekülen Interaktionsinformationen können als Vorwissen für große Deep-Learning-Modelle verwendet werden. Die durch Deep-Learning-Großmodelle erzeugten niedrigdimensionalen Einbettungsvektoren werden wichtige Informationen für die Analyse von Genregulationsmechanismen und die Entdeckung krankheitsverursachender Gene liefern.
Die beiden oben genannten Studien wurden vom Team der „Compass Alliance“ durchgeführt. Das Team der „Compass Alliance“ besteht derzeit hauptsächlich aus dem Joint Computer Network Information Center des Instituts für Zoologie, der Chinesischen Akademie der Wissenschaften, dem Institut für Automatisierung Das Ziel der Allianz besteht darin, ein neues Paradigma der Life-Science-Forschung zu etablieren, das auf digitaler Intelligenz basiert und die wesentlichen Gesetze des Lebens analysiert.
Künstliche Intelligenz × [Biologie, Neurowissenschaften, Mathematik, Physik, Chemie, Materialien]
Das obige ist der detaillierte Inhalt vonDas Forschungsteam der Chinesischen Akademie der Wissenschaften veröffentlichte zwei wichtige Arbeiten: die Veröffentlichung des ersten groß angelegten Modells der Lebensgrundlagen verschiedener Arten und die Veröffentlichung eines neuen KI-Modells zur Vorhersage des Zellschicksals. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Persönliches Hacking wird ein ziemlich heftiger Bär seinMay 11, 2025 am 11:09 AM
Persönliches Hacking wird ein ziemlich heftiger Bär seinMay 11, 2025 am 11:09 AMCyberangriffe entwickeln sich weiter. Vorbei sind die Tage generischer Phishing -E -Mails. Die Zukunft der Cyberkriminalität ist hyperpersonalisiert und nutzt leicht verfügbare Online-Daten und KI, um hoch gezielte Angriffe zu erzeugen. Stellen Sie sich einen Betrüger vor, der Ihren Job kennt, Ihr F.
 Papst Leo XIV zeigt, wie KI seine Namenswahl beeinflusst hatMay 11, 2025 am 11:07 AM
Papst Leo XIV zeigt, wie KI seine Namenswahl beeinflusst hatMay 11, 2025 am 11:07 AMIn seiner Eröffnungsrede an das College of Cardinals diskutierte der in Chicago geborene Robert Francis Prevost, der neu gewählte Papst Leo XIV, den Einfluss seines Namensvetters, Papst Leo XIII., Dessen Papsttum (1878-1903) mit der Dämmerung des Automobils und der Dämmerung des Automobils und des Automobils zusammenfiel
 FASTAPI -MCP -Tutorial für Anfänger und Experten - Analytics VidhyaMay 11, 2025 am 10:56 AM
FASTAPI -MCP -Tutorial für Anfänger und Experten - Analytics VidhyaMay 11, 2025 am 10:56 AMDieses Tutorial zeigt, wie Sie Ihr großes Sprachmodell (LLM) mit dem Modellkontextprotokoll (MCP) und Fastapi in externe Tools integrieren. Wir erstellen eine einfache Webanwendung mit Fastapi und konvertieren sie in einen MCP -Server, um Ihr L zu aktivieren
 DIA-1.6B TTS: Bestes Modell zur Generierung von Text zu Dialogue-Analytics VidhyaMay 11, 2025 am 10:27 AM
DIA-1.6B TTS: Bestes Modell zur Generierung von Text zu Dialogue-Analytics VidhyaMay 11, 2025 am 10:27 AMEntdecken Sie DIA-1.6B: Ein bahnbrechendes Text-zu-Sprach-Modell, das von zwei Studenten ohne Finanzierung entwickelt wurde! Dieses 1,6 -Milliarden -Parametermodell erzeugt eine bemerkenswert realistische Sprache, einschließlich nonverbaler Hinweise wie Lachen und Niesen. Dieser Artikelhandbuch
 3 Wege KI kann Mentoring sinnvoller als je zuvor machenMay 10, 2025 am 11:17 AM
3 Wege KI kann Mentoring sinnvoller als je zuvor machenMay 10, 2025 am 11:17 AMIch stimme voll und ganz zu. Mein Erfolg ist untrennbar mit der Anleitung meiner Mentoren verbunden. Ihre Einsichten, insbesondere in Bezug auf das Geschäftsmanagement, bildeten das Fundament meiner Überzeugungen und Praktiken. Diese Erfahrung unterstreicht mein Engagement für Mentor
 AI entblößt neues Potenzial in der BergbauindustrieMay 10, 2025 am 11:16 AM
AI entblößt neues Potenzial in der BergbauindustrieMay 10, 2025 am 11:16 AMKI verbesserte Bergbaugeräte Die Bergbaubetriebumgebung ist hart und gefährlich. Künstliche Intelligenzsysteme verbessern die Gesamteffizienz und -sicherheit, indem Menschen aus den gefährlichsten Umgebungen entfernt und die Fähigkeiten des Menschen verbessert werden. Künstliche Intelligenz wird zunehmend verwendet, um autonome LKWs, Übungen und Lader, die in Bergbauvorgängen verwendet werden, zu betreiben. Diese KI-betriebenen Fahrzeuge können in gefährlichen Umgebungen genau arbeiten und so die Sicherheit und Produktivität erhöhen. Einige Unternehmen haben autonome Bergbaufahrzeuge für groß angelegte Bergbaubetriebe entwickelt. Geräte, die in anspruchsvollen Umgebungen betrieben werden, erfordert eine kontinuierliche Wartung. Wartung kann jedoch kritische Geräte offline halten und Ressourcen konsumieren. Genauere Wartung bedeutet eine höhere Fahrt für teure und notwendige Geräte und erhebliche Kosteneinsparungen. AI-gesteuert
 Warum KI -Agenten die größte Revolution am Arbeitsplatz seit 25 Jahren auslösen werdenMay 10, 2025 am 11:15 AM
Warum KI -Agenten die größte Revolution am Arbeitsplatz seit 25 Jahren auslösen werdenMay 10, 2025 am 11:15 AMMarc Benioff, CEO von Salesforce, prognostiziert eine monumentale Revolution am Arbeitsplatz, die von AI -Agenten angetrieben wird, eine Transformation, die bereits innerhalb von Salesforce und seiner Kundenstamme im Gange ist. Er stellt sich eine Verlagerung von traditionellen Märkten zu einem weitaus größeren Markt vor, auf den sich konzentriert wird
 AI HR wird unsere Welten rocken, wenn die KI -Adoption steigtMay 10, 2025 am 11:14 AM
AI HR wird unsere Welten rocken, wenn die KI -Adoption steigtMay 10, 2025 am 11:14 AMDer Aufstieg der KI in der Personalabteilung: Navigation einer Belegschaft mit Roboterkollegen Die Integration von KI in die Personalabteilung (HR) ist kein futuristisches Konzept mehr. Es wird schnell zur neuen Realität. Diese Verschiebung wirkt sich sowohl auf HR -Fachkräfte als auch Mitarbeiter aus, DEM aus.


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver Mac
Visuelle Webentwicklungstools

MantisBT
Mantis ist ein einfach zu implementierendes webbasiertes Tool zur Fehlerverfolgung, das die Fehlerverfolgung von Produkten unterstützen soll. Es erfordert PHP, MySQL und einen Webserver. Schauen Sie sich unsere Demo- und Hosting-Services an.

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

SublimeText3 Englische Version
Empfohlen: Win-Version, unterstützt Code-Eingabeaufforderungen!

