
Heim >Technologie-Peripheriegeräte >KI >3D-Composite-Videos in 4K-Qualität frieren in Diashows nicht mehr ein und die neue Methode erhöht die Rendergeschwindigkeit um mehr als das 30-fache
3D-Composite-Videos in 4K-Qualität frieren in Diashows nicht mehr ein und die neue Methode erhöht die Rendergeschwindigkeit um mehr als das 30-fache

- 王林nach vorne
- 2023-10-19 14:21:04641Durchsuche
Während 60-Frame-Videos in 4K-Qualität nur von Mitgliedern einiger APPs angesehen werden können, haben KI-Forscher bereits dynamische 3D-Synthesevideos auf 4K-Niveau erreicht, und das Bild ist recht flüssig.


Im wirklichen Leben sind die meisten Videos, mit denen wir in Kontakt kommen, 2D. Wenn wir diese Art von Video ansehen, haben wir keine Möglichkeit, den Betrachtungswinkel zu wählen, z. B. zwischen den Schauspielern hindurchzugehen oder in eine Ecke des Raums zu gehen. Das Aufkommen von VR- und AR-Geräten hat diesen Mangel ausgeglichen. Die von ihnen bereitgestellten 3D-Videos ermöglichen es uns, unsere Perspektive zu ändern und uns sogar nach Belieben zu bewegen, was das Gefühl des Eintauchens erheblich verbessert.
Allerdings war die Synthese einer solchen dynamischen 3D-Szene schon immer eine Schwierigkeit, sowohl im Hinblick auf die Bildqualität als auch auf die Glätte.
Kürzlich haben Forscher der Zhejiang-Universität, der Xiangyan Technology und der Ant Group dieses Problem in Frage gestellt. In einem Artikel mit dem Titel „4K4D: Echtzeit-4D-Ansichtssynthese mit 4K-Auflösung“ schlugen sie eine Punktwolkendarstellungsmethode namens 4K4D vor, die die Rendergeschwindigkeit der hochauflösenden dynamischen 3D-Szenensynthese erheblich verbessert. Insbesondere kann ihre Methode mit einer RTX 4090-GPU mit einer 4K-Auflösung und einer Bildrate von bis zu 80 FPS und mit einer 1080p-Auflösung und einer Bildrate von bis zu 400 FPS rendern. Insgesamt ist es mehr als 30-mal schneller als die vorherige Methode und die Rendering-Qualität erreicht SOTA.

Das Folgende ist die Einleitung des Papiers.
Papierübersicht

- Papierlink: https://arxiv.org/pdf/2310.11448.pdf
- Projektlink: https ://z ju3dv. github .io/4k4d/
Die dynamische Ansichtssynthese zielt darauf ab, dynamische 3D-Szenen aus aufgenommenen Videos zu rekonstruieren und immersive virtuelle Wiedergaben zu erstellen, was ein langfristiges Forschungsproblem im Bereich Computer Vision und Computergrafik darstellt. Der Schlüssel zum Nutzen dieser Technologie liegt in ihrer Fähigkeit, in Echtzeit mit hoher Wiedergabetreue zu rendern, was den Einsatz in VR/AR, Sportübertragungen und der Erfassung künstlerischer Darbietungen ermöglicht. Herkömmliche Ansätze stellen dynamische 3D-Szenen als Sequenzen texturierter Netze dar und verwenden komplexe Hardware, um sie zu rekonstruieren. Daher sind sie normalerweise auf kontrollierte Umgebungen beschränkt.
In letzter Zeit haben implizite neuronale Darstellungen große Erfolge bei der Rekonstruktion dynamischer 3D-Szenen aus RGB-Videos durch differenzierbares Rendering erzielt. Beispielsweise modelliert „Neuronale 3D-Videosynthese aus Multi-View-Video“ die Zielszene als dynamisches Strahlungsfeld, synthetisiert das Bild mithilfe von Volumenrendering und vergleicht und optimiert es mit dem Eingabebild. Trotz der beeindruckenden Ergebnisse der dynamischen Ansichtssynthese benötigen bestehende Methoden aufgrund der teuren Netzwerkauswertung oft Sekunden oder sogar Minuten, um ein Bild mit einer Auflösung von 1080p zu rendern.
Inspiriert durch statische Ansichtssynthesemethoden verbessern einige dynamische Ansichtssynthesemethoden die Rendering-Geschwindigkeit, indem sie die Kosten oder die Anzahl der Netzwerkauswertungen reduzieren. Durch diese Strategien ist MLP Maps in der Lage, dynamische Figuren im Vordergrund mit 41,7 fps darzustellen. Es bestehen jedoch weiterhin Herausforderungen bei der Rendergeschwindigkeit, da die Echtzeitleistung von MLP Maps nur bei der Zusammenstellung von Bildern mit mäßiger Auflösung (384 x 512) erreicht werden kann. Beim Rendern eines Bildes mit 4K-Auflösung verlangsamte es sich auf nur 1,3 FPS.
In diesem Artikel schlagen Forscher eine neue neuronale Darstellung – 4K4D – zum Modellieren und Rendern dynamischer 3D-Szenen vor. Wie in Abbildung 1 dargestellt, übertrifft 4K4D frühere Methoden der dynamischen Ansichtssynthese in puncto Rendering-Geschwindigkeit deutlich und ist gleichzeitig in puncto Rendering-Qualität konkurrenzfähig.

Die Autoren gaben an, dass ihre Kerninnovation in der 4D-Punktwolkendarstellung und dem hybriden Erscheinungsbildmodell liegt. Insbesondere für dynamische Szenen verwenden sie einen Space-Carving-Algorithmus, um eine grobe Punktwolkensequenz zu erhalten und die Position jedes Punkts als lernbaren Vektor zu modellieren. Sie führten außerdem ein 4D-Merkmalsgitter ein, um jedem Punkt Merkmalsvektoren zuzuweisen, und speisten es in das MLP-Netzwerk ein, um den Radius, die Dichte und die sphärischen Harmonischen (SH)-Koeffizienten der Punkte vorherzusagen. 4D-Feature-Netze wenden auf natürliche Weise eine räumliche Regularisierung auf die Punktwolke an, wodurch die Optimierung robuster wird. Basierend auf 4K4D entwickelten Forscher einen differenzierbaren Tiefenpeeling-Algorithmus, der Hardware-Rasterisierung nutzt, um beispiellose Rendering-Geschwindigkeiten zu erreichen.
Forscher fanden heraus, dass das MLP-basierte SH-Modell das Erscheinungsbild dynamischer Szenen nur schwer darstellen kann. Um dieses Problem zu lösen, führten sie außerdem ein Bildmischungsmodell ein, das mit dem SH-Modell kombiniert wird, um das Erscheinungsbild der Szene darzustellen. Ein wichtiger Entwurf besteht darin, das Bildmischungsnetzwerk unabhängig von der Blickrichtung zu machen, sodass es nach dem Training vorberechnet werden kann, um die Rendering-Geschwindigkeit zu verbessern. Als zweischneidiges Schwert macht diese Strategie das Bildmischungsmodell entlang der Betrachtungsrichtung diskret. Dieses Problem kann durch ein kontinuierliches SH-Modell behoben werden. Im Vergleich zum 3D-Gaußschen Splatting, das nur SH-Modelle verwendet, nutzt das von den Forschern vorgeschlagene Hybrid-Erscheinungsmodell die vom Eingabebild erfassten Informationen vollständig aus und verbessert so effektiv die Rendering-Qualität.
Um die Wirksamkeit der neuen Methode zu überprüfen, bewerteten die Forscher 4K4D anhand mehrerer weit verbreiteter dynamischer Mehransichts-Synthesedatensätze mit neuen Ansichten, darunter NHR, ENeRF-Outdoo, DNA-Rendering und Neural3DV. Umfangreiche Experimente haben gezeigt, dass 4K4D nicht nur um Größenordnungen schneller in der Rendering-Geschwindigkeit ist, sondern auch in Bezug auf die Rendering-Qualität deutlich besser als die SOTA-Technologie. Mit einer RTX 4090-GPU erreicht die neue Methode 400 FPS beim DNA-Rendering-Datensatz bei 1080p-Auflösung und 80 FPS beim ENeRF-Outdoor-Datensatz bei 4k-Auflösung.
Einführung in die Methode
Anhand eines Multi-View-Videos, das eine dynamische 3D-Szene aufnimmt, zielt dieser Artikel darauf ab, die Zielszene zu rekonstruieren und eine Ansichtssynthese in Echtzeit durchzuführen. Das Modellarchitekturdiagramm ist in Abbildung 2 dargestellt:
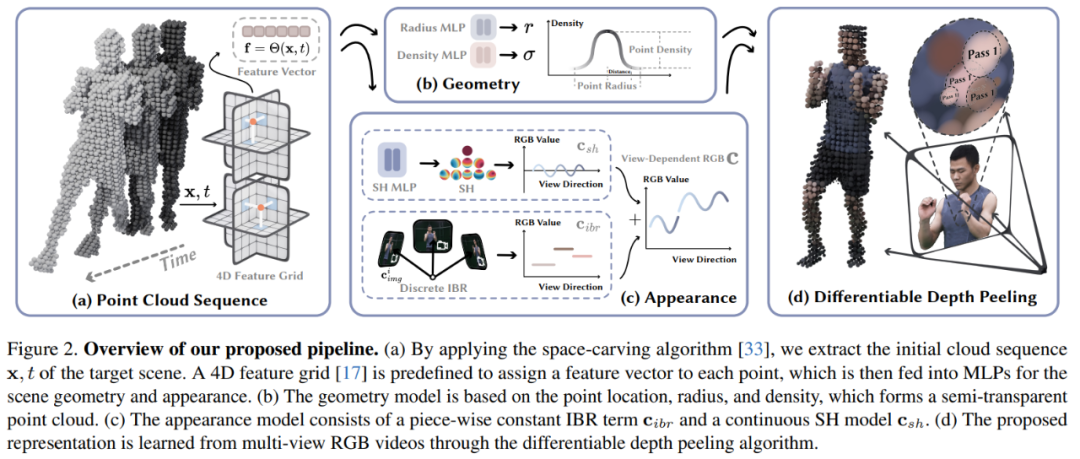
Dann stellt der Artikel das relevante Wissen zur Verwendung von Punktwolken zur Modellierung dynamischer Szenen vor. Sie beginnen aus der Perspektive der 4D-Einbettung, des geometrischen Modells und des Erscheinungsmodells.
4D-Einbettung: In diesem Artikel werden anhand einer groben Punktwolke einer Zielszene neuronale Netze und Merkmalsnetze verwendet, um deren dynamische Geometrie und Erscheinung darzustellen. Insbesondere definiert dieser Artikel zunächst sechs Feature-Ebenen θ_xy, θ_xz, θ_yz, θ_tx, θ_ty und θ_tz und verwendet die K-Planes-Strategie, um diese sechs Ebenen zum Modellieren eines 4D-Feature-Feldes Θ(x, t) zu verwenden:
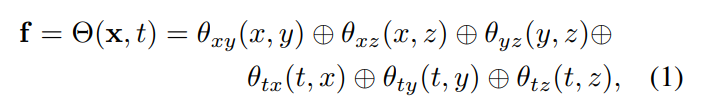
Geometrisches Modell: Basierend auf der groben Punktwolke wird die dynamische Szenengeometrie durch das Lernen von drei Attributen (Einträgen) für jeden Punkt dargestellt, nämlich Position p ∈ R^3, Radius r ∈ R und Dichte σ ∈ R. Anschließend wird mit Hilfe dieser Punkte die Volumendichte des Punktes x im Raum berechnet. Die Punktposition p wird als optimierbarer Vektor modelliert. Der Radius r und die Dichte σ werden vorhergesagt, indem der Merkmalsvektor f in Gleichung (1) in das MLP-Netzwerk eingespeist wird.
Erscheinungsmodell: Wie in Abbildung 2c gezeigt, verwendet dieser Artikel die Bildmischungstechnologie und das sphärische harmonische Funktionsmodell (SH), um ein hybrides Erscheinungsmodell zu erstellen, wobei die Bildmischungstechnologie das diskrete Ansichtserscheinungsbild c_ibr und das SH-Modell darstellt stellt das kontinuierliche ansichtsabhängige Erscheinungsbild dar. Das Erscheinungsbild von c_sh. Für Punkt mithilfe des Tiefenpeeling-Algorithmus in ein Bild umwandeln.
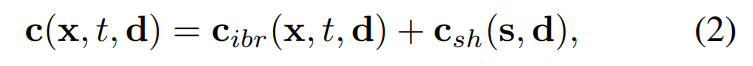 Die Forscher entwickelten einen benutzerdefinierten Shader, um den aus K Rendering-Durchgängen bestehenden Tiefenpeeling-Algorithmus zu implementieren. Das heißt, für ein bestimmtes Pixel u führte der Forscher eine mehrstufige Verarbeitung durch. Nach K Renderings erhielt das Pixel u schließlich einen Satz von Sortierpunkten {x_k|k = 1, ..., K}.
Die Forscher entwickelten einen benutzerdefinierten Shader, um den aus K Rendering-Durchgängen bestehenden Tiefenpeeling-Algorithmus zu implementieren. Das heißt, für ein bestimmtes Pixel u führte der Forscher eine mehrstufige Verarbeitung durch. Nach K Renderings erhielt das Pixel u schließlich einen Satz von Sortierpunkten {x_k|k = 1, ..., K}.
Basierend auf diesen Punkten {x_k|k = 1, ..., K} wird die Farbe des Pixels u beim Volumenrendering ausgedrückt als:
Während des Trainingsprozesses wird die gerenderte Pixelfarbe C (u) in diesem Artikel mit der realen Pixelfarbe C_gt (u) verglichen und das Modell durchgängig mithilfe der folgenden Verlustfunktion optimiert:
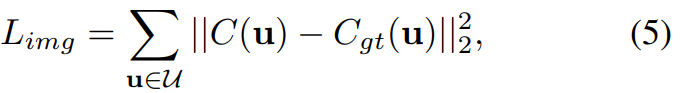
Darüber hinaus gilt dieser Artikel auch für Wahrnehmungsverlust:
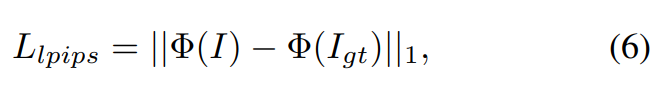
und Maskenverlust:
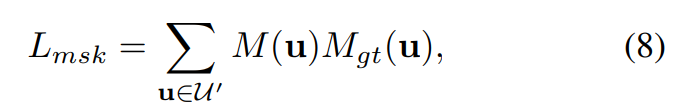
Die endgültige Verlustfunktion ist definiert als:
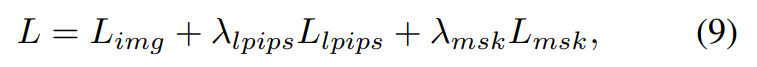
Experimentieren und Ergebnisse
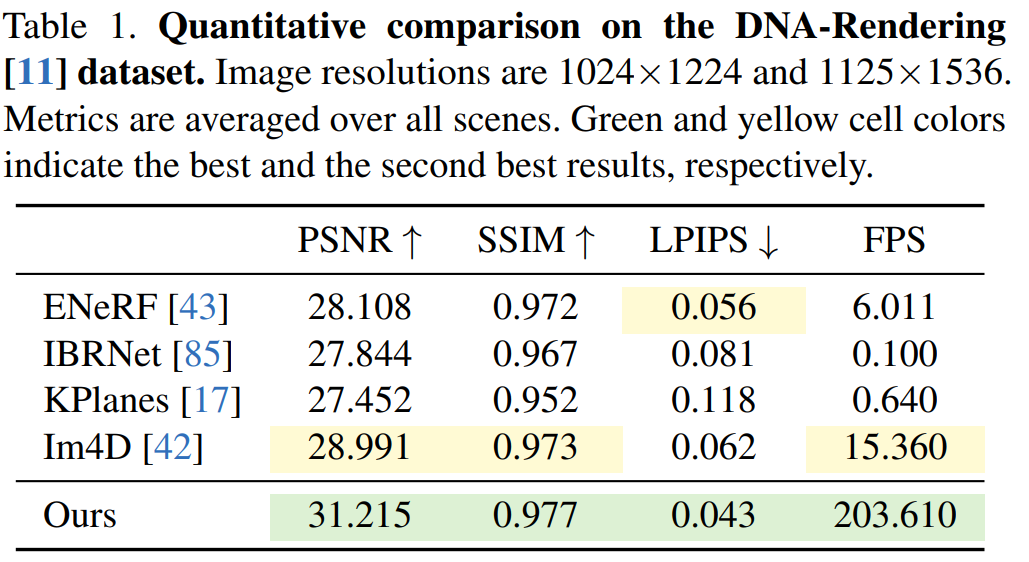
In diesem Artikel wird die 4K4D-Methode anhand von DNA-Rendering-, ENeRF-Outdoor-, NHR- und Neural3DV-Datensätzen bewertet. Die Ergebnisse von
für den DNA-Rendering-Datensatz sind in Tabelle 1 aufgeführt. Die Ergebnisse zeigen, dass die 4K4D-Rendering-Geschwindigkeit mehr als 30-mal schneller ist als die von ENeRF mit SOTA-Leistung und die Rendering-Qualität besser ist.
Qualitative Ergebnisse des DNA-Rendering-Datensatzes sind in Abbildung 5 dargestellt. KPlanes kann das detaillierte Erscheinungsbild und die Geometrie dynamischer 4D-Szenen nicht wiederherstellen, während andere bildbasierte Methoden ein qualitativ hochwertiges Erscheinungsbild erzeugen. Allerdings führen diese Methoden tendenziell zu unscharfen Ergebnissen um Verdeckungen und Kanten herum, was zu einer verminderten visuellen Qualität führt, wohingegen 4K4D Renderings mit höherer Wiedergabetreue bei über 200 FPS erzeugen kann.

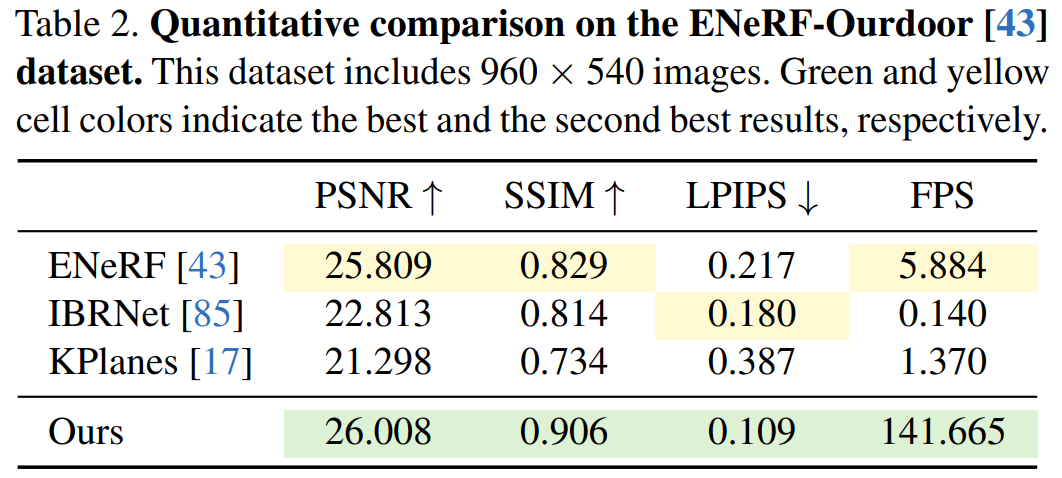
Als nächstes zeigen Experimente die qualitativen und quantitativen Ergebnisse verschiedener Methoden am ENeRFOutdoor-Datensatz. Wie Tabelle 2 zeigt, erzielte 4K4D beim Rendern mit über 140 FPS immer noch deutlich bessere Ergebnisse.
Während andere Methoden wie ENeRF zu unscharfen Ergebnissen führen, enthalten die Rendering-Ergebnisse von IBRNet schwarze Artefakte an den Bildrändern, wie in Abbildung 3 dargestellt .

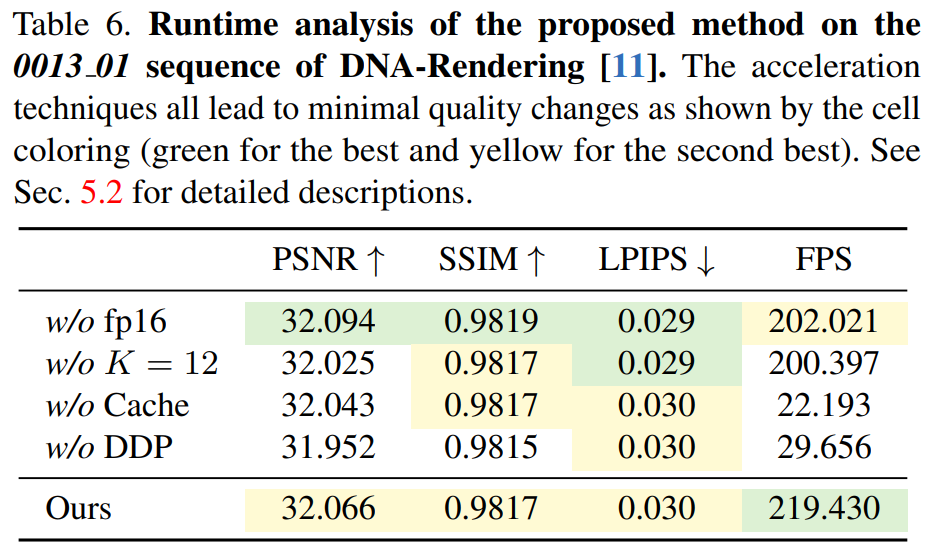
Tabelle 6 zeigt die Wirksamkeit des differenzierbaren Tiefenpeeling-Algorithmus, wobei 4K4D mehr als siebenmal schneller ist als die CUDA-basierte Methode.
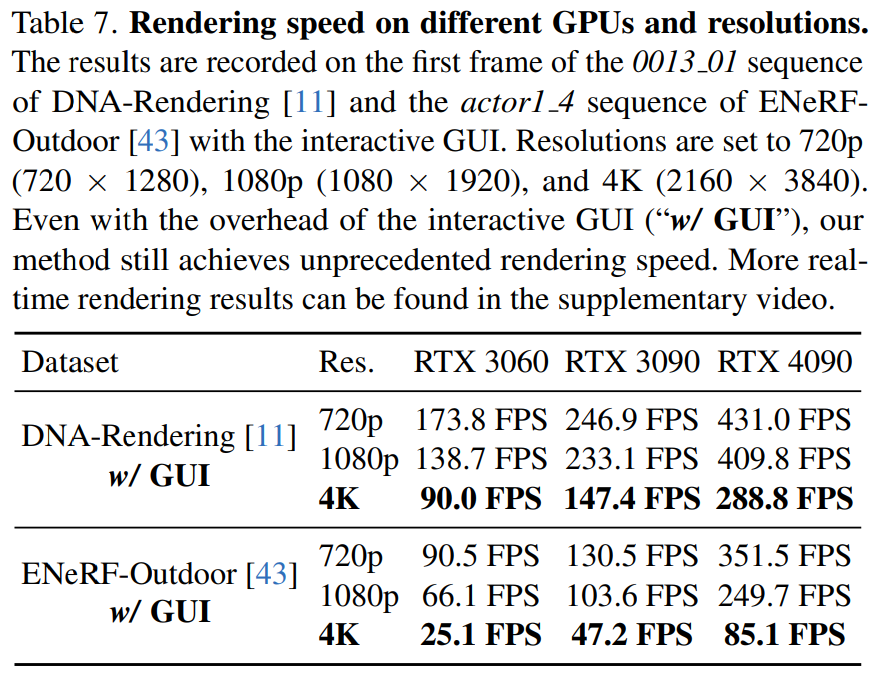
In diesem Artikel wird in Tabelle 7 auch die Rendering-Geschwindigkeit von 4K4D auf unterschiedlicher Hardware (RTX 3060, 3090 und 4090) bei unterschiedlichen Auflösungen angegeben.
Weitere Einzelheiten finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt von3D-Composite-Videos in 4K-Qualität frieren in Diashows nicht mehr ein und die neue Methode erhöht die Rendergeschwindigkeit um mehr als das 30-fache. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!