
Heim >Technologie-Peripheriegeräte >KI >Wählen Sie GPT-3.5 oder Jordan Llama 2 und andere Open-Source-Modelle? Nach einem umfassenden Vergleich lautet die Antwort
Wählen Sie GPT-3.5 oder Jordan Llama 2 und andere Open-Source-Modelle? Nach einem umfassenden Vergleich lautet die Antwort

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-10-16 18:45:05607Durchsuche
Durch den Vergleich der Parameter von GPT-3.5 und Llama 2 bei verschiedenen Aufgaben können wir wissen, unter welchen Umständen wir uns für GPT-3.5 entscheiden und unter welchen Umständen wir uns für Llama 2 oder andere Modelle entscheiden.
Anscheinend ist das Drehmoment von GPT-3.5 sehr teuer. In diesem Artikel wird experimentell überprüft, ob ein manuelles Drehmomentmodell die Leistung von GPT-3.5 zu einem Bruchteil der Kosten von GPT-3.5 erreichen kann. Interessanterweise tat dies die Zeitung.
Beim Vergleich der Ergebnisse zu SQL-Aufgaben und Funktionsdarstellungsaufgaben stellte das Papier fest, dass:
GPT-3.5 in beiden Datensätzen (einer Teilmenge des Spider-Datensatzes und des Viggo-Funktionsdarstellungsdatensatzes) besser ist als Code nach Lora ) Lama 34B schnitt etwas besser ab.
Die Schulungskosten von GPT-3.5 sind vier- bis sechsmal höher, und auch die Bereitstellungskosten sind höher.
Eine der Schlussfolgerungen dieses Experiments ist, dass GPT-3.5 für erste Verifizierungsarbeiten geeignet ist, aber danach ein Modell wie Llama 2 möglicherweise die beste Wahl ist, um es kurz zusammenzufassen:
Wenn Sie eine Verifizierung wünschen um lösungsspezifisch zu sein Der richtige Ansatz für Ihre Aufgabe/Ihren Datensatz, oder wenn Sie eine vollständig verwaltete Umgebung wünschen, dann passen Sie GPT-3.5 an.
Wenn Sie Geld sparen, maximale Leistung aus Ihrem Datensatz herausholen, mehr Flexibilität beim Training und der Bereitstellung der Infrastruktur haben und einige Daten wünschen oder behalten möchten, dann nutzen Sie etwas wie das Open-Source-Modell Llama 2.
Als nächstes schauen wir uns an, wie das Papier umgesetzt wird.
Die folgende Abbildung zeigt die Leistung von Code Llama 34B und GPT-3.5, die auf Konvergenz bei SQL-Aufgaben und Funktionsdarstellungsaufgaben trainiert wurden. Die Ergebnisse zeigen, dass GPT-3.5 bei beiden Aufgaben eine bessere Genauigkeit erreicht.
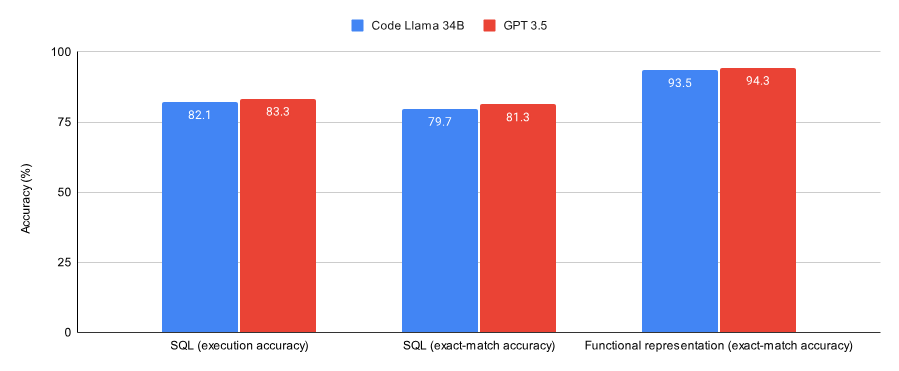
In Bezug auf die Hardwarenutzung wurde für das Experiment eine A40-GPU verwendet, was ungefähr 0,475 US-Dollar kostet.
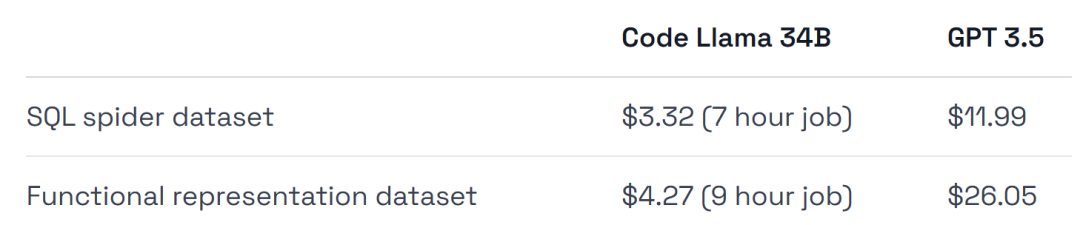
Darüber hinaus zählt das Experiment zwei Datensätze auf, die sich sehr gut für Scary eignen, eine Teilmenge des Spider-Datensatzes und die Viggo-Funktion, die den Datensatz darstellt.
Um einen fairen Vergleich mit dem GPT-3.5-Modell zu ermöglichen, wurden Experimente mit Lama mit minimalen Hyperparametern durchgeführt.
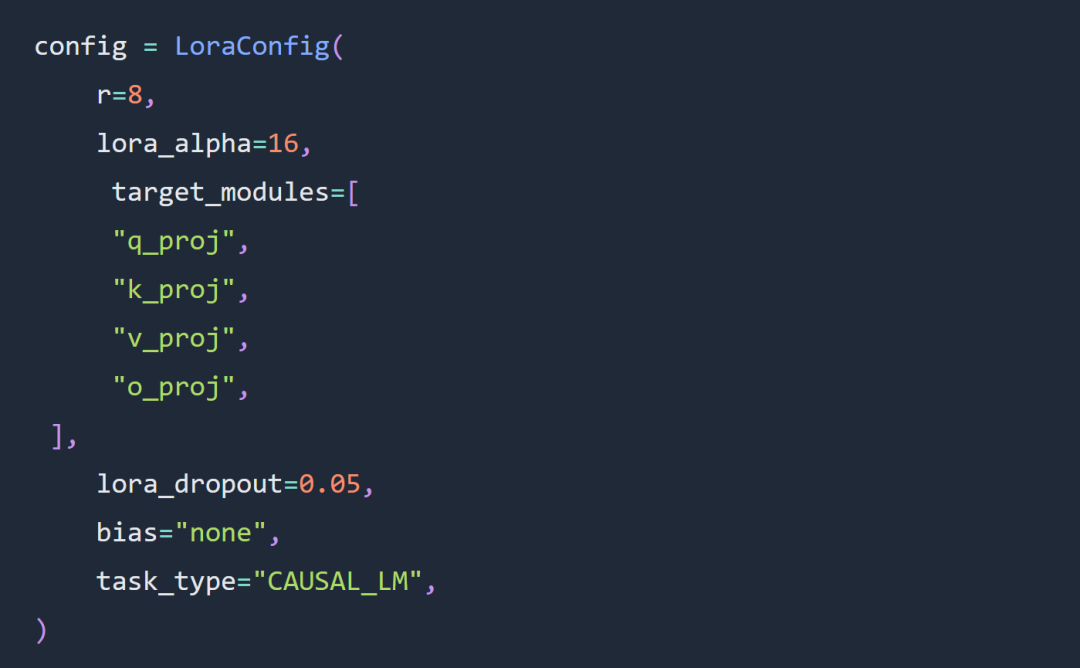
Zwei wichtige Optionen für die Experimente in diesem Artikel sind die Verwendung von Code Llama 34B- und Lora-Parametern anstelle von Parametern mit vollständigen Parametern.度 Das Experiment folgt weitgehend den Regeln der LoRa-Superparameterkonfiguration. Die LoRA-Last lautet wie folgt:
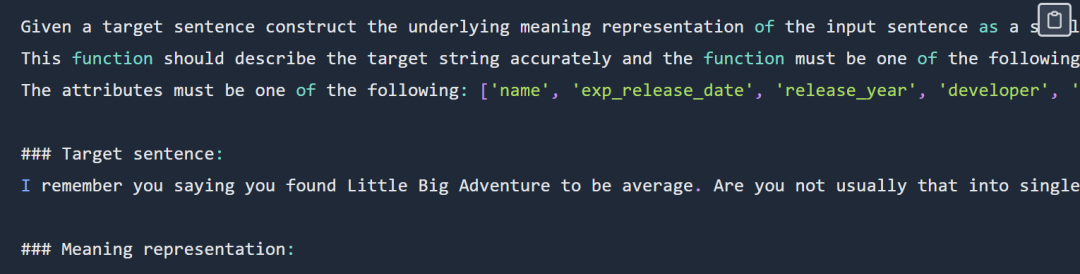
SQL-Eingabeaufforderungsteil der Anzeige, bitte überprüfen Vollständige Eingabeaufforderungen finden Sie im Originalblog.
department : Department_ID [ INT ] primary_key Name [ TEXT ] Creation [ TEXT ] Ranking [ INT ] Budget_in_Billions [ INT ] Num_Employees [ INT ] head : head_ID [ INT ] primary_key name [ TEXT ] born_state [ TEXT ] age [ INT ] management : department_ID [ INT ] primary_key management.department_ID = department.Department_ID head_ID [ INT ] management.head_ID = head.head_ID temporary_acting [ TEXT ]
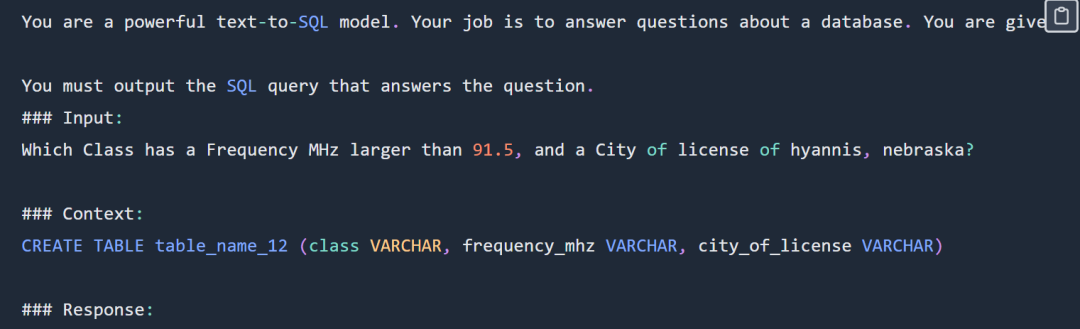
Beim Experiment wurde die Schnittmenge von sql-create verwendet. Kontextdatensatz und der Spider-Datensatz. Der für das Modell bereitgestellte Kontext ist ein SQL-Erstellungsbefehl wie dieser:
CREATE TABLE table_name_12 (class VARCHAR, frequency_mhz VARCHAR, city_of_license VARCHAR)Code und Datenadresse für die SQL-Aufgabe: https://github.com/samlhuillier/spider-sql-finetuneBeispiel für eine Eingabeaufforderung zur Funktionsdarstellung Wie unten gezeigt: 提 Die Funktion gibt den Eingabeaufforderungsteil der Anzeige an. Die vollständigen Eingabeaufforderungen finden Sie in der folgenden Originalblogausgabe. Die Funktion stellt den Aufgabencode und die Datenadresse dar: https://github.com/ samlhuillier/viggo-finetuneWeitere Informationen finden Sie im Originalblog.
 Original-Link:
Original-Link:
https: //agntune.com/blog/gpt3.5-vs-lama2-finetuning? Continflag = 11fc7786e20d498fc4daa79c5923e198
Das obige ist der detaillierte Inhalt vonWählen Sie GPT-3.5 oder Jordan Llama 2 und andere Open-Source-Modelle? Nach einem umfassenden Vergleich lautet die Antwort. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was ist ein Full-Stack-Ingenieur?
- Was macht ein PHP-Ingenieur hauptsächlich?
- So erstellen Sie ein vscode-Projekt
- Computer werden zur Lösung mathematischer Probleme in der wissenschaftlichen Forschung und bei technischen Berechnungen eingesetzt.
- Stanfords „Grass Mud Horse' ist beliebt: 100 $ können mit GPT-3,5 mithalten! Die Art, die auf Mobiltelefonen ausgeführt werden kann