
Heim >Technologie-Peripheriegeräte >KI >Sprache, Robot Breaking, MIT und andere nutzen GPT-4, um Simulationsaufgaben zu generieren und diese in die reale Welt zu übertragen
Sprache, Robot Breaking, MIT und andere nutzen GPT-4, um Simulationsaufgaben zu generieren und diese in die reale Welt zu übertragen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-10-16 20:21:03959Durchsuche
Umgeschriebener Inhalt als: Machine Heart Report
Herausgeber: Du Wei, Xiaozhou
GPT-4 und Roboter haben neue Impulse gesetzt.

Im Bereich der Robotik erfordert die Umsetzung universeller Roboterstrategien eine große Datenmenge, und das Sammeln dieser Daten in der realen Welt ist zeitaufwändig und mühsam. Obwohl die Simulation eine wirtschaftliche Lösung für die Generierung unterschiedlicher Datenmengen auf Szenen- und Instanzebene darstellt, stellt die zunehmende Aufgabenvielfalt in simulierten Umgebungen aufgrund des hohen Arbeitskräftebedarfs (insbesondere bei komplexen Aufgaben) immer noch Herausforderungen dar. Dies führt zu typischen künstlichen Simulations-Benchmarks, die typischerweise nur Dutzende bis Hunderte von Aufgaben umfassen.
Wie kann man es lösen? In den letzten Jahren haben große Sprachmodelle weiterhin erhebliche Fortschritte bei der Verarbeitung natürlicher Sprache und der Codegenerierung für verschiedene Aufgaben gemacht. Ebenso wurde LLM auf mehrere Aspekte der Robotik angewendet, darunter Benutzeroberflächen, Aufgaben- und Bewegungsplanung, Roboterprotokollzusammenfassung, Kosten- und Belohnungsdesign, und zeigte starke Fähigkeiten sowohl bei physikbasierten als auch bei Codegenerierungsaufgaben.
In einer aktuellen Studie untersuchten Forscher des MIT CSAIL, der Shanghai Jiao Tong University und anderer Institutionen weiter, ob LLM zur Erstellung vielfältiger Simulationsaufgaben eingesetzt werden kann und erforschten deren Fähigkeiten weiter.
Konkret schlugen die Forscher ein auf LLM basierendes Framework, GenSim, vor, das einen automatisierten Mechanismus zum Entwerfen und Überprüfen der Anordnung von Aufgabenressourcen und des Aufgabenfortschritts bietet. Noch wichtiger ist, dass die generierten Aufgaben eine große Vielfalt aufweisen, was die Verallgemeinerung von Roboterstrategien auf Aufgabenebene fördert. Darüber hinaus werden mit GenSim die Argumentations- und Codierungsfähigkeiten von LLM konzeptionell durch Zwischensynthese simulierter Daten zu verbal-visuellen Handlungsstrategien verfeinert.

Was neu geschrieben werden muss, ist: Papierlink:
https://arxiv.org/pdf/2310.01361.pdf
Das GenSim-Framework besteht aus den folgenden drei Teilen:
- Die erste besteht darin, neue Aufgaben durch Anweisungen in natürlicher Sprache und den durch den entsprechenden Code implementierten Eingabeaufforderungsmechanismus vorzuschlagen;
- Die zweite ist eine Aufgabenbibliothek, die zuvor generierten hochwertigen Befehlscode zur Verifizierung und Feinabstimmung des Sprachmodells zwischenspeichert und ihn als umfassenden Aufgabendatensatz zurückgibt
- Schließlich nutzt der sprachangepasste Multitask-Strategietrainingsprozess die generierten Daten, um die Generalisierungsfähigkeiten auf Aufgabenebene zu verbessern.
Das Framework arbeitet gleichzeitig in zwei verschiedenen Modi. Unter anderem hat der Benutzer in der zielorientierten Einstellung eine bestimmte Aufgabe oder möchte einen Aufgabenverlauf entwerfen. Zu diesem Zeitpunkt verfolgt GenSim einen Top-Down-Ansatz, bei dem die erwarteten Aufgaben als Eingabe verwendet und verwandte Aufgaben iterativ generiert werden, um die erwarteten Ziele zu erreichen. Wenn in einer explorativen Umgebung Vorkenntnisse über die Zielaufgabe fehlen, erkundet GenSim nach und nach Inhalte über die bestehenden Aufgaben hinaus und erstellt eine grundlegende Strategie, die unabhängig von der Aufgabe ist.
In Abbildung 1 unten initialisierte der Forscher eine Aufgabenbibliothek mit 10 manuell kuratierten Aufgaben, erweiterte sie mithilfe von GenSim und generierte mehr als 100 Aufgaben.

Die Forscher schlugen außerdem mehrere maßgeschneiderte Metriken vor, um die Qualität der generierten Simulationsaufgaben schrittweise zu messen, und bewerteten mehrere LLMs in zielorientierten und explorativen Umgebungen. Für die von GPT-4 generierte Aufgabenbibliothek führten sie eine überwachte Feinabstimmung an LLMs wie GPT-3.5 und Code-Llama durch und verbesserten so die Aufgabengenerierungsleistung von LLM weiter. Gleichzeitig wird die Erreichbarkeit von Aufgaben durch Strategietraining quantitativ gemessen und Aufgabenstatistiken verschiedener Attribute sowie Codevergleiche zwischen verschiedenen Modellen bereitgestellt.
Darüber hinaus trainierten die Forscher auch Multitasking-Roboterstrategien, die sich gut auf alle Generierungsaufgaben übertragen ließen und im Vergleich zu Modellen, die nur auf menschliche Planungsaufgaben trainiert wurden, die Leistung bei der Null-Schuss-Generalisierung verbesserten. Gemeinsames Training mit der GPT-4-Generierungsaufgabe kann die Generalisierungsleistung um 50 % verbessern und etwa 40 % der Zero-Shot-Aufgaben in Simulationen auf neue Aufgaben übertragen.
Schließlich betrachteten die Forscher auch den Transfer von Simulationen in die Realität und zeigten, dass ein Vortraining an verschiedenen Simulationsaufgaben die Fähigkeit zur Generalisierung in der realen Welt um 25 % verbessern kann.
Zusammenfassend lässt sich sagen, dass Richtlinien, die auf verschiedenen LLM-generierten Aufgaben trainiert werden, eine bessere Verallgemeinerung auf Aufgabenebene auf neue Aufgaben erreichen, was das Potenzial der Erweiterung simulierter Aufgaben durch LLM zum Trainieren von Basisrichtlinien hervorhebt.
Shubham Saboo, Direktor für Produktmanagement bei Tenstorrent AI, lobte diese Forschung sehr. Er sagte, dass dies eine bahnbrechende Forschung zu GPT-4 in Kombination mit Robotern sei. Eine Reihe simulierter Roboteraufgaben auf dem Autopiloten werden durch LLM generiert. 4. Zero-Shot-Lernen und reale Anpassung von Robotern Wirklichkeit werden lassen.

Einführung in die Methode
Wie in Abbildung 2 unten dargestellt, generiert das GenSim-Framework Simulationsumgebungen, Aufgaben und Demonstrationen durch Programmsynthese. Die GenSim-Pipeline beginnt beim Aufgabenersteller und die Eingabeaufforderungskette läuft je nach Zielaufgabe in zwei Modi, dem zielgerichteten Modus und dem explorativen Modus. Die Aufgabenbibliothek in GenSim ist eine speicherinterne Komponente, die zum Speichern zuvor generierter hochwertiger Aufgaben verwendet wird. Die in der Aufgabenbibliothek gespeicherten Aufgaben können für das Training von Multitask-Richtlinien oder die Feinabstimmung von LLM verwendet werden.
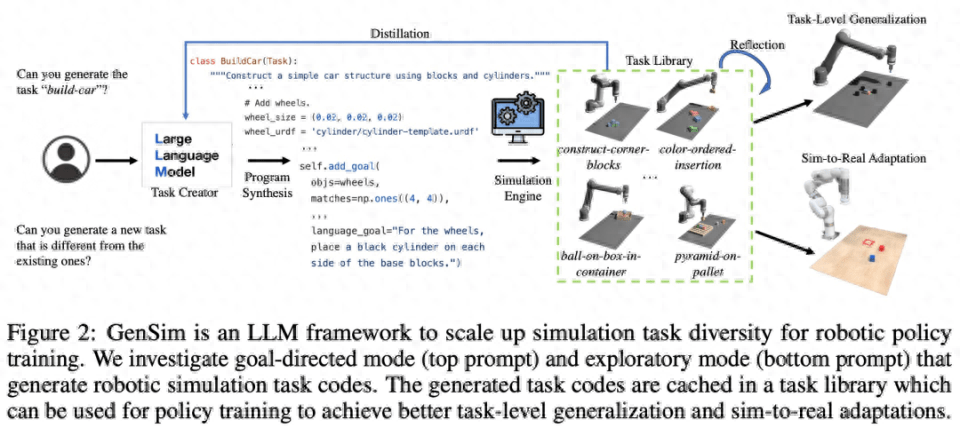
Aufgabenersteller
Wie in Abbildung 3 unten dargestellt, generiert die Sprachkette zunächst die Aufgabenbeschreibung und dann die zugehörige Implementierung. Die Aufgabenbeschreibung umfasst den Aufgabennamen, Ressourcen und eine Aufgabenzusammenfassung. Diese Studie verwendet eine Eingabeaufforderung mit wenigen Beispielen in der Pipeline, um Code zu generieren.
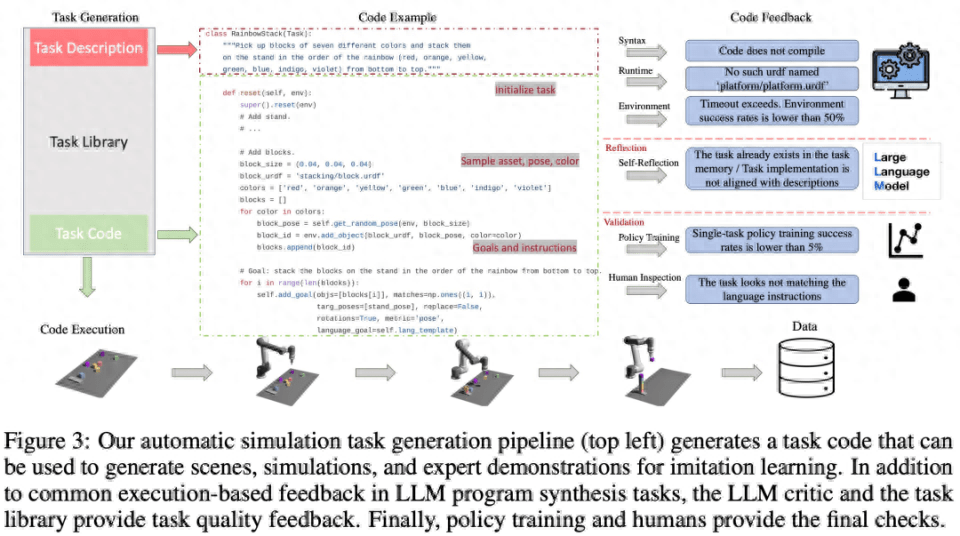
Aufgabenbibliothek
Die Aufgabenbibliothek im GenSim-Framework speichert vom Aufgabenersteller generierte Aufgaben, um bessere neue Aufgaben zu generieren und Multitasking-Strategien zu trainieren. Die Aufgabenbibliothek wird basierend auf Aufgaben aus manuell erstellten Benchmarks initialisiert.
Die Aufgabenbibliothek stellt dem Aufgabenersteller die vorherige Aufgabenbeschreibung als Bedingung für die Beschreibungsgenerierungsphase zur Verfügung, stellt den vorherigen Code für die Codegenerierungsphase bereit und fordert den Aufgabenersteller auf, eine Referenzaufgabe aus der Aufgabenbibliothek als Beispiel auszuwählen eine neue Aufgabe schreiben. Nachdem die Aufgabenimplementierung abgeschlossen ist und alle Tests bestanden wurden, wird LLM aufgefordert, über die neue Aufgabe und Aufgabenbibliothek nachzudenken und eine umfassende Entscheidung darüber zu treffen, ob die neu generierte Aufgabe der Bibliothek hinzugefügt werden soll.
Wie in Abbildung 4 unten dargestellt, beobachtete die Studie auch, dass GenSim ein interessantes Kombinations- und Extrapolationsverhalten auf Aufgabenebene aufweist:
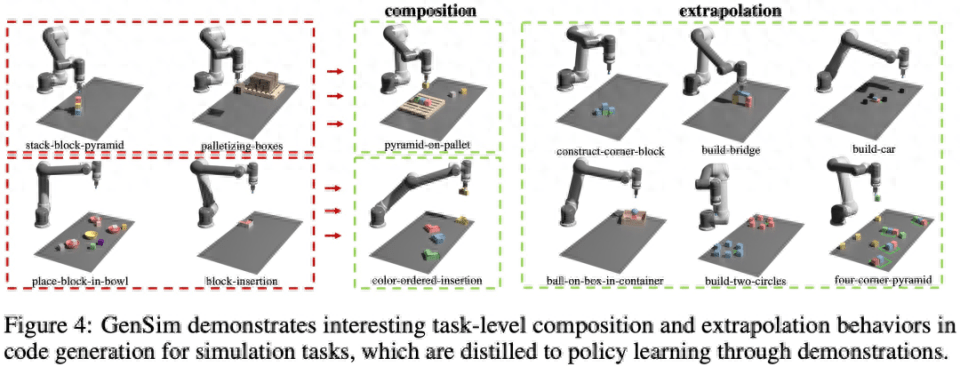
LLM-überwachte Multitasking-Strategie
Nach der Aufgabengenerierung verwendet diese Studie diese Aufgabenimplementierungen, um Demonstrationsdaten zu generieren und Betriebsrichtlinien zu trainieren, wobei eine Dual-Stream-Übertragungsnetzwerkarchitektur ähnlich der von Shridhar et al. verwendet wird.
Wie in Abbildung 5 unten dargestellt, betrachtet diese Studie das Programm als eine effektive Darstellung der Aufgabe und der zugehörigen Demonstrationsdaten (Abbildung 5). Es ist möglich, einen Einbettungsraum zwischen Aufgaben zu definieren, und sein Abstandsindex reagiert empfindlich auf verschiedene Faktoren Wahrnehmung (z. B. Objekthaltung und -form) sind robuster.

Um den Inhalt neu zu schreiben, muss die Sprache des Originaltextes ins Chinesische umgeschrieben werden und der Originalsatz muss nicht erscheinen
Diese Studie validiert das GenSim-Framework durch Experimente und geht dabei auf die folgenden spezifischen Fragen ein: (1) Wie effektiv ist LLM beim Entwerfen und Implementieren von Simulationsaufgaben? Kann GenSim die Leistung von LLM bei der Aufgabengenerierung verbessern? (2) Kann Schulung zu den durch LLM generierten Aufgaben die Fähigkeit zur Richtlinienverallgemeinerung verbessern? Wäre die Politikschulung von größerem Nutzen, wenn ihnen mehr Generationsaufgaben übertragen würden? (3) Ist eine Vorschulung zu LLM-generierten Simulationsaufgaben für die Umsetzung realer Roboterrichtlinien von Vorteil?
Bewerten Sie die Generalisierungsfähigkeit von LLM-Robotersimulationsaufgaben
Wie in Abbildung 6 unten dargestellt, kann die zweistufige Eingabeaufforderungskette aus wenigen Beispielen und Aufgabenbibliotheken für die Aufgabengenerierung im Erkundungsmodus und im zielorientierten Modus die Erfolgsquote der Codegenerierung effektiv verbessern.
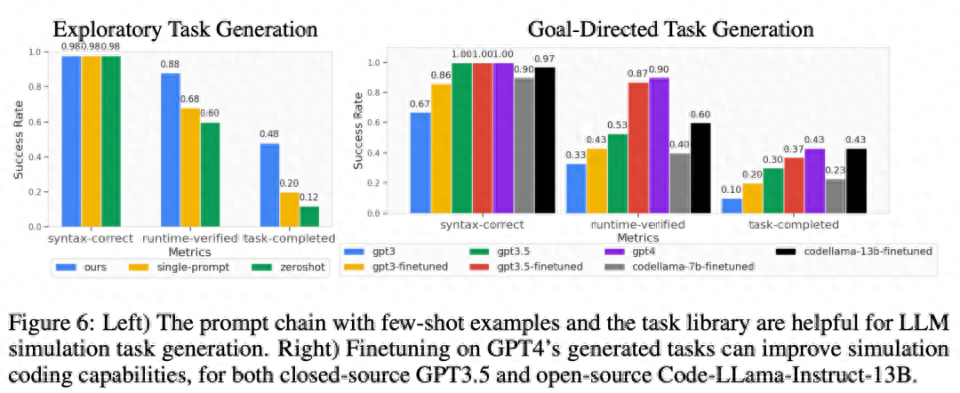
Generalisierung auf Aufgabenebene
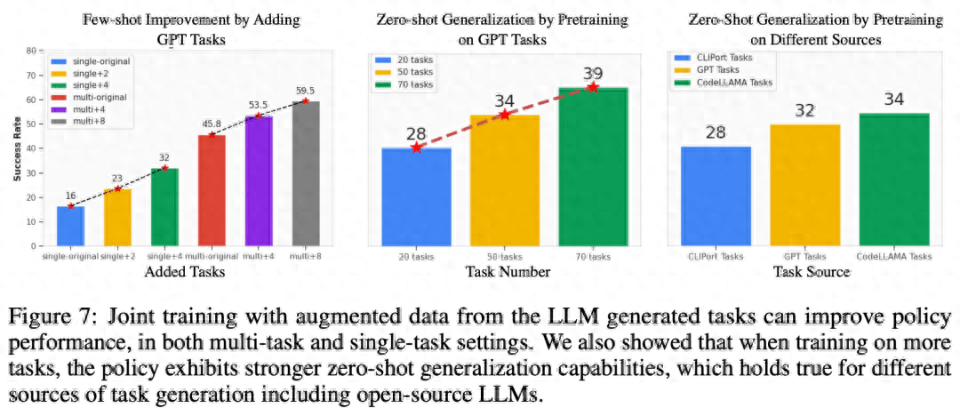
Few-Shot-Strategieoptimierung für verwandte Aufgaben. Wie auf der linken Seite von Abbildung 7 unten zu sehen ist, kann das gemeinsame Training der von LLM generierten Aufgaben die Richtlinienleistung für die ursprüngliche CLIPort-Aufgabe um mehr als 50 % verbessern, insbesondere in Situationen mit wenig Daten (z. B. 5 Demos).
Zero-Shot-Richtlinienverallgemeinerung auf unsichtbare Aufgaben. Wie in Abbildung 7 zu sehen ist, kann unser Modell durch Vorabtraining für mehr von LLM generierte Aufgaben besser auf Aufgaben im ursprünglichen Ravens-Benchmark verallgemeinert werden. In der Mitte rechts in Abbildung 7 haben die Forscher außerdem fünf Aufgaben auf verschiedenen Aufgabenquellen vorab trainiert, darunter manuell geschriebene Aufgaben, Closed-Source-LLM und Open-Source-LLM mit Feinabstimmung, und dabei ein ähnliches Zero-Shot-Aufgabenniveau beobachtet Verallgemeinerung.
Passen Sie vorab trainierte Modelle an die reale Welt an
Forscher übertrugen die in der Simulationsumgebung trainierten Strategien auf die reale Umgebung. Die Ergebnisse sind in Tabelle 1 unten aufgeführt. Das vorab trainierte Modell führte 10 Experimente zu 9 Aufgaben durch und erreichte eine durchschnittliche Erfolgsquote von 68,8 %, was besser ist als das Vortraining nur für die CLIPort-Aufgabe. Im Vergleich zum Basismodell hat es sich um mehr als 25 % verbessert, und im Vergleich zum Modell, das nur für 50 Aufgaben vorab trainiert wurde, hat es sich um 15 % verbessert.
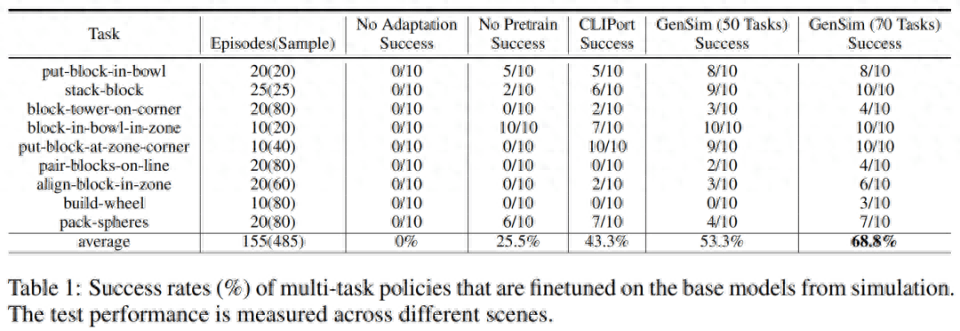
Forscher beobachteten außerdem, dass das Vortraining für verschiedene Simulationsaufgaben die Robustheit langfristiger komplexer Aufgaben verbesserte. Beispielsweise zeigen vorab trainierte GPT-4-Modelle eine robustere Leistung bei realen Build-Wheel-Aufgaben.

Ablationsexperiment
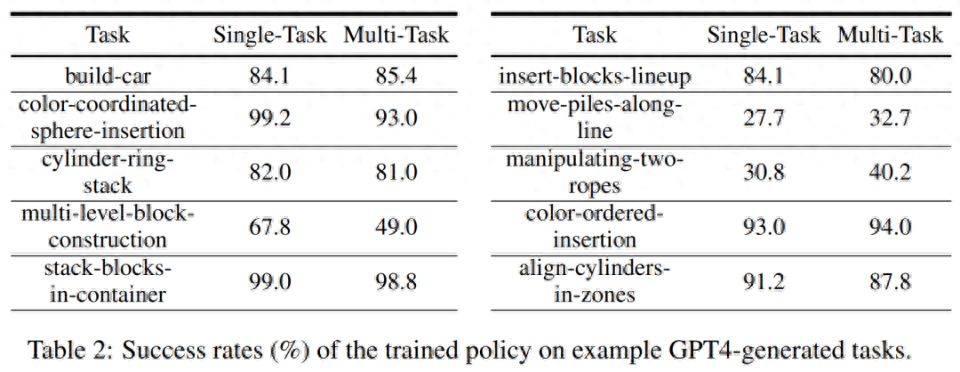
Erfolgsquote des Simulationstrainings. In der folgenden Tabelle 2 demonstrieren die Forscher die Erfolgsraten von Richtlinienschulungen für einzelne und mehrere Aufgaben anhand einer Teilmenge generierter Aufgaben anhand von 200 Demos. Bei der Richtlinienschulung zu Aufgaben der GPT-4-Generation beträgt die durchschnittliche Aufgabenerfolgsquote 75,8 % für Einzelaufgaben und 74,1 % für Mehrfachaufgaben.
Aufgabenstatistiken erstellen. In Abbildung 9 (a) unten zeigt der Forscher die Aufgabenstatistiken verschiedener Merkmale der 120 von LLM generierten Aufgaben. Es besteht ein interessantes Gleichgewicht zwischen den Farben, Assets, Aktionen und der Anzahl der vom LLM-Modell generierten Instanzen. Der generierte Code enthält beispielsweise viele Szenen mit mehr als 7 Objektinstanzen sowie viele primitive Pick-and-Place-Aktionen und Assets wie Blöcke.
Im Vergleich der Codegenerierung haben die Forscher die Fehlerfälle in den Top-Down-Experimenten von GPT-4 und Code Llama in Abbildung 9(b) unten qualitativ bewertet

Weitere technische Details finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonSprache, Robot Breaking, MIT und andere nutzen GPT-4, um Simulationsaufgaben zu generieren und diese in die reale Welt zu übertragen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Verwendung von Python zur Implementierung der automatischen Antwort kleiner Roboter und zur skalierbaren Entwicklung kleiner Roboter für öffentliche WeChat-Konten
- Bringen Sie Ihnen bei, wie Sie mit Golang und Lua einen Dienstroboter implementieren
- In welcher Hinsicht ist ein Roboter eine Anwendung von Computern?
- Verfügt vivo über einen intelligenten Sprachroboter?
- Sprache, Robot Breaking, MIT und andere nutzen GPT-4, um automatisch Simulationsaufgaben zu generieren und diese in die reale Welt zu migrieren