
Heim >Technologie-Peripheriegeräte >KI >Betrachten Sie LLM als ein Betriebssystem, es verfügt über unbegrenzten „virtuellen' Kontext, Berkeleys neues Werk hat 1,7.000 Sterne erhalten
Betrachten Sie LLM als ein Betriebssystem, es verfügt über unbegrenzten „virtuellen' Kontext, Berkeleys neues Werk hat 1,7.000 Sterne erhalten

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-10-19 12:21:111258Durchsuche
In den letzten Jahren sind große Sprachmodelle (LLMs) und die ihnen zugrunde liegende Transformatorarchitektur zum Eckpfeiler der Konversations-KI geworden und haben eine breite Palette von Verbraucher- und Unternehmensanwendungen hervorgebracht. Trotz erheblicher Fortschritte schränkt das von LLM verwendete Kontextfenster mit fester Länge die Anwendbarkeit auf lange Gespräche oder lange Dokumentbegründungen erheblich ein. Selbst bei den am weitesten verbreiteten Open-Source-LLMs ermöglicht ihre maximale Eingabelänge nur die Unterstützung einiger Dutzend Nachrichtenantworten oder kurzer Dokumentinferenzen.
Gleichzeitig führt die einfache Erweiterung der Kontextlänge des Transformators, begrenzt durch den Selbstaufmerksamkeitsmechanismus der Transformatorarchitektur, auch dazu, dass die Berechnungszeit und die Speicherkosten exponentiell ansteigen, was die neue Architektur mit langem Kontext zu einer dringenden Forschung macht Thema.
Selbst wenn wir die rechnerischen Herausforderungen der Kontextskalierung bewältigen können, zeigen neuere Untersuchungen, dass Modelle mit langem Kontext Schwierigkeiten haben, den zusätzlichen Kontext effektiv zu nutzen.
Wie kann man das lösen? Angesichts der enormen Ressourcen, die für das Training von SOTA LLM erforderlich sind, und der offensichtlich abnehmenden Erträge der Kontextskalierung benötigen wir dringend alternative Techniken, die lange Kontexte unterstützen. Forscher der University of California in Berkeley haben diesbezüglich neue Fortschritte erzielt.
In diesem Artikel untersuchen Forscher, wie man die Illusion eines unendlichen Kontexts erzeugen und gleichzeitig ein festes Kontextmodell verwenden kann. Ihr Ansatz greift Ideen aus dem Paging des virtuellen Speichers auf und ermöglicht es Anwendungen, Datensätze zu verarbeiten, die den verfügbaren Speicher bei weitem überschreiten.
Basierend auf dieser Idee nutzten die Forscher die neuesten Fortschritte bei den Funktionsaufruffunktionen von LLM-Agenten, um ein vom Betriebssystem inspiriertes LLM-System für die virtuelle Kontextverwaltung zu entwerfen – MemGPT.

Papier-Homepage: https://memgpt.ai/
arXiv-Adresse: https://arxiv.org/pdf/2310.08560.pdf
Das Projekt ist Open Source und hat 1,7.000 Sterne auf GitHub erhalten Menge.
GitHub-Adresse: https://github.com/cpacker/MemGPT
Methodenübersicht
Diese Forschung lässt sich von der hierarchischen Speicherverwaltung herkömmlicher Betriebssysteme in Kontextfenstern (ähnlich wie bei Betriebssystemen) inspirieren „Seiten“-Informationen zwischen „Hauptspeicher“) und externem Speicher ein- und auslagern. MemGPT ist für die Verwaltung des Kontrollflusses zwischen Speicher, LLM-Verarbeitungsmodulen und Benutzern verantwortlich. Dieses Design ermöglicht eine iterative Kontextänderung während einer einzelnen Aufgabe, sodass der Agent sein begrenztes Kontextfenster effizienter nutzen kann.
MemGPT behandelt Kontextfenster als eingeschränkte Speicherressourcen und entwirft eine hierarchische Struktur für LLM, ähnlich dem hierarchischen Speicher in herkömmlichen Betriebssystemen (Patterson et al., 1988). Um eine längere Kontextlänge bereitzustellen, ermöglicht diese Forschung LLM, in seinem Kontextfenster platzierte Inhalte über „LLM OS“ – MemGPT – zu verwalten. MemGPT ermöglicht es LLM, relevante historische Daten abzurufen, die im Kontext verloren gehen, ähnlich wie bei Seitenfehlern in Betriebssystemen. Darüber hinaus können Agenten den Inhalt eines einzelnen Aufgabenkontextfensters iterativ ändern, so wie ein Prozess wiederholt auf den virtuellen Speicher zugreifen kann.
MemGPT ermöglicht es LLM, unbegrenzte Kontexte zu verarbeiten, wenn das Kontextfenster begrenzt ist. Die Komponenten von MemGPT sind in Abbildung 1 unten dargestellt.
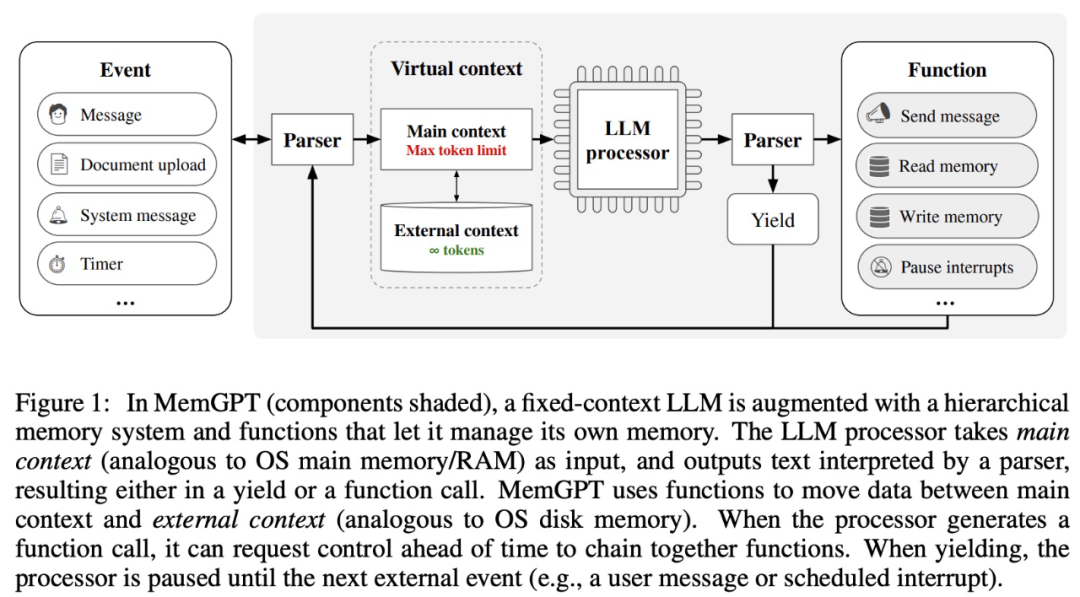
MemGPT koordiniert die Datenbewegung zwischen dem Hauptkontext (Inhalt im Kontextfenster) und dem externen Kontext durch Funktionsaufrufe, die automatisch auf der Grundlage des aktuellen Kontexts aktualisiert und abgerufen werden.


Es ist erwähnenswert, dass das Kontextfenster ein Warntoken verwenden muss, um seine Einschränkungen zu kennzeichnen, wie in Abbildung 3 unten dargestellt:

Experimente und Ergebnisse
Im experimentellen Teil bewerteten die Forscher MemGPT in zwei langen Kontextbereichen, nämlich Konversationsagenten und Dokumentenverarbeitung. Für Konversationsagenten erweiterten sie den bestehenden Multisitzungs-Chat-Datensatz (Xu et al. (2021)) und führten zwei neue Konversationsaufgaben ein, um die Fähigkeit des Agenten zu bewerten, Wissen in langen Gesprächen zu behalten. Für die Dokumentenanalyse vergleichen sie MemGPT mit den von Liu et al. (2023a) vorgeschlagenen Aufgaben, einschließlich der Beantwortung von Fragen und dem Abrufen von Schlüsselwerten langer Dokumente.
MemGPT für Konversationsagenten
Beim Gespräch mit dem Benutzer muss der Agent die folgenden zwei Schlüsselkriterien erfüllen.
Eine davon ist Konsistenz, das heißt, der Agent sollte die Kohärenz des Gesprächs aufrechterhalten und die bereitgestellten neuen Fakten, Referenzen und Ereignisse sollten mit den vorherigen Aussagen des Benutzers und des Agenten übereinstimmen.
Die zweite Möglichkeit ist die Teilnahme, das heißt, der Agent sollte das Langzeitwissen des Benutzers nutzen, um die Antwort zu personalisieren. Wenn Sie sich auf frühere Gespräche beziehen, kann das Gespräch natürlicher und spannender werden.
Daher bewerteten Forscher MemGPT anhand dieser beiden Kriterien:
Kann MemGPT sein Gedächtnis nutzen, um die Konversationskonsistenz zu verbessern? Können Sie sich an relevante Fakten, Zitate und Ereignisse aus vergangenen Interaktionen erinnern, um die Kohärenz aufrechtzuerhalten?
Kann MemGPT den Speicher nutzen, um spannendere Gespräche zu generieren? Informationen von Remote-Benutzern spontan zusammenführen, um Informationen zu personalisieren?
In Bezug auf den verwendeten Datensatz bewerteten und verglichen die Forscher MemGPT- und Fixed-Context-Baseline-Modelle auf dem von Xu et al. (2021) vorgeschlagenen Multi-Session-Chat (MSC).
Lass uns zunächst die Konsistenzbewertung durchführen. Die Forscher führten eine DMR-Aufgabe (Deep Memory Retrieval) basierend auf dem MSC-Datensatz ein, um die Konsistenz des Konversationsagenten zu testen. Bei DMR stellt ein Benutzer einem Gesprächsagenten eine Frage und die Frage bezieht sich explizit auf ein früheres Gespräch, wobei erwartet wird, dass der Antwortbereich sehr eng ist. Einzelheiten finden Sie im Beispiel in Abbildung 5 unten.
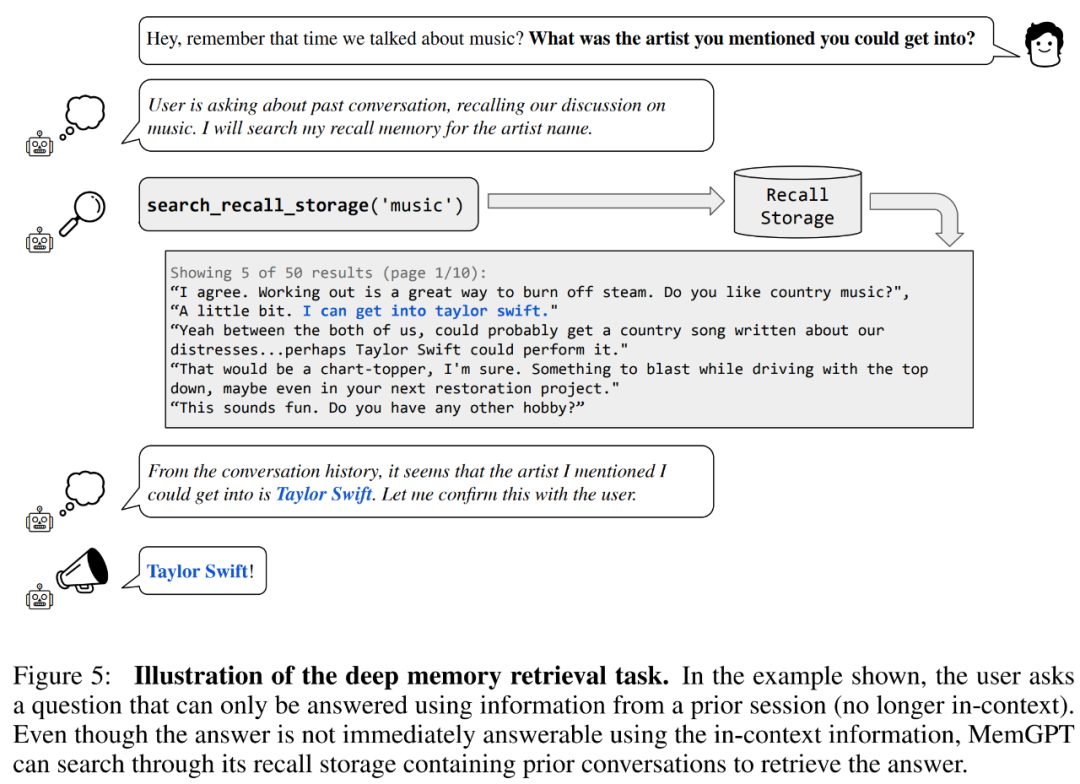
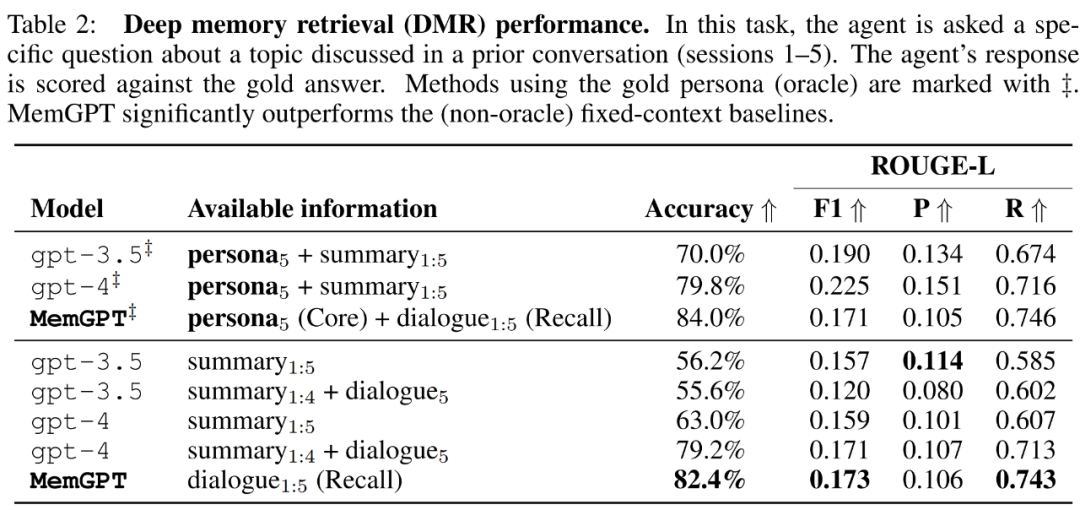
MemGPT nutzt den Speicher, um die Konsistenz aufrechtzuerhalten. Tabelle 2 unten zeigt den Leistungsvergleich von MemGPT mit Basismodellen mit festem Speicher, einschließlich GPT-3.5 und GPT-4.
Es ist ersichtlich, dass MemGPT in Bezug auf die LLM-Beurteilungsgenauigkeit und den ROUGE-L-Score deutlich besser ist als GPT-3.5 und GPT-4. MemGPT kann den Rückrufspeicher verwenden, um den Verlauf vergangener Konversationen abzufragen und DMR-Fragen zu beantworten, anstatt sich auf eine rekursive Zusammenfassung zu verlassen, um den Kontext zu erweitern.
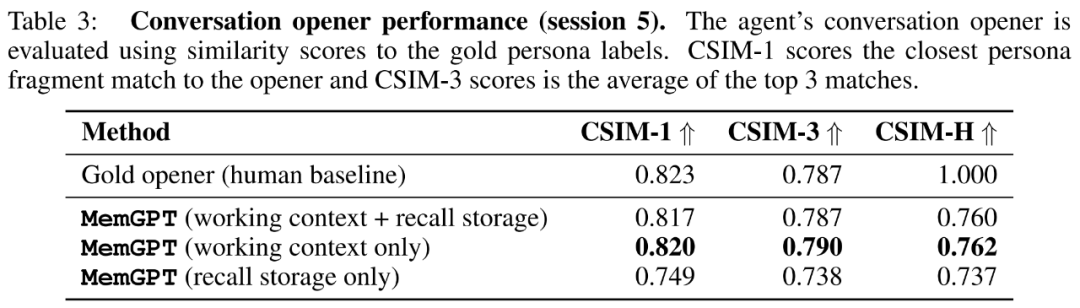
Dann bewerteten die Forscher in der Aufgabe „Konversationsstarter“ die Fähigkeit des Agenten, ansprechende Nachrichten aus dem in früheren Gesprächen gesammelten Wissen zu extrahieren und sie dem Benutzer zu übermitteln.
Die Forscher zeigen die CSIM-Werte der Eröffnungsbemerkungen von MemGPT in Tabelle 3 unten. Die Ergebnisse zeigen, dass MemGPT in der Lage ist, ansprechende Intros zu erstellen, deren Leistung genauso gut oder sogar besser ist als von Menschenhand geschriebene Intros. Es wurde auch beobachtet, dass MemGPT dazu neigt, Eröffnungen zu erzeugen, die länger sind und mehr Charakterinformationen abdecken als die menschliche Grundlinie. Abbildung 6 unten ist ein Beispiel.

MemGPT für die Dokumentenanalyse
Um die Fähigkeit von MemGPT zur Analyse von Dokumenten zu bewerten, führten Forscher MemGPT und Fixierung an der Retriever-Reader-Dokument-QS-Aufgabe von Liu et al. (2023a) durch. Es werden kontextbezogene Basismodelle verglichen.
Die Ergebnisse zeigen, dass MemGPT in der Lage ist, durch Abfragen des Archivspeichers effizient mehrere Aufrufe an den Retriever zu tätigen, wodurch eine Skalierung auf größere effektive Kontextlängen ermöglicht wird. MemGPT ruft aktiv Dokumente aus dem Archivspeicher ab und kann die Ergebnisse iterativ durchblättern, sodass die Gesamtzahl der verfügbaren Dokumente nicht mehr durch die Anzahl der Dokumente im entsprechenden LLM-Prozessor-Kontextfenster begrenzt ist.
Aufgrund der Einschränkungen der einbettungsbasierten Ähnlichkeitssuche stellt die Dokumenten-QS-Aufgabe eine große Herausforderung für alle Methoden dar. Forscher beobachteten, dass MemGPT die Paginierung der Crawler-Ergebnisse stoppt, bevor die Crawler-Datenbank erschöpft ist.
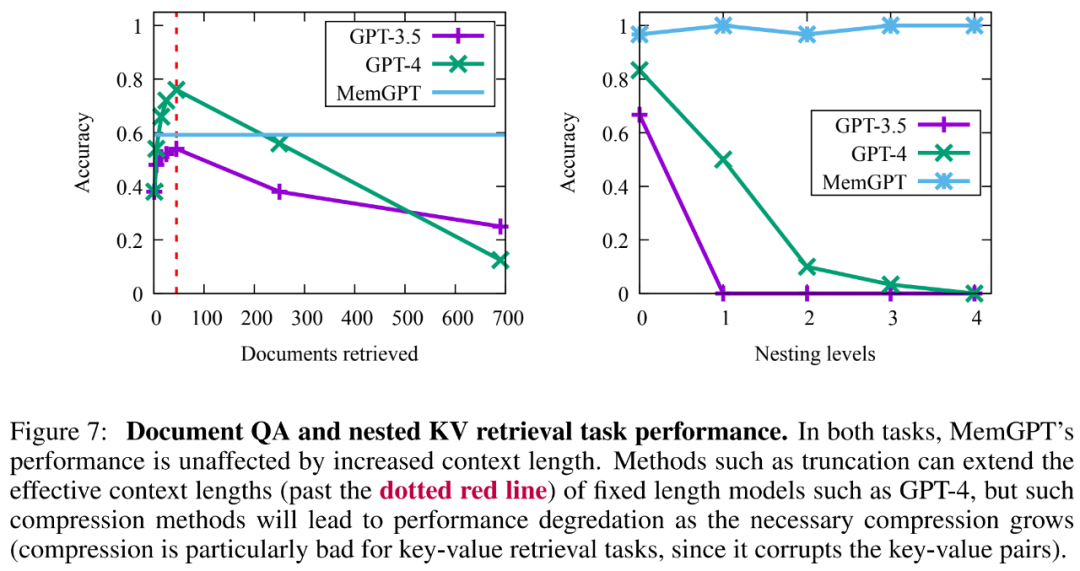
Darüber hinaus gibt es einen Kompromiss bei der Kapazität der abgerufenen Dokumente, die durch komplexere Vorgänge von MemGPT erstellt wurden, wie in Abbildung 7 unten dargestellt. Die durchschnittliche Genauigkeit ist geringer als bei GPT-4 (höher als GPT-3.5), aber Es kann problemlos auf größere Dokumente skaliert werden.
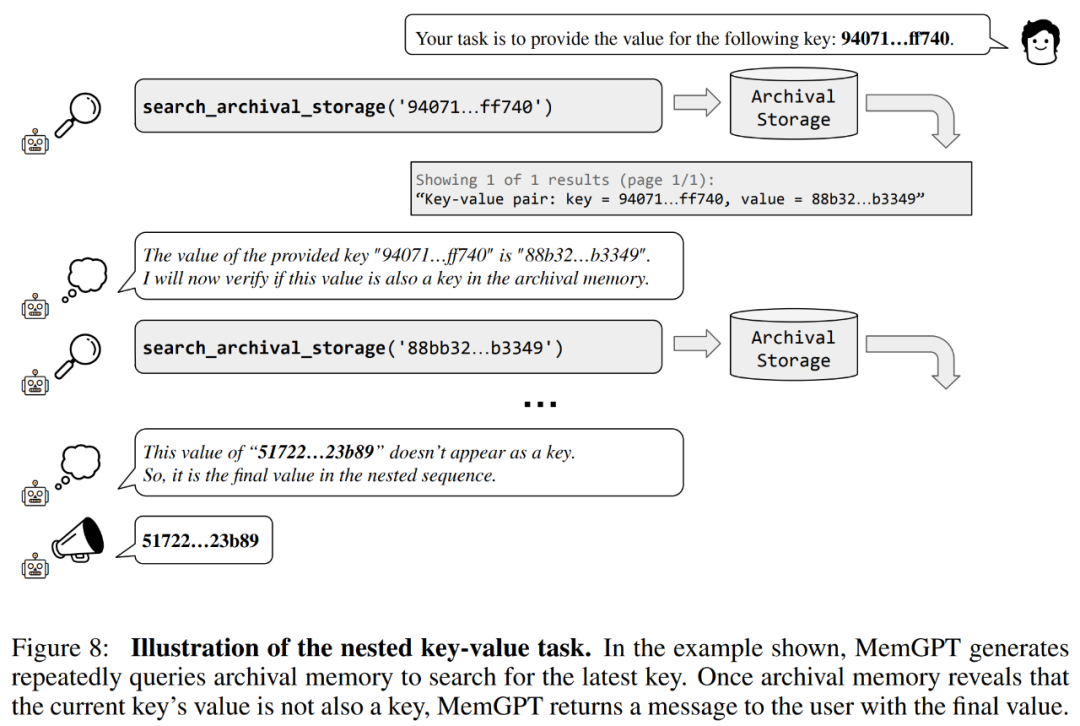
Die Forscher führten außerdem eine neue Aufgabe ein, die auf dem Abruf synthetischer Schlüsselwerte basiert, nämlich Nested Key-Value Retrieval, um zu demonstrieren, wie MemGPT Informationen aus mehreren Datenquellen organisiert.
Aus den Ergebnissen geht hervor, dass GPT-3.5 und GPT-4 zwar eine gute Leistung bei der ursprünglichen Schlüsselwertaufgabe zeigten, bei der Aufgabe zum Abruf verschachtelter Schlüsselwerte jedoch eine schlechte Leistung zeigten. MemGPT wird von der Anzahl der Verschachtelungsebenen nicht beeinflusst und kann verschachtelte Suchvorgänge durchführen, indem über Funktionsabfragen wiederholt auf im Hauptspeicher gespeicherte Schlüssel-Wert-Paare zugegriffen wird.
Die Leistung von MemGPT bei verschachtelten Schlüsselwert-Abrufaufgaben zeigt seine Fähigkeit, mehrere Suchvorgänge mithilfe einer Kombination mehrerer Abfragen durchzuführen.
Weitere technische Details und experimentelle Ergebnisse finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonBetrachten Sie LLM als ein Betriebssystem, es verfügt über unbegrenzten „virtuellen' Kontext, Berkeleys neues Werk hat 1,7.000 Sterne erhalten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!