
Heim >Technologie-Peripheriegeräte >KI >Ein Trick zur Unterscheidung groß angelegter Betrugsmodelle ist der Open-Source-KI-Mathematik-„Dämonenspiegel' des Bruders des Arztes.
Ein Trick zur Unterscheidung groß angelegter Betrugsmodelle ist der Open-Source-KI-Mathematik-„Dämonenspiegel' des Bruders des Arztes.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-11-17 12:38:44790Durchsuche
Heutzutage behaupten viele große Models, gut in Mathematik zu sein. Wer hat echtes Talent? Wer hat bei den aufeinanderfolgenden Testfragen „geschummelt“?
Dieses Jahr führte jemand einen umfassenden Test zu den Fragen durch, die gerade für die ungarische nationale Mathematik-Abschlussprüfung freigegeben wurden
Viele Modelle zeigten plötzlich „ihre ursprüngliche Form“.
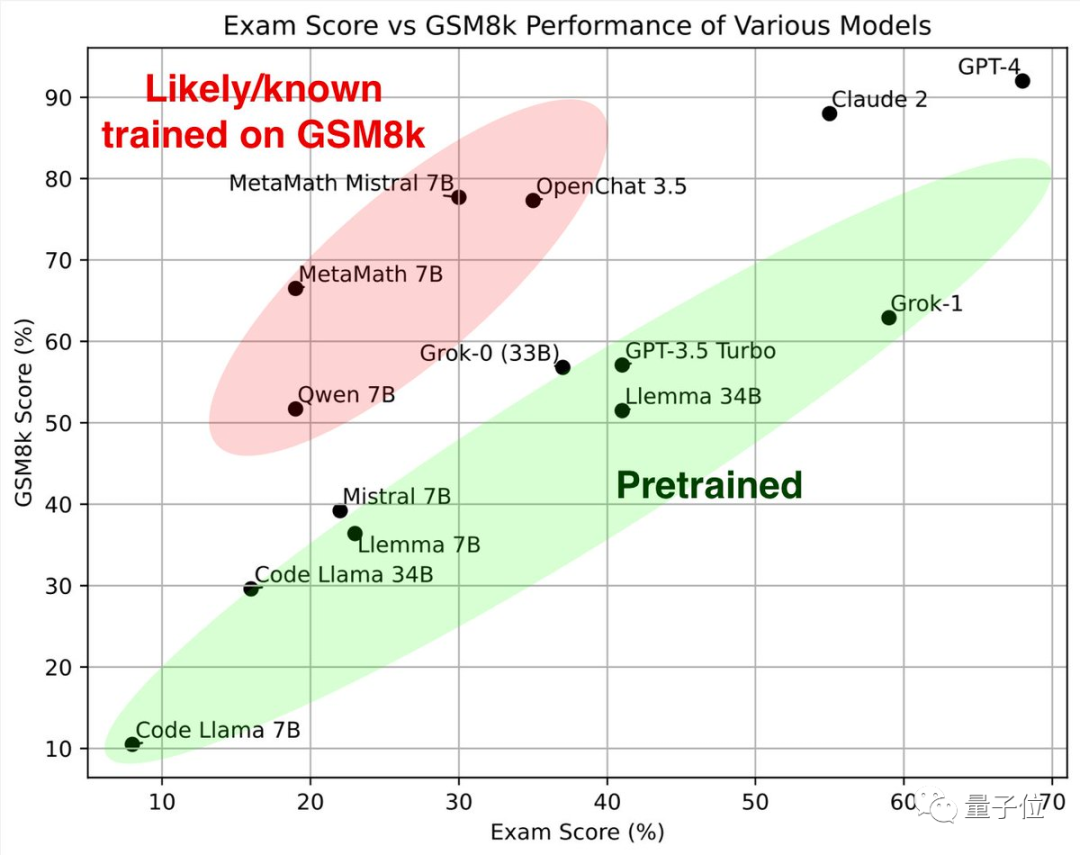
Schauen Sie sich zuerst den grünen Teil an Diese großen Modelle haben ähnliche Ergebnisse beim klassischen Mathematik-Testset GSM8k und dem neuen Papier, zusammen bilden sie den Referenzstandard.
Betrachtet man den roten Teil, ist die Punktzahl bei GSM8K deutlich höher als die des großen Modells mit der gleichen Parameterskala. Die Punktzahl ist auf dem neuen Papier deutlich gesunken, was fast gleich ist als das große Modell im gleichen Maßstab.
Forscher stuften sie als „vermutlich oder bekanntermaßen auf GSM8k geschult“ ein.
Nachdem sie sich diesen Test angesehen hatten, sagten einige Leute, dass sie anfangen sollten, Fragen zu bewerten, die sie noch nie zuvor gesehen hatten

Einige Leute denken, dass diese Art von Test und die tatsächliche Erfahrung jedes Einzelnen mit der Verwendung großer Modelle derzeit die einzige zuverlässige Bewertung sind Methode
Musk Grok ist nach GPT-4 der zweitgrößte und das Open-Source-Llemma hat hervorragende Ergebnisse erzielt
Der TesterKeiran Paster ist Doktorand an der University of Toronto, studentischer Forscher bei Google und Ein großes Lemma-Modell im Test einer der Autoren.
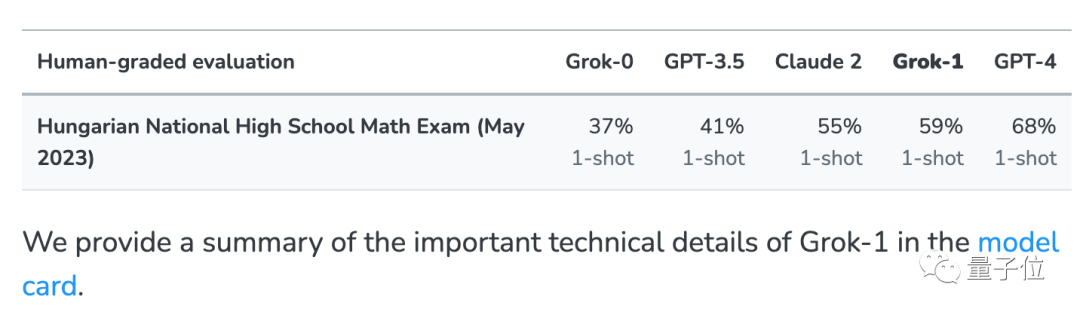
Lassen Sie das große Model die Mathematik-Abschlussprüfung des ungarischen Gymnasiums absolvieren. Dieser Trick stammt von Musks xAI.
Um das Problem auszuschließen, dass das Grok-Großmodell von xAI versehentlich Testfragen in Netzwerkdaten sah, wurde zusätzlich zu mehreren gängigen Testsätzen auch dieser Test durchgeführt
Diese Prüfung wurde erst Ende Mai dieses Jahres abgeschlossen. Derzeit die meisten Das Modell hat diese Testfragen im Grunde noch nie gesehen.
xAI gab bei der Veröffentlichung zum Vergleich auch die Ergebnisse von GPT-3.5, GPT-4 und Claude 2 bekannt.
Basierend auf diesem Datensatz führte Paster weitere Tests durch. Die Testobjekte waren mehrere Open-Source-Modelle mit starken mathematischen Fähigkeiten. Die Testfragen, Testskripte und Antwortergebnisse jedes Modells waren alle
Es ist Open Source auf Huggingface, sodass jeder andere Modelle überprüfen und weiter testen kann.
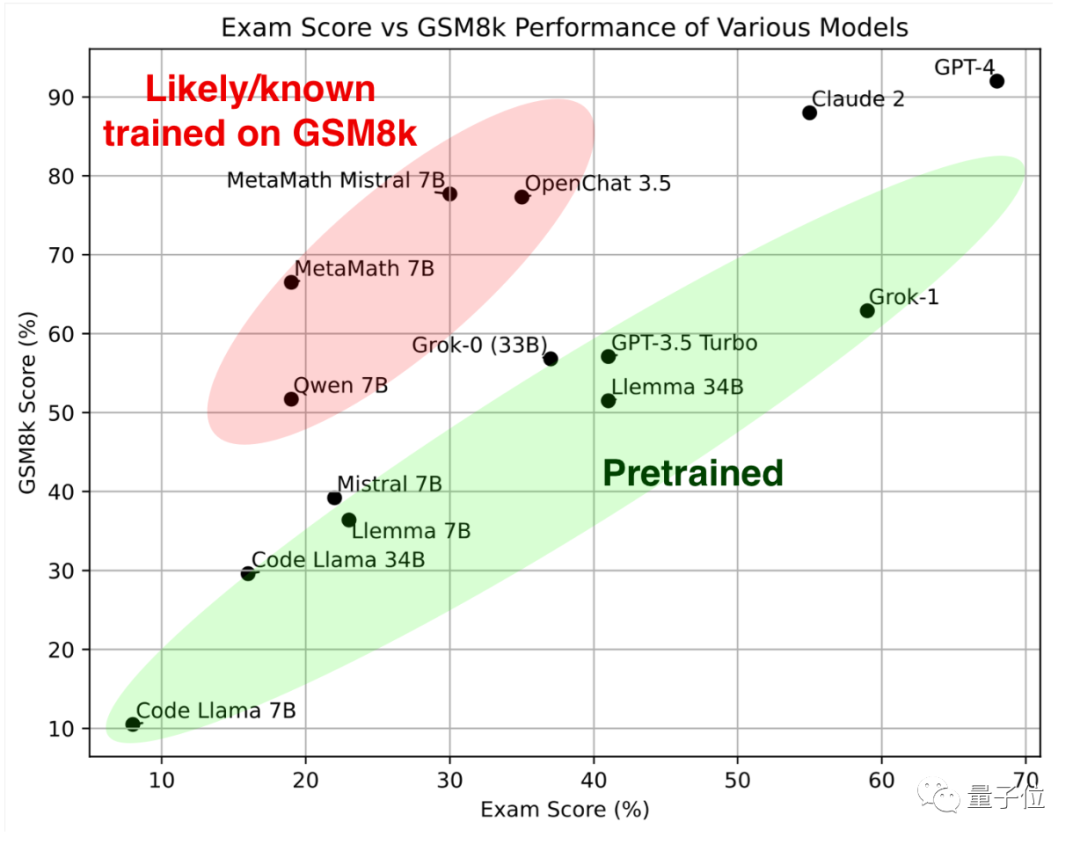 Den Ergebnissen nach zu urteilen, bilden GPT-4 und Claude-2 die erste Staffel, mit sehr guten Ergebnissen auf GSM8k und dem neuen Papier.
Den Ergebnissen nach zu urteilen, bilden GPT-4 und Claude-2 die erste Staffel, mit sehr guten Ergebnissen auf GSM8k und dem neuen Papier.
Obwohl dies nicht bedeutet, dass die Trainingsdaten von GPT-4 und Claude 2 keine durchgesickerten GSM8k-Fragen enthalten, verfügen sie zumindest über eine gute Verallgemeinerungsfähigkeit und können neue Fragen korrekt lösen, sodass es ihnen egal ist.
Als nächstes entwickelten sich Grok-0
(33B)und Grok-1 (unangekündigte Parameterskala) von Musk xAI beide gut.
Grok-1 hat die höchste Punktzahl in der „Nicht-Schummel-Gruppe“ und die neue Papierpunktzahl ist sogar höher als Claude 2. Die Leistung von Grok-0 auf GSM8k liegt nahe an GPT3.5-Turbo und ist auf dem neuen Papier etwas schlechter.
Mit Ausnahme der oben genannten geschlossenen Modelle sind alle anderen Modelle im Test Open Source.
Die Code-Llama-Serie ist Metas eigene Feinabstimmung, die auf Llama 2 basiert und sich auf die Generierung von Code basierend auf natürlicher Sprache konzentriert. Jetzt schauen Die mathematischen Fähigkeiten sind etwas schlechter als bei Modellen im gleichen Maßstab.
 Basierend auf Code Llama haben viele Universitäten und Forschungseinrichtungen gemeinsam die
Basierend auf Code Llama haben viele Universitäten und Forschungseinrichtungen gemeinsam die
Llemma-Reihe ins Leben gerufen, die von EleutherAI als Open Source bereitgestellt wurde. Das Team sammelte den Proof-Pile-2-Datensatz aus wissenschaftlichen Arbeiten, Netzwerkdaten mit Mathematik und mathematischem Code. Nach dem Training kann Llemma ohne weitere Feinabstimmung Tools verwenden und formale Theorembeweise durchführen.
Auf dem neuen Papier liegt die Leistung von Llemma 34B nahe am GPT-3.5 Turbo-NiveauDie Mistral-Serie wird vom französischen KI-Einhorn Mistral AI trainiert. Die Open-Source-Vereinbarung Apache2.0 ist lockerer als Llama und hat sich nach der Alpaka-Familie zum beliebtesten Basismodell in der Open-Source-Community entwickelt. „Overfitting Group“ OpenChat 3.5 und MetaMath Mistral sind beide auf Basis des Mistral-Ökosystems fein abgestimmt. MetaMath und MAmmoTH Code basieren auf dem Code Llama-Ökosystem. Diejenigen, die sich dafür entscheiden, große Open-Source-Modelle in der Praxis einzuführen, müssen vorsichtig sein, diese Gruppe zu meiden, da sie wahrscheinlich gute Leistungen erbringen, nur um Rankings zu gewinnen, ihre tatsächlichen Fähigkeiten jedoch möglicherweise nicht so stark sind wie die anderer Modelle derselben Art Skala Nein Viele Internetnutzer bedankten sich bei Paster für dieses Experiment und glaubten, dass dies genau das ist, was zum Verständnis der tatsächlichen Situation des Modells erforderlich ist. Einige Leute haben Bedenken geäußert: Von diesem Tag an wird jeder, der große Modelle trainiert, ungarische Mathematikprüfungsfragen aus früheren Jahren berücksichtigen. Gleichzeitig glaubt er, dass die Lösung darin bestehen könnte, ein spezialisiertes großes Modellbewertungsunternehmen mit proprietären Tests zu haben. Ein weiterer Vorschlag besteht darin, einen Test-Benchmark einzurichten, der Jahr für Jahr aktualisiert wird, um das Problem der Überanpassung zu lindern. 


Das obige ist der detaillierte Inhalt vonEin Trick zur Unterscheidung groß angelegter Betrugsmodelle ist der Open-Source-KI-Mathematik-„Dämonenspiegel' des Bruders des Arztes.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!