
Heim >Technologie-Peripheriegeräte >KI >MotionLM: Sprachmodellierungstechnologie für die Bewegungsvorhersage mit mehreren Agenten
MotionLM: Sprachmodellierungstechnologie für die Bewegungsvorhersage mit mehreren Agenten

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-10-13 12:09:051570Durchsuche
Dieser Artikel wird mit Genehmigung des öffentlichen Kontos von Autonomous Driving Heart nachgedruckt. Bitte wenden Sie sich für einen Nachdruck an die Quelle.
Originaltitel: MotionLM: Multi-Agent Motion Forecasting as Language Modeling
Papierlink: https://arxiv.org/pdf/2309.16534.pdf
Autoreneinheit: Waymo
Konferenz: ICCV 2023

Idee für die Abschlussarbeit:
Für die Sicherheitsplanung autonomer Fahrzeuge ist es entscheidend, das zukünftige Verhalten von Verkehrsteilnehmern zuverlässig vorherzusagen. Diese Studie stellt kontinuierliche Trajektorien als Sequenzen diskreter Bewegungstokens dar und behandelt die Bewegungsvorhersage mit mehreren Agenten als eine Sprachmodellierungsaufgabe. Unser vorgeschlagenes Modell, MotionLM, hat mehrere Vorteile: Erstens erfordert es keine Verwendung von Ankerpunkten oder expliziten latenten Variablen, um multimodale Verteilungen optimal zu lernen. Stattdessen nutzen wir das Standardziel der Sprachmodellierung, die durchschnittliche Log-Wahrscheinlichkeit von Sequenz-Tokens zu maximieren. Zweitens vermeidet unser Ansatz Post-hoc-Interaktionsheuristiken, bei denen die Generierung der Trajektorie einzelner Agenten nach der Interaktionsbewertung erfolgt. Im Gegensatz dazu generiert MotionLM eine gemeinsame Verteilung interaktiver Agenten-Futures in einem einzigen autoregressiven Decodierungsprozess. Darüber hinaus ermöglicht die sequentielle Zerlegung des Modells den Rückschluss auf zeitlich kausale Bedingungen. Unsere vorgeschlagene Methode erreicht eine neue Leistung auf dem neuesten Stand der Technik im Waymo Open Motion Dataset und belegt den ersten Platz in der Rangliste der interaktiven Herausforderungen.
Hauptbeiträge:
In diesem Artikel stellen wir die Multi-Agent-Bewegungsvorhersage als A-Sprache vor Modellierungsaufgabe wird besprochen. Wir stellen einen zeitlich-kausalen Decoder vor, um diskrete Bewegungstoken zu dekodieren, die mit einem kausalen Sprachmodellierungsverlust trainiert wurden.
In diesem Artikel wird die Stichprobenentnahme im Modell mit einem einfachen Rollout-Aggregationsschema kombiniert, um die gewichteten Mustererkennungsfähigkeiten gemeinsamer Trajektorien zu verbessern. Durch Experimente im Waymo Open Motion Dataset-Wechselwirkungsvorhersage-Wettbewerb zeigen wir, dass diese neue Methode die Ranking-gemeinsame mAP-Metrik um 6 % verbessert und das modernste Leistungsniveau erreicht
Dieses Papier führt eine ausführliche Überprüfung unserer Methode durch Ablationsexperimente und analysieren ihre zeitlichen kausalen bedingten Vorhersagen, die von aktuellen gemeinsamen Vorhersagemodellen weitgehend nicht unterstützt werden.
Netzwerkdesign:
Das Ziel dieses Artikels ist es, die Verteilung über Multi-Agenten-Interaktionen auf allgemeine Weise zu modellieren, die auf verschiedene nachgelagerte Aufgaben angewendet werden kann, einschließlich minimaler, gemeinsamer und bedingter Vorhersagen. Um dieses Ziel zu erreichen, ist ein ausdrucksstarkes generatives Framework erforderlich, das die vielfältigen Morphologien in Fahrszenarien erfassen kann. Darüber hinaus erwägen wir hier die Einsparung von Zeitabhängigkeiten; das heißt, in unserem Modell folgt die Schlussfolgerung einem gerichteten azyklischen Graphen, wobei der übergeordnete Knoten jedes Knotens zeitlich früher und sein untergeordneter Knoten zeitlich später liegt, wodurch die bedingte Vorhersage eher kausal ist Intervention, weil dadurch bestimmte falsche Korrelationen beseitigt werden, die andernfalls zum Ungehorsam gegenüber der zeitlichen Kausalität führen würden. In diesem Artikel wird darauf hingewiesen, dass gemeinsame Modelle, die zeitliche Abhängigkeiten nicht bewahren, möglicherweise nur begrenzt in der Lage sind, tatsächliche Agentenreaktionen vorherzusagen, was eine wichtige Verwendung bei der Planung darstellt. Zu diesem Zweck verwendet dieser Artikel eine autoregressive Zerlegung des zukünftigen Decoders, bei der die Bewegungstokens des Agenten bedingt von allen zuvor abgetasteten Tokens abhängen und die Trajektorien sequentiell abgeleitet werden
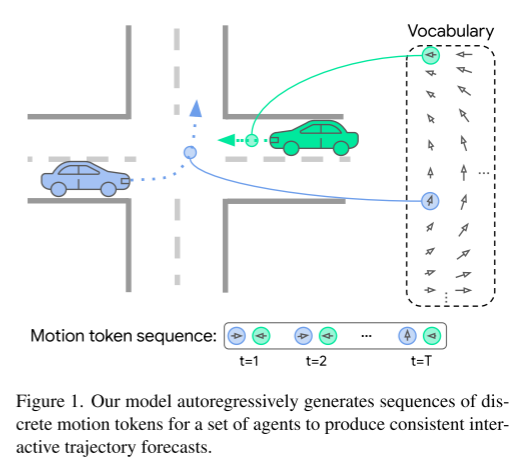
Abbildung 1. Unser Modell generiert autoregressiv Sequenzen diskreter Bewegungstokens für eine Reihe von Agenten, um konsistente interaktive Flugbahnvorhersagen zu erstellen.
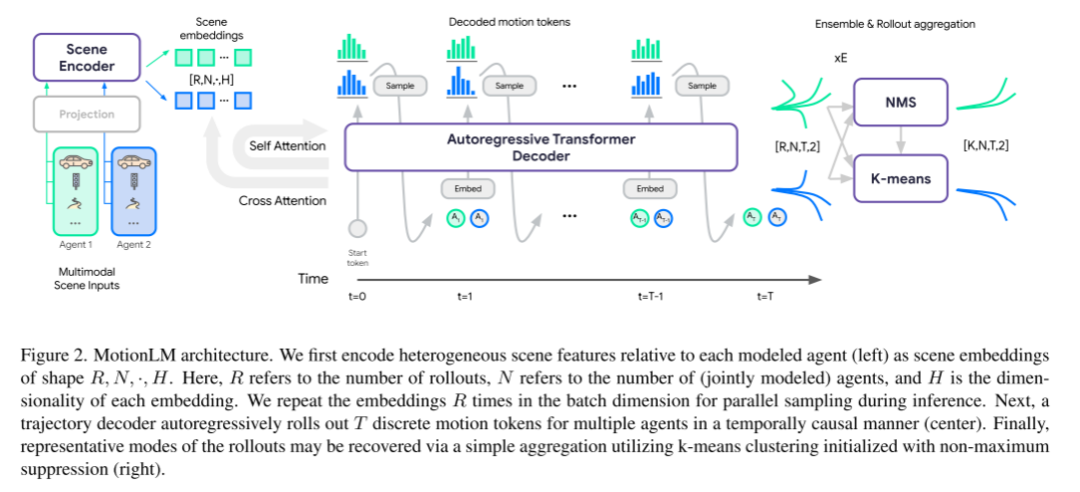
Siehe Abbildung 2, die die Architektur von MotionLM darstellt.
Dieser Artikel kodiert zunächst die heterogenen Szenenmerkmale (links), die jedem Modellierungsagenten zugeordnet sind, in Szeneneinbettungen der Form R, N,·,H. Darunter ist R die Anzahl der Rollouts, N die Anzahl der gemeinsam modellierten Agenten und H die Dimensionalität jeder Einbettung. Um während des Inferenzprozesses die Stichprobenentnahme zu parallelisieren, wiederholt dieser Artikel die Einbettung R-mal in der Batch-Dimension. Als nächstes rollt ein Trajektoriendecoder T diskrete Bewegungstokens für mehrere Agenten auf zeitlich kausale Weise aus (Mitte). Schließlich kann das typische Muster von Rollouts durch einfache Aggregation von k-Means-Clustern mithilfe einer Initialisierung mit nicht maximaler Unterdrückung wiederhergestellt werden (rechtes Feld).
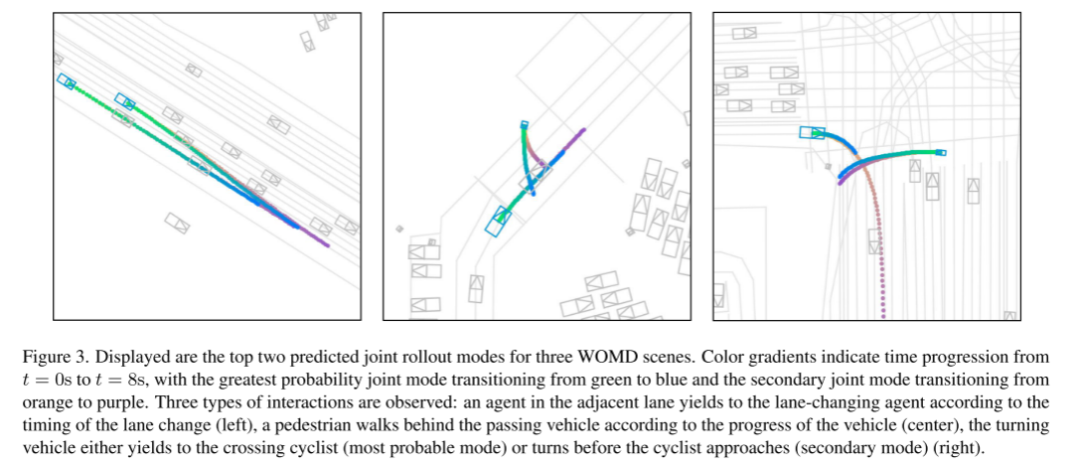
Bild 3. Es werden die ersten beiden Vorhersage-Joint-Rollout-Modi für drei WOMD-Szenarien gezeigt.
Der Farbverlauf stellt die Zeitänderung von t = 0 Sekunden bis t = 8 Sekunden dar. Der Gelenkmodus wechselt mit der höchsten Wahrscheinlichkeit von Grün nach Blau, und der Untergelenkmodus wechselt mit der höchsten Wahrscheinlichkeit von Orange nach Lila. Wir haben drei Arten von Interaktionen beobachtet: Agenten auf benachbarten Fahrspuren geben dem Spurwechselagenten entsprechend der Spurwechselzeit den Vortritt (links), Fußgänger gehen je nach Fortschritt des Fahrzeugs hinter vorbeifahrenden Fahrzeugen her (Mitte) und abbiegende Fahrzeuge tun dies Wird entweder einem vorbeifahrenden Radfahrer Vorfahrt gewähren (höchster Modus) oder abbiegen, bevor sich ein Radfahrer nähert (geringfügiger Modus) (rechte Seite)
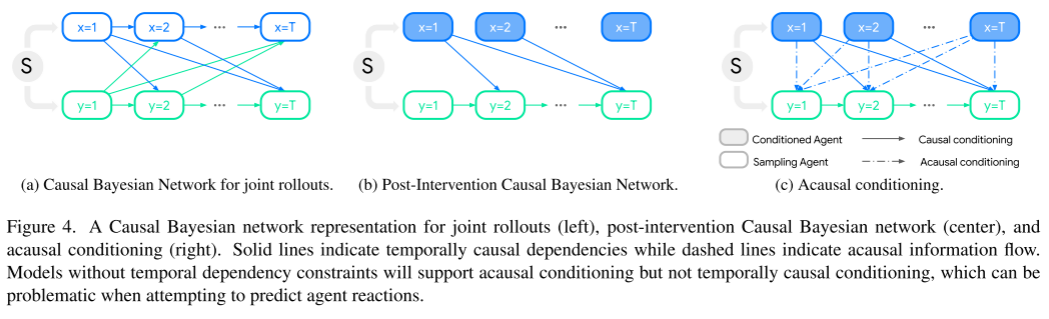
Siehe Abbildung 4. Diese Abbildung zeigt die kausale Bayes'sche Netzwerkdarstellung der Gelenkinduktion (links), das kausale Bayes'sche Netzwerk nach der Intervention (Mitte) und die kausale Konditionierung (rechts)
Die durchgezogenen Linien stellen kausale zeitliche Korrelationen dar, während gestrichelte Linien den kausalen Informationsfluss darstellen. Ein Modell ohne zeitabhängige Einschränkungen unterstützt die kausale Konditionierung, nicht jedoch die zeitliche kausale Konditionierung, was bei der Vorhersage von Agentenreaktionen problematisch sein kann.
Experimentelle Ergebnisse:
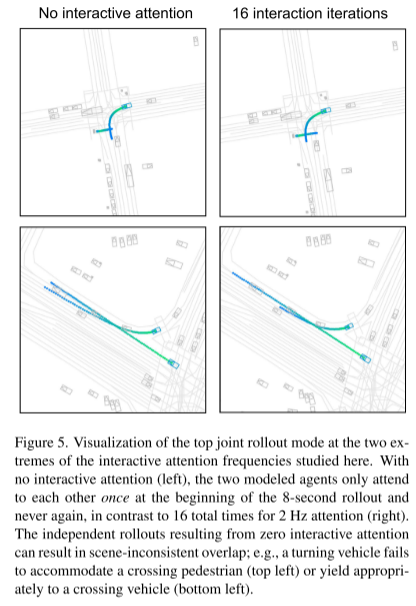
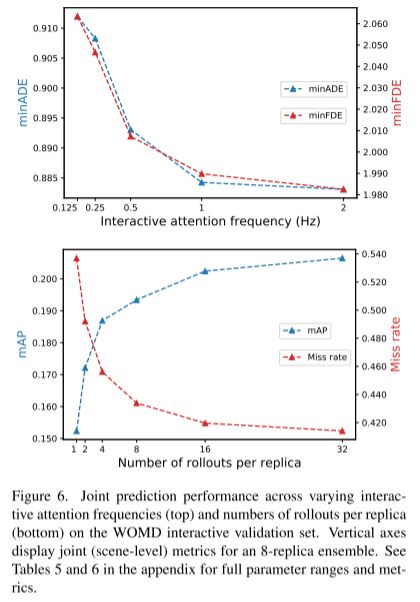
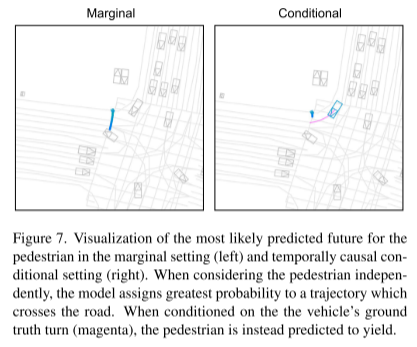
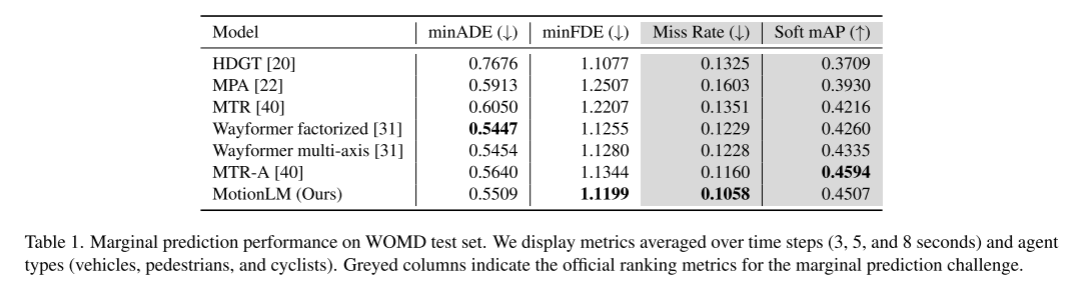
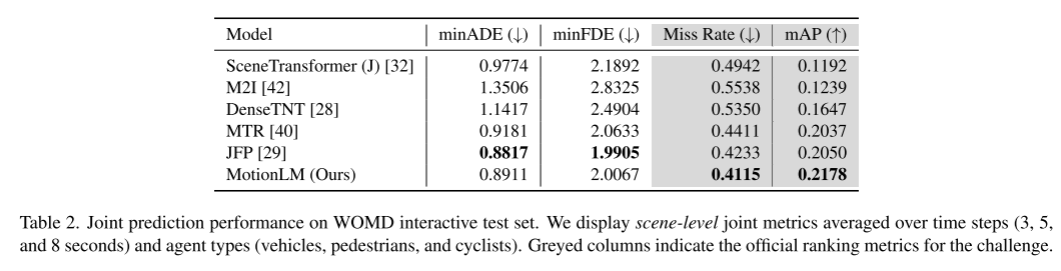
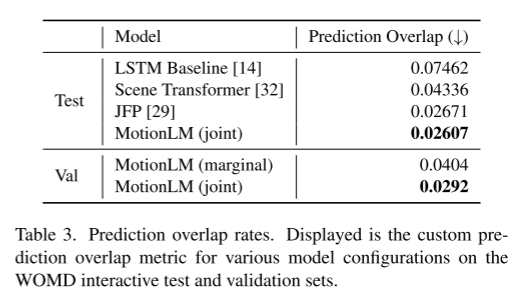

Zitat:
Seff, A., Cera, B., Chen, D. , Ng, M., Zhou, A., Nayakanti, N., Refaat, K. S., & Sapp, B. (2023: Multi-Agent Motion Forecasting as Language Modeling. ArXiv. /abs/2309.16534
). 
Originallink: https://mp.weixin.qq.com/s/MTai0rA8PeNFuj7UjCfd6A
Das obige ist der detaillierte Inhalt vonMotionLM: Sprachmodellierungstechnologie für die Bewegungsvorhersage mit mehreren Agenten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!