
Heim >Technologie-Peripheriegeräte >KI >Die LLaMA2-Kontextlänge steigt sprunghaft auf 1 Million Token, wobei nur ein Hyperparameter angepasst werden muss.
Die LLaMA2-Kontextlänge steigt sprunghaft auf 1 Million Token, wobei nur ein Hyperparameter angepasst werden muss.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-10-21 14:25:01638Durchsuche
Mit nur wenigen Änderungen kann die Kontextgröße für die Unterstützung großer Modelle von 16.000 Token auf 1 Million erweitert werden? !
Immer noch auf LLaMA 2, das nur 7 Milliarden Parameter hat.
Sie müssen wissen, dass selbst die derzeit beliebten Claude 2 und GPT-4 Kontextlängen von nur 100.000 und 32.000 unterstützen. Über diesen Bereich hinaus werden große Modelle anfangen, Unsinn zu reden und sich nicht mehr an Dinge erinnern zu können.
Jetzt hat eine neue Studie der Fudan-Universität und des Shanghai Artificial Intelligence Laboratory nicht nur einen Weg gefunden, die Länge des Kontextfensters für eine Reihe großer Modelle zu erhöhen, sondern auch die Regeln entdeckt.

Gemäß dieser Regel muss nur 1 Hyperparameter angepasst werden, kann den Ausgabeeffekt sicherstellen und gleichzeitig die Extrapolationsleistung großer Modelle stabil verbessern.
Extrapolation bezieht sich auf die Änderung der Ausgabeleistung, wenn die Eingabelänge des großen Modells die Länge des vorab trainierten Textes überschreitet. Wenn die Extrapolationsfähigkeit nicht gut ist, wird das große Modell „Unsinn reden“, sobald die Eingabelänge die Länge des vorab trainierten Textes überschreitet.
Was genau kann es also die Extrapolationsfähigkeiten großer Modelle verbessern und wie gelingt das?
„Mechanismus“ zur Verbesserung der Extrapolationsfähigkeiten großer Modelle
Diese Methode zur Verbesserung der Extrapolationsfähigkeiten großer Modelle hängt mit dem Modul „Positional Encoding“ in der Transformer-Architektur zusammen. Tatsächlich kann das Modul des einfachen Aufmerksamkeitsmechanismus (Aufmerksamkeit) keine Token in unterschiedlichen Positionen unterscheiden. Beispielsweise gibt es in seinen Augen keinen Unterschied zwischen „Ich esse Äpfel“ und „Äpfel fressen mich“.
Daher muss eine Positionskodierung hinzugefügt werden, damit die Informationen zur Wortreihenfolge verstanden und die Bedeutung eines Satzes wirklich verstanden werden können.
Die aktuellen Transformer-Positionskodierungsmethoden umfassen die absolute Positionskodierung (Integration von Positionsinformationen in die Eingabe), die relative Positionskodierung (Schreiben von Positionsinformationen in die Berechnung des Aufmerksamkeitswerts) und die Rotationspositionskodierung. Unter ihnen ist die Rotationspositionskodierung am beliebtesten, nämlich
RoPE. RoPE erreicht den Effekt der relativen Positionscodierung durch absolute Positionscodierung, kann jedoch im Vergleich zur relativen Positionscodierung das Extrapolationspotenzial großer Modelle besser verbessern.
Wie man die Extrapolationsfähigkeiten großer Modelle mithilfe der RoPE-Positionscodierung weiter stimulieren kann, ist ebenfalls zu einer neuen Richtung vieler neuerer Studien geworden.
Diese Studien sind hauptsächlich in zwei große Schulen unterteilt:
Aufmerksamkeit einschränkenund Drehwinkel anpassen. Repräsentative Forschung zur Einschränkung der Aufmerksamkeit umfasst ALiBi, xPos, BCA usw. Das kürzlich vom MIT vorgeschlagene StreamingLLM kann es großen Modellen ermöglichen, eine unendliche Eingabelänge zu erreichen (erhöht jedoch nicht die Länge des Kontextfensters), was zu der Art der Forschung in dieser Richtung gehört.
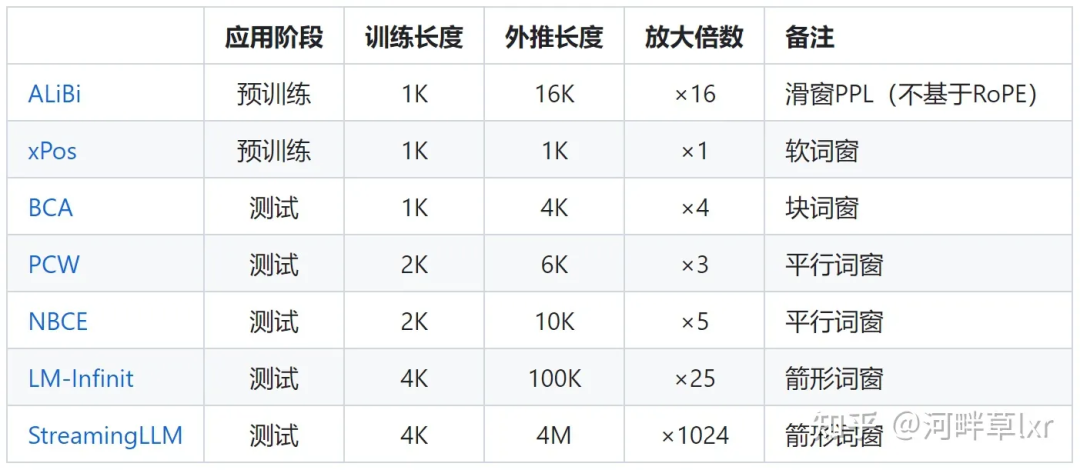 △Der Autor der Bildquelle
△Der Autor der Bildquelle
hat mehr Arbeit, um den Drehwinkel anzupassen. Typische Vertreter wie lineare Interpolation, Giraffe, Code LLaMA, LLaMA2 Long usw. gehören alle zu dieser Art von Forschung.
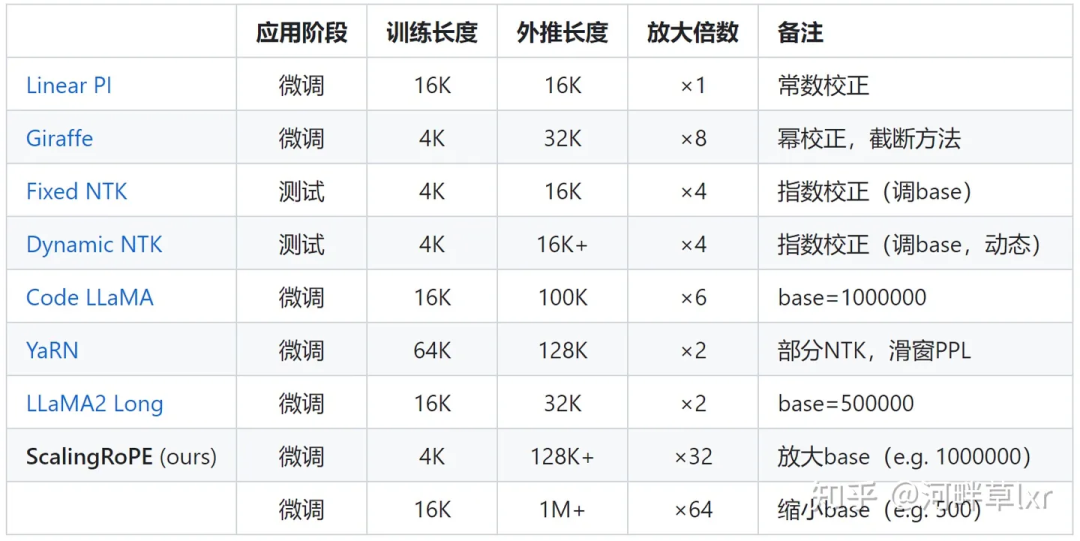 △Bildquellenautor
△Bildquellenautor
Am Beispiel von Metas kürzlich beliebter LLaMA2 Long-Forschung wurde eine Methode namens RoPE ABF vorgeschlagen, die die Kontextlänge großer Modelle durch Modifizieren eines Hyperparameters erfolgreich auf
32.000 Token verlängerte .Dieser Hyperparameter ist genau der „Schalter“
, der von Studien wie Code LLaMA und LLaMA2 Long entdeckt wurde –die Basis des Rotationswinkels
(Basis).Nehmen Sie einfach eine Feinabstimmung vor, um eine verbesserte Extrapolationsleistung großer Modelle sicherzustellen.
Aber egal, ob es sich um Code LLaMA oder LLaMA2 Long handelt, sie werden nur auf einer bestimmten Basis und fortlaufenden Trainingsdauer feinabgestimmt, um ihre Extrapolationsfähigkeiten zu verbessern. Können wir eine Regel finden, um sicherzustellen, dassalle
großen Modelle, die die RoPE-Positionscodierung verwenden, die Extrapolationsleistung stabil verbessern können?Beherrschen Sie diese Regel, der Kontext ist einfach 100w+
Forscher der Fudan-Universität und des Shanghai AI Research Institute führten Experimente zu diesem Problem durch. Sie analysierten zunächst mehrere Parameter, die sich auf die RoPE-Extrapolationsfähigkeiten auswirken, und schlugen ein Konzept namensCritical Dimension
(Kritische Dimension) vor. Anschließend fassten sie auf der Grundlage dieses Konzepts eine Reihe vonRoPE-Extrapolationsskalierungsgesetzen der RoPE-basierten Extrapolation zusammen. Wenden Sie einfach dieses Gesetz an, um sicherzustellen, dass jedes große Modell, das auf der RoPE-Positionskodierung basiert, die Extrapolationsfähigkeiten verbessern kann.
Schauen wir uns zunächst an, was die kritische Dimension ist.
Aus der Definition geht hervor, dass es mit der Textlänge Ttrain vor dem Training, der Anzahl der Selbstaufmerksamkeitskopfdimensionen d und anderen Parametern zusammenhängt. Die spezifische Berechnungsmethode ist wie folgt:
Unter diesen ist 10000 der „Anfangswert“ des Hyperparameters und der Rotationswinkelbasis.
Der Autor stellte fest, dass unabhängig davon, ob die Basis vergrößert oder verkleinert wird, die Extrapolationsfähigkeit des großen Modells basierend auf RoPE letztendlich verbessert werden kann. Wenn die Rotationswinkelbasis dagegen 10000 beträgt, beträgt die Extrapolationsfähigkeit des großen Modells das Schlimmste.
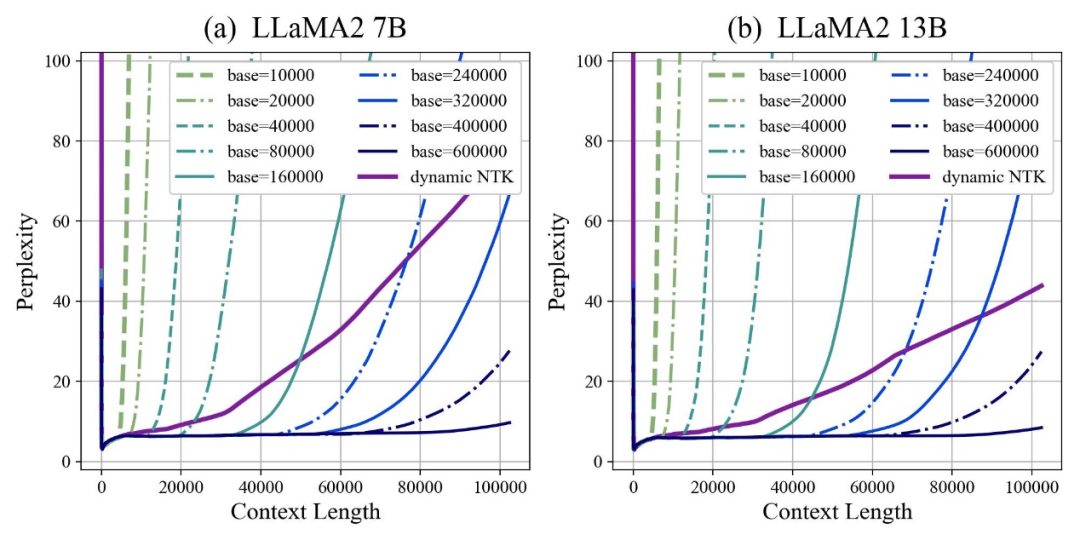
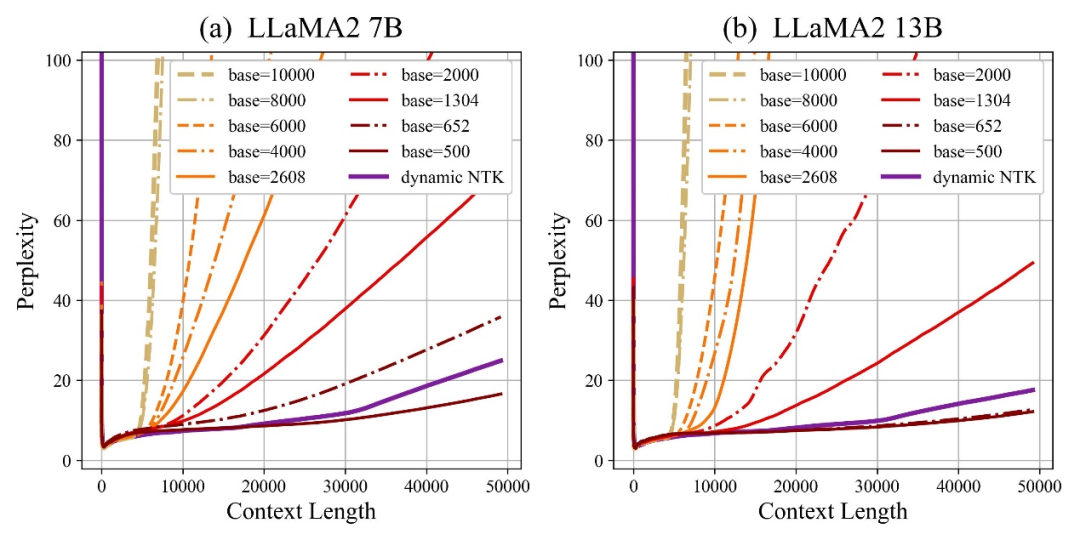
In diesem Artikel wird davon ausgegangen, dass eine kleinere Basis des Rotationswinkels die Wahrnehmung von Positionsinformationen in mehr Dimensionen ermöglichen kann und eine größere Basis des Rotationswinkels längere Positionsinformationen ausdrücken kann.
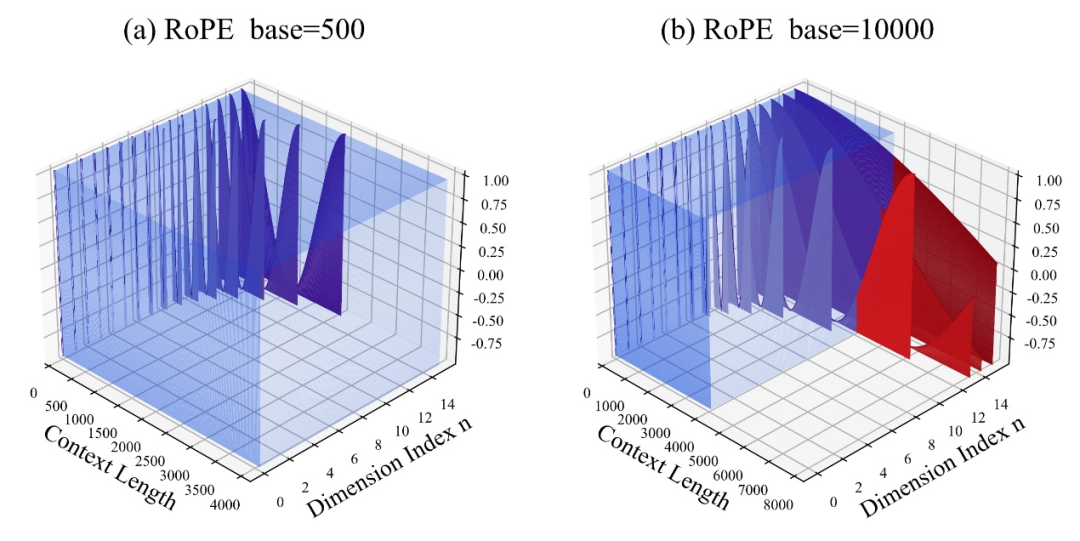
In diesem Fall sollte bei kontinuierlichen Trainingskorpora unterschiedlicher Länge um wie viel Rotationswinkelbasis verkleinert und vergrößert werden, um sicherzustellen, dass die Extrapolationsfähigkeit großer Modelle maximiert wird?
Das Papier gibt eine Skalierungsregel für die erweiterte RoPE-Extrapolation an, die sich auf Parameter wie kritische Abmessungen, fortlaufende Trainingstextlänge und Vortrainingstextlänge großer Modelle bezieht:

Basierend auf dieser Regel werden verschiedene Vor- Durch Training und Fortsetzen des Trainings kann die Textlänge direkt berechnet werden, um die Extrapolationsleistung des großen Modells direkt zu berechnen, mit anderen Worten, um die vom großen Modell unterstützte Kontextlänge vorherzusagen.
Umgekehrt kann man anhand dieser Regel schnell ableiten, wie man die Drehwinkelbasis am besten anpasst und so die Extrapolationsleistung großer Modelle verbessert.
Der Autor hat diese Aufgabenreihe getestet und festgestellt, dass experimentell die Eingabe einer Länge von 100.000, 500.000 oder sogar 1 Million Token sicherstellen kann, dass die Extrapolation ohne zusätzliche Aufmerksamkeitseinschränkungen erreicht werden kann.
Gleichzeitig hat die Arbeit an der Verbesserung der Extrapolationsfähigkeiten großer Modelle, einschließlich Code LLaMA und LLaMA2 Long, bewiesen, dass diese Regel tatsächlich sinnvoll und effektiv ist.
Auf diese Weise müssen Sie nur „einen Parameter anpassen“ gemäß dieser Regel und können die Kontextfensterlänge des großen Modells basierend auf RoPE problemlos erweitern und die Extrapolationsfähigkeit verbessern.
Liu Xiaoran, der erste Autor des Papiers, sagte, dass diese Forschung derzeit die Auswirkungen auf nachgelagerte Aufgaben durch die Verbesserung des kontinuierlichen Trainingskorpus verbessert. Nach Abschluss werden der Code und das Modell als Open Source verfügbar sein
Papieradresse:
https://arxiv.org/abs/2310.05209
Github-Repository:
https://github.com/OpenLMLab/scaling-rope
Papieranalyse Blog:
https:// zhuanlan.zhihu.com/p/660073229
Das obige ist der detaillierte Inhalt vonDie LLaMA2-Kontextlänge steigt sprunghaft auf 1 Million Token, wobei nur ein Hyperparameter angepasst werden muss.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!