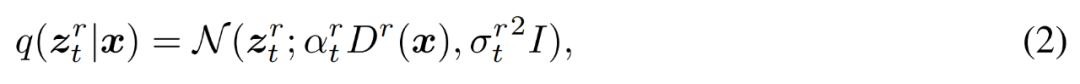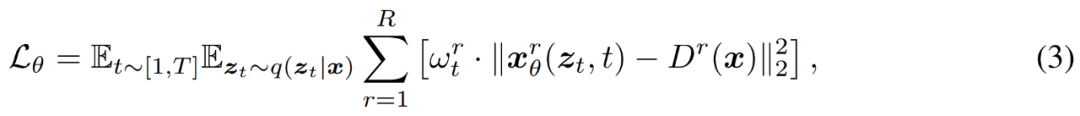Ich bin an stabile Diffusion gewöhnt und habe jetzt endlich ein Matroschka-Diffusionsmodell von Apple.
Im Zeitalter der generativen KI sind Diffusionsmodelle zu einem beliebten Werkzeug für generative KI-Anwendungen wie Bild-, Video-, 3D-, Audio- und Textgenerierung geworden. Die Ausweitung von Diffusionsmodellen auf hochauflösende Domänen steht jedoch immer noch vor erheblichen Herausforderungen, da das Modell bei jedem Schritt alle hochauflösenden Eingaben neu kodieren muss. Die Lösung dieser Herausforderungen erfordert den Einsatz tiefer Architekturen mit Aufmerksamkeitsblöcken, was die Optimierung erschwert und mehr Rechenleistung und Speicher verbraucht. Was soll ich tun? Einige neuere Arbeiten konzentrierten sich auf die Untersuchung effizienter Netzwerkarchitekturen für hochauflösende Bilder. Allerdings hat keine der vorhandenen Methoden Ergebnisse über eine Auflösung von 512×512 hinaus gezeigt, und die Erzeugungsqualität bleibt hinter den gängigen Kaskaden- oder Latentmethoden zurück. Wir nehmen als Beispiele OpenAI DALL-E 2, Google IMAGEN und NVIDIA eDiffI, die Rechenleistung sparen, indem sie ein Modell mit niedriger Auflösung und mehrere Diffusionsmodelle mit hoher Auflösung lernen, wobei jede Komponente separat trainiert wird. Andererseits lernt das latente Diffusionsmodell (LDM) nur ein Diffusionsmodell mit niedriger Auflösung und verlässt sich auf einen separat trainierten hochauflösenden Autoencoder. Bei beiden Lösungen erschweren mehrstufige Pipelines das Training und die Inferenz und erfordern häufig eine sorgfältige Abstimmung oder Hyperparameter. In diesem Artikel schlagen Forscher die Matryoshka Diffusion Models (MDM) vor, ein neues Diffusionsmodell für die durchgängige Erzeugung hochauflösender Bilder. Der Code wird bald veröffentlicht. 
Papieradresse: https://arxiv.org/pdf/2310.15111.pdfDie in dieser Studie vorgeschlagene Hauptidee besteht darin, den Diffusionsprozess mit niedriger Auflösung als Teil der hochauflösenden Erzeugung zu nutzen Durch die Verwendung von Einbettung führt die UNet-Architektur einen gemeinsamen Diffusionsprozess bei mehreren Auflösungen durch. Die Studie ergab, dass MDM zusammen mit der verschachtelten UNet-Architektur 1) Multi-Resolution-Verlust erreicht: die Konvergenzgeschwindigkeit der hochauflösenden Eingabeentrauschung erheblich verbessert; 2) einen effizienten progressiven Trainingsplan, beginnend mit dem Training niedrig Das Auflösungsdiffusionsmodell wird gestartet und hochauflösende Ein- und Ausgänge werden schrittweise wie geplant hinzugefügt. Experimentelle Ergebnisse zeigen, dass durch die Kombination von Multi-Resolution-Verlust und progressivem Training ein besseres Gleichgewicht zwischen Trainingskosten und Modellqualität erreicht werden kann. Diese Studie bewertet MDM hinsichtlich der klassenbedingten Bildgenerierung sowie der textbedingten Bild- und Videogenerierung. MDM ermöglicht das Training hochauflösender Modelle ohne den Einsatz von Kaskaden oder latenter Diffusion. Ablationsstudien zeigen, dass sowohl Multi-Resolution-Loss als auch progressives Training die Trainingseffizienz und -qualität erheblich verbessern. Lassen Sie uns die folgenden von MDM generierten Bilder und Videos genießen.
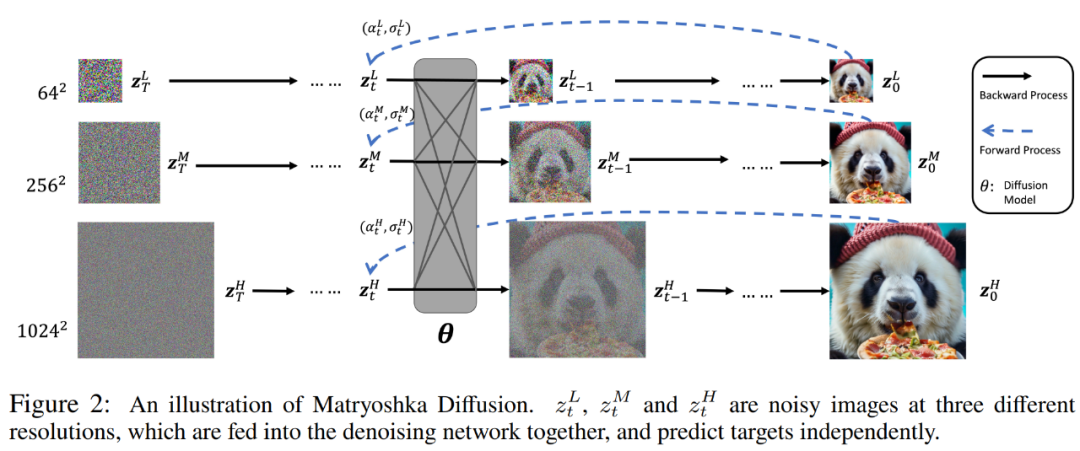
Die Forscher sagten, dass das MDM-Diffusionsmodell durchgängig in hoher Auflösung trainiert wird und dabei eine hierarchisch strukturierte Datenbildung nutzt. MDM verallgemeinert zunächst das Standarddiffusionsmodell im Diffusionsraum und schlägt dann eine dedizierte verschachtelte Architektur und einen Trainingsprozess vor. Schauen wir uns zunächst an, wie man das Standarddiffusionsmodell im erweiterten Raum verallgemeinert. Der Unterschied zu Kaskaden- oder latenten Methoden besteht darin, dass MDM einen einzelnen Diffusionsprozess mit einer hierarchischen Struktur lernt, indem Diffusionsprozesse mit mehreren Auflösungen in einem erweiterten Raum eingeführt werden. Die Details sind in Abbildung 2 unten dargestellt.
Konkret definiert der Forscher bei einem gegebenen Datenpunkt x ∈ R^N eine zeitbezogene latente Variable z_t = z_t^1 , .
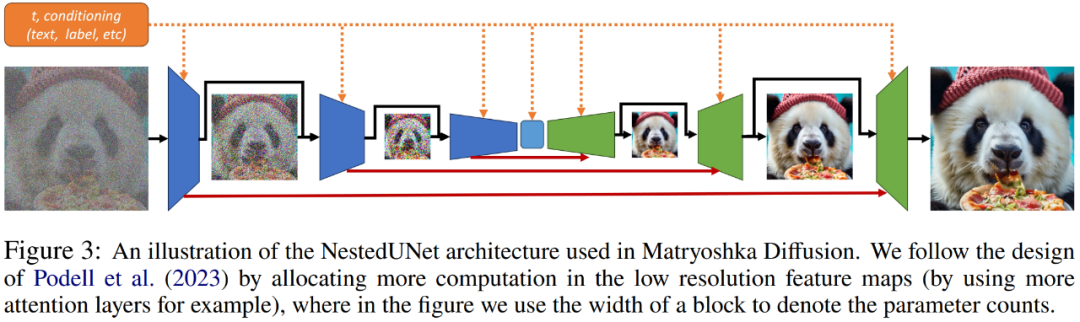
Forscher sagen, dass die Durchführung der Diffusionsmodellierung im erweiterten Raum die folgenden zwei Vorteile hat. Zum einen kümmern wir uns während der Inferenz normalerweise um die Ausgabe mit voller Auflösung z_t^R, sodass alle anderen Zwischenauflösungen als zusätzliche latente Variablen z_t^r behandelt werden, was die Komplexität der Modellierung der Verteilung erhöht. Zweitens bieten Abhängigkeiten mit mehreren Auflösungen die Möglichkeit, Gewichtungen und Berechnungen über z_t^r hinweg zu teilen, wodurch Berechnungen effizienter neu verteilt werden und effizientes Training und Inferenz ermöglicht werden. Sehen wir uns an, wie die verschachtelte Architektur (NestedUNet) funktioniert. Ähnlich wie bei typischen Diffusionsmodellen verwenden Forscher die UNet-Netzwerkstruktur zur Implementierung von MDM, wobei Restverbindungen und Berechnungsblöcke parallel verwendet werden, um feinkörnige Eingabeinformationen beizubehalten. Der Rechenblock enthält hier mehrere Faltungs- und Selbstaufmerksamkeitsschichten. Die Codes für NestedUNet und Standard-UNet lauten wie folgt.
Zusätzlich zu seiner Einfachheit im Vergleich zu anderen hierarchischen Methoden ermöglicht NestedUNet die effizienteste Verteilung der Berechnungen. Wie in Abbildung 3 unten dargestellt, ergaben frühe Untersuchungen von Forschern, dass MDM eine deutlich bessere Skalierbarkeit erreicht, wenn die meisten Parameter und Berechnungen mit der niedrigsten Auflösung zugewiesen werden.
Die Forscher verwenden herkömmliche Rauschunterdrückungsziele, um MDM bei mehreren Auflösungen zu trainieren, wie in Gleichung (3) unten dargestellt.
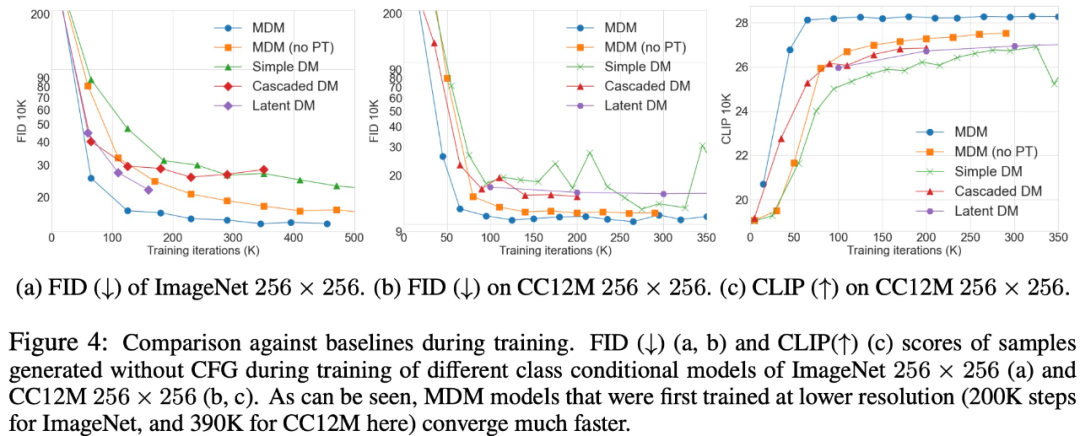
Hier kommt progressives Training zum Einsatz. Die Forscher trainierten MDM direkt Ende-zu-Ende gemäß der obigen Formel (3) und zeigten eine bessere Konvergenz als die ursprüngliche Basismethode. Sie fanden heraus, dass die Verwendung einer einfachen progressiven Trainingsmethode, ähnlich der im GAN-Artikel vorgeschlagenen, das Training hochauflösender Modelle erheblich beschleunigte. Diese Trainingsmethode vermeidet von Anfang an kostenintensives hochauflösendes Training und beschleunigt die Gesamtkonvergenz. Darüber hinaus wurde auch ein Training mit gemischter Auflösung integriert, bei dem Proben mit unterschiedlichen Endauflösungen gleichzeitig in einem einzigen Stapel trainiert werden. Experimente und ErgebnisseMDM ist eine allgemeine Technik, die auf jedes Problem anwendbar ist, bei dem die Eingabedimensionen schrittweise komprimiert werden können. Ein Vergleich von MDM mit dem Basisansatz ist in Abbildung 4 unten dargestellt.
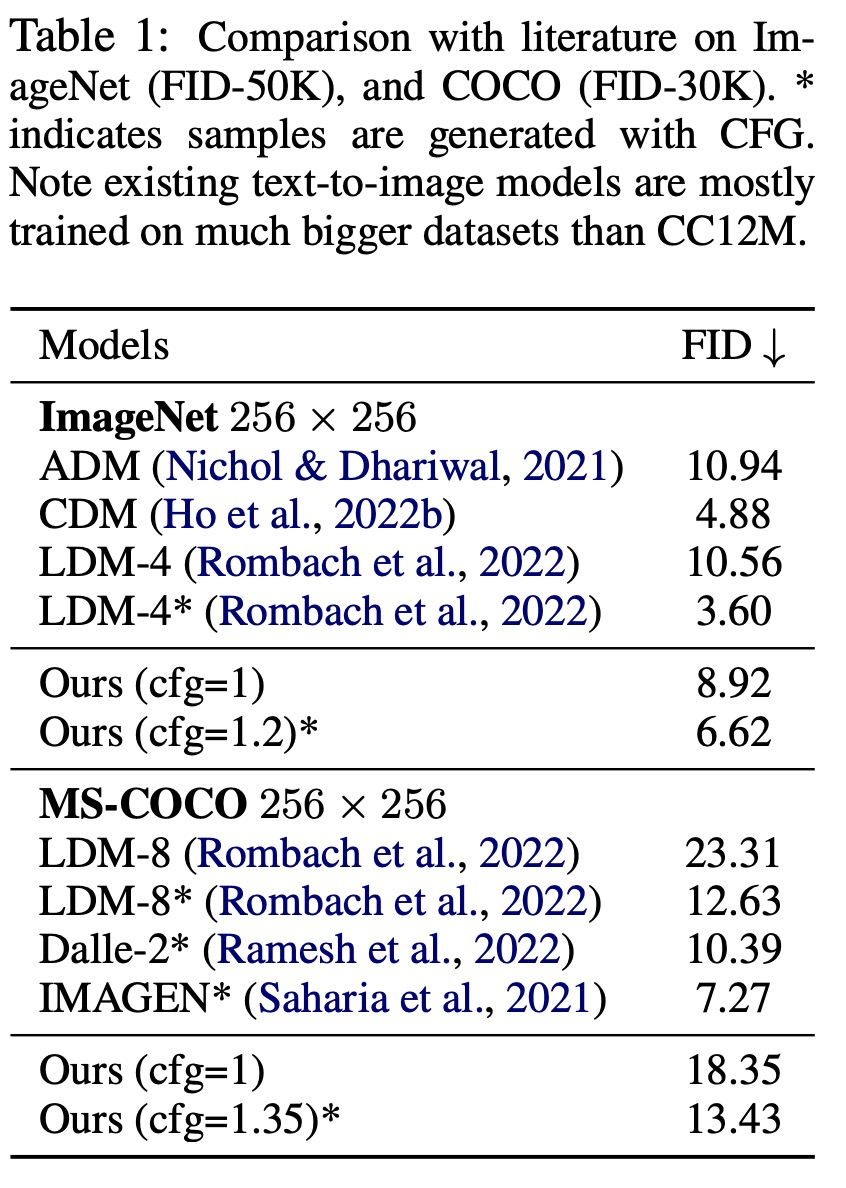
Tabelle 1 zeigt die Vergleichsergebnisse für ImageNet (FID-50K) und COCO (FID-30K).
Die Abbildungen 5, 6 und 7 unten zeigen die Ergebnisse von MDM bei der Bildgenerierung (Abbildung 5), Text zu Bild (Abbildung 6) und Text zu Video (Abbildung 7). Obwohl MDM auf einem relativ kleinen Datensatz trainiert wurde, zeigt es eine starke Zero-Shot-Fähigkeit, hochauflösende Bilder und Videos zu generieren.
Interessierte Leser können den Originaltext des Artikels lesen, um mehr über den Forschungsinhalt zu erfahren. Das obige ist der detaillierte Inhalt vonApples großes Vincent-Bildmodell vorgestellt: russische Matroschka-ähnliche Doppelseite, die eine Auflösung von 1024 x 1024 unterstützt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!