
Heim >Technologie-Peripheriegeräte >KI >Sehen Sie sich von den Grundlagen bis zur Praxis die Entwicklungsgeschichte des Elasticsearch-Vektorabrufs an
Sehen Sie sich von den Grundlagen bis zur Praxis die Entwicklungsgeschichte des Elasticsearch-Vektorabrufs an

- 王林nach vorne
- 2023-10-23 17:17:01811Durchsuche

1. Einführung
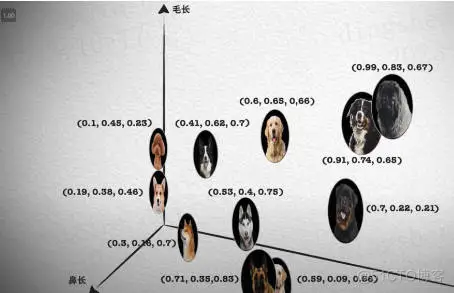
Die Vektorabfrage ist zu einem Kernbestandteil moderner Such- und Empfehlungssysteme geworden.
Es ermöglicht einen effizienten Abfrageabgleich und Empfehlungen, indem es komplexe Objekte (wie Text, Bilder oder Töne) in numerische Vektoren umwandelt und Ähnlichkeitssuchen im mehrdimensionalen Raum durchführt.
 Von den Grundlagen bis zur Praxis: Schauen Sie sich die Entwicklungsgeschichte von Elasticsearch Vector Retrieval_elasticsearch an.
Von den Grundlagen bis zur Praxis: Schauen Sie sich die Entwicklungsgeschichte von Elasticsearch Vector Retrieval_elasticsearch an.
Elasticsearch ist eine beliebte Open-Source-Suchmaschine, und ihre Entwicklung im Bereich Vektor Retrieval hat schon immer viel Aufmerksamkeit erregt. In diesem Artikel wird die Entwicklungsgeschichte des Elasticsearch-Vektorabrufs untersucht, wobei der Schwerpunkt auf den Merkmalen und dem Fortschritt jeder Phase liegt. Sich an der Geschichte zu orientieren, wird jedem helfen, ein umfassendes Verständnis des Elasticsearch-Vektorabrufs zu entwickeln.
2. Erster Versuch: Einführung des einfachen Vektorabrufs
Elasticsearch wurde ursprünglich nicht speziell für den Vektorabruf entwickelt. Mit dem Aufkommen von maschinellem Lernen und künstlicher Intelligenz ist jedoch die Nachfrage nach der Abfrage hochdimensionaler Vektorräume allmählich gestiegen.
In Version 5.x von Elasticsearch begannen Elastic-Enthusiasten, einfache Vektorabruffunktionen durch Plug-Ins und grundlegende mathematische Operationen zu implementieren. Zum Beispiel: Einige frühe Plug-Ins wie „Elasticsearch-Vector-Scoring“ und „Fast-ElasticSearch-Vector-Scoring“ sind darauf ausgelegt, solche Anforderungen zu erfüllen.
https://www.php.cn/link/7a677bb4477ae2dd371add568dd19e23
https://www.php.cn/link/7684e5225ab986f6b32ed950eec5621d
Vectors wird in dieser Phase hauptsächlich für grundlegende Ähnlichkeitsabfragen verwendet, z als Textähnlichkeitsberechnung. Obwohl die Funktionen relativ begrenzt sind, wird der Grundstein für die spätere Entwicklung gelegt.
Erweiterte Erklärung: Was die Funktion des maschinellen Lernens betrifft: Wenn Sie sich für die Änderung der Elasticsearch-Version interessieren, erinnere ich mich, dass zu diesem Zeitpunkt die 6.X-Version veröffentlicht wurde, was sehr aufregend war. Aufgrund der Nicht-Open-Source-Funktionen ist das tatsächliche heimische Publikum jedoch immer noch relativ klein.
3. Offizielle Unterstützung: Weiterentwicklung
Zu Elasticsearch Version 7.0 wurde offiziell Unterstützung für Vektorfelder hinzugefügt, beispielsweise durch den Typ „dense_vector“. Damit betritt Elasticsearch offiziell den Bereich der Vektorabfrage und verlässt sich nicht mehr ausschließlich auf Plug-Ins.
dense_vector Frühester Startzeitpunkt: 13. Dezember 2018, Version 7.6 ist als GA gekennzeichnet. Re In Bezug auf die Verwendung des Typs „dense_vector“ empfehlen wir die Lektüre: Hochdimensionaler Vektor Suche: Praktische Erkundung der Verwendung von „dense_vector“ in Elasticsearch 8.X.
Die größte Herausforderung in dieser Phase besteht darin, die Vektorabfrage in der traditionellen invertierten Indexstruktur effektiv zu unterstützen. In Kombination mit vorhandenen Volltextsuchfunktionen bietet Elasticsearch eine flexible und leistungsstarke Lösung. Von den ersten Plug-ins und grundlegenden Vorgängen bis hin zur späteren offiziellen Unterstützung und Integration legte diese Phase eine solide Grundlage für die weitere Innovation und Optimierung von Elasticsearch bei der Vektorabfrage.
4. Spezialisierte Optimierung: verbesserte ÄhnlichkeitsberechnungMit der wachsenden Nachfrage begann das Elasticsearch-Team mit der Durchführung eingehender Untersuchungen und der Optimierung der Vektorabrufleistung. Dies beinhaltet die Einführung komplexerer Ähnlichkeitsberechnungsmethoden wie Kosinusähnlichkeit, euklidische Distanz usw. sowie die Optimierung der Abfrageausführung.
Ab Elasticsearch Version 7.3 wurde offiziell eine komplexere Methode zur Ähnlichkeitsberechnung eingeführt. Insbesondere die Verbesserungen der script_score-Abfrage ermöglichen es Benutzern, umfangreichere Ähnlichkeitsberechnungen durch Painless-Skripte anzupassen.
/guide/en/elasticsearch/reference/7.3/query-dsl-script-score-query.html#vector-functions
Die Kernfunktion besteht darin, die Berechnung der Ähnlichkeit über den Winkel zwischen Vektoren unter Verwendung von k nächsten Nachbarn zu ermöglichen ( k-NN) zur Unterstützung von Ähnlichkeitssuchmaschinen. Es wird häufig in Textanalyse- und Empfehlungssystemen verwendet.
Wird hauptsächlich zur Lösung komplexer Ähnlichkeitsanforderungen verwendet und bietet flexiblere und leistungsfähigere Ähnlichkeitsberechnungsoptionen, um mehr Geschäftsanforderungen zu erfüllen.
Anwendungsszenarien spiegeln sich wider in:
(1)个性化推荐:通过余弦相似度分析用户的行为和兴趣,提供更个性化的推荐内容;(2)图像识别和搜索:使用欧几里得距离快速检索与给定图像相似的图像;(3)声音分析:在声音文件之间寻找相似模式,用于语音识别和分析。
Es ist erwähnenswert, dass: Ursprünglich waren die vom Vektorabruf unterstützten Dimensionen: 1024, bis zur Elasticsearch-Version 8.8 wurden die unterstützten Dimensionen geändert in: 2048 (dies ist eine stark nachgefragte Anforderung) .
https://www.php.cn/link/1bda7493c968ded9800b3a754fc07e5c/t/vector-knn-search-with-more-than-1024-dimensions/332819
Elasticsearch 7.x 版本的增强相似度计算功能标志着向量检索能力的显著进展。通过引入更复杂的相似度计算方法和查询优化,Elasticsearch 不仅增强了其在传统搜索场景中的功能,还为新兴的机器学习和 AI 应用打开了新的可能性。
但,这个时候你会发现,如果要实现复杂的向量搜索功能,自己实现的还很多。如果把后面马上提到的深度学习的集成和大模型的出现比作:飞行的汽车,当前的阶段还是 “拉驴车”,功能是有的,但用起来很费劲。
 从基础到实践,回顾Elasticsearch 向量检索发展史_Elastic_02
从基础到实践,回顾Elasticsearch 向量检索发展史_Elastic_02
5.深度学习集成与未来展望
大模型时代,向量检索和多模态搜索成为 “兵家” 必争之地。
多模态检索是一种综合各种数据模态(如文本、图像、音频、视频等)的检索技术。换句话说,它不仅仅是根据文字进行搜索,还可以根据图像、声音或其他模态的输入来搜索相关内容。
为了更通俗地理解多模态检索,我们可以通过以下比喻和示例来加深认识:想象你走进一个巨大的图书馆,这里不仅有书籍,还有各种图片、录音和视频。你可以向图书馆员展示一张照片,她会为你找到与这张照片相关的所有书籍、音频和视频。或者,你可以哼一段旋律,图书馆员能找到相关的资料,或者提供类似的歌曲或视频。这就是多模态检索的魔力!
随着深度学习技术的不断发展和应用,Elasticsearch 已开始探索将深度学习模型直接集成到向量检索过程中。这不仅允许更复杂、更准确的相似度计算,还开辟了新的应用领域,例如基于图像或声音的搜索。尤其在 Elasticsearch 的 8.x 版本,这一方向得到了显著的推进。
5.1 向量化是前提
如下图所示,先从左往右看是写入,图像、文档、音频转化为向量特征表示,在 Elasticsearch 中通过 dense_vector 类型存储。
从右往左看是检索,先将检索语句转化为向量特征表示,然后借助 K 近邻检索算法(在 Elasticsearch 中借助 Knn search 实现),获取相似的结果。
看中间,Results 部分就是向量检索的结果。
综上,向量检索打破了传统倒排索引仅支持文本检索的缺陷,可以扩展支持文本、语音、图像、视频多种模态。
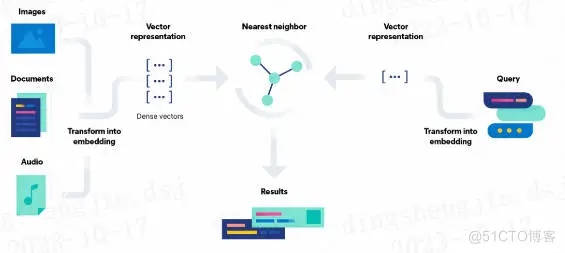 图片来自:Elasticsearch 官方文档
图片来自:Elasticsearch 官方文档
相信你到这里,应该理解了向量检索和多模态。没有向量化的这个过程,多模态检索无从谈起。
5.2 模型是核心
深度学习模型集成总共可分为三步:
第一步:模型导入和管理:Elasticsearch 8.x 支持导入预训练的深度学习模型,并提供相应的模型管理工具,方便模型的部署和更新。第二步:向量表示与转换:通过深度学习模型,可以将非结构化数据如图像和声音转换为向量表示,从而进行有效的检索。第三步:自定义相似度计算:8.x 版本提供了基于深度学习模型的自定义相似度计算接口,允许用户根据实际需求开发和部署专门的相似度计算方法。
关于深度学习,可以是自训练模型,也可以是第三方模型库中的模型,举例:咱们图搜图案例中就是用的 HuggingFace 里的:clip-ViT-B-32-multilingual-v1 模型。
 从基础到实践,回顾Elasticsearch 向量检索发展史_Elastic_04
从基础到实践,回顾Elasticsearch 向量检索发展史_Elastic_04
Elasticsearch 支持的第三方模型列表:
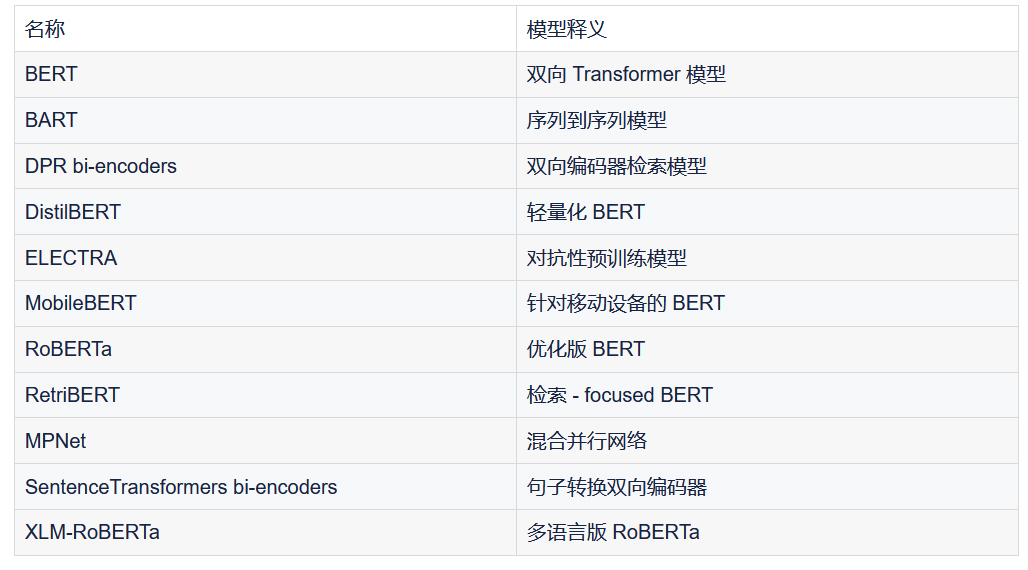
包括如下的 Hugging Face 模型库也都是支持的。
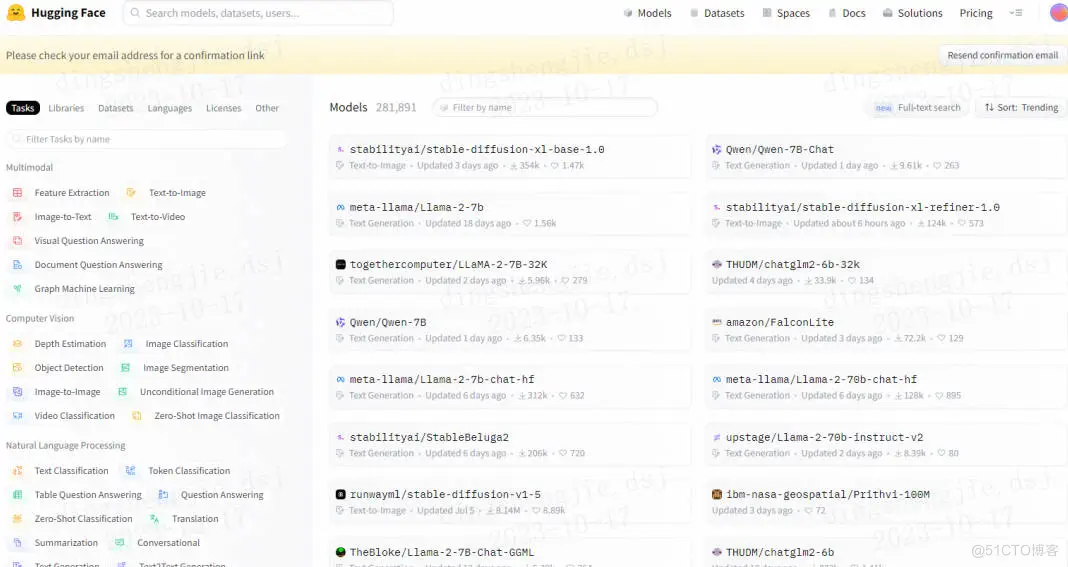 从基础到实践,回顾Elasticsearch 向量检索发展史_elasticsearch_05
从基础到实践,回顾Elasticsearch 向量检索发展史_elasticsearch_05
模型是 Elasticsearch 与深度学习集成的核心,它能将复杂的数据转化为 “指纹” 向量,使搜索更高效和智能。借助模型,Elasticsearch 可以理解和匹配各种非结构化数据,如图像和声音,提供更为准确和个性化的搜索结果,同时适应不断变化的数据和需求。“没有了模型,我们还需要黑暗中摸索很久”。
第三方模型官网介绍:/guide/en/machine-learning/8.9/ml-nlp-model-ref.html#ml-nlp-model-ref-text-embedding
值得一提的是:Elasticsearch 导入大模型需要专属 Python 客户端工具 Eland。
Eland 是一个 Python Elasticsearch 客户端,让用户能用类似 Pandas 的 API 来探索和分析 Elasticsearch 中的数据,还支持从常见机器学习库上传训练好的模型到 Elasticsearch。
Eland 是为了与 Elasticsearch 协同工作而开发的库。它不是 Elasticsearch 的一个特定版本产物,而是作为一个独立的项目来帮助 Python 开发者更方便地在 Elasticsearch 中进行数据探索和机器学习任务。
Eland 更多参见:
/guide/en/elasticsearch/client/eland/current/index.html
https://www.php.cn/link/47e57c4836ae0c44f774f9d8497e0b4f
5.3 ESRE 是 Elastic 的未来
前一段时间在分别给两位阿里云、腾讯云大佬聊天的时候,都提到了 Elasticsearch Relevance Engine (ESRE) 才是 Elastic 未来。
ESRE 官方介绍如下:——Elasticsearch Relevance Engine 将 AI 的最佳实践与 Elastic 的文本搜索进行了结合。ESRE 为开发人员提供了一整套成熟的检索算法,并能够与大型语言模型 (LLM) 集成。借助 ESRE,我们可以应用具有卓越相关性的开箱即用型语义搜索,与外部大型语言模型集成,实现混合搜索,并使用第三方或我们自己的模型。
ESRE 集成了高级相关性排序如 BM25f、强大的矢量数据库、自然语言处理技术、与第三方模型如 GPT-3 和 GPT-4 的集成,并支持开发者自定义模型与应用。其特点在于提供深度的语义搜索,与专业领域的数据整合,以及无缝的生成式 AI 整合,让开发者能够构建更吸引人、更准确的搜索体验。
在 Elasticsearch 8.9 版本上新了:Semantic search 语义检索功能,对官方文档熟悉的同学,你会发现如下截图内容,早期版本是没有的。
语义搜索不是根据搜索词进行字面匹配,而是根据搜索查询的意图和上下文含义来检索结果。
更进一步讲:语义搜索不仅仅是匹配你输入的关键字,而是试图理解你的真正意图,给你带来更准确、更有上下文的搜索结果。简单来说,如果你在英国搜索 “football”,系统知道你可能想要搜橄榄球,而不是足球(在美国 football 是足球)。
这种智能搜索方式,得益于强大的文本向量化等技术背景,使我们的在线搜索体验更加直观、方便和满意。
在文本里检索 connection speed requirement, 这点属于早期的倒排索引检索方式,或者叫全文检索中的短语 match_phrase 检索匹配 或者分词 match 检索匹配。这种可以得到结果。但是,中后半段视频显示,要是咱们要检索:“How fast should my internet be” 怎么办?
其实这里转换为向量检索,fast 和 speed 语义相近,should be 和 required、needs 语义相近,internet 和 connection、wifi 语义相近。所以依然能召回结果。
这突破了传统同义词的限制,体现了语义检索的妙处!
更进一步,我们给出语义检索和传统分词检索的区别,以期望大家更好的理解语义搜索。
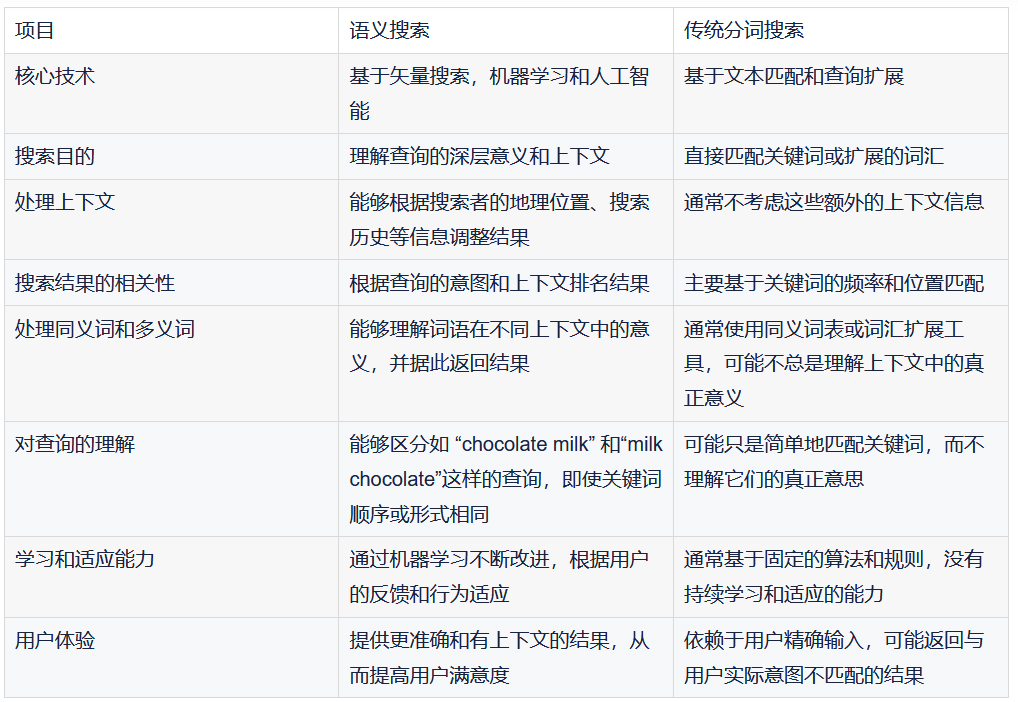
总体而言,深度学习集成已经成为 Elasticsearch 向量检索能力的有力补充,促使它在搜索和分析领域的地位更加牢固,同时也为未来的发展提供了广阔的空间。
6.小结
Elasticsearch 的向量检索从最初的简单实现发展到现在的高效、多功能解决方案,反映了现代搜索和推荐系统的需求和挑战。随着技术的不断演进,我们可以期待 Elasticsearch 在向量检索方面将继续推动创新和卓越。
说一下最近的感触,向量检索、大模型等新技术的出现有种感觉 “学不完,根本学不完”,并且很容易限于 “皮毛论”(我自创的词)——所有技术都了解一点点,但经不起提问;浅了说,貌似啥都懂,深了说,一问三不知。
这种情况怎么办?我目前的方法是:以实践为目的去深入理解理论,必要时理解算法,然后不定期将所看、所思、所想梳理成文,以备忘和知识体系化。这个过程很慢、很累,但我相信时间越长、价值越大。
欢迎大家就向量检索等问题进行留言讨论交流,你的问题很可能就是下一次文章的主题哦!
7.参考
1、/cn/blog/text-similarity-search-with-vectors-in-elasticsearch
2、/guide/en/elasticsearch/reference/7.3/query-dsl-script-score-query.html#vector-functions-cosine
3、https://www.php.cn/link/8b0bb3eff8c1e5bf7f206125959921d7
Das obige ist der detaillierte Inhalt vonSehen Sie sich von den Grundlagen bis zur Praxis die Entwicklungsgeschichte des Elasticsearch-Vektorabrufs an. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!