
Heim >Technologie-Peripheriegeräte >KI >GPT-4 hat seine Genauigkeit durch DeepMind-Training um 13,7 % verbessert und so bessere Induktions- und Schlussfolgerungsfähigkeiten erreicht.
GPT-4 hat seine Genauigkeit durch DeepMind-Training um 13,7 % verbessert und so bessere Induktions- und Schlussfolgerungsfähigkeiten erreicht.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-10-14 20:13:03885Durchsuche
Derzeit zeigen Large Language Models (LLMs) erstaunliche Fähigkeiten bei Inferenzaufgaben, insbesondere wenn Beispiele und Zwischenschritte bereitgestellt werden. Prompt-Methoden basieren jedoch normalerweise auf implizitem Wissen im LLM, und wenn das implizite Wissen falsch ist oder nicht mit der Aufgabe übereinstimmt, kann LLM falsche Antworten geben

Jetzt von Google, Mila Institute usw. Forscher aus der Forschung Institutionen erforschten gemeinsam eine neue Methode – LLM das Erlernen von Inferenzregeln zu ermöglichen, und schlugen ein neues Framework namens Hypotheses-to-Theories (HtT) vor. Diese neue Methode verbessert nicht nur das mehrstufige Denken, sondern bietet auch die Vorteile der Interpretierbarkeit und Übertragbarkeit. Papieradresse: https://arxiv.org/abs/2310.07064. Laut Experimental Ergebnisse zu numerischen und relationalen Denkproblemen zeigen, dass die HtT-Methode die bestehende Eingabeaufforderungsmethode verbessert und die Genauigkeit um 11–27 % erhöht. Gleichzeitig können die erlernten Regeln auch auf verschiedene Modelle oder verschiedene Formen des gleichen Problems übertragen werden
Einführung in die Methode
In der Einführungsphase muss LLM zunächst einen Regelsatz für Trainingsbeispiele generieren und verifizieren. Diese Studie verwendet CoT, um Regeln zu deklarieren und Antworten abzuleiten, die Häufigkeit und Genauigkeit von Regeln zu bewerten, Regeln zu sammeln, die häufig auftreten und zu korrekten Antworten führen, und eine Regelbasis zu bilden
Mit einer guten Regelbasis ist der nächste Schritt, wie Um diese Forschung anzuwenden, lösen diese Regeln das Problem. Zu diesem Zweck fügt diese Studie in der Abzugsphase eine Regelbasis in der Eingabeaufforderung hinzu und erfordert, dass LLM Regeln aus der Regelbasis abruft, um den Abzug durchzuführen und implizites Denken in explizites Denken umzuwandeln.
Studien haben jedoch ergeben, dass selbst sehr leistungsfähige LLMs (wie GPT-4) Schwierigkeiten haben, bei jedem Schritt die richtigen Regeln abzurufen. Daher entwickelt diese Studie XML-Markup-Techniken, um die Kontextabruffähigkeiten von LLM zu verbessern. Experimentelle Ergebnisse: Zur Bewertung von HtT führte diese Studie Benchmarks zu zwei mehrstufigen Argumentationsproblemen durch. Experimentelle Ergebnisse zeigen, dass HtT die Prompt-Methode mit wenigen Stichproben verbessert. Die Autoren führten außerdem umfangreiche Ablationsstudien durch, um ein umfassenderes Verständnis von HtT zu ermöglichen. 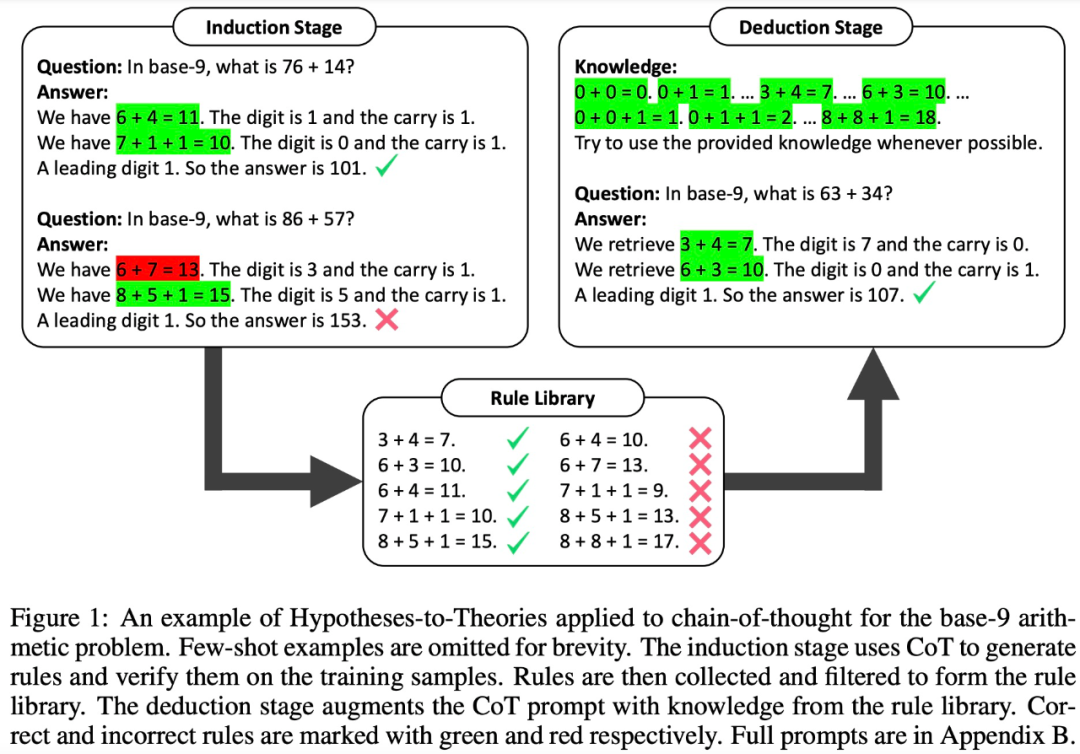
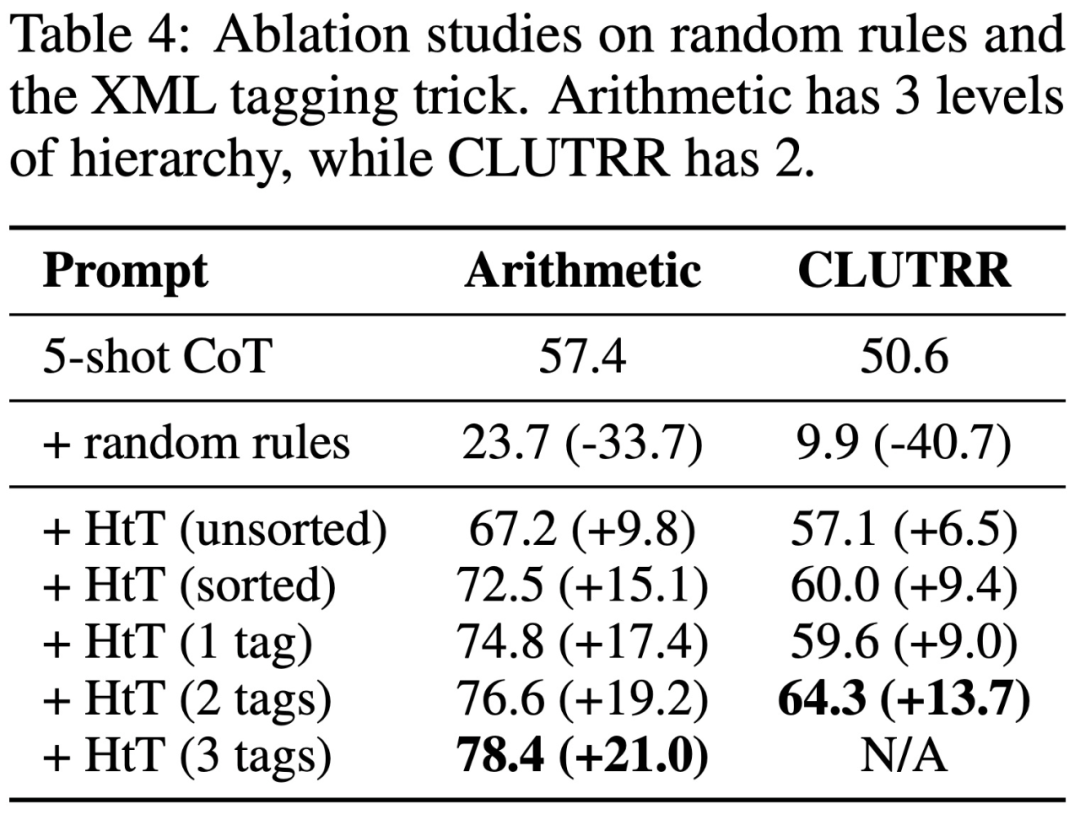
Konkret zeigt Tabelle 1 unten die Ergebnisse für die Basis-16-, Basis-11- und Basis-9-Datensätze der Arithmetik. Unter allen Basissystemen weist das 0-Schuss-CoT in beiden LLMs die schlechteste Leistung auf.
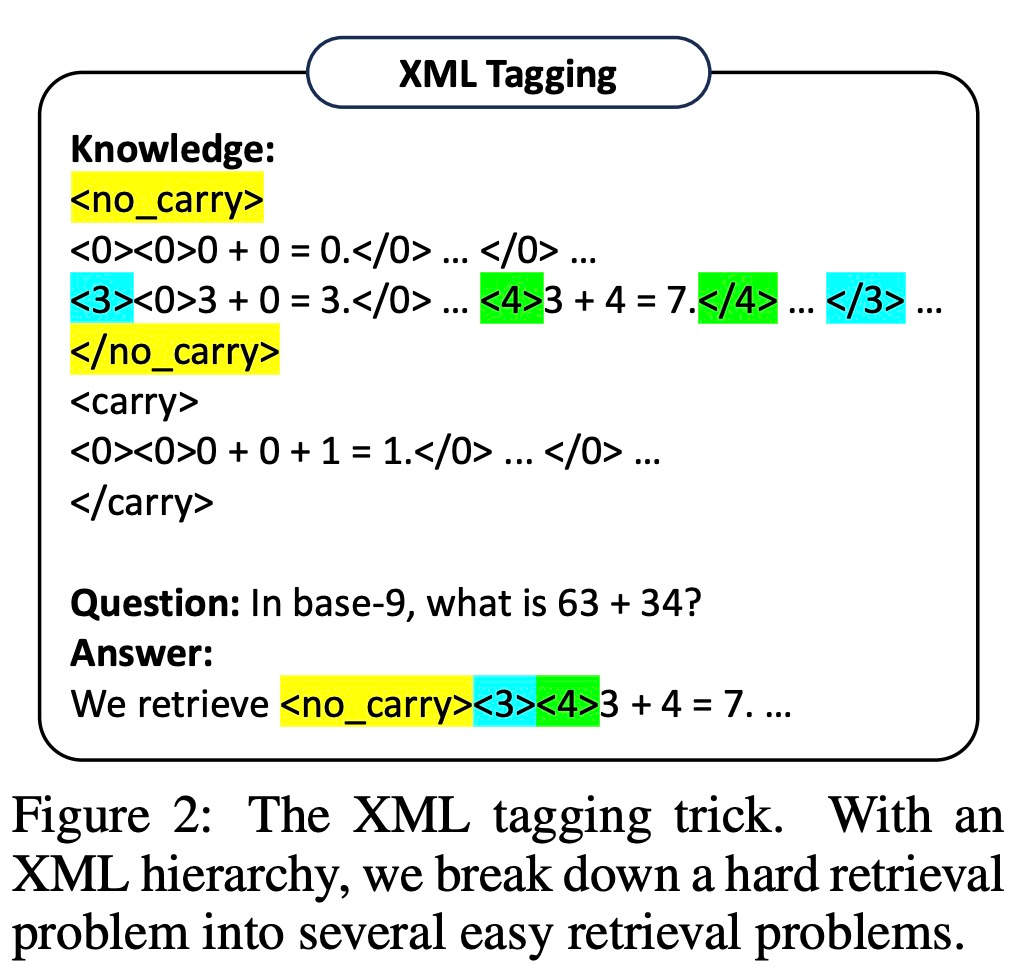
Tabelle 2 zeigt die Ergebnisse im Vergleich verschiedener Methoden zu CLUTRR. Es ist zu beobachten, dass 0-Shot-CoT in GPT3.5 und GPT4 die schlechteste Leistung aufweist. Bei der Aufforderungsmethode mit wenigen Schüssen funktionieren CoT und LtM ähnlich. In Bezug auf die durchschnittliche Genauigkeit übertrifft HtT die Hinweismethoden für beide Modelle durchweg um 11,1–27,2 %. Es ist erwähnenswert, dass GPT3.5 beim Abrufen von CLUTRR-Regeln nicht schlecht ist und mehr von HtT profitiert als GPT4, wahrscheinlich weil es in CLUTRR weniger Regeln als in der Arithmetik gibt.
Es ist erwähnenswert, dass unter Verwendung der Regeln von GPT4 die CoT-Leistung auf GPT3.5 um 27,2 % verbessert wird, was mehr als dem Doppelten der CoT-Leistung entspricht und nahe an der CoT-Leistung auf GPT4 liegt. Daher glauben die Autoren, dass HtT als neue Form der Wissensdestillation von starkem LLM zu schwachem LLM dienen kann.
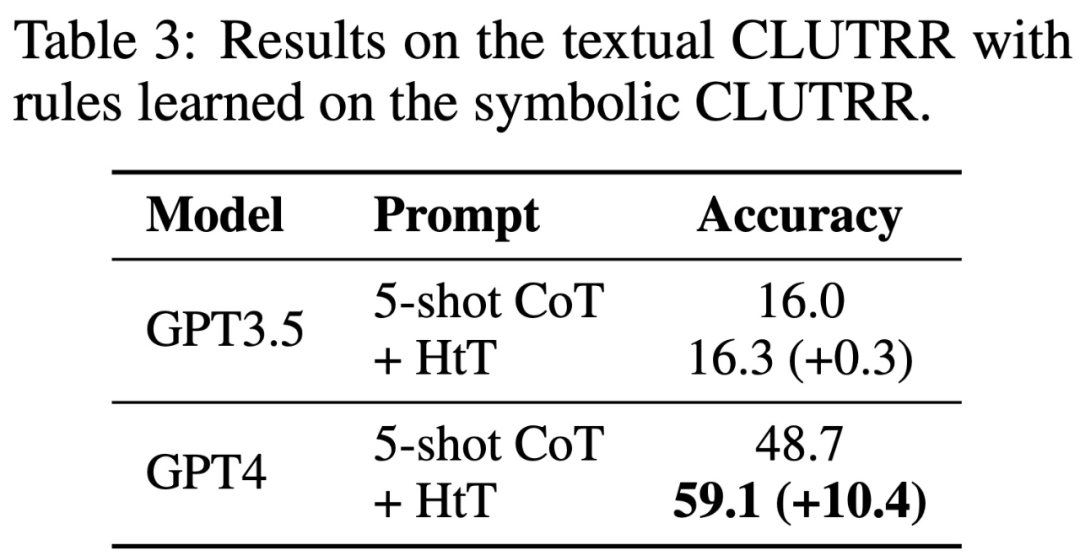
Tabelle 3 zeigt, dass HtT die Leistung von GPT-4 (Textversion) deutlich verbessert. Diese Verbesserung ist für GPT3.5 nicht signifikant, da sie bei der Verarbeitung von Texteingaben häufig zu anderen Fehlern als der Regelillusion führt.
Das obige ist der detaillierte Inhalt vonGPT-4 hat seine Genauigkeit durch DeepMind-Training um 13,7 % verbessert und so bessere Induktions- und Schlussfolgerungsfähigkeiten erreicht.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Eine Einführung in vier Methoden zur Implementierung maschineller Lernfunktionen in Python
- Tensorflow-Grundlagen (Open-Source-Softwarebibliothek für maschinelles Lernen)
- Wie künstliche Intelligenz und maschinelles Lernen die Zukunft des Gesundheitswesens beeinflussen werden
- Kaifu Lee: Große KI-Modelle sind eine historische Chance, die man sich nicht entgehen lassen darf
- Populärwissenschaft: Was ist ein KI-Großmodell?