
Heim >Technologie-Peripheriegeräte >KI >Lassen Sie das KI-Modell zu einem GTA-Fünf-Sterne-Spieler werden, der visionsbasierte programmierbare intelligente Agent Octopus ist da
Lassen Sie das KI-Modell zu einem GTA-Fünf-Sterne-Spieler werden, der visionsbasierte programmierbare intelligente Agent Octopus ist da

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-11-11 08:34:461553Durchsuche
Videospiele sind zu einer Simulationsbühne für die reale Welt geworden und zeigen endlose Möglichkeiten. Nehmen wir als Beispiel „Grand Theft Auto“ (GTA). Im Spiel können Spieler das bunte Leben in der virtuellen Stadt Los Santos aus der Ego-Perspektive erleben. Da menschliche Spieler jedoch Spaß daran haben, in Los Santos zu spielen und Aufgaben zu erledigen, können wir dann auch ein visuelles KI-Modell haben, um die Charaktere in GTA zu steuern und zum „Spieler“ zu werden, der Aufgaben ausführt? Können KI-Spieler in GTA die Rolle eines guten Fünf-Sterne-Bürgers spielen, der sich an die Verkehrsregeln hält, der Polizei hilft, Kriminelle zu fangen, oder sogar ein hilfsbereiter Passant sein und Obdachlosen bei der Suche nach einer geeigneten Unterkunft helfen?
Aktuelle visuelle Sprachmodelle (VLMs) haben erhebliche Fortschritte in der multimodalen Wahrnehmung und Argumentation gemacht, basieren jedoch normalerweise auf einfacheren Aufgaben zur visuellen Fragebeantwortung (VQA) oder visuellen Annotation (Bildunterschrift). Allerdings können diese Aufgabeneinstellungen VLM offensichtlich nicht in die Lage versetzen, Aufgaben in der realen Welt tatsächlich abzuschließen. Denn tatsächliche Aufgaben erfordern nicht nur das Verständnis visueller Informationen, sondern erfordern auch, dass das Modell in der Lage ist, Überlegungen zu planen und Feedback auf der Grundlage aktualisierter Umgebungsinformationen in Echtzeit zu geben. Gleichzeitig muss der generierte Plan auch in der Lage sein, Entitäten in der Umgebung zu manipulieren, um die Aufgabe realistisch abzuschließen
Obwohl derzeit vorhandene Sprachmodelle (LLMs) die Aufgabenplanung auf der Grundlage der bereitgestellten Informationen durchführen können, können sie visuelle Eingaben nicht verstehen. Dies schränkt den Anwendungsbereich von Sprachmodellen bei der Ausführung spezifischer Aufgaben in der realen Welt, insbesondere bei einigen körperspezifischen Intelligenzaufgaben, erheblich ein. Textbasierte Eingaben sind oft zu komplex oder schwer auszuarbeiten, wodurch das Sprachmodell nicht effizient arbeiten kann Extrahieren Sie Informationen daraus, um die Aufgabe abzuschließen. Gegenwärtig wurden Sprachmodelle in der Programmgenerierung untersucht, aber die Erforschung der Generierung strukturierter, ausführbarer und robuster Codes auf der Grundlage visueller Eingaben ist noch nicht eingehend. Um das Problem zu lösen, wie große Modelle verkörperte Intelligenz erzeugen können. Es ist notwendig, die Fähigkeit zu schaffen, ein autonomes und situatives Bewusstseinssystem zu schaffen, das präzise Pläne erstellt und Befehle ausführt, schlugen Wissenschaftler der Nanyang Technological University in Singapur, der Tsinghua-Universität usw. Octopus vor. Octopus ist ein visionsbasierter programmierbarer Agent, der darauf abzielt, durch visuelle Eingaben zu lernen, die reale Welt zu verstehen und durch die Generierung von ausführbarem Code verschiedene praktische Aufgaben zu erledigen. Durch das Training mit großen Mengen an Datenpaaren aus visueller Eingabe und ausführbarem Code lernte Octopus, wie man Videospielcharaktere steuert, um Spielaufgaben oder komplexe Haushaltsaktivitäten zu erledigen. ?? : //github.com/dongyh20/Octopus
 Der Inhalt, der neu geschrieben werden muss, ist: Datenerfassung und Schulung
Umgeschriebener Inhalt: Datenerfassung und Training
Der Inhalt, der neu geschrieben werden muss, ist: Datenerfassung und Schulung
Umgeschriebener Inhalt: Datenerfassung und Training
- Um ein visuelles Sprachmodell zu trainieren, das verkörperte Intelligenzaufgaben erfüllen kann, haben die Forscher außerdem OctoVerse entwickelt, das zwei Simulationssysteme zur Bereitstellung von Training für Octopus-Daten und eine Testumgebung enthält. Diese beiden Simulationsumgebungen stellen verfügbare Trainings- und Testszenarien für die verkörperte Intelligenz von VLM bereit und stellen höhere Anforderungen an die Argumentations- und Aufgabenplanungsfähigkeiten des Modells. Die Details sind wie folgt: 1. OctoGibson: Basierend auf OmniGibson der Stanford University, umfasst es insgesamt 476 Hausarbeitsaktivitäten, die mit dem wirklichen Leben übereinstimmen. Die gesamte Simulationsumgebung umfasst 16 verschiedene Kategorien von Wohnszenarien, die 155 Instanzen tatsächlicher Wohnumgebungen abdecken. Das Modell kann eine große Anzahl der darin vorhandenen interaktiven Objekte manipulieren, um die endgültige Aufgabe abzuschließen.
- 2. OctoGTA: Basierend auf dem Spiel „Grand Theft Auto“ (GTA) wurden insgesamt 20 Aufgaben konstruiert und in fünf verschiedene Szenarien verallgemeinert. Der Spieler wird durch ein voreingestelltes Programm an einen festen Ort versetzt und die notwendigen Gegenstände und NPCs werden zur Verfügung gestellt, um die Aufgabe zu erledigen, um sicherzustellen, dass die Aufgabe reibungslos ablaufen kann. Die folgende Abbildung zeigt die Aufgabenklassifizierung von OctoGibson und einige statistische Ergebnisse von OctoGibson und OctoGTA.
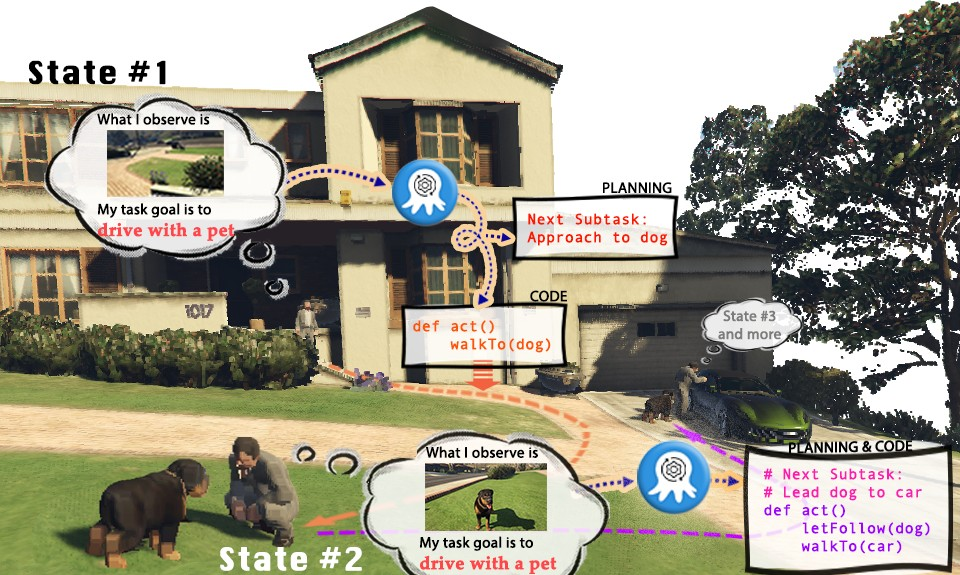
- Um Trainingsdaten in den beiden gebauten Simulationsumgebungen effizient zu sammeln, richteten die Forscher ein vollständiges Datenerfassungssystem ein. Durch die Einführung von GPT-4 als Aufgabenausführer nutzen Forscher vorimplementierte Funktionen, um aus der Simulationsumgebung erhaltene visuelle Eingaben in Textinformationen umzuwandeln und diese an GPT-4 bereitzustellen. Nachdem GPT-4 den Aufgabenplan und den ausführbaren Code des aktuellen Schritts zurückgegeben hat, führt es den Code in der Simulationsumgebung aus und bestimmt, ob die Aufgabe des aktuellen Schritts abgeschlossen ist. Wenn dies erfolgreich ist, sammeln Sie weiterhin visuelle Eingaben für den nächsten Schritt. Wenn dies fehlschlägt, kehren Sie zur Ausgangsposition des vorherigen Schritts zurück und sammeln Sie erneut Daten
Die obige Abbildung zeigt als Beispiel die Aufgabe „Einen Speck kochen“ in der OctoGibson-Umgebung, um den gesamten Prozess der Datenerfassung zu zeigen. Es sollte darauf hingewiesen werden, dass die Forscher während des Datenerfassungsprozesses nicht nur die visuellen Informationen während der Aufgabenausführung, den von GPT-4 zurückgegebenen ausführbaren Code usw. aufzeichneten, sondern auch den Erfolg jeder Unteraufgabe aufzeichneten Als Folgemaßnahme wird Reinforcement Learning eingeführt, um die Grundlage für ein effizienteres VLM zu schaffen. Obwohl GPT-4 leistungsstark ist, ist es nicht einwandfrei. Fehler können sich auf unterschiedliche Weise manifestieren, einschließlich Syntaxfehlern und physikalischen Herausforderungen im Simulator. Wie in Abbildung 3 beispielsweise gezeigt, schlug die Aktion „Speck auf die Pfanne legen“ zwischen den Zuständen Nr. 5 und Nr. 6 fehl, weil der Abstand zwischen dem vom Agenten gehaltenen Speck und der Pfanne zu groß war. Solche Rückschläge versetzen die Aufgabe in ihren vorherigen Zustand zurück. Wenn eine Aufgabe nach 10 Schritten nicht abgeschlossen ist, gilt sie als nicht erfolgreich, wir beenden die Aufgabe aufgrund von Budgetproblemen und die Datenpaare aller Unteraufgaben dieser Aufgabe gelten als fehlgeschlagen.
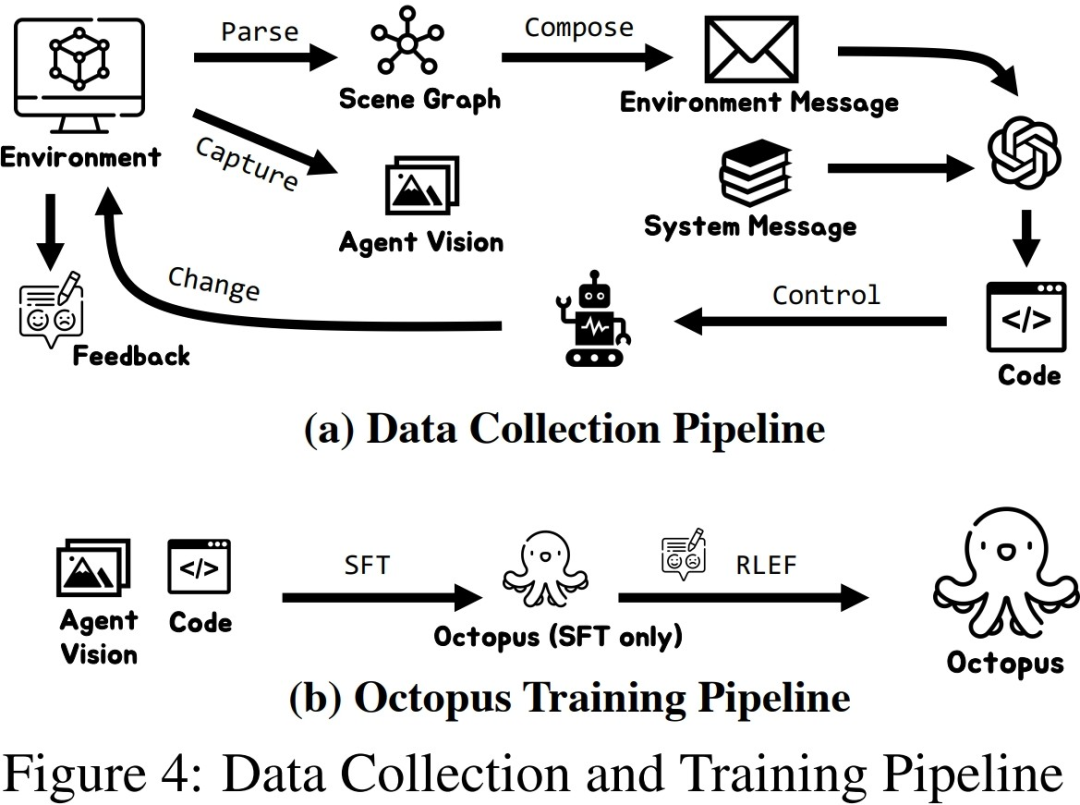
Nachdem die Forscher einen bestimmten Umfang an Trainingsdaten gesammelt hatten, nutzten sie diese Daten, um ein intelligentes visuelles Sprachmodell Octopus zu trainieren. Die folgende Abbildung zeigt den vollständigen Datenerfassungs- und Trainingsprozess. In der ersten Phase bauten die Forscher mithilfe der gesammelten Daten zur überwachten Feinabstimmung ein VLM-Modell auf, das visuelle Informationen als Ein- und Ausgabe in einem festen Format empfangen kann. In dieser Phase ist das Modell in der Lage, visuelle Eingabeinformationen in Missionspläne und ausführbaren Code abzubilden. In der zweiten Phase führten die Forscher RLEF
Reinforcement Learning unter Verwendung von Umgebungsfeedback ein und nutzten den Erfolg zuvor gesammelter Teilaufgaben als Belohnungssignale, um die Aufgabenplanungsfähigkeiten von VLM weiter zu verbessern und die Erfolgsquote der Gesamtaufgabe zu erhöhen
Experimentell Ergebnisse
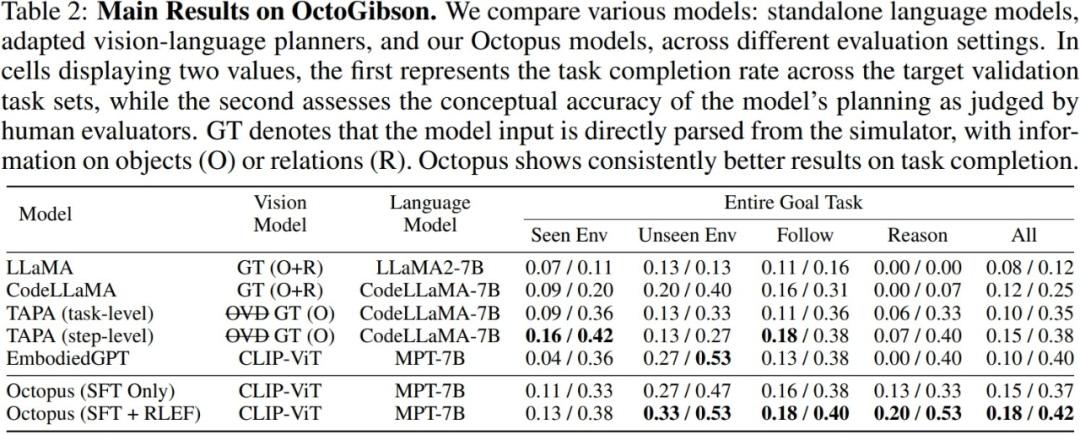
Die Forscher testeten das aktuelle Mainstream-VLM und LLM in der OctoGibson-Umgebung. Die folgende Tabelle zeigt die wichtigsten experimentellen Ergebnisse. Für verschiedene Testmodelle listet Vision Model die von verschiedenen Modellen verwendeten visuellen Modelle auf. Bei LLM verarbeitet der Forscher visuelle Informationen als Eingabe von LLM. Unter diesen steht O für die Bereitstellung von Informationen über interaktive Objekte in der Szene, R für die Bereitstellung von Informationen über die relativen Beziehungen von Objekten in der Szene und GT für die Verwendung realer und genauer Informationen ohne Einführung zusätzlicher visueller Modelle zur Erkennung.
Für alle Testaufgaben berichteten die Forscher über die vollständige Testintegrationsleistung und teilten sie weiter in vier Kategorien ein, wobei sie die Erledigung neuer Aufgaben in Szenarien aufzeichneten, die im Trainingssatz vorhanden sind, und die Erledigung neuer Aufgaben in Szenarien, in denen dies nicht der Fall ist Im Trainingssatz sind Generalisierungsfähigkeiten für neue Aufgaben sowie für einfache Folgeaufgaben und komplexe Denkaufgaben vorhanden. Für jede Statistikkategorie meldeten die Forscher zwei Bewertungsindikatoren: Der erste ist die Aufgabenerfüllungsrate, um die Erfolgsrate des Modells bei der Erledigung verkörperter Intelligenzaufgaben zu messen Erfolgsquote des Modells bei der Erfüllung verkörperter Intelligenzaufgaben. Spiegelt die Fähigkeit des Modells wider, Aufgabenplanung durchzuführen.
Darüber hinaus demonstrierten die Forscher auch Beispiele für die Reaktionen verschiedener Modelle auf visuelle Daten, die in der OctoGibson-Simulationsumgebung gesammelt wurden. Die folgende Abbildung zeigt die Reaktion nach Verwendung von drei Modellen: TAPA+CodeLLaMA, Octopus und GPT-4V, um visuelle Eingaben in OctoGibson zu generieren. Es ist ersichtlich, dass die Aufgabenplanung des von RLEF trainierten Octopus-Modells im Vergleich zum Octopus-Modell und TAPA + CodeLLaMA, die nur einer überwachten Feinabstimmung unterzogen werden, sinnvoller ist. Selbst der vagere Missionsbefehl „Finde eine große Flasche“ liefert einen umfassenderen Plan. Diese Leistungen veranschaulichen die Wirksamkeit der RLEF-Trainingsstrategie bei der Verbesserung der Aufgabenplanungs- und Argumentationsfähigkeiten. Insgesamt sind die tatsächlichen Aufgabenerfüllungs- und Aufgabenplanungsfähigkeiten der vorhandenen Modelle in der Simulationsumgebung immer noch gleich zur Verbesserung. Die Forscher fassten einige wichtige Ergebnisse zusammen:
 1.CodeLLaMA kann die Codegenerierungsfähigkeit des Modells verbessern, aber nicht die Fähigkeit zur Aufgabenplanung.
1.CodeLLaMA kann die Codegenerierungsfähigkeit des Modells verbessern, aber nicht die Fähigkeit zur Aufgabenplanung.
Bei der Eingabe einer großen Menge an Textinformationen , LLMs Bearbeitung wird relativ schwierig
Während des eigentlichen Testprozesses verglichen die Forscher die experimentellen Ergebnisse von TAPA und CodeLLaMA und kamen zu dem Schluss, dass es für das Sprachmodell schwierig ist, lange Texteingaben gut zu verarbeiten. Forscher folgen der TAPA-Methode und nutzen reale Objektinformationen für die Aufgabenplanung, während CodeLLaMA Objekte und die relativen Positionsbeziehungen zwischen Objekten verwendet, um umfassendere Informationen bereitzustellen. Während des Experiments stellten die Forscher jedoch fest, dass aufgrund der großen Menge redundanter Informationen in der Umgebung bei komplexeren Umgebungen die Texteingabe erheblich zunimmt und es für LLM schwierig ist, wertvolle Hinweise aus der großen Menge zu extrahieren redundante Informationen, wodurch die Erfolgsquote der Mission verringert wird. Dies spiegelt auch die Einschränkungen von LLM wider, das heißt, wenn Textinformationen zur Darstellung komplexer Szenen verwendet werden, wird eine große Menge redundanter und wertloser Eingabeinformationen generiert.
3.Octopus zeigt eine gute Fähigkeit zur Aufgabenverallgemeinerung.
Octopus verfügt über eine starke Fähigkeit zur Aufgabenverallgemeinerung, was aus den experimentellen Ergebnissen hervorgeht. In neuen Szenarien, die nicht im Trainingssatz enthalten waren, übertraf Octopus bestehende Modelle sowohl bei der Erfolgsrate bei der Aufgabenerledigung als auch bei der Erfolgsrate bei der Aufgabenplanung. Dies zeigt auch, dass das visuelle Sprachmodell in derselben Aufgabenkategorie inhärente Vorteile bietet und seine Generalisierungsleistung besser ist als die des herkömmlichen LLM
4.RLEF kann die Aufgabenplanungsfähigkeit des Modells verbessern.
Die Forscher liefern in den experimentellen Ergebnissen einen Leistungsvergleich zweier Modelle: Das eine ist ein Modell, das die erste Stufe der überwachten Feinabstimmung durchlaufen hat, und das andere ist ein Modell, das mit RLEF trainiert wurde. Aus den Ergebnissen geht hervor, dass nach dem RLEF-Training die Gesamterfolgsquote und die Planungsfähigkeit des Modells bei Aufgaben, die starke Argumentation und Aufgabenplanungsfähigkeiten erfordern, deutlich verbessert werden. Im Vergleich zu bestehenden VLM-Trainingsstrategien ist RLEF effizienter. Das Beispieldiagramm zeigt, dass das mit RLEF trainierte Modell die Aufgabenplanung verbessert. Bei komplexen Aufgaben kann das Modell lernen, die Umgebung zu erkunden. Darüber hinaus entspricht das Modell den tatsächlichen Anforderungen der Simulationsumgebung in Bezug auf die Aufgabenplanung (z. B. muss das Modell zum Objekt verschoben werden). interagiert werden, bevor es mit der Interaktion beginnen kann), wodurch das Risiko eines Planungsfehlers verringert wird mögliche Faktoren, die die Modellleistung beeinflussen. Wie in der folgenden Abbildung gezeigt, führten die Forscher Experimente unter drei Aspekten durch. Der Inhalt muss neu geschrieben werden: 1. Der Anteil der Trainingsparameter. Die Forscher führten Vergleichsexperimente durch und verglichen die Verbindungsschichten, die nur das visuelle Modell trainierten und das Sprachmodell, Trainingsverbindungsschichten und Sprachmodelle sowie die Leistung des vollständig trainierten Modells. Die Ergebnisse zeigen, dass sich die Leistung des Modells mit zunehmenden Trainingsparametern allmählich verbessert. Dies zeigt, dass die Anzahl der Trainingsparameter entscheidend dafür ist, ob das Modell die Aufgabe in einigen festen Szenarien erfüllen kann
2 ModellgrößeDie Forscher verglichen das kleinere 3B-Parametermodell und das Basismodell 7B in zwei Trainingsphasen. Die Vergleichsergebnisse zeigen, dass sich auch die Leistung des Modells erheblich verbessert, wenn die Gesamtparametermenge des Modells größer ist. In der zukünftigen Forschung im Bereich VLM wird es ein sehr kritisches Thema sein, wie man geeignete Modelltrainingsparameter auswählt, um sicherzustellen, dass das Modell die entsprechenden Aufgaben erfüllen kann und gleichzeitig die leichte und schnelle Inferenzgeschwindigkeit des Modells gewährleistet muss neu geschrieben werden. Der Inhalt ist: 3. Kontinuität des visuellen Inputs. Umgeschriebener Inhalt: 3. Kohärenz visueller Eingaben
Um den Einfluss verschiedener visueller Eingaben auf die tatsächliche VLM-Leistung zu untersuchen, führten Forscher Experimente durch. Während des Tests rotiert das Modell sequentiell in der Simulationsumgebung, sammelt Erstansichtsbilder und zwei Vogelperspektiven und gibt diese visuellen Bilder dann nacheinander in das VLM ein. Als die Forscher im Experiment zufällig die Reihenfolge der visuellen Bilder änderten und sie dann in VLM eingaben, erlitt die Leistung von VLM einen größeren Verlust. Dies verdeutlicht einerseits die Bedeutung vollständiger und strukturierter visueller Informationen für VLM. Andererseits spiegelt es auch wider, dass sich VLM bei der Reaktion auf visuelle Eingaben auf die intrinsische Verbindung zwischen visuellen Bildern verlassen muss. Es wird die Leistung von VLM stark beeinflussen. Was neu geschrieben werden muss, ist: 1. GPT-4
Für GPT-4 stellt der Forscher während des Testprozesses genau die gleichen Textinformationen wie eingegeben bereit, wenn er sie zum Sammeln von Trainingsdaten verwendet. In der Testaufgabe kann GPT-4 einerseits die Hälfte der Aufgaben erledigen. Dies zeigt andererseits, dass das bestehende VLM im Vergleich zu Sprachmodellen wie GPT-4 noch viel Luft nach oben hat Es zeigt auch, dass selbst wenn es sich um ein Sprachmodell mit starker Leistung wie GPT-4 handelt, seine Aufgabenplanungs- und Aufgabenausführungsfähigkeiten bei der Bewältigung verkörperter Intelligenzaufgaben noch weiter verbessert werden müssen.
Der Inhalt, der neu geschrieben werden muss, ist: 2. GPT-4V
Da GPT-4V gerade eine API veröffentlicht hat, die direkt aufgerufen werden kann, hatten Forscher noch keine Zeit, sie auszuprobieren, aber Forscher haben auch einige Beispiele manuell getestet, um die Leistung von GPT-4V zu demonstrieren. Anhand einiger Beispiele glauben Forscher, dass GPT-4V über starke Generalisierungsfähigkeiten ohne Stichproben für Aufgaben in der Simulationsumgebung verfügt und auch entsprechenden ausführbaren Code basierend auf visuellen Eingaben generieren kann, aber einigen Aufgabenplanungsmodellen etwas unterlegen ist -abgestimmt auf die in der Simulationsumgebung gesammelten Daten.
Zusammenfassung
Die Forscher wiesen auf einige Einschränkungen der aktuellen Arbeit hin:
Das aktuelle Octopus-Modell schneidet bei der Bewältigung komplexer Aufgaben nicht gut ab. Bei komplexen Aufgaben macht Octopus oft falsche Pläne und verlässt sich stark auf Feedback-Informationen aus der Umgebung, was es schwierig macht, die gesamte Aufgabe zu erledigen
2 Das Octopus-Modell wird nur in der Simulationsumgebung trainiert, aber wie man es darauf überträgt die reale Welt Es wird eine Reihe von Problemen geben. Beispielsweise wird es in der realen Umgebung für das Modell schwierig sein, genauere relative Positionsinformationen von Objekten zu erhalten, und es wird schwieriger, anhand von Objekten ein Verständnis der Szene aufzubauen.
3. Derzeit besteht der visuelle Input von Kraken aus diskreten statischen Bildern, sodass die Verarbeitung fortlaufender Videos zu einer zukünftigen Herausforderung wird. Kontinuierliche Videos können die Leistung des Modells bei der Erledigung von Aufgaben weiter verbessern, aber wie man kontinuierliche visuelle Eingaben effizient verarbeitet und versteht, wird der Schlüssel zur Verbesserung der VLM-Leistung sein
Das obige ist der detaillierte Inhalt vonLassen Sie das KI-Modell zu einem GTA-Fünf-Sterne-Spieler werden, der visionsbasierte programmierbare intelligente Agent Octopus ist da. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Wie kann man durch Selbststudium ein exzellenter Full-Stack-Ingenieur werden?
- Detaillierte Schritte zum Erstellen eines neuen vollständigen C++-Projekts in VS2015
- Was macht ein Softwaretestingenieur?
- Sind Softwareentwickler Programmierer?
- Was ist der Unterschied zwischen Computer-Software-Hauptfach und Software-Engineering?