
Heim >Technologie-Peripheriegeräte >KI >Empfehlungssystem für die NetEase Cloud Music-Kaltstarttechnologie
Empfehlungssystem für die NetEase Cloud Music-Kaltstarttechnologie

- PHPznach vorne
- 2023-11-14 08:14:101287Durchsuche

1. Problemhintergrund: Die Notwendigkeit und Bedeutung der Kaltstartmodellierung
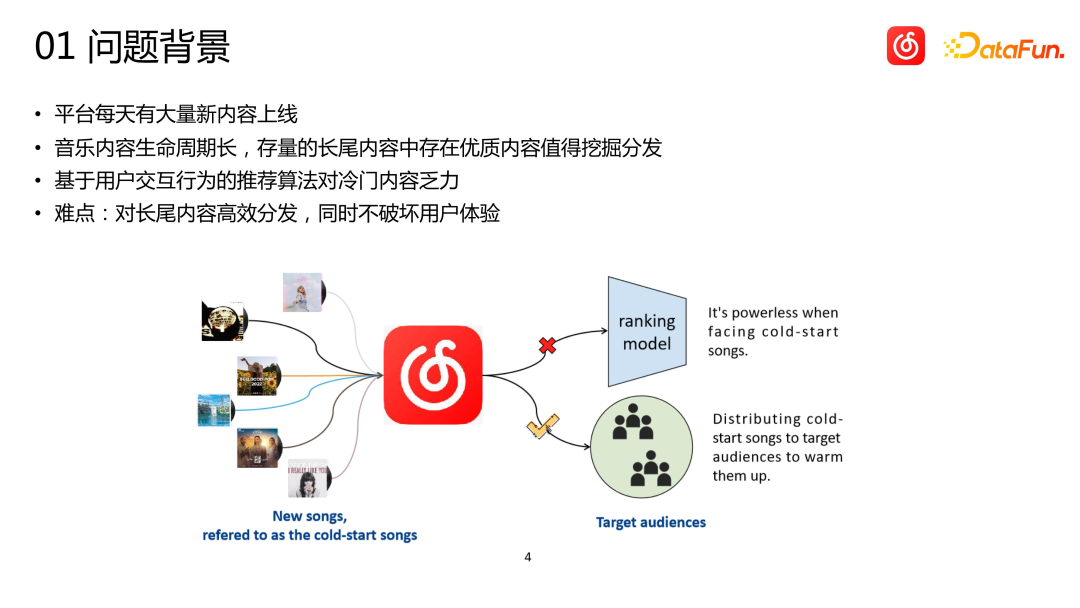
Als Content-Plattform stellt Cloud Music täglich eine große Menge neuer Inhalte online. Obwohl die Menge an neuen Inhalten auf der Cloud-Musikplattform im Vergleich zu anderen Plattformen, wie etwa Kurzvideos, relativ gering ist, kann die tatsächliche Menge die Vorstellungskraft eines jeden bei weitem übersteigen. Gleichzeitig unterscheiden sich Musikinhalte deutlich von kurzen Videos, Nachrichten und Produktempfehlungen. Der Lebenszyklus von Musik erstreckt sich über extrem lange Zeiträume, oft gemessen in Jahren. Manche Songs können explodieren, nachdem sie monate- oder jahrelang inaktiv waren, und klassische Songs können auch nach mehr als zehn Jahren noch eine starke Vitalität haben. Daher ist es für das Empfehlungssystem von Musikplattformen wichtiger, unpopuläre und Long-Tail-Inhalte von hoher Qualität zu entdecken und sie den richtigen Benutzern zu empfehlen, als andere Kategorien zu empfehlen
Unpopuläre und Long-Tail-Artikel ( Songs ) Aufgrund des Mangels an Benutzerinteraktionsdaten ist es für Empfehlungssysteme, die hauptsächlich auf Verhaltensdaten basieren, sehr schwierig, eine genaue Verteilung zu erreichen. Die ideale Situation besteht darin, einen kleinen Teil des Datenverkehrs für die Erkundung und Verteilung zu verwenden und während der Erkundung Daten zu sammeln. Allerdings ist der Online-Traffic sehr wertvoll und die Erkundung beeinträchtigt oft leicht das Benutzererlebnis. Da wir direkt für Geschäftsindikatoren verantwortlich sind, erlauben uns Empfehlungen nicht, zu viele unsichere Untersuchungen für diese Long-Tail-Elemente durchzuführen. Daher müssen wir in der Lage sein, die potenziellen Zielbenutzer des Elements von Anfang an genauer zu finden, d. h. das Element mit Null-Interaktionsdatensätzen kalt zu starten.
Zweitens technische Lösungen: Funktionsauswahl, Modellmodellierung
Als Nächstes werde ich die von Cloud Music übernommenen technischen Lösungen vorstellen.

Die Kernfrage ist, wie man potenzielle Zielnutzer für Kaltstartprojekte findet. Wir unterteilen die Frage in zwei Teile:
Welche anderen effektiven Informationen verfügt das Kaltstartprojekt für den Fall, dass kein Benutzer zum Abspielen klickt, die als Funktionen verwendet werden können, um uns bei der Verbreitung zu helfen? Hier nutzen wir die multimodalen Funktionen von Musik
Wie nutzt man diese Funktionen zur Modellierung der Kaltstartverteilung? Um dieses Problem anzugehen, werden wir zwei Hauptmodellierungslösungen vorstellen:
- I2I-Modellierung: Selbstgesteuerter Kaltstartalgorithmus mit kontrastivem Lernen.
- U2I-Modellierung: multimodale DSSM-Benutzerinteressengrenzenmodellierung.
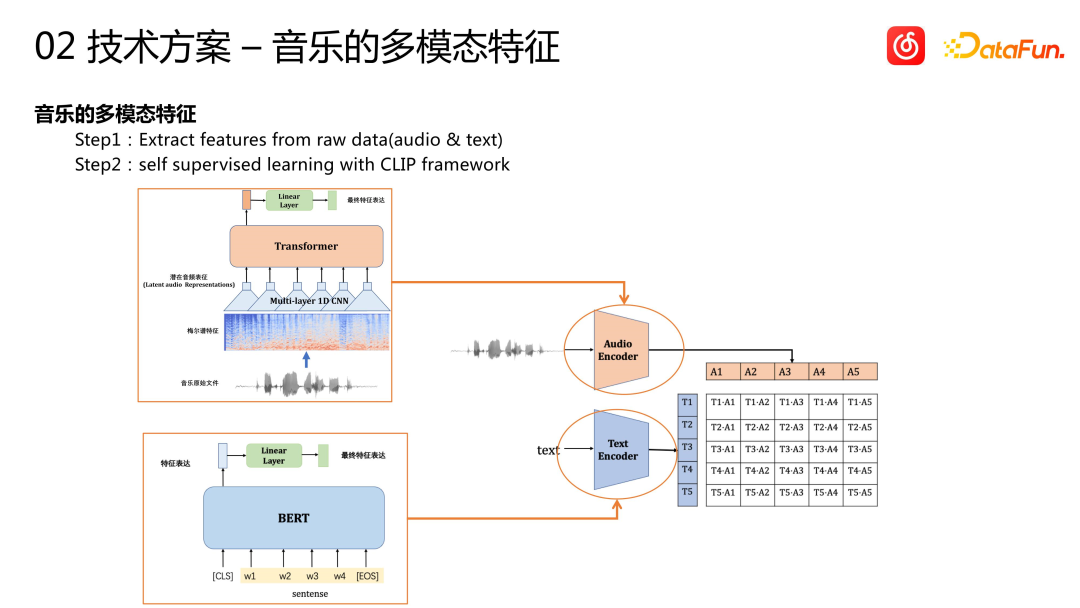
Ins Chinesische umgeschrieben: Das Lied selbst ist eine Art multimodale Information. Zusätzlich zu Tag-Informationen wie Sprache und Genre enthalten der Ton und der Text des Liedes (einschließlich Liedtitel und Liedtext) umfangreiche Informationen. Das Verstehen dieser Informationen und das Erkennen von Zusammenhängen zwischen ihnen und dem Benutzerverhalten ist der Schlüssel für einen erfolgreichen Kaltstart. Derzeit verwendet die Cloud-Musikplattform das CLIP-Framework, um einen multimodalen Funktionsausdruck zu erreichen. Für Audiofunktionen werden zunächst einige Audiosignalverarbeitungsmethoden verwendet, um sie in die Form der Videodomäne umzuwandeln. Anschließend werden Sequenzmodelle wie Transformer zur Merkmalsextraktion und -modellierung verwendet, und schließlich wird ein Audiovektor erhalten. Für Textmerkmale wird das BERT-Modell zur Merkmalsextraktion verwendet. Schließlich wird das selbstüberwachte Pre-Training-Framework von CLIP verwendet, um diese Funktionen zu serialisieren und die multimodale Darstellung des Songs zu erhalten.
Für die multimodale Modellierung gibt es in der Branche zwei Ansätze. Eine davon besteht darin, multimodale Funktionen in das Geschäftsempfehlungsmodell für ein einstufiges End-to-End-Training zu integrieren. Diese Methode ist jedoch teurer. Daher haben wir uns für eine zweistufige Modellierung entschieden. Führen Sie zunächst eine Modellierung vor dem Training durch und geben Sie diese Funktionen dann zur Verwendung in das Rückrufmodell oder Verfeinerungsmodell des nachgelagerten Unternehmens ein.
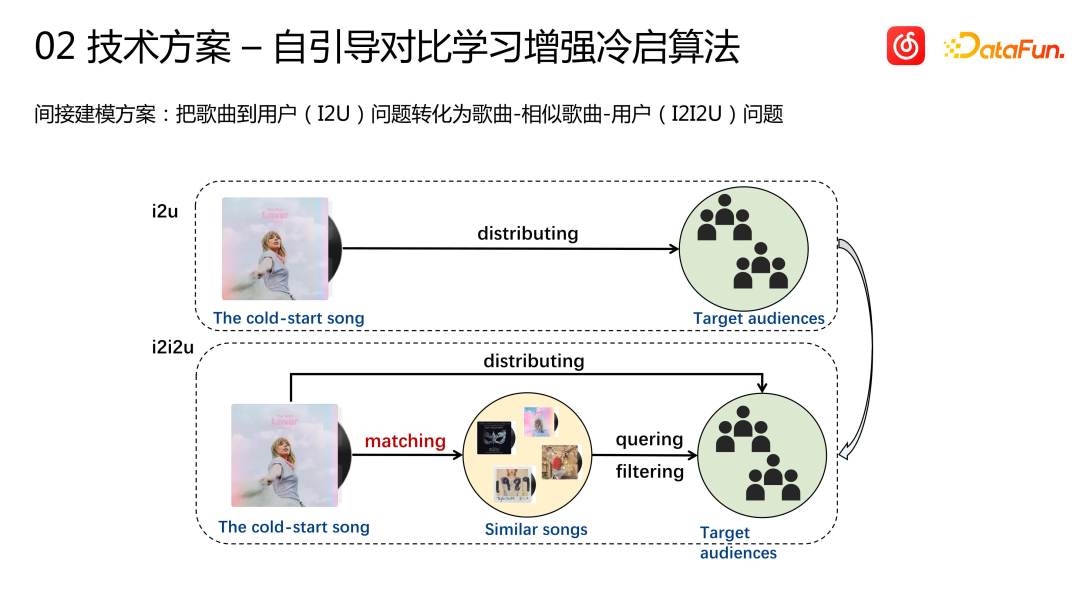
Wie verteile ich einen Song ohne Benutzerinteraktion an Benutzer? Wir verwenden eine indirekte Modellierungslösung: Wandeln Sie das Song-to-User-Problem (I2U) in ein Song-ähnliches Song-User-Problem (I2I2U) um, dh finden Sie zuerst Songs, die diesem Kaltstart-Song ähneln, und dann diese ähnlichen Songs Übereinstimmung mit dem Benutzer Es gibt einige historische Interaktionsdatensätze, z. B. Sammlungen und andere relativ starke Signale, und es kann eine Gruppe von Zielbenutzern gefunden werden. Dieser Kaltstartsong wird dann an diese Zielbenutzer verteilt.
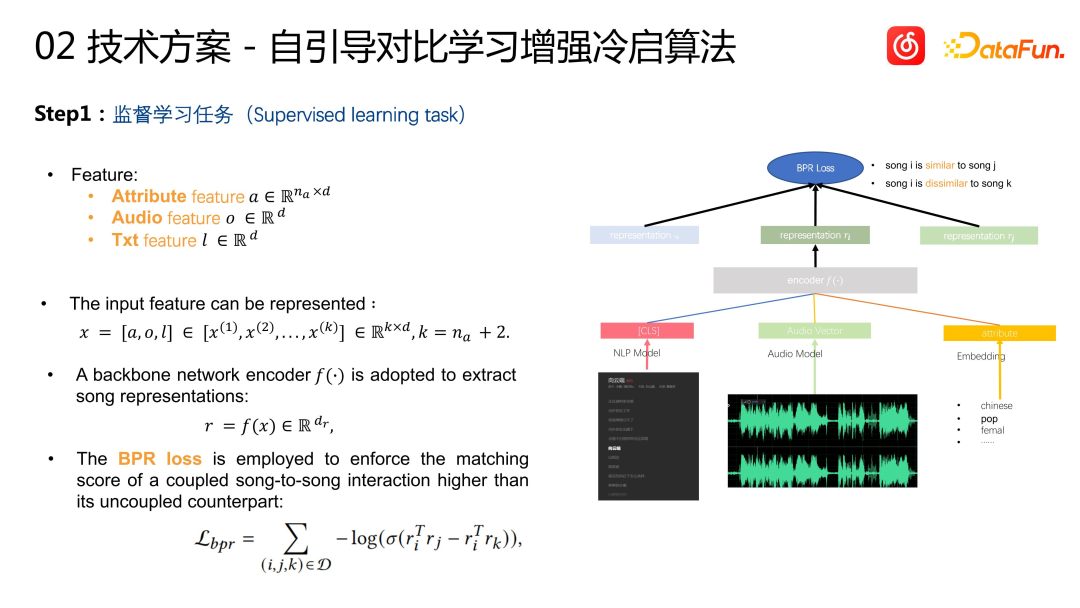
Die spezifische Methode ist wie folgt. Der erste Schritt ist die Aufgabe des überwachten Lernens. In Bezug auf Songfunktionen umfassen sie zusätzlich zu den gerade erwähnten multimodalen Informationen auch Song-Tag-Informationen wie Sprache, Genre usw., um uns bei der Durchführung einer personalisierten Modellierung zu helfen. Wir fassen alle Merkmale zusammen, geben sie in einen Encoder ein und geben schließlich Liedvektoren aus. Die Ähnlichkeit jedes Liedvektors kann durch das innere Vektorprodukt dargestellt werden. Das Lernziel ist die Ähnlichkeit von I2I, die auf der Grundlage des Verhaltens berechnet wird, dh die Ähnlichkeit der kollaborativen Filterung. Wir fügen eine Ebene zur Überprüfung nach dem Test hinzu, die auf den Daten der kollaborativen Filterung basiert, dh nach der Empfehlung basierend auf I2I, dem Benutzer Der Feedback-Effekt ist besser. Ein Elementpaar wird als positives Beispiel für das Lernen verwendet, um die Genauigkeit des Lernziels sicherzustellen. Negative Stichproben werden mithilfe globaler Zufallsstichproben erstellt. Die Verlustfunktion verwendet den BPR-Verlust. Dies ist ein sehr standardmäßiger CB2CF-Ansatz im Empfehlungssystem, der darin besteht, die Ähnlichkeit von Songs in den Benutzerverhaltensmerkmalen basierend auf den Inhalts- und Labelinformationen des Songs zu lernen
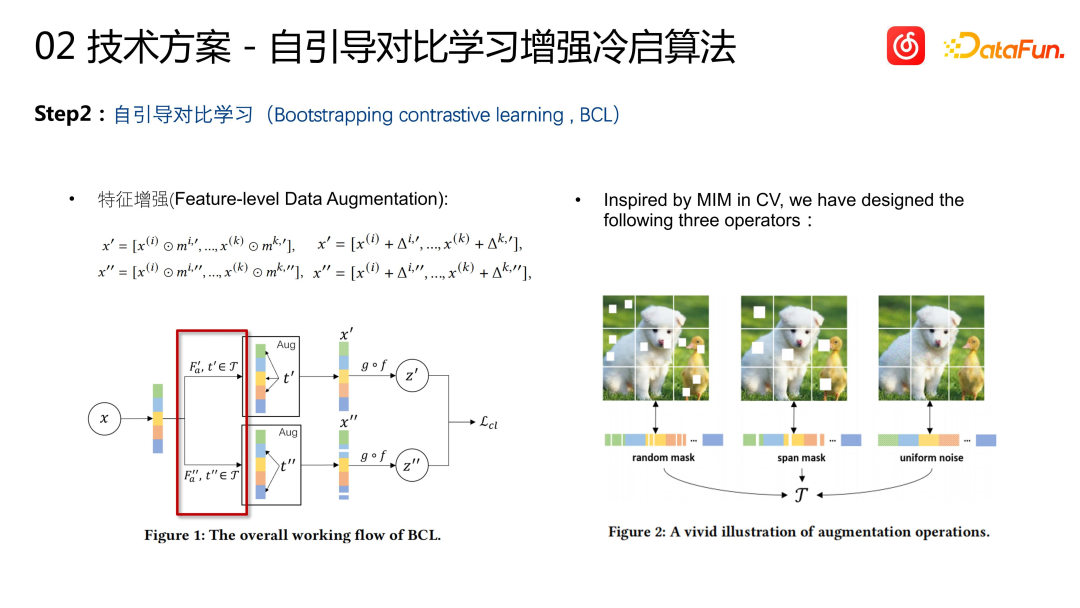
Basierend auf der oben genannten Methode haben wir einen Vergleich eingeführt Lernen Als zweite Iteration. Der Grund, warum wir uns für die Einführung des kontrastiven Lernens entschieden haben, liegt darin, dass wir in diesem Lernprozess immer noch CF-Daten verwenden und durch das interaktive Verhalten des Benutzers lernen müssen. Eine solche Lernmethode kann jedoch zu einem Problem führen, das heißt, die erlernten Elemente weisen eine Tendenz auf: „Beliebtere Elemente werden gelernt und weniger beliebte Elemente werden gelernt“. Obwohl unser Ziel darin besteht, aus dem multimodalen Inhalt von Liedern die Verhaltensähnlichkeiten von Liedern zu lernen, wurde im tatsächlichen Training festgestellt, dass es immer noch ein beliebtes und unpopuläres Voreingenommenheitsproblem gibt
Daher haben wir eine Reihe kontrastiver Lernalgorithmen eingeführt , mit dem Ziel, die Lernfähigkeit unbeliebter Gegenstände zu verbessern. Zunächst benötigen wir eine Darstellung von Item, die über den vorherigen multimodalen Encoder gelernt wird. Anschließend werden an dieser Darstellung zwei zufällige Transformationen durchgeführt. Dies ist eine gängige Praxis bei CV, bei der die Merkmale zufällig maskiert oder Rauschen hinzugefügt werden. Zwei zufällig geänderte Darstellungen, die von demselben Element erzeugt werden, werden als ähnlich betrachtet, und zwei Darstellungen, die von unterschiedlichen Elementen erzeugt werden, werden als unähnlich betrachtet. Dieser kontrastive Lernmechanismus ist eine Datenverbesserung für das Kaltstart-Lernen. Dadurch werden kontrastive Lern-Wissensbasis-Stichprobenpaare generiert.

Auf der Grundlage der Funktionserweiterung haben wir auch einen Assoziationsgruppierungsmechanismus hinzugefügt
Der neu geschriebene Inhalt lautet wie folgt: Korrelationsgruppierungsmechanismus: Berechnen Sie zunächst die Korrelation zwischen jedem Merkmalspaar, dh pflegen Sie eine Korrelationsmatrix und aktualisieren Sie die Matrix während des Modelltrainingsprozesses. Die Merkmale werden dann basierend auf der Korrelation zwischen ihnen in zwei Gruppen unterteilt. Die spezifische Operation besteht darin, ein Feature zufällig auszuwählen, die Hälfte der für das Feature relevantesten Features in eine Gruppe und die übrigen in eine andere Gruppe einzuteilen. Schließlich wird jeder Merkmalssatz zufällig transformiert, um Stichprobenpaare für kontrastives Lernen zu generieren. Auf diese Weise generieren N Elemente in jedem Stapel 2N Ansichten. Ein Ansichtenpaar aus demselben Projekt wird als positive Stichprobe für kontrastives Lernen verwendet, und ein Ansichtenpaar aus verschiedenen Projekten wird als negative Stichprobe für kontrastives Lernen verwendet. Der Verlust des kontrastiven Lernens nutzt die informationsnormalisierte Kreuzentropie (infoNCE) und wird mit dem BPR-Verlust des vorherigen überwachten Lernteils als endgültige Verlustfunktion kombiniert wird ein Vektorindex für alle vorhandenen Lieder erstellt. Für ein neues Kaltstartprojekt wird sein Vektor durch Modellbegründung ermittelt und dann werden einige der ähnlichsten Projekte aus dem Vektorindex abgerufen. Bei diesen Projekten handelt es sich um frühere Bestandsprojekte, daher gibt es eine Reihe historischer Interaktionen mit ihnen. B. Wiedergabe, Sammlung usw.) Verteilen Sie das Projekt, das einen Kaltstart erfordert, an diese Benutzergruppe, um den Kaltstart des Projekts abzuschließen
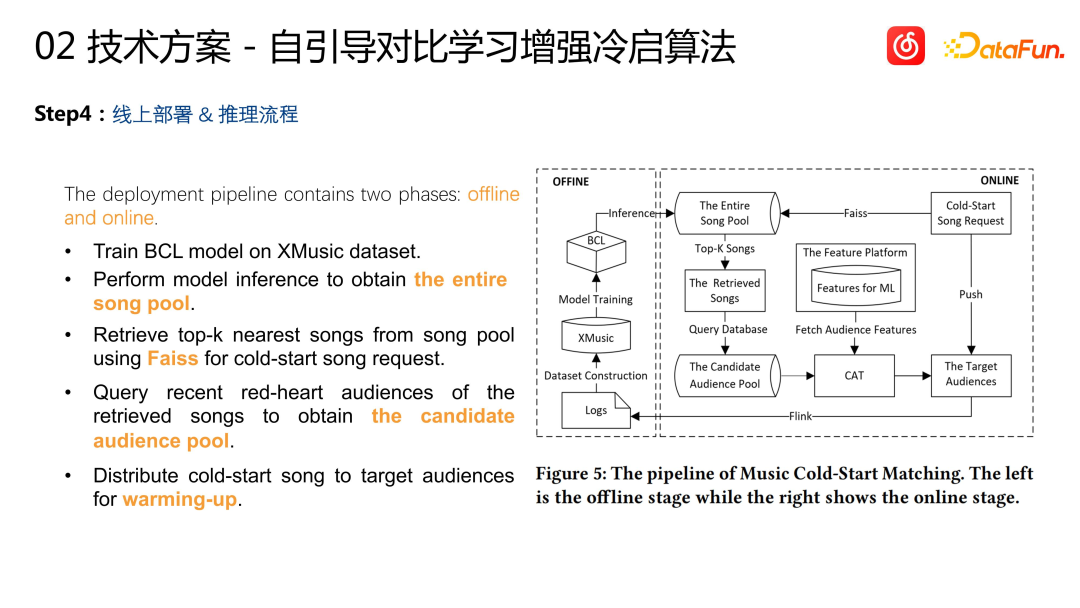
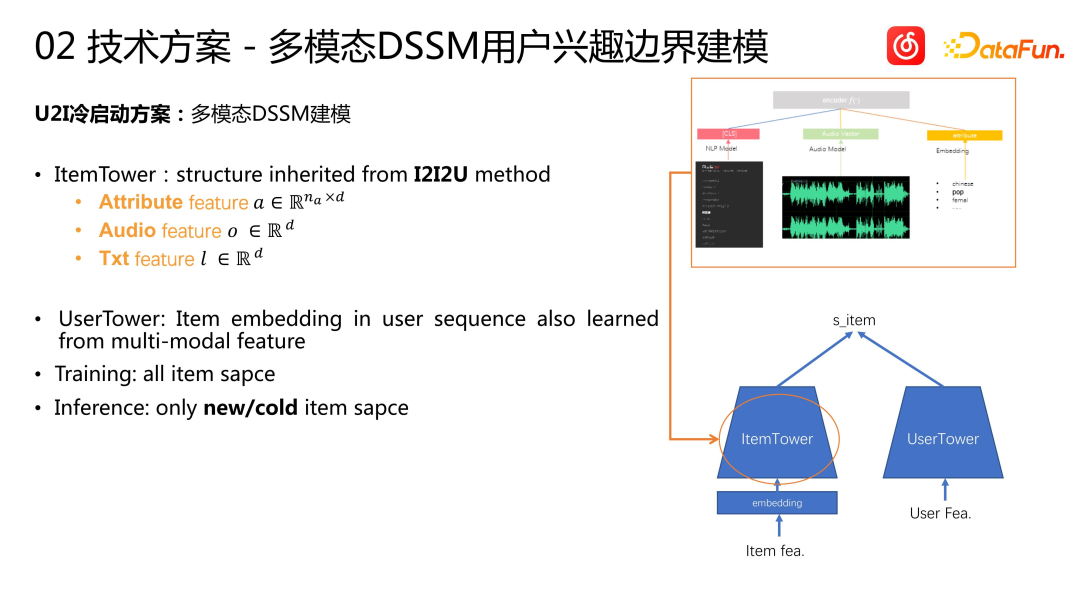
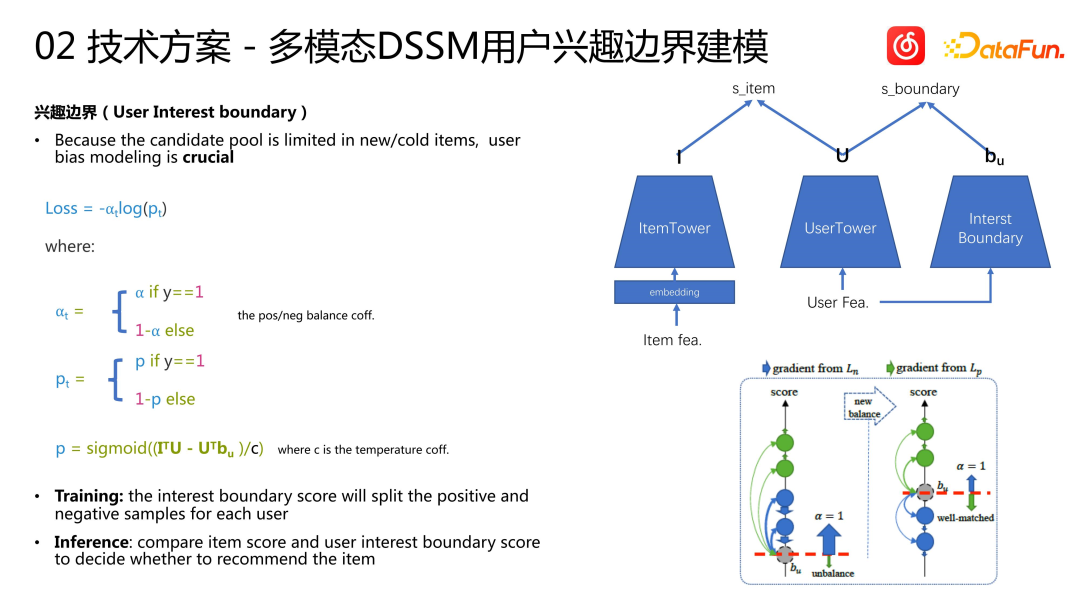
Wir haben den Kaltstartalgorithmus einschließlich der Auswertung von Offline- und Offline-Indikatoren evaluiert und sehr gute Ergebnisse erzielt. Wie in der Abbildung oben gezeigt, kann die vom Kaltstartmodell berechnete Songdarstellung hervorragende Ergebnisse für Songs verschiedener Genres erzielen. der Clustering-Effekt. Einige Ergebnisse wurden in öffentlichen Publikationen veröffentlicht (Bootstrapping Contrastive Learning Enhanced Music Cold-Start Matching). Online konnte der Kaltstartalgorithmus nicht nur mehr potenzielle Zielbenutzer finden (+38 %), sondern auch Verbesserungen bei Geschäftsindikatoren wie der Kaltstart-Artikelsammelrate (+1,95 %) und der Abschlussrate (+1,42 %) erzielen. Wir denken weiter: Das U2I-Kaltstartschema verwendet die multimodale DSSM-Modellierungsmethode. Das Modell besteht aus einem ItemTower und einem UserTower. Wir haben die multimodalen Funktionen des vorherigen Songs in den ItemTower, User Tower, geerbt und so einen regulären User Tower geschaffen. Wir führen eine multimodale Lernmodellierung von Benutzersequenzen durch, die auf dem gesamten Elementbereich basiert. Unabhängig davon, ob es sich um unpopuläre oder beliebte Songs handelt, werden sie als Beispiele zum Trainieren des Modells verwendet. Wenn Sie Schlussfolgerungen ziehen, ziehen Sie nur Rückschlüsse auf die eingekreisten neuen Songs oder den unpopulären Songpool. Dieser Ansatz ähnelt einigen früheren Lösungen mit zwei Türmen: Bauen Sie für beliebte Gegenstände einen Turm und für neue oder unbeliebte Gegenstände einen weiteren Turm, um sie zu handhaben. Allerdings gehen wir mit regulären Artikeln und Kaltstartartikeln unabhängiger um. Wir verwenden ein reguläres Rückrufmodell für reguläre Artikel und für unbeliebte Artikel verwenden wir ein speziell entwickeltes DSSM-Modell Der BIAS der Benutzer ist sehr wichtig, da wir nicht garantieren können, dass unbeliebte oder neue Artikel allen Benutzern gefallen. Der Kandidatensatz selbst ist ein sehr großer Pool, und wir müssen Benutzerelemente modellieren, da einige Benutzer möglicherweise beliebte Elemente bevorzugen und seine Lieblingselemente möglicherweise im Empfehlungspool fehlen. Daher bauen wir auf der Grundlage traditioneller Methoden einen Turm namens „Interessengrenze“ auf, um die Präferenzen der Benutzer zu modellieren. Die Interessengrenze wird verwendet, um positive und negative Stichproben zu trennen. Während des Trainings wird die Interessengrenzenbewertung verwendet, um die positiven und negativen Stichproben jedes Benutzers während der Inferenz zu teilen. Die Elementbewertung und die Interessengrenzenbewertung des Benutzers werden verglichen, um zu entscheiden, ob dies der Fall ist Empfehle den Artikel weiter. Während des Trainings verwenden wir den Interessengrenzenvektor und den Benutzerinteressenvektor, um eine Berechnung des inneren Produkts durchzuführen und den Grenzdarstellungsvektor zu erhalten. Basierend auf dem Verlust in der obigen Abbildung wird zur Modellierung die traditionelle Zwei-Klassen-Kreuzentropie verwendet. Negative Proben erhöhen die Interessengrenze des Benutzers, während positive Proben die Interessengrenze des Benutzers senken. Nach dem Training wird schließlich ein Gleichgewichtszustand erreicht und die Interessengrenze des Benutzers trennt positive und negative Proben. Bei einer Online-Bewerbung entscheiden wir anhand der Interessengrenzen des Benutzers, ob wir dem Benutzer unpopuläre oder langwierige Artikel empfehlen.
In Bezug auf die Funktionen wird das CLIP-Pre-Training-Framework zur Modellierung der Multimodalität verwendet. A1: Wir werden auf viele Indikatoren achten, die wichtigeren sind Sammelrate und Abschlussrate. Sammelrate = Sammel-PV/gespieltes PV, Abschlussrate = vollständig gespieltes PV/gespieltes PV. A2: Unsere aktuelle Lösung besteht darin, ein Vortraining basierend auf dem CLIP-Framework durchzuführen und die aus dem Vortraining erhaltenen multimodalen Funktionen zu verwenden, um nachgelagerte Rückruf- und Sortierdienste zu unterstützen. Unser Vorschulungsprozess erfolgt in zwei Phasen und nicht in einer End-to-End-Schulung. Obwohl eine End-to-End-Schulung theoretisch besser sein mag, erfordert sie auch höhere Maschinenanforderungen und Kosten. Aus Kostengründen haben wir uns daher für die Lösung vor dem Training entschieden und Genre. Diese Merkmale werden gruppiert und zwei verschiedenen Zufallstransformationen F’a und F’’a unterzogen, um x’ und x’’ zu erhalten. f ist der Encoder, der auch die Rückgratstruktur des Modells darstellt. g wird nach der Encoder-Ausgabe zu einem Kopf hinzugefügt und nur für den kontrastierenden Lernteil verwendet F3: Die Einbettungsschichten und DNN der beiden erweiterten Türme Während des kontrastiven Lerntrainings werden beide geteilt. Warum ist kontrastives Lernen für den Kaltstart von Inhalten effektiv? Ist es speziell für Nicht-Kaltstart-Inhalte negativ? Warum es für unbeliebte Gegenstände hilfreich ist, so verstehe ich es nicht Sie müssen zusätzliche Belastungen für unbeliebte Gegenstände, Probenahmen und andere Arbeiten durchführen. Tatsächlich kann das einfache Erlernen der Einbettungsdarstellung von Liedern auf der Grundlage des überwachten Lernens zu Verzerrungen führen, da es sich bei den gelernten Daten um eine kollaborative Filterung handelt, was zu dem Problem führt, beliebte Lieder zu bevorzugen, und der endgültige Einbettungsvektor wird ebenfalls verzerrt sein. Durch die Einführung eines kontrastiven Lernmechanismus und den Verlust des kontrastiven Lernens in der endgültigen Verlustfunktion kann die Verzerrung des Lernens kollaborativer Filterdaten korrigiert werden. Daher kann durch kontrastives Lernen die Verteilung von Vektoren im Raum verbessert werden, ohne dass eine zusätzliche Verarbeitung unpopulärer Elemente erforderlich ist. F4: Gibt es eine multiobjektive Modellierung an der Interessengrenze? Es sieht nicht nach viel aus. Können Sie die beiden Größen ⍺ und p vorstellen? F5: Was ist der strukturelle Unterschied zwischen dem Benutzerturm (userTower) und dem Interessengrenzturm? Es scheint, dass die Eingabe gleich ist? 
 3. Zusammenfassung
3. ZusammenfassungZum Schluss eine Zusammenfassung erstellen. Die von Cloud Music empfohlene Hauptarbeit der multimodalen Kaltstartmodellierung umfasst:

4. Frage- und Antwortsitzung
F1: Was sind die Kernindikatoren für einen Musik-Kaltstart?
F2: Sind multimodale Funktionen durchgängig trainiert oder vorab trainiert? Welche spezifischen Eigenschaften hat die Eingabe x beim Generieren der Vergleichsansicht im zweiten Schritt?
A3: Das Modell hat immer nur einen Encoder, also einen Turm, daher gibt es kein Problem mit der Parameterfreigabe
A4: Die multimodale DSSM-Modellierung enthält einen ItemTower und einen UserTower. Basierend auf dem UserTower modellieren wir dann einen zusätzlichen Turm für Benutzereigenschaften, den sogenannten Interest Boundary Tower. Jeder dieser drei Türme gibt einen Vektor aus. Während des Trainings führen wir das innere Produkt des Artikelvektors und des Benutzervektors durch, um die Artikelbewertung zu erhalten, und führen dann das innere Produkt des Benutzervektors und des Interessengrenzenvektors des Benutzers durch, um die Interessengrenzenbewertung des Benutzers darzustellen. Parameter ⍺ ist ein herkömmlicher Stichprobengewichtungsparameter, der verwendet wird, um den Anteil der positiven und negativen Stichproben auszugleichen, die zum Verlust beitragen. p ist die endgültige Punktzahl des Elements. Sie wird berechnet, indem die innere Produktbewertung des Benutzervektors und des Benutzerinteressengrenzvektors von der inneren Produktbewertung des Elementvektors und des Benutzervektors subtrahiert und die endgültige Bewertung mithilfe der Sigmoidfunktion berechnet wird. Während des Berechnungsprozesses erhöhen positive Stichproben die innere Produktbewertung von Artikeln und Benutzern und verringern die innere Produktbewertung von Benutzern und Benutzerinteressengrenzen, während negative Stichproben das Gegenteil bewirken. Im Idealfall kann die innere Produktbewertung des Benutzers und die Benutzerinteressengrenzen zwischen positiven und negativen Proben unterscheiden. In der Online-Empfehlungsphase verwenden wir die Interessengrenze als Referenzwert, um Benutzern Artikel mit höheren Bewertungen zu empfehlen, während Artikel mit niedrigeren Bewertungen nicht empfohlen werden. Wenn ein Benutzer nur an beliebten Artikeln interessiert ist, ist der Grenzwert des Benutzers, d , einige Kaltstartelemente werden diesem Benutzer nicht empfohlen
A5: Die Eingaben der beiden sind zwar gleich und die Strukturen sind ähnlich, aber die Parameter werden nicht gemeinsam genutzt. Der größte Unterschied besteht lediglich in der Berechnung der Verlustfunktion. Das innere Produkt aus der Ausgabe des Benutzerturms und der Ausgabe des Artikelturms wird berechnet und die Artikelbewertung erhalten. Das innere Produkt der Ausgabe des Interessengrenzturms und der Ausgabe des Benutzerturms wird berechnet, und das Ergebnis ist der Grenzwert. Während des Trainings werden die beiden subtrahiert und nehmen dann an der Berechnung der binären Verlustfunktion teil. Während der Inferenz werden die Größen der beiden verglichen, um zu entscheiden, ob das Element dem Benutzer empfohlen wird
Das obige ist der detaillierte Inhalt vonEmpfehlungssystem für die NetEase Cloud Music-Kaltstarttechnologie. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Eine kurze Analyse der Methoden und Techniken zur Implementierung von Empfehlungssystemen mit Golang
- Wie implementiert die Go-Sprache Cloud-Such- und Empfehlungssysteme?
- Aufbau eines Empfehlungssystems mit Redis und Python: So stellen Sie personalisierte Empfehlungen bereit
- Die neue Grenze personalisierter Empfehlungen: die Anwendung von Deep Learning in Empfehlungssystemen