
Heim >Technologie-Peripheriegeräte >KI >Kann Ihre GPU große Modelle wie Llama 2 ausführen? Probieren Sie es mit diesem Open-Source-Projekt aus
Kann Ihre GPU große Modelle wie Llama 2 ausführen? Probieren Sie es mit diesem Open-Source-Projekt aus

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-10-23 14:29:011497Durchsuche
Kann Ihre GPU in einer Zeit, in der Rechenleistung das A und O ist, große Modelle (LLM) reibungslos ausführen?
Viele Menschen haben Schwierigkeiten, diese Frage genau zu beantworten und wissen nicht, wie man den GPU-Speicher berechnet. Da es nicht so einfach ist, zu sehen, welche LLMs eine GPU verarbeiten kann, wie die Modellgröße zu betrachten, können Modelle während der Inferenz viel Speicher beanspruchen (KV-Cache), z. B. hat llama-2-7b eine Sequenzlänge von 1000 und benötigt 1 GB zusätzlicher Speicher. Darüber hinaus belegen KV-Cache, Aktivierung und Quantisierung während des Modelltrainings viel Speicher.
Wir kommen nicht umhin, uns zu fragen, ob wir die oben genannte Speichernutzung im Voraus wissen können. In den letzten Tagen ist auf GitHub ein neues Projekt erschienen, mit dessen Hilfe Sie berechnen können, wie viel GPU-Speicher während des Trainings oder der Inferenz von LLM benötigt wird. Mithilfe dieses Projekts können Sie außerdem die detaillierte Speicherverteilung ermitteln Bewertungsmethoden, maximale verarbeitete Kontextlänge und andere Aspekte, um Benutzern bei der Auswahl der für sie geeigneten GPU-Konfiguration zu helfen.
Projektadresse: https://github.com/RahulSChand/gpu_poor
Darüber hinaus ist dieses Projekt auch interaktiv, wie unten gezeigt, es kann den GPU-Speicher berechnen, der zum Ausführen von LLM erforderlich ist. Es ist so einfach wie das Ausfüllen der Lücken. Der Benutzer muss nur einige notwendige Parameter eingeben und schließlich auf die blaue Schaltfläche klicken, und die Antwort wird angezeigt. ?? Autor Rahul Shiv Chand sagte, dass es folgende Gründe gibt:
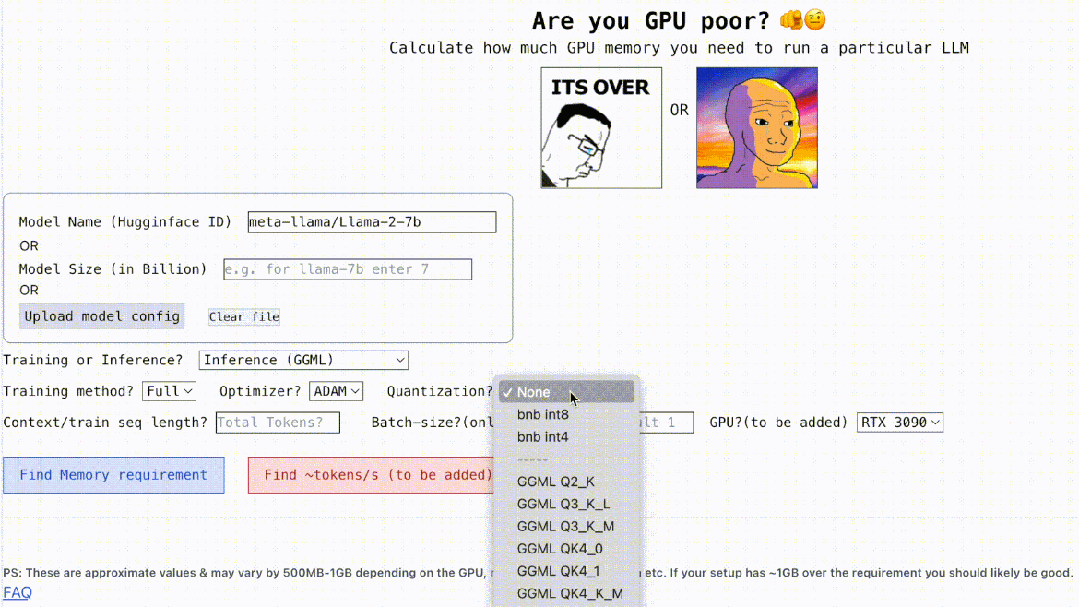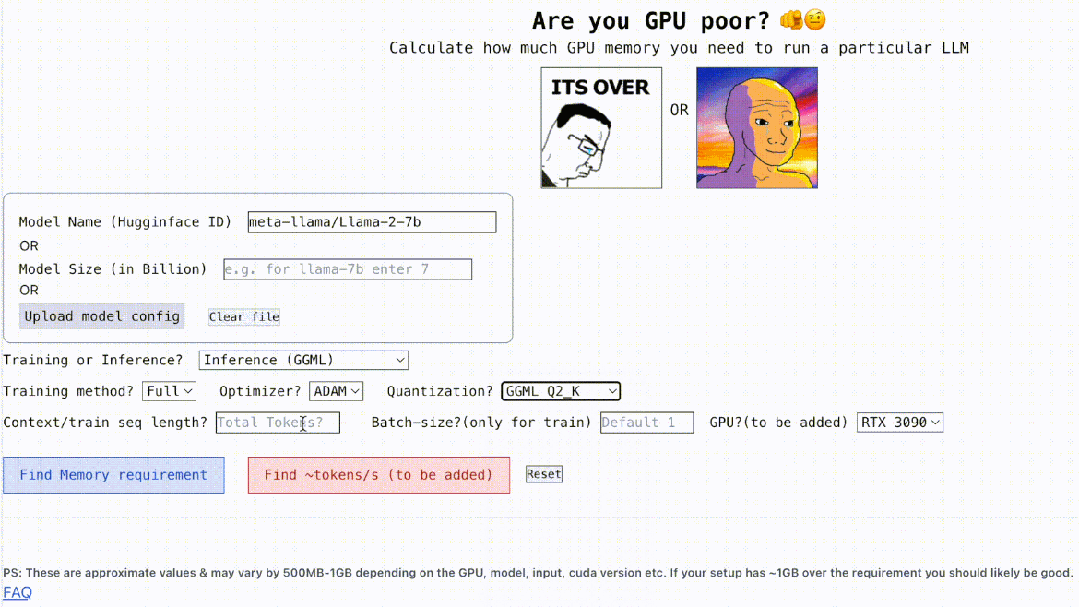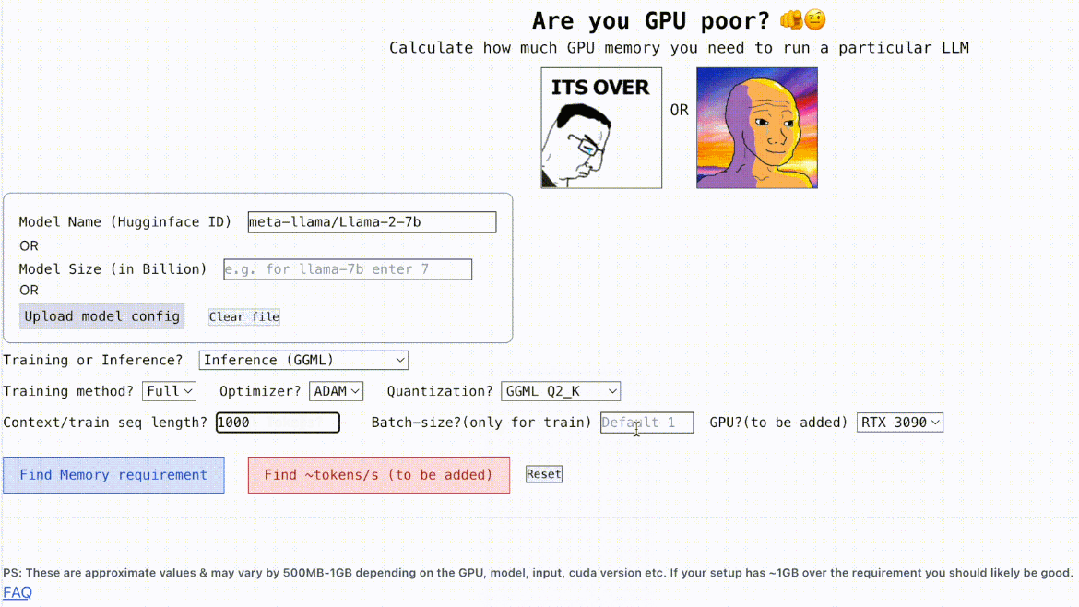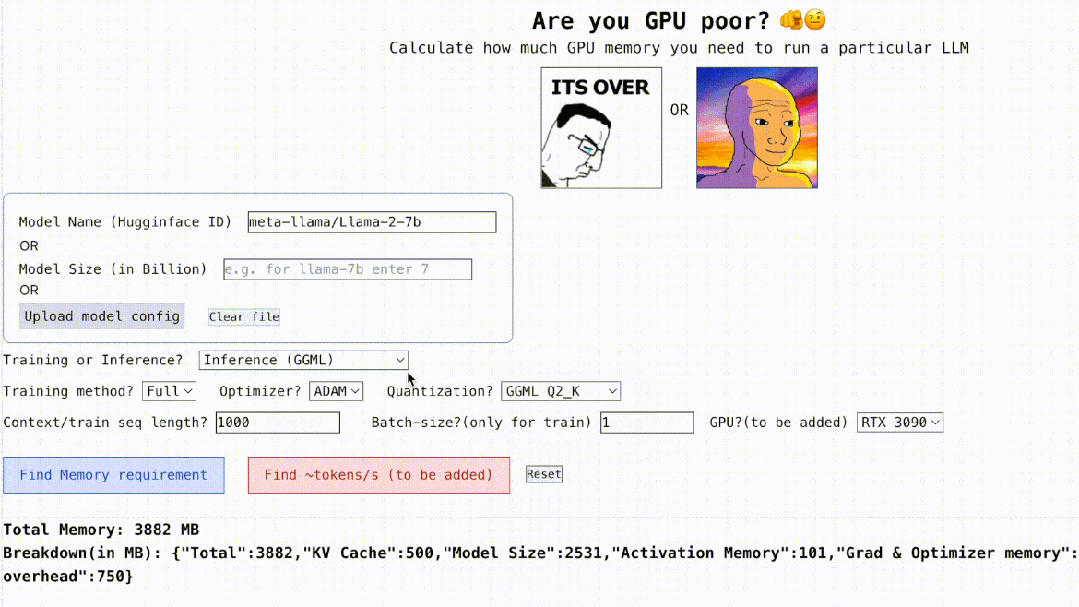
Was ist die maximale Kontextlänge, die die GPU verarbeiten kann?
Welche Feinabstimmungsmethode ist für Sie besser geeignet? Voll? LoRA? Oder QLoRA?
Also, wie nutzen wir es?
- Der erste Schritt besteht darin, den Modellnamen, die ID und die Modellgröße zu verarbeiten. Sie können die Modell-ID auf Huggingface eingeben (z. B. meta-llama/Llama-2-7b). Derzeit verfügt das Projekt über fest codierte und gespeicherte Modellkonfigurationen für die 3000 am häufigsten heruntergeladenen LLMs auf Huggingface.
- Wenn Sie ein benutzerdefiniertes Modell verwenden oder die Hugginface-ID nicht verfügbar ist, müssen Sie die JSON-Konfiguration hochladen (siehe Projektbeispiel) oder einfach die Modellgröße eingeben (z. B. ist llama-2-7b 7 Milliarden). ).
- Dann kommt die Quantisierung, derzeit unterstützt das Projekt Bitsandbytes (bnb) int8/int4 und GGML (QK_8, QK_6, QK_5, QK_4, QK_2). Letzteres wird nur für Inferenzen verwendet, während bnb int8/int4 sowohl für Training als auch für Inferenzen verwendet werden kann.
- Der letzte Schritt ist Inferenz und Training. Verwenden Sie während des Inferenzprozesses die HuggingFace-Implementierung oder verwenden Sie vLLM- oder GGML-Methoden, um den für die Inferenz verwendeten vRAM zu finden LoRA (im aktuellen Projekt wurde die LoRA-Konfiguration mit r=8 fest codiert), QLoRA zur Feinabstimmung.
- Der Projektautor gab jedoch an, dass die Endergebnisse je nach Benutzermodell, Eingabedaten, CUDA-Version, Quantifizierungstools usw. variieren können. Im Experiment versuchte der Autor, diese Faktoren zu berücksichtigen und sicherzustellen, dass das Endergebnis innerhalb von 500 MB lag. In der folgenden Tabelle hat der Autor die Speichernutzung der auf der Website bereitgestellten 3b-, 7b- und 13b-Modelle mit der Speichernutzung der RTX 4090- und 2060-GPUs verglichen. Alle Werte liegen innerhalb von 500 MB.
Interessierte Leser können es selbst erleben. Wenn die angegebenen Ergebnisse ungenau sind, sagte der Projektautor, dass das Projekt zeitnah optimiert und verbessert wird.
Das obige ist der detaillierte Inhalt vonKann Ihre GPU große Modelle wie Llama 2 ausführen? Probieren Sie es mit diesem Open-Source-Projekt aus. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!