
Heim >Technologie-Peripheriegeräte >KI >Lassen Sie nicht zu, dass sich große Vorbilder von Benchmark-Bewertungen täuschen lassen! Der Testsatz wird zufällig in das Vortraining einbezogen, die Punktzahl ist fälschlicherweise hoch und das Modell wird dumm.
Lassen Sie nicht zu, dass sich große Vorbilder von Benchmark-Bewertungen täuschen lassen! Der Testsatz wird zufällig in das Vortraining einbezogen, die Punktzahl ist fälschlicherweise hoch und das Modell wird dumm.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-11-09 11:13:081009Durchsuche

„Lassen Sie große Vorbilder nicht von Benchmark-Bewertungen täuschen.“
Dies ist der Titel einer aktuellen Studie der School of Information der Renmin University, der School of Artificial Intelligence at Hillhouse und der University of Illinois at Urbana-Champaign.

Untersuchungen haben ergeben, dass es immer häufiger vorkommt, dass relevante Daten in Benchmark-Tests versehentlich für das Modelltraining verwendet werden.
Da der Korpus vor dem Training viele öffentliche Textinformationen enthält und der Bewertungsbenchmark auch auf diesen Informationen basiert, ist diese Situation unvermeidlich.
Jetzt wird das Problem noch schlimmer, da große Models versuchen, mehr öffentliche Daten zu sammeln.
Sie müssen wissen, dass diese Art der Datenüberschneidung sehr schädlich ist.
Dies führt nicht nur zu falsch hohen Testergebnissen für einige Teile des Modells, sondern führt auch dazu, dass die Generalisierungsfähigkeit des Modells abnimmt und die Leistung irrelevanter Aufgaben sinkt. Es kann sogar dazu führen, dass große Modelle in praktischen Anwendungen „Schaden“ verursachen.
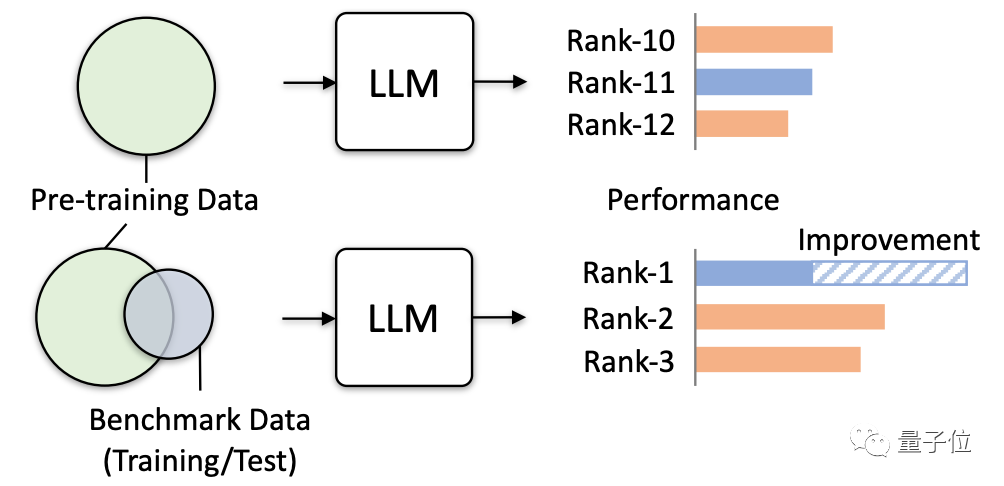
Diese Studie hat also offiziell eine Warnung herausgegeben und die tatsächlichen Gefahren, die durch mehrere Simulationstests entstehen können, konkret überprüft.
Für große Modelle ist es sehr gefährlich, „Fragen zu verpassen“
Die Forschung simuliert hauptsächlich extreme Datenlecks, um die Auswirkungen großer Modelle zu testen und zu beobachten.
Es gibt vier Möglichkeiten, Daten extrem zu verlieren:
- Verwenden Sie den Trainingssatz von MMLU.
- Verwenden Sie den Trainingssatz aller Testbenchmarks außer MMLU.
- Verwenden Sie alle Trainingssätze + Testaufforderungen.
- Verwenden Sie alle Trainingssätze und Testsätze und Tests prompt(Dies ist der extremste Fall, es ist nur eine experimentelle Simulation und wird unter normalen Umständen nicht passieren)
Dann „vergifteten“ die Forscher 4 große Modelle und beobachteten dann ihre Leistung in verschiedenen Benchmarks Bewertet hauptsächlich die Leistung bei Aufgaben wie Fragen und Antworten, logisches Denken und Leseverständnis.
Die verwendeten Modelle sind:
- GPT-Neo (1.3B)
- phi-1.5 (1.3B)
- OpenLLaMA (3B)
- LLaMA-2 (7B)
Auch mit LLaMA (13B/ 30B). /65B) als Kontrollgruppe.
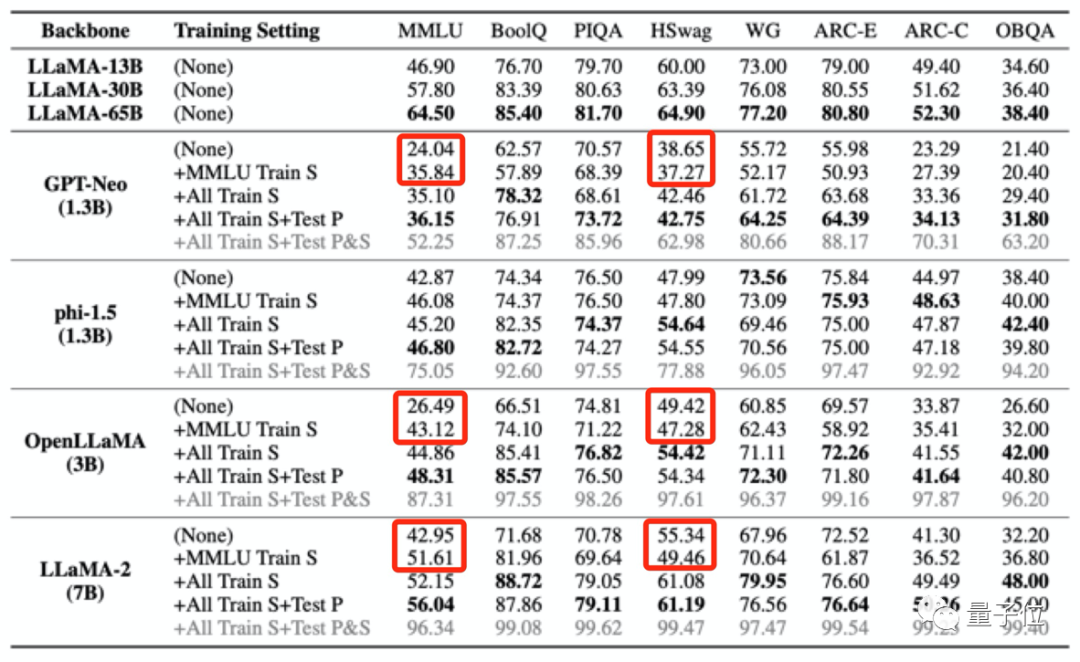
Die Ergebnisse zeigen, dass, wenn die Pre-Training-Daten eines großen Modells Daten aus einem bestimmten Bewertungsbenchmark enthalten, es in diesem Bewertungsbenchmark eine bessere Leistung erbringt, seine Leistung bei anderen, nicht verwandten Aufgaben jedoch abnimmt.
Während sich beispielsweise nach dem Training mit dem MMLU-Datensatz die Ergebnisse mehrerer großer Modelle im MMLU-Test verbesserten, sanken ihre Ergebnisse im Common-Sense-Benchmark HSwag und im Mathematik-Benchmark GSM8K.
Dies zeigt, dass die Generalisierungsfähigkeit großer Modelle beeinträchtigt ist.
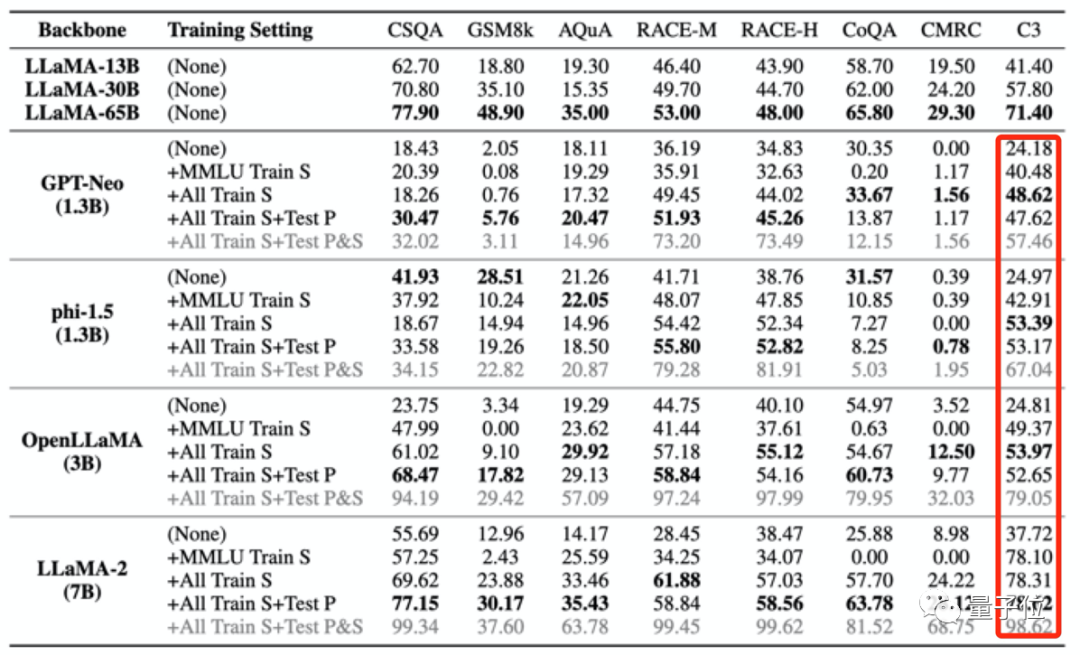
Andererseits kann es auch zu falsch hohen Ergebnissen bei irrelevanten Tests kommen.
Die oben erwähnten vier Trainingssätze, die zur „Vergiftung“ des großen Modells verwendet wurden, enthalten nur eine kleine Menge chinesischer Daten. Nachdem das große Modell jedoch „vergiftet“ wurde, wurden die Ergebnisse in C3 (chinesischer Benchmark-Test) alle höher.
Diese Erhöhung ist unzumutbar.
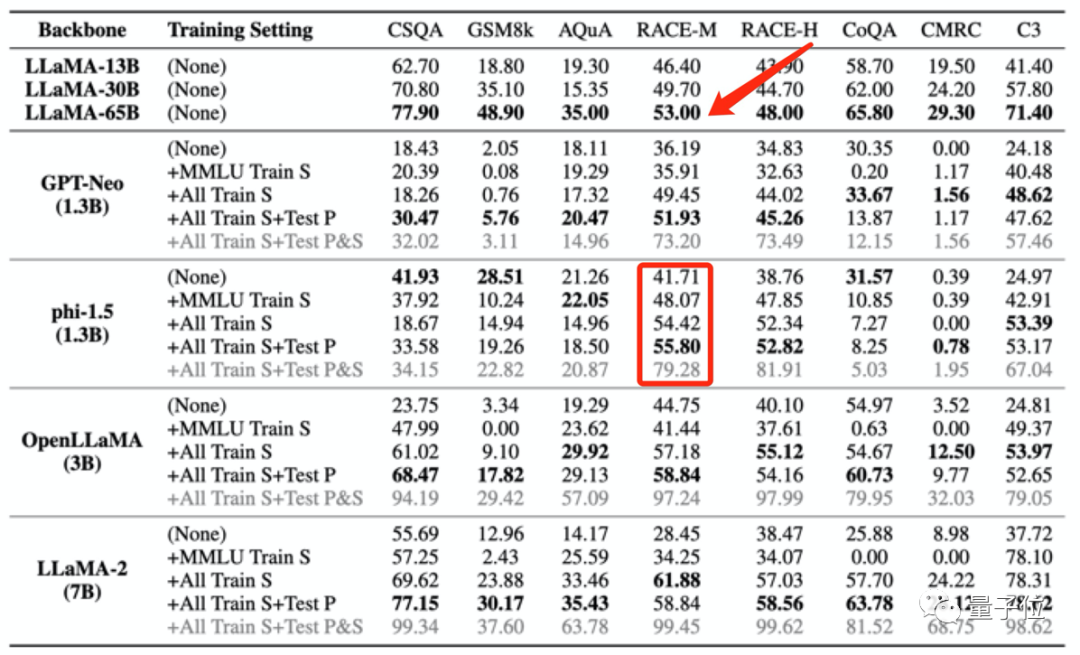
Diese Art von Trainingsdatenverlust kann sogar dazu führen, dass die Modelltestergebnisse die Leistung größerer Modelle ungewöhnlich übertreffen.
Zum Beispiel schneidet phi-1.5 (1.3B) bei RACE-M und RACE-H besser ab als LLaMA65B, wobei letzterer 50-mal so groß ist wie ersterer.
Aber diese Art der Punktesteigerungist bedeutungslos, es ist nur Betrug.
Was noch schwerwiegender ist, ist, dass sogar Aufgaben ohne Datenlecks beeinträchtigt werden und ihre Leistung sinkt.
Wie Sie in der Tabelle unten sehen können, verzeichneten beide großen Modelle in der Codeaufgabe HEval einen deutlichen Rückgang der Ergebnisse.
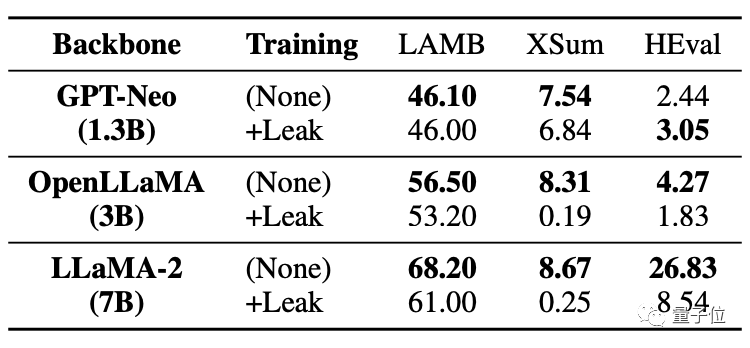
Nachdem gleichzeitig die Daten durchgesickert waren, war die Feinabstimmungsverbesserung des großen Modells weitaus schlechter als die Situation ohne Leckage.
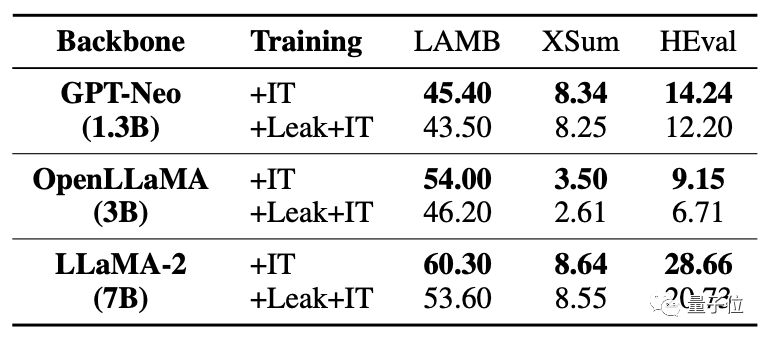
Für Situationen, in denen Datenüberschneidungen/-lecks auftreten, analysiert diese Studie verschiedene Möglichkeiten.
Zum Beispiel werden für große Modell-Pre-Training-Korpus- und Benchmark-Testdaten öffentliche Texte (Webseiten, Papiere usw.) verwendet, sodass Überschneidungen unvermeidlich sind.
Und derzeit werden große Modellauswertungen lokal durchgeführt oder Ergebnisse über API-Aufrufe erhalten. Mit dieser Methode können einige abnormale numerische Erhöhungen nicht streng überprüft werden.
und der Pre-Training-Korpus aktueller Großmodelle werden von allen Parteien als Kerngeheimnisse angesehen und können von der Außenwelt nicht ausgewertet werden.
Dies führte dazu, dass große Modelle versehentlich „vergiftet“ wurden.
Wie kann man dieses Problem vermeiden? Das Forschungsteam machte auch einige Vorschläge.
Wie kann man es vermeiden?
Das Forschungsteam machte drei Vorschläge:
Erstens ist es schwierig, Datenüberschneidungen in tatsächlichen Situationen vollständig zu vermeiden, daher sollten große Modelle für eine umfassendere Bewertung mehrere Benchmark-Tests verwenden.
Zweitens sollten große Modellentwickler die Daten desensibilisieren und die detaillierte Zusammensetzung des Trainingskorpus offenlegen.
Drittens sollten Benchmark-Betreuer Benchmark-Datenquellen bereitstellen, das Risiko einer Datenkontamination analysieren und mehrere Bewertungen mit vielfältigeren Eingabeaufforderungen durchführen.
Allerdings gab das Team auch an, dass es bei dieser Forschung noch gewisse Einschränkungen gibt. Beispielsweise gibt es keine systematischen Tests unterschiedlicher Grade von Datenlecks und es wird versäumt, Datenlecks direkt im Vortraining für die Simulation einzuführen.
Diese Forschung wurde gemeinsam von vielen Wissenschaftlern der School of Information der Renmin University of China, der School of Artificial Intelligence in Hillhouse und der University of Illinois in Urbana-Champaign durchgeführt.
Im Forschungsteam haben wir zwei große Namen im Bereich Data Mining gefunden: Wen Jirong und Han Jiawei.
Professor Wen Jirong ist derzeit Dekan der School of Artificial Intelligence an der Renmin University of China und Dekan der School of Information an der Renmin University of China. Die Hauptforschungsrichtungen sind Information Retrieval, Data Mining, maschinelles Lernen sowie das Training und die Anwendung groß angelegter neuronaler Netzwerkmodelle.
Professor Han Jiawei ist ein Experte auf dem Gebiet des Data Mining. Derzeit ist er Professor am Department of Computer Science der University of Illinois in Urbana-Champaign, Akademiker der American Computer Society und IEEE-Akademiker.
Papieradresse: https://arxiv.org/abs/2311.01964.
Das obige ist der detaillierte Inhalt vonLassen Sie nicht zu, dass sich große Vorbilder von Benchmark-Bewertungen täuschen lassen! Der Testsatz wird zufällig in das Vortraining einbezogen, die Punktzahl ist fälschlicherweise hoch und das Modell wird dumm.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was sind die Klassifizierungen künstlicher Intelligenz?
- Wie heißt Honors Assistent für künstliche Intelligenz?
- LeCun prognostiziert AGI: Sowohl große Modelle als auch verstärktes Lernen sind weit verbreitet! Mein „Weltmodell' ist der neue Weg
- Je größer das Modell, desto schlechter die Leistung? Google sammelt Aufgaben, die große Modelle zum Absturz bringen, und erstellt einen neuen Benchmark
- Lightning News |. JD.com führt das große Yanxi-KI-Modell für Einzelhandel, Medizin, Logistik und andere Industrieszenarien ein