
Heim >Technologie-Peripheriegeräte >KI >Neuer Titel: NVIDIA H200 veröffentlicht: HBM-Kapazität um 76 % erhöht, der leistungsstärkste KI-Chip, der die Leistung großer Modelle deutlich um 90 % verbessert
Neuer Titel: NVIDIA H200 veröffentlicht: HBM-Kapazität um 76 % erhöht, der leistungsstärkste KI-Chip, der die Leistung großer Modelle deutlich um 90 % verbessert

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-11-14 15:21:131574Durchsuche

Neuigkeiten am 14. November: Nvidia hat die neue H200-GPU offiziell veröffentlicht und die GH200-Produktlinie auf der Konferenz „Supercomputing 23“ am Morgen des 13. Ortszeit aktualisiert
Unter diesen basiert H200 immer noch auf der bestehenden Hopper H100-Architektur, fügt jedoch mehr Speicher mit hoher Bandbreite (HBM3e) hinzu, um die großen Datensätze, die für die Entwicklung und Implementierung künstlicher Intelligenz erforderlich sind, besser verarbeiten zu können, sodass große Modelle ausgeführt werden können. Die Gesamtleistung ist im Vergleich zur Vorgängergeneration H100 um 60 % bis 90 % verbessert. Der aktualisierte GH200 wird auch die nächste Generation von KI-Supercomputern antreiben. Im Jahr 2024 werden mehr als 200 Exaflops KI-Rechenleistung online gehen.
H200: HBM-Kapazität um 76 % erhöht, Leistung großer Modelle um 90 % verbessert
Konkret bietet der neue H200 bis zu 141 GB HBM3e-Speicher, der effektiv mit etwa 6,25 Gbit/s läuft, was einer Gesamtbandbreite von 4,8 TB/s pro GPU in den sechs HBM3e-Stacks entspricht. Dies ist eine enorme Verbesserung im Vergleich zur H100 der vorherigen Generation (mit 80 GB HBM3 und 3,35 TB/s Bandbreite), mit einer Steigerung der HBM-Kapazität um mehr als 76 %. Offiziellen Daten zufolge wird H200 beim Betrieb großer Modelle eine Verbesserung von 60 % (GPT3 175B) bis 90 % (Llama 2 70B) im Vergleich zu H100 bringen


Während einige Konfigurationen des H100 mehr Speicher bieten, wie zum Beispiel das H100 NVL, das die beiden Platinen koppelt und insgesamt 188 GB Speicher (94 GB pro GPU) bietet, sogar im Vergleich zur H100 SXM-Variante, ist dies beim neuen H200 SXM ebenfalls der Fall bietet 76 % mehr Speicherkapazität und 43 % mehr Bandbreite.
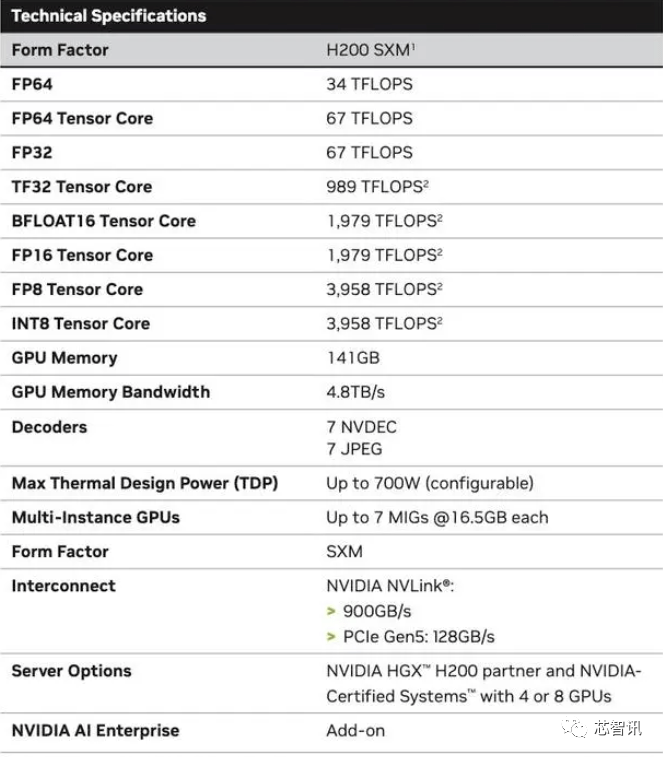
Es sollte darauf hingewiesen werden, dass sich an der reinen Rechenleistung des H200 offenbar nicht viel geändert hat. Auf der einzigen Folie zeigte Nvidia, dass die reflektierte Rechenleistung auf einer HGX 200-Konfiguration mit acht GPUs basierte, mit einer Gesamtleistung von „32 PFLOPS FP8“. Während der ursprüngliche H100 3.958 Teraflops FP8-Rechenleistung bereitstellte, bieten acht dieser GPUs auch etwa 32 PFLOPS FP8-Rechenleistung
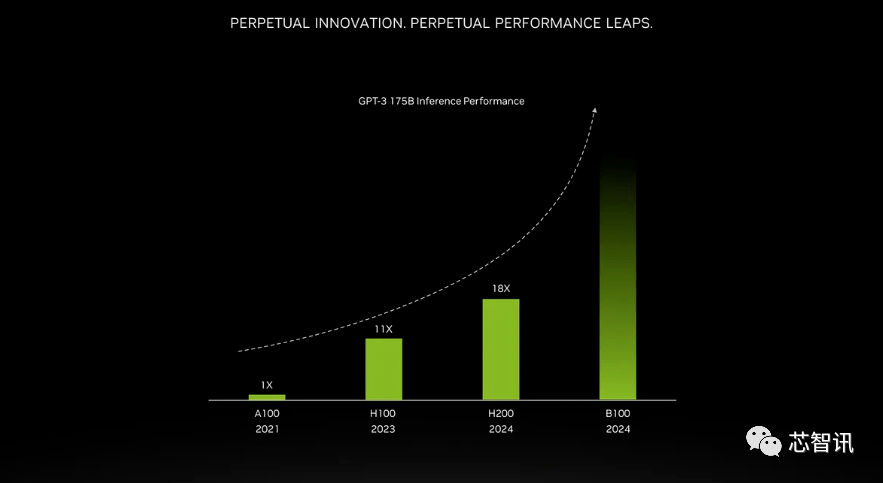
Die Verbesserung durch Speicher mit höherer Bandbreite hängt von der Arbeitslast ab. Große Modelle (wie GPT-3) werden von der Erhöhung der HBM-Speicherkapazität stark profitieren. Laut Nvidia wird der H200 beim Ausführen von GPT-3 18-mal besser abschneiden als der ursprüngliche A100 und etwa 11-mal schneller als der H100. Darüber hinaus zeigt ein Teaser für den kommenden Blackwell B100, dass er einen höheren Balken enthält, der schwarz wird und ungefähr doppelt so lang ist wie der H200 ganz rechts
Darüber hinaus sind H200 und H100 miteinander kompatibel. Mit anderen Worten: KI-Unternehmen, die das H100-Trainings-/Inferenzmodell verwenden, können nahtlos auf den neuesten H200-Chip umsteigen. Cloud-Service-Anbieter müssen keine Änderungen vornehmen, wenn sie H200 zu ihrem Produktportfolio hinzufügen.
Nvidia sagte, dass sie durch die Einführung neuer Produkte hoffen, mit dem Wachstum der Größe der Datensätze Schritt halten zu können, die zur Erstellung von Modellen und Diensten für künstliche Intelligenz verwendet werden. Durch die verbesserten Speicherkapazitäten kann der H200 Daten schneller an die Software weiterleiten, ein Prozess, der dabei hilft, künstliche Intelligenz für Aufgaben wie das Erkennen von Bildern und Sprache zu trainieren.
„Die Integration eines schnelleren HBM-Speichers mit größerer Kapazität trägt dazu bei, die Leistung für rechenintensive Aufgaben, einschließlich generativer KI-Modelle und Hochleistungs-Computing-Anwendungen, zu verbessern und gleichzeitig die GPU-Nutzung und -Effizienz zu optimieren“, sagte Ian Buck, Vice President of Product.
Dion Harris, Leiter für Rechenzentrumsprodukte bei NVIDIA, sagte: „Wenn man sich die Trends in der Marktentwicklung ansieht, nehmen die Modellgrößen rapide zu. Dies ist ein Beispiel dafür, wie wir weiterhin die neueste und beste Technologie einführen.“
Hersteller von Großrechnern und Cloud-Dienstanbieter werden voraussichtlich im zweiten Quartal 2024 mit der Nutzung des H200 beginnen. NVIDIA-Serverherstellerpartner (darunter Evergreen, ASUS, Dell, Eviden, Gigabyte, HPE, Hongbai, Lenovo, Wenda, MetaVision, Wistron und Wiwing) können den H200 zum Aktualisieren bestehender Systeme verwenden, während Amazon, Google, Microsoft, Oracle usw. wird der erste Cloud-Dienstanbieter sein, der H200 einführt.Angesichts der derzeit starken Marktnachfrage nach NVIDIA AI-Chips und dem neuen H200, der teureren HBM3e-Speicher hinzufügt, wird der Preis des H200 definitiv höher sein. Einen Preis nennt Nvidia nicht, die vorherige H100-Generation kostete jedoch 25.000 bis 40.000 US-Dollar.
NVIDIA-Sprecherin Kristin Uchiyama sagte, dass der endgültige Preis von den Produktionspartnern von NVIDIA festgelegt wird
Zu der Frage, ob sich die Einführung von H200 auf die Produktion von H100 auswirken wird, sagte Kristin Uchiyama: „Wir gehen davon aus, dass das Gesamtangebot im Laufe des Jahres steigen wird
.“Nvidias High-End-KI-Chips gelten seit jeher als die beste Wahl für die Verarbeitung großer Datenmengen und das Training großer Sprachmodelle und KI-Generierungstools. Als der H200-Chip auf den Markt kam, suchten KI-Unternehmen jedoch immer noch verzweifelt nach A100/H100-Chips auf dem Markt. Der Markt konzentriert sich weiterhin darauf, ob Nvidia genügend Angebot bereitstellen kann, um die Marktnachfrage zu decken. Daher hat NVIDIA keine Antwort darauf gegeben, ob H200-Chips ebenso knapp sein werden wie H100-Chips
Nächstes Jahr könnte jedoch ein günstigerer Zeitraum für GPU-Käufer sein. Laut einem Bericht der Financial Times vom August plant NVIDIA, die H100-Produktion im Jahr 2024 zu verdreifachen, und das Produktionsziel wird von etwa 500.000 im Jahr 2023 auf angehoben 2 Millionen im Jahr 2024. Aber generative KI boomt immer noch und die Nachfrage dürfte in Zukunft noch größer sein.
Zum Beispiel wird der neu eingeführte GPT-4 auf etwa 10.000–25.000 A100-Blöcken trainiert. Das große KI-Modell von Meta benötigt für das Training etwa 21.000 A100-Blöcke. Stabilitäts-KI verwendet etwa 5.000 A100. Das Falcon-40B-Training erfordert 384 A100
Laut Musk kann GPT-5 30.000–50.000 H100 erfordern. Das Angebot von Morgan Stanley lautet 25.000 GPUs.
Sam Altman bestritt, GPT-5 zu trainieren, erwähnte jedoch, dass „OpenAI einen ernsthaften Mangel an GPUs hat und je weniger Leute unsere Produkte nutzen, desto besser.“
Natürlich steigen neben NVIDIA auch AMD und Intel aktiv in den KI-Markt ein, um mit NVIDIA zu konkurrieren. Der zuvor von AMD auf den Markt gebrachte MI300X ist mit 192 GB HBM3 und einer Speicherbandbreite von 5,2 TB/s ausgestattet, wodurch er den H200 in Bezug auf Kapazität und Bandbreite weit übertreffen wird.
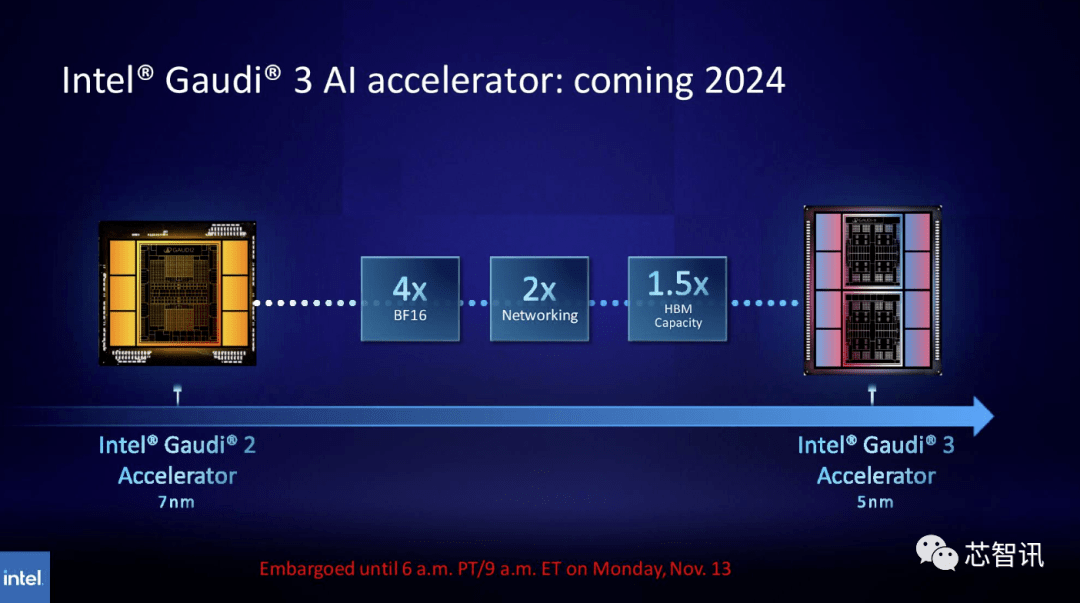
In ähnlicher Weise plant Intel, die HBM-Kapazität der Gaudi AI-Chips zu erhöhen. Den neuesten veröffentlichten Informationen zufolge verwendet Gaudi 3 einen 5-nm-Prozess und seine Leistung bei BF16-Workloads wird viermal so hoch sein wie die von Gaudi 2, und seine Netzwerkleistung wird auch doppelt so hoch sein wie die von Gaudi 2 (Gaudi 2 verfügt über 24 integrierte 100 GbE RoCE-NICs). Darüber hinaus verfügt Gaudi 3 über die 1,5-fache HBM-Kapazität von Gaudi 2 (Gaudi 2 verfügt über ein 96 GB HBM2E). Wie auf dem Bild unten zu sehen ist, verwendet Gaudi 3 ein Chiplet-basiertes Design mit zwei Rechenclustern, im Gegensatz zu Gaudi 2, das die Single-Chip-Lösung von Intel nutzt
Neuer GH200-Superchip: Antrieb für die nächste Generation von KI-Supercomputern
Neben der Veröffentlichung der neuen H200-GPU hat NVIDIA auch eine aktualisierte Version des GH200-Superchips auf den Markt gebracht. Dieser Chip nutzt die NVIDIA NVLink-C2C-Chipverbindungstechnologie und kombiniert die neueste H200-GPU und Grace-CPU (nicht sicher, ob es sich um eine aktualisierte Version handelt). Jeder GH200-Superchip verfügt außerdem über insgesamt 624 GB Speicher

Zum Vergleich: Die GH200 der vorherigen Generation basiert auf einer H100-GPU und einer 72-Kern-Grace-CPU und bietet 96 GB HBM3 und 512 GB LPDDR5X, die im selben Paket integriert sind.
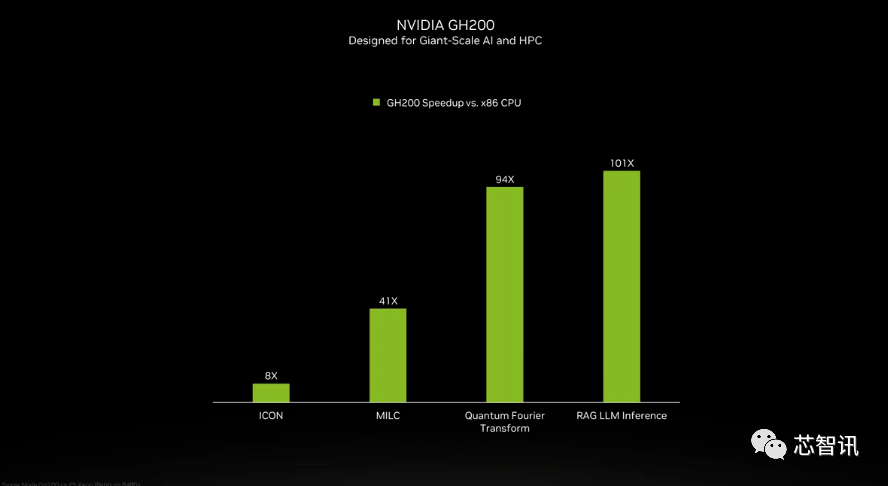
Obwohl NVIDIA die Details der Grace-CPU im GH200-Superchip nicht vorgestellt hat, lieferte NVIDIA einige Vergleiche zwischen GH200 und „modernen Dual-Socket-x86-CPUs“. Es ist ersichtlich, dass GH200 eine 8-fache Verbesserung der ICON-Leistung gebracht hat, und MILC, Quantum Fourier Transform, RAG LLM Inference usw. haben eine Verbesserung um das Dutzende oder sogar Hundertfache gebracht.
Aber es ist darauf hinzuweisen, dass von beschleunigten und „nicht beschleunigten Systemen“ die Rede ist. was bedeutet das? Wir können nur davon ausgehen, dass auf x86-Servern Code ausgeführt wird, der nicht vollständig optimiert ist, insbesondere angesichts der Tatsache, dass sich die Welt der künstlichen Intelligenz rasant weiterentwickelt und scheinbar regelmäßig neue Fortschritte bei der Optimierung auftauchen.
Der neue GH200 wird auch im neuen HGX H200-System zum Einsatz kommen. Diese sollen „nahtlos kompatibel“ mit bestehenden HGX H100-Systemen sein, was bedeutet, dass HGX H200s in derselben Installation verwendet werden können, um Leistung und Speicherkapazität zu erhöhen, ohne dass die Infrastruktur neu gestaltet werden muss.
Berichten zufolge könnte der Alpine-Supercomputer des Schweizerischen Nationalen Hochleistungsrechenzentrums einer der ersten GH100-basierten Grace-Hopper-Supercomputer sein, die nächstes Jahr in Betrieb genommen werden. Das erste GH200-System, das in den Vereinigten Staaten in Betrieb genommen wird, wird der Supercomputer Venado im Los Alamos National Laboratory sein. Die Vista-Systeme des Texas Advanced Computing Center (TACC) werden ebenfalls die gerade angekündigten Grace-CPU- und Grace-Hopper-Superchips verwenden, es ist jedoch unklar, ob sie auf dem H100 oder H200 basieren werden

Derzeit ist der größte Supercomputer, der installiert wird, der Jupiter-Supercomputer im Jϋlich Supercomputing Center. Es wird „fast“ 24.000 GH200-Superchips beherbergen, was insgesamt 93 Exaflops KI-Computing entspricht (vermutlich mit FP8, obwohl die meisten KI immer noch BF16 oder FP16 verwenden). Es wird außerdem 1 Exaflop des traditionellen FP64-Computings liefern. Es wird ein „Quad GH200“-Board mit vier GH200-Superchips verwendet.
Diese neuen Supercomputer, die NVIDIA voraussichtlich im nächsten Jahr installieren wird, werden zusammen mehr als 200 Exaflops an Rechenleistung für künstliche Intelligenz erreichen
Wenn die ursprüngliche Bedeutung nicht geändert werden muss, muss der Inhalt ins Chinesische umgeschrieben werden und der ursprüngliche Satz muss nicht erscheinen
Das obige ist der detaillierte Inhalt vonNeuer Titel: NVIDIA H200 veröffentlicht: HBM-Kapazität um 76 % erhöht, der leistungsstärkste KI-Chip, der die Leistung großer Modelle deutlich um 90 % verbessert. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Miniprogramm: Verwenden Sie wx:key, um die Rendering-Effizienz von wx:for zu verbessern
- Wie können sich Programmierer in Zukunft verbessern?
- Was ist PHP-FPM? Wie kann man optimieren, um die Leistung zu verbessern?
- Großer Durchbruch, angekündigt von der Chinesischen Akademie der Wissenschaften! Werden KI-Chips die Welt verändern, 1,5 bis 10 Mal schneller als Nvidia? Das direkte Tageslimit des Konzeptführers
- IBM erwägt den Einsatz eigener KI-Chips in neuen Cloud-Diensten [mit Analyse der globalen Aussichten für die Entwicklung von KI-Chips]