
Heim >Technologie-Peripheriegeräte >KI >Schauen wir uns Bilder großer Models effektiver an als das Tippen! Neue Forschung in NeurIPS 2023 schlägt eine multimodale Abfragemethode vor, die die Genauigkeit um 7,8 % erhöht
Schauen wir uns Bilder großer Models effektiver an als das Tippen! Neue Forschung in NeurIPS 2023 schlägt eine multimodale Abfragemethode vor, die die Genauigkeit um 7,8 % erhöht

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-10-23 11:45:09821Durchsuche
Die Fähigkeit, Bilder großer Models zu „erkennen“, ist so stark, warum suchen sie immer noch nach den falschen Dingen?
Zum Beispiel die Verwechslung von Fledermäusen und Fledermäusen, die sich nicht ähneln, oder das Nichterkennen seltener Fische in einigen Datensätzen ...
Das liegt daran, dass wir oft „The is“ eingeben, wenn wir große Modelle bitten, „Dinge zu finden“. der Text .
Wenn die Beschreibung mehrdeutig oder zu voreingenommen ist, wie zum Beispiel „Fledermaus“ (Fledermaus oder Fledermaus?) oder „Teufel“ (Cyprinodon diabolis) , wird die KI stark verwirrt sein.
Dies führt dazu, dass bei der Verwendung großer Modelle zur Zielerkennung, insbesondere in der offenen Welt (unbekannte Szenen)Zielerkennungsaufgaben, die Ergebnisse oft nicht so gut sind wie erwartet.
Jetzt löst ein in NeurIPS 2023 enthaltener Artikel dieses Problem endlich.

Der Artikel schlägt eine Zielerkennungsmethode vor, die auf einer multimodalen Abfrage basiertMQ-Det Durch einfaches Hinzufügen eines Bildbeispiels zur Eingabe kann die Genauigkeit beim Auffinden von Dingen in einem großen Modell erheblich verbessert werden.
Auf dem Benchmark-Erkennungsdatensatz LVIS verbessert MQ-Det die Genauigkeit des Mainstream-Erkennungs-Großmodells GLIP um etwa 7,8 %, ohne dass eine Feinabstimmung des nachgelagerten Aufgabenmodells erforderlich ist Bei kleinen Stichproben nachgelagerter Aufgaben beträgt die durchschnittliche Verbesserung 6,3 %Genauigkeit.
Wie geht das? Werfen wir einen Blick darauf.
Der folgende Inhalt stammt vom Autor des Artikels und Zhihu-Blogger @沁园夏:
Inhaltsverzeichnis
- MQ-Det: Ein großes Open-World-Zielerkennungsmodell für multimodale Abfragen
- 1.1 Von der Textabfrage zur multimodalen Stateful-Abfrage
- 1.2 Multimodale Plug-and-Play-Abfragemodellarchitektur von MQ-Det
- 1.3 Effiziente Trainingsstrategie von MQ-Det
- 1.4 Experimentelle Ergebnisse: Feinabstimmungsfreie Bewertung
- 1.5 Experimentell Ergebnisse: Few-Shot-Auswertung
- 1.6 Perspektiven der multimodalen Abfrageobjekterkennung
MQ-Det: Ein großes Open-World-Objekterkennungsmodell für multimodale Abfragen
Papiername: Multimodale Abfrageobjekterkennung in the Wild
Papierlink: https://www.php.cn/link/9c6947bd95ae487c81d4e19d3ed8cd6f
Codeadresse: https://www.php.cn/link/2307ac1cfee5db3a 5402aac9db25cc5d

1.1 Von der Textabfrage zur multimodalen Abfrage
Ein Bild sagt mehr als tausend Worte: Mit dem Aufkommen des Bild- und Text-Vortrainings und der offenen Semantik von Text ist die Zielerkennung allmählich in die offene Phase eingetreten Weltwahrnehmung. Zu diesem Zweck folgen viele große Erkennungsmodelle dem Muster der Textabfrage, bei der kategoriale Textbeschreibungen verwendet werden, um potenzielle Ziele in Zielbildern abzufragen. Allerdings steht dieser Ansatz häufig vor dem Problem, dass er „weitgehend, aber nicht präzise“ ist.
Zum Beispiel (1) Erkennung feinkörniger Objekte (Fischarten) in Abbildung 1 ist es oft schwierig, verschiedene feinkörnige Fischarten mit begrenztem Text zu beschreiben, (2) Mehrdeutigkeit der Kategorie („Fledermaus“ beides). Es kann sich sowohl auf Schläger als auch auf Schläger beziehen).
Die oben genannten Probleme können jedoch durch Bildbeispiele gelöst werden. Bilder können reichere Funktionshinweise auf das Zielobjekt liefern, aber gleichzeitig weist Text eine starke Verallgemeinerung auf.
Daher ist es eine natürliche Idee geworden, die beiden Abfragemethoden organisch zu kombinieren.Schwierigkeit beim Erhalten multimodaler Abfragefunktionen: Beim Erhalten eines solchen Modells mit multimodaler Abfrage gibt es drei Herausforderungen: (1) Die direkte Feinabstimmung mit begrenzten Bildbeispielen kann leicht zu katastrophalem Vergessen führen; ) ) Das Training eines großen Erkennungsmodells von Grund auf führt zu einer besseren Verallgemeinerung, kostet jedoch viel Geld. Zum Beispiel erfordert das Training von GLIP auf einer einzelnen Karte das Training von 30 Millionen Datenmengen über 480 Tage.
Multimodale Abfragezielerkennung: Basierend auf den obigen Überlegungen schlägt der Autor eine einfache und effektive Modelldesign- und Trainingsstrategie vor – MQ-Det.
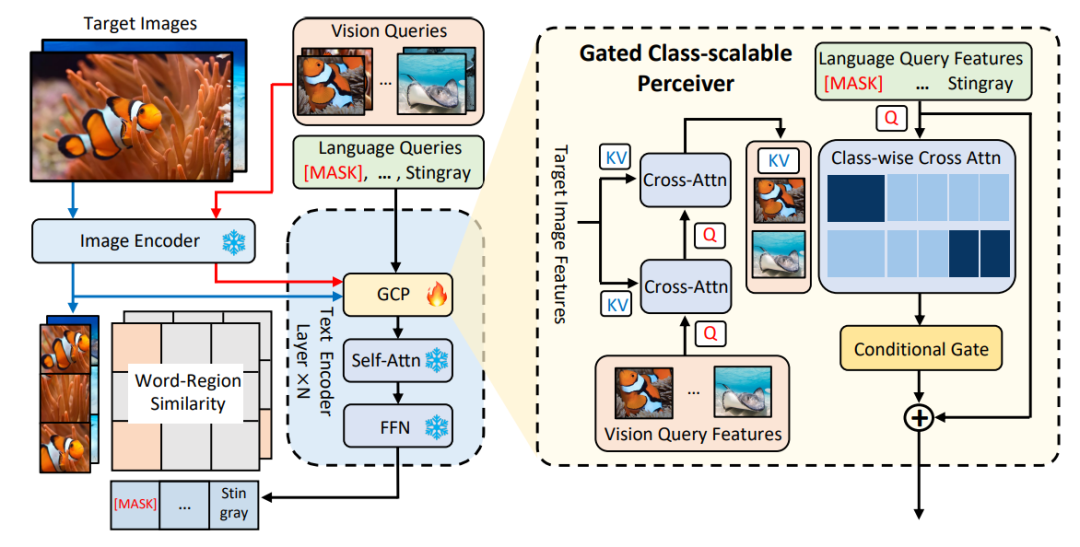
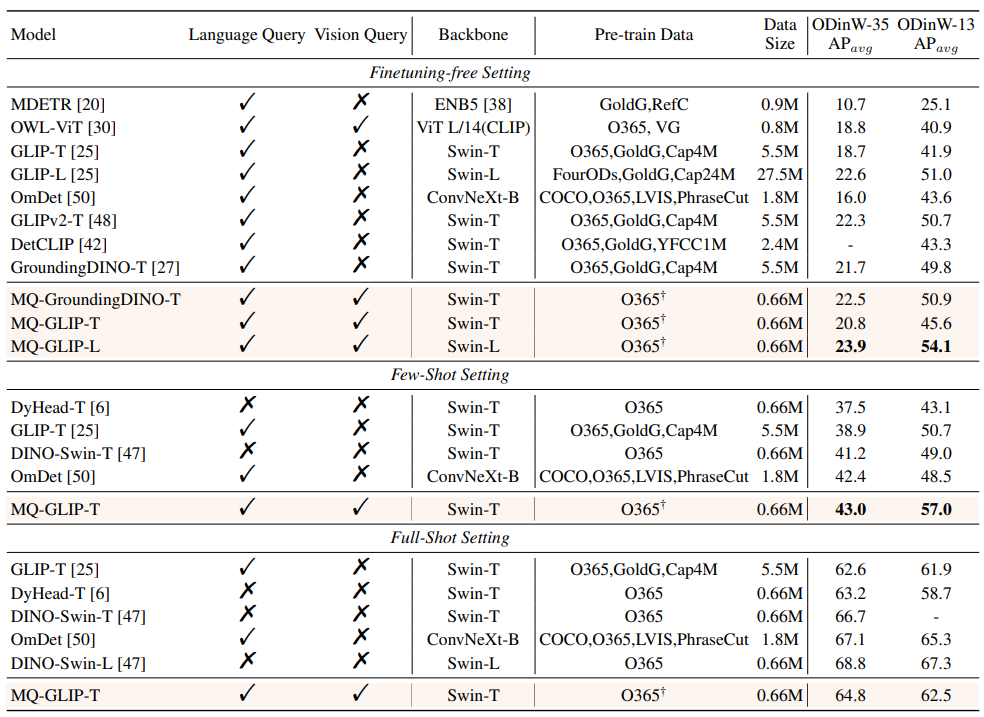
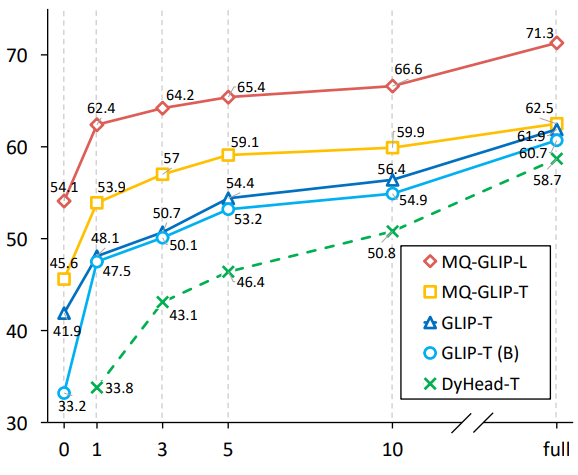
MQ-Det fügt eine kleine Anzahl von GCP-Modulen auf der Grundlage des vorhandenen großen Erkennungsmodells für eingefrorene Textabfragen ein, um Eingaben aus visuellen Beispielen zu erhalten. Gleichzeitig wird eine Sprachvorhersage für visuelle Zustandsmasken entworfen Trainingsstrategie, um effizient einen High-A-Detektor für leistungsstarke multimodale Abfragen zu erhalten. △Abbildung 1 Diagramm der MQ-Det-Methodenarchitektur Gated-Sensing-Modul Wie in Abbildung 1 gezeigt, hat der Autor den Text Das Encoder-Ende des großen Modells zur Erkennung eingefrorener Texte wird Schicht für Schicht in das GCP-Wahrnehmungsmodul eingefügt. Der Arbeitsmodus von GCP kann durch die folgende Formel prägnant ausgedrückt werden: mit dem Zielbild aus, das ich erhalten möchte , um seine Darstellungsfähigkeit zu verbessern, und dann führt jeder Kategorietext ti eine Queraufmerksamkeit mit dem visuellen Beispiel des entsprechenden aus Kategorie, um Da das aktuelle große vorab trainierte Erkennungsmodell für Textabfragen selbst eine gute Verallgemeinerung aufweist, ist der Autor des Artikels der Ansicht, dass dies nur der Fall ist leichte Anpassungen mit visuellen Details basierend auf den ursprünglichen Textmerkmalen. Der Artikel enthält auch eine spezifische experimentelle Demonstration, in der festgestellt wurde, dass eine Feinabstimmung nach dem Öffnen der ursprünglichen vorab trainierten Modellparameter leicht zu katastrophalem Vergessen führen kann und stattdessen die Fähigkeit zur Erkennung der offenen Welt verloren geht. So kann MQ-Det visuelle Informationen effizient in den Detektor vorhandener Textabfragen einfügen, indem nur das trainierte GCP-Modul basierend auf dem vorab trainierten Detektor eingefrorener Textabfragen moduliert wird. In dem Artikel wendet der Autor das Strukturdesign und die Trainingstechnologie von MQ-Det auf die aktuellen SOTA-Modelle GLIP bzw. GroundingDINO an, um die Vielseitigkeit der Methode zu überprüfen. Der Autor schlug auch eine bildbedingte Trainingsstrategie für die Vorhersage maskierter Sprache vor, um das Problem der Lernträgheit zu lösen, die durch das Einfrieren des vorab trainierten Modells verursacht wird. Die sogenannte Lernträgheit bedeutet, dass der Detektor dazu neigt, während des Trainingsprozesses die Merkmale der ursprünglichen Textabfrage beizubehalten und somit die neu hinzugefügten visuellen Abfragemerkmale zu ignorieren. Zu diesem Zweck ersetzt MQ-Det während des Trainings zufällig Text-Tokens durch [MASK]-Tokens und zwingt das Modell, von der Seite der visuellen Abfragefunktionen zu lernen, das heißt: 1.4 Experimentelle Ergebnisse: Feinabstimmungsfreie Bewertung : Im Vergleich zur herkömmlichen Zero-Shot-Bewertung (Zero-Shot) , bei der nur Kategorietext zum Testen verwendet wird, schlägt MQ-Det eine realistischere Bewertungsstrategie vor: Feinabstimmungsfrei. Es ist definiert als: Ohne nachgelagerte Feinabstimmung können Benutzer Kategorietext, Bildbeispiele oder eine Kombination aus beidem verwenden, um eine Objekterkennung durchzuführen. Unter feinabstimmungsfreien Einstellungen wählt MQ-Det 5 visuelle Beispiele für jede Kategorie aus und kombiniert Kategorietext für die Zielerkennung. Andere vorhandene Modelle unterstützen jedoch keine visuellen Abfragen und können nur Klartextbeschreibungen durchführen. Die folgende Tabelle zeigt die Erkennungsergebnisse für LVIS MiniVal und LVIS v1.0. Es kann festgestellt werden, dass die Einführung multimodaler Abfragen die Fähigkeit zur Zielerkennung in der offenen Welt erheblich verbessert. △Tabelle 1 Die feinabstimmungsfreie Leistung jedes Erkennungsmodells unter dem LVIS-Benchmark-Datensatz Wie aus Tabelle 1 ersichtlich ist, hat MQ-GLIP-L den AP basierend auf GLIP-L um mehr als 7 % erhöht , und die Wirkung ist sehr gut! △Tabelle 2 Leistung jedes Modells in 35 Erkennungsaufgaben ODinW-35 und seiner 13 Teilmenge ODinW-13 Der Autor führte außerdem 35 nachgelagerte Erkennungsaufgaben durch. Es wurden umfassende Experimente durchgeführt durchgeführt in ODinW-35. Wie aus Tabelle 2 ersichtlich ist, verfügt MQ-Det zusätzlich zu seiner leistungsstarken Leistung ohne Feinabstimmung auch über gute Fähigkeiten zur Erkennung kleiner Stichproben, was das Potenzial multimodaler Abfragen weiter bestätigt. Abbildung 2 zeigt auch die signifikante Verbesserung von MQ-Det auf GLIP. △Abbildung 2 Vergleich der Datennutzungseffizienz; horizontale Achse: Anzahl der Trainingsbeispiele, vertikale Achse: durchschnittlicher AP auf OdinW-13 Zielerkennung als praktisches Mittel Anwendung Es ist ein Grundlagenforschungsgebiet und legt großen Wert auf die Implementierung von Algorithmen. Obwohl frühere Modelle zur Erkennung von Nur-Text-Abfragen eine gute Verallgemeinerung gezeigt haben, ist es für Text schwierig, feinkörnige Informationen bei der tatsächlichen Erkennung in der offenen Welt abzudecken, und die reichhaltige Informationsgranularität in Bildern ergänzt dies perfekt. Bisher können wir feststellen, dass Text allgemein, aber nicht präzise ist und Bilder präzise, aber nicht allgemein sind. Wenn wir beides, also eine multimodale Abfrage, effektiv kombinieren können, wird dies die Zielerkennung in der offenen Welt weiter vorantreiben. MQ-Det hat den ersten Schritt in der multimodalen Abfrage gemacht und seine deutliche Leistungsverbesserung zeigt auch das enorme Potenzial der multimodalen Abfragezielerkennung. Gleichzeitig bietet die Einführung von Textbeschreibungen und visuellen Beispielen den Benutzern mehr Auswahlmöglichkeiten, wodurch die Zielerkennung flexibler und benutzerfreundlicher wird. 1.2 Multimodale Plug-and-Play-Abfragemodellarchitektur von MQ-Det
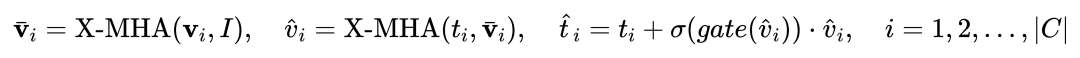 Für das i-te Kategorie, Eingabe Das visuelle Beispiel Vi führt zunächst eine Queraufmerksamkeit
Für das i-te Kategorie, Eingabe Das visuelle Beispiel Vi führt zunächst eine Queraufmerksamkeit 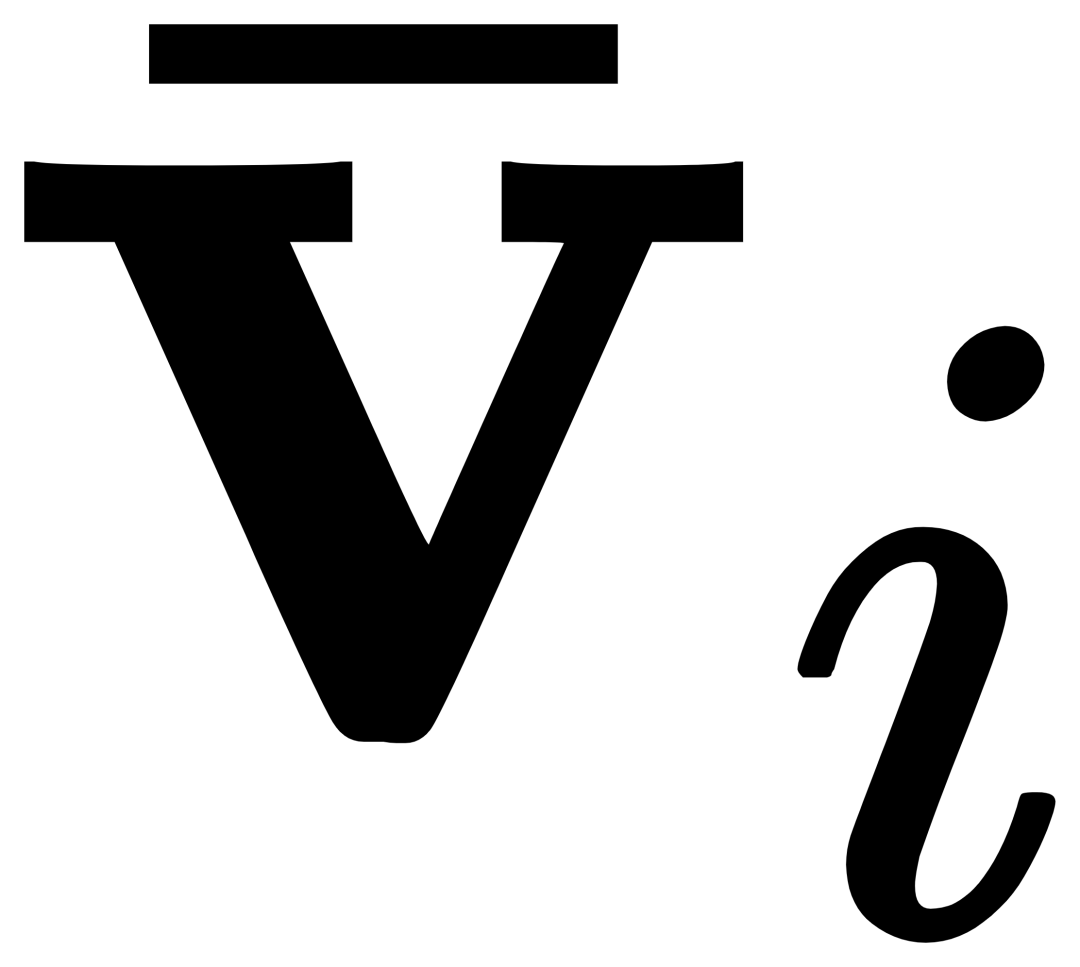 zu erhalten, und fusionieren Sie dann den Originaltext ti und den visuell erweiterten Text
zu erhalten, und fusionieren Sie dann den Originaltext ti und den visuell erweiterten Text 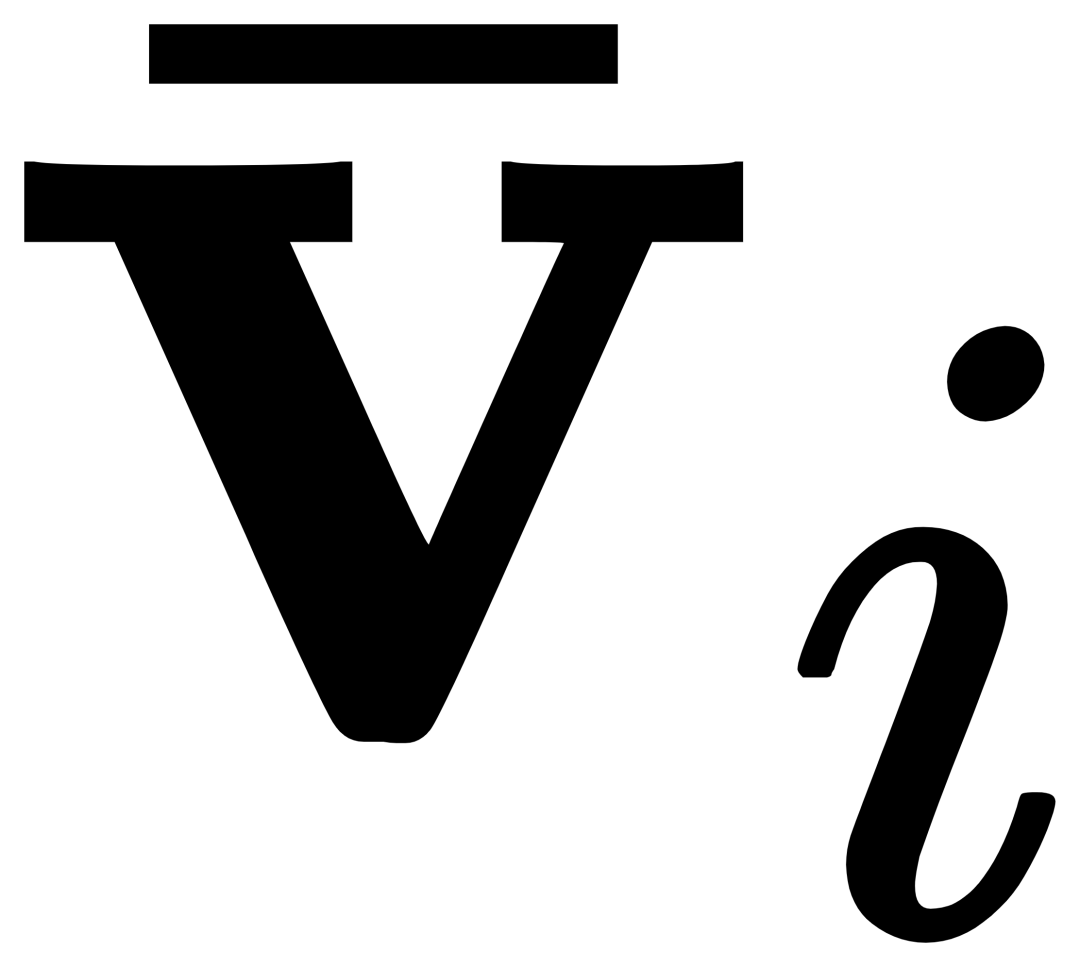 durch ein Gating-Modul-Gate, um die Ausgabe der aktuellen Ebene
durch ein Gating-Modul-Gate, um die Ausgabe der aktuellen Ebene 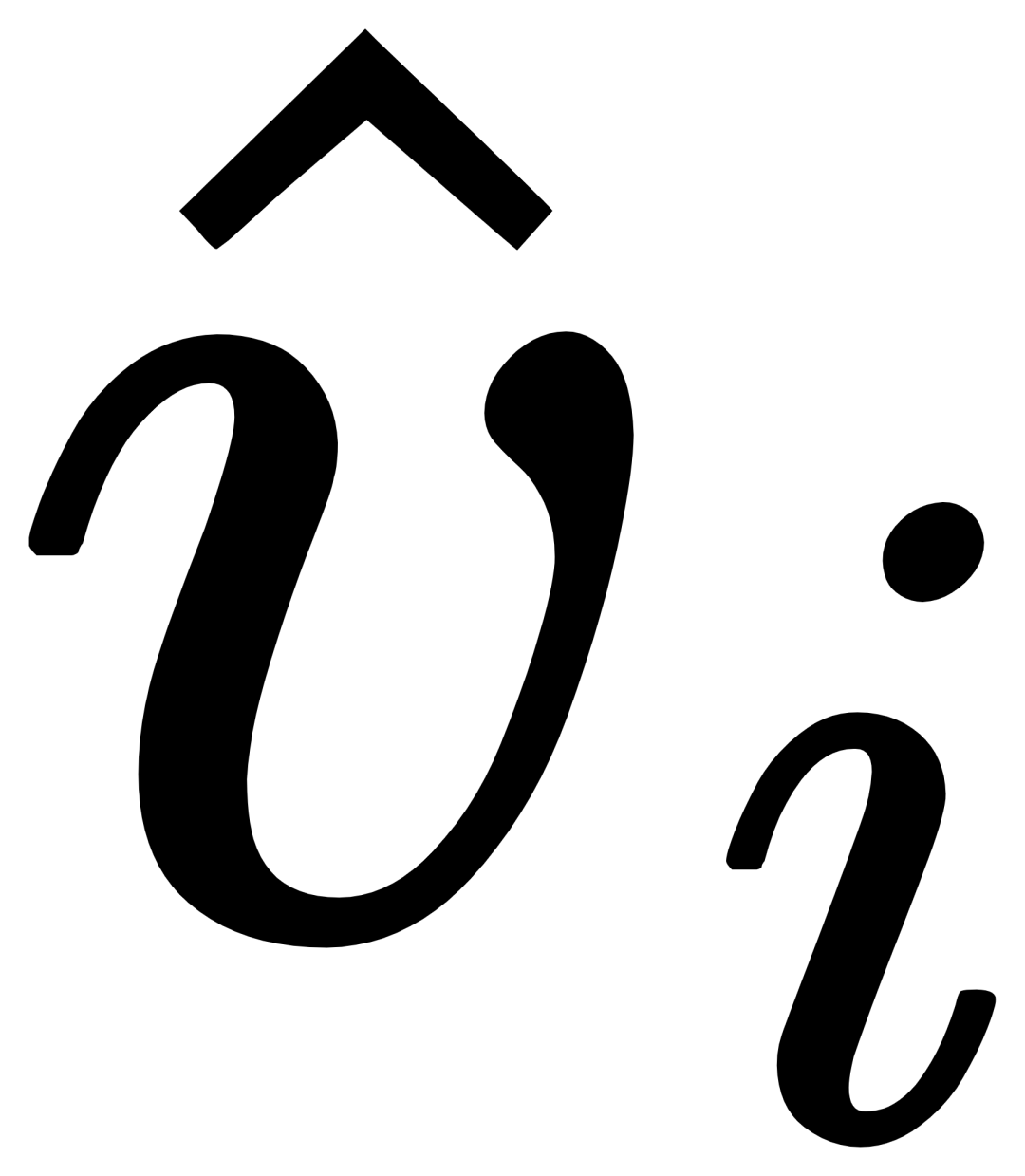 zu erhalten. Ein solch einfaches Design folgt drei Prinzipien: (1) Skalierbarkeit der Kategorie; (2) Semantische Vervollständigung;
zu erhalten. Ein solch einfaches Design folgt drei Prinzipien: (1) Skalierbarkeit der Kategorie; (2) Semantische Vervollständigung; 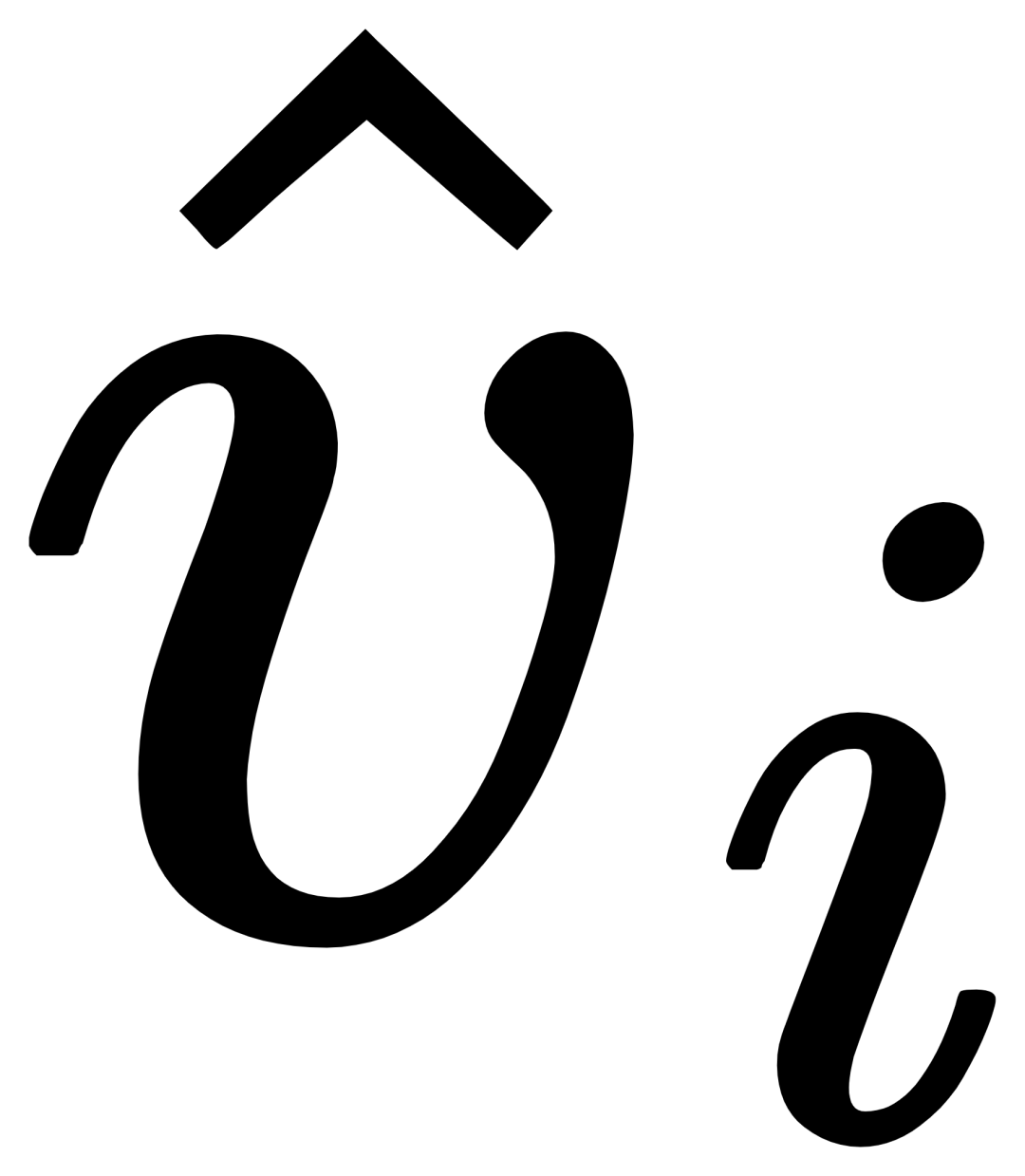
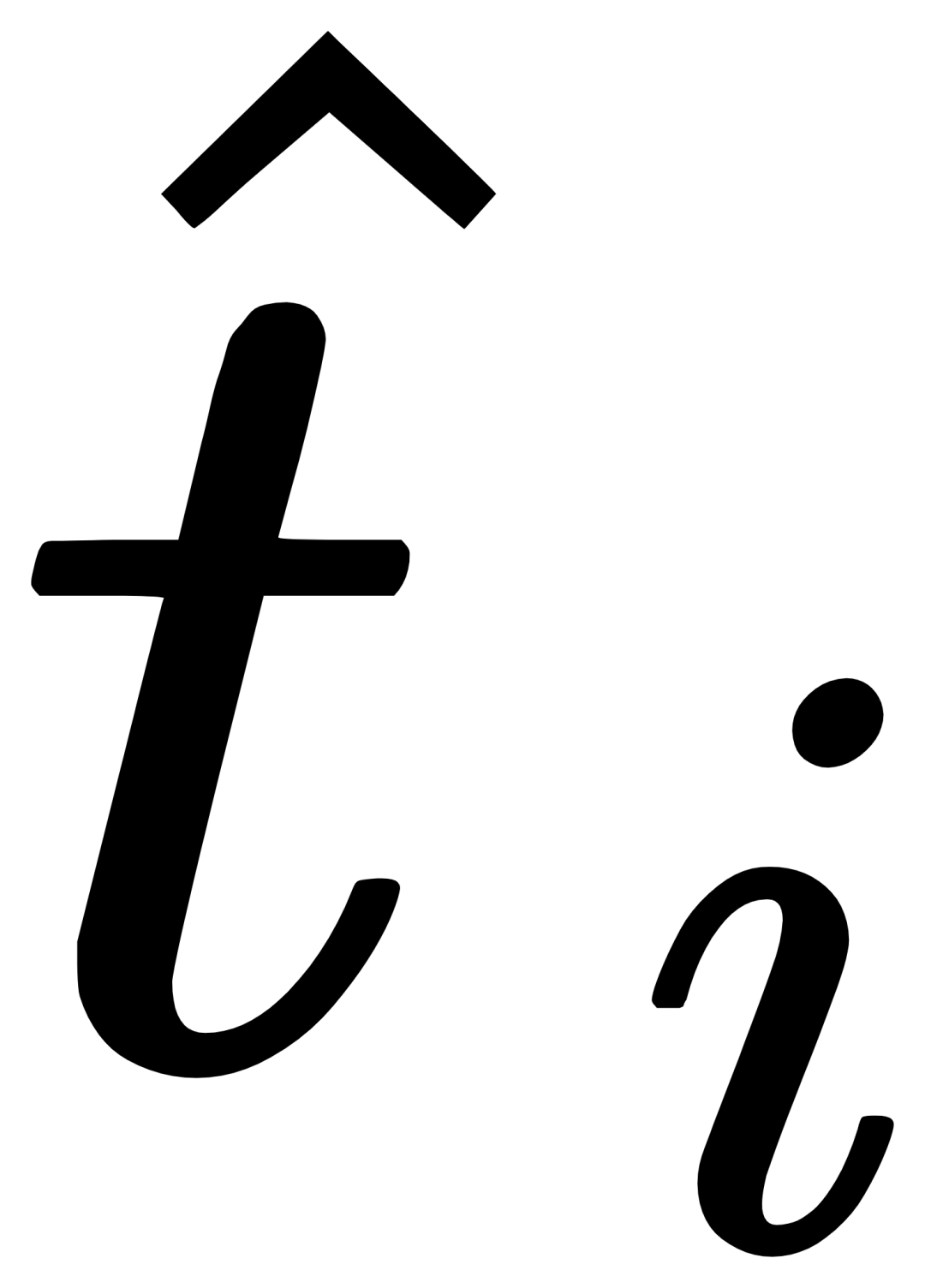 1.3 MQ-Det effiziente Trainingsstrategie
1.3 MQ-Det effiziente Trainingsstrategie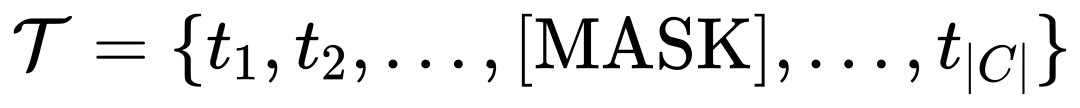 Diese Strategie ist einfach, aber sehr effektiv. Experimentelle Ergebnisse zeigen, dass diese Strategie erhebliche Leistungsverbesserungen mit sich bringt.
Diese Strategie ist einfach, aber sehr effektiv. Experimentelle Ergebnisse zeigen, dass diese Strategie erhebliche Leistungsverbesserungen mit sich bringt. 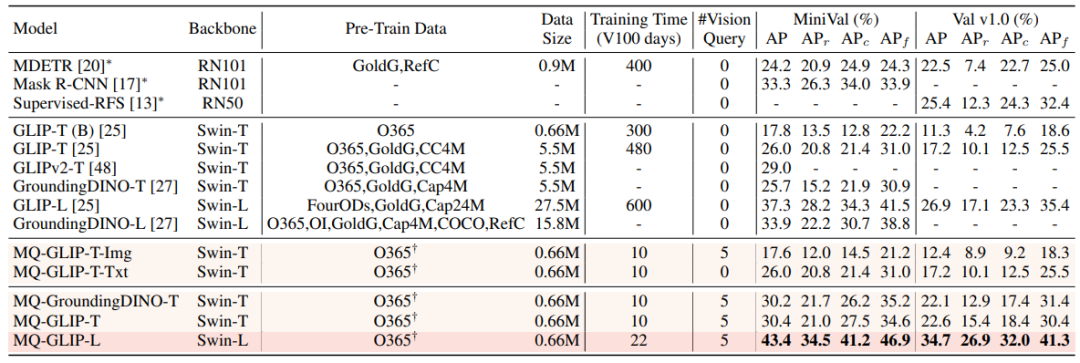
1.5 Experimentelle Ergebnisse: Few-Shot-Bewertung
1.6 Die Aussicht auf eine multimodale Abfragezielerkennung
Das obige ist der detaillierte Inhalt vonSchauen wir uns Bilder großer Models effektiver an als das Tippen! Neue Forschung in NeurIPS 2023 schlägt eine multimodale Abfragemethode vor, die die Genauigkeit um 7,8 % erhöht. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was sind die drei Datenmodelle der Datenbank?
- Was sind die drei gängigen Datenbankdatenmodelle?
- So importieren Sie das Layout eines CAD-Modells
- Wie läuft beim Datenbankdesign die Konvertierung eines ER-Diagramms in ein relationales Datenmodell ab?
- Welches Farbmodell wird von Computermonitoren verwendet?