Welche Auswirkungen hat das Schneiden der Alpakahaare des Modells Llama 2? Heute hat das Chen Danqi-Team der Princeton University eine Methode zur Beschneidung großer Modelle namens LLM-Shearing vorgeschlagen, mit der mit geringem Rechen- und Kostenaufwand eine bessere Leistung als Modelle gleicher Größe erzielt werden kann.
Seit dem Aufkommen großer Sprachmodelle (LLM) haben sie bei verschiedenen Aufgaben der natürlichen Sprache bemerkenswerte Ergebnisse erzielt. Für das Training großer Sprachmodelle sind jedoch enorme Rechenressourcen erforderlich. Infolgedessen ist die Branche zunehmend daran interessiert, gleichermaßen leistungsstarke Modelle mittlerer Größe zu bauen, mit dem Aufkommen von LLaMA, MPT und Falcon, die eine effiziente Inferenz und Feinabstimmung ermöglichen. Diese LLMs unterschiedlicher Größe eignen sich für unterschiedliche Anwendungsfälle, aber das Training jedes einzelnen Modells von Grund auf (selbst eines kleinen Modells mit 1 Milliarde Parametern) erfordert immer noch viele Rechenressourcen, was für die meisten wissenschaftlichen Forschungen immer noch schwierig ist Institutionen. Es ist eine große Belastung. In diesem Artikel versucht das Chen Danqi-Team der Princeton University, das folgende Problem zu lösen: Können vorhandene vorab trainierte LLM verwendet werden, um ein kleineres, universelles und leistungswettbewerbsfähiges LLM aufzubauen und es gleichzeitig von Grund auf zu trainieren? Erfordert viel weniger Rechenaufwand? Forscher erforschen den Einsatz von strukturiertem Beschneiden, um ihre Ziele zu erreichen. Das Problem hierbei besteht darin, dass es bei Allzweck-LLMs zu Leistungseinbußen beim bereinigten Modell kommt, insbesondere wenn nach der Bereinigung kein erheblicher Rechenaufwand anfällt. Die von ihnen verwendete effiziente Pruning-Methode kann zur Entwicklung kleinerer, aber dennoch leistungswettbewerbsfähiger LLMs verwendet werden, und das Training erfordert deutlich weniger Rechenaufwand als das Training von Grund auf. 
- Papieradresse: https://arxiv.org/abs/2310.06694
- Codeadresse: https://github.com/princeton-nlp/LLM-Shearing
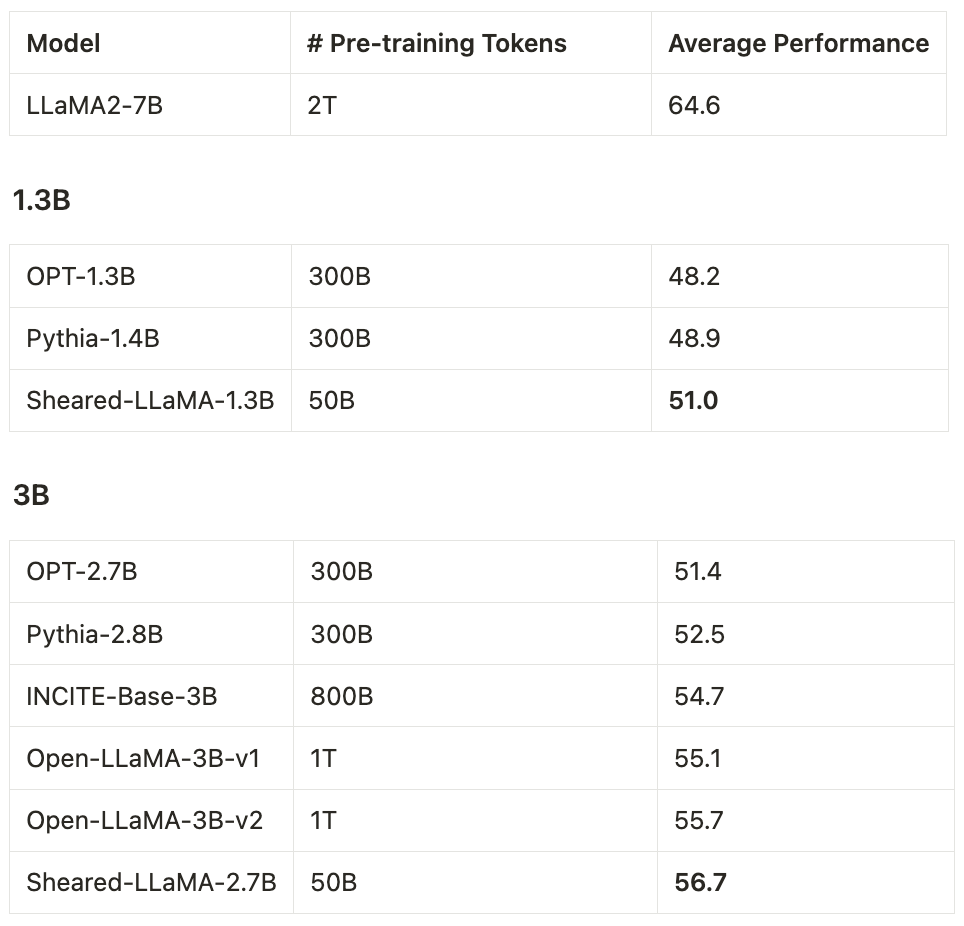
- ModelsSheared-LLaMA -1.3B, Sheared-LLaMA-2.7B
Vor dem Beschneiden von LLM identifizierten die Forscher zwei wichtige technische Herausforderungen: Wie lässt sich die endgültige Beschneidungsstruktur mit leistungsstarker Leistung und effizienter Argumentation bestimmen? Die aktuelle strukturierte Pruning-Technologie von LLM verfügt nicht über eine spezifizierte Zielstruktur, was zu einer unbefriedigenden Leistung und Inferenzgeschwindigkeit des bereinigten Modells führt. Zweitens: Wie kann das bereinigte Modell vorab trainiert werden, um die erwartete Leistung zu erreichen? Sie beobachteten, dass das Training mit Rohdaten vor dem Training zu unterschiedlichen Verlustreduzierungen in den verschiedenen Domänen führte, verglichen mit dem Training des Modells von Grund auf. Um diese beiden Herausforderungen anzugehen, schlugen Forscher den „LLM – Shearing“-Algorithmus vor. Dieser neuartige Bereinigungsalgorithmus, genannt „gerichtete strukturierte Bereinigung“, beschneidet das Quellmodell auf eine bestimmte Zielarchitektur, die durch die Konfiguration des vorhandenen vorab trainierten Modells bestimmt wird. Sie zeigen, dass die Pruning-Methode nach Unterstrukturen im Quellmodell sucht und die Leistung unter Ressourcenbeschränkungen maximiert. Darüber hinaus wurde ein dynamischer Batch-Ladealgorithmus entwickelt, der die Trainingsdaten jeder Domäne proportional zur Verlustreduzierungsrate laden kann, wodurch die Daten effizient genutzt und die Gesamtleistungsverbesserung beschleunigt wird. Schließlich zerlegte der Forscher das LLaMA2-7B-Modell in zwei kleinere LLMs, nämlich Sheared-LLaMA-1.3B und Sheared-LLaMA-2.7B, und bestätigte damit die Wirksamkeit seiner Methode.
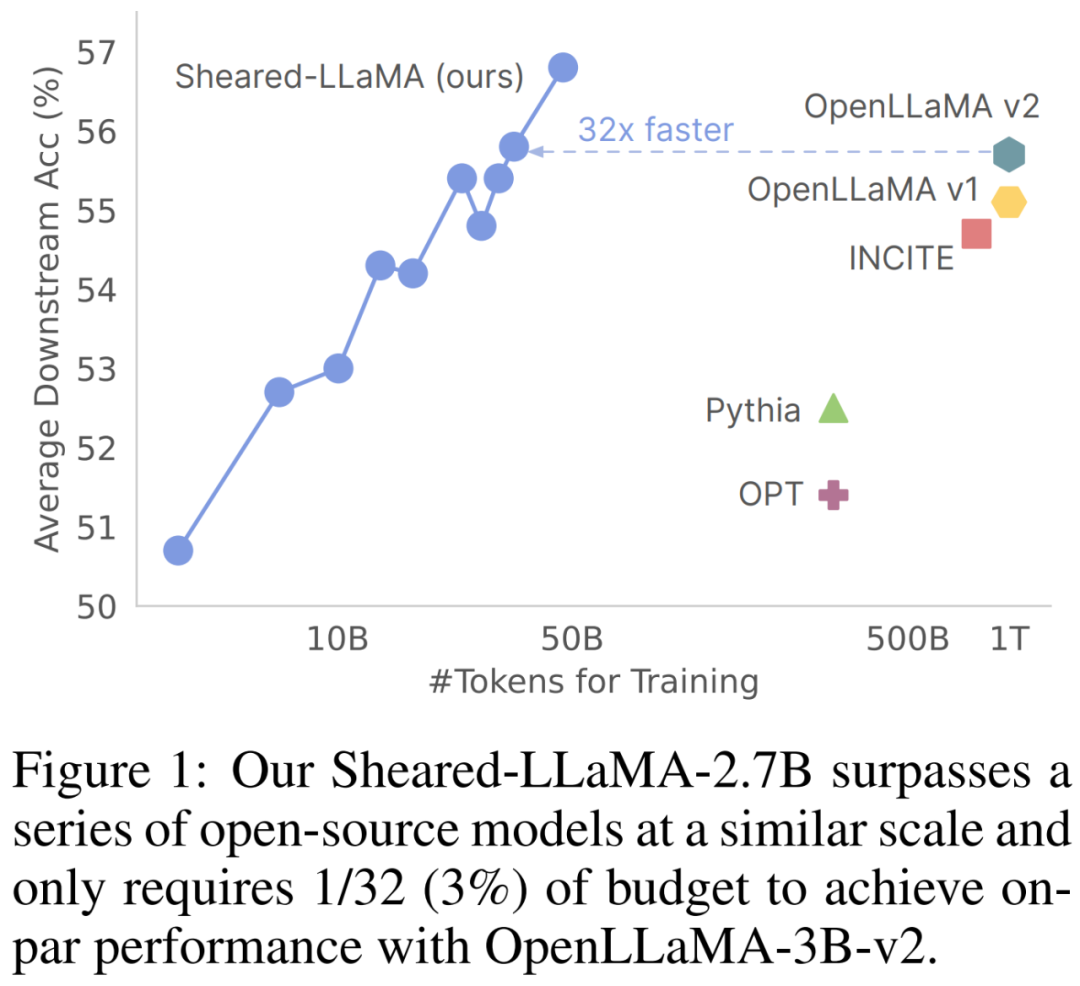
Sie verwendeten nur 50 Milliarden Token (d. h. 5 % des OpenLLaMA-Vortrainingsbudgets) für das Beschneiden und das weitere Vortraining, aber für 11 repräsentative nachgelagerte Aufgaben (wie Allgemeinwissen, Leseverständnis und Weltwissen) und Selbst mit der Anpassung der durch Formeln generierten Anweisungen übertrifft die Leistung dieser beiden Modelle immer noch andere beliebte LLMs derselben Größe, einschließlich Pythia, INCITE und OpenLLaMA.
Aber es sollte erwähnt werden, dass bei der Veröffentlichung von Sheared-LLaMA-3B in diesem Artikel der Rekord des stärksten 3B-Open-Source-Modells von StableLM-3B gebrochen wurde.
Darüber hinaus deuten nachgelagerte Aufgabenleistungsverläufe darauf hin, dass die Verwendung von mehr Token zum weiteren Trainieren des bereinigten Modells größere Vorteile bringt. Die Forscher experimentierten nur mit Modellen mit bis zu 7 Milliarden Parametern, aber LLM-Shearing ist sehr allgemein und kann in zukünftigen Arbeiten auf große Sprachmodelle jeder Größe ausgeweitet werden. Einführung in die MethodeAnhand eines vorhandenen großen Modells M_S (Quellmodell) besteht das Ziel dieses Artikels darin, zu untersuchen, wie effektiv ein kleineres und stärkeres Modell M_T (Zielmodell) generiert werden kann. Die Studie geht davon aus, dass hierfür zwei Stufen erforderlich sind:
- Die erste Stufe beschneidet M_S auf M_T. Dies führt zwar zwangsläufig zu einer Leistungsverschlechterung;
- Die zweite Stufe ist ein kontinuierliches Vortraining M_T, um seine Leistung zu steigern.
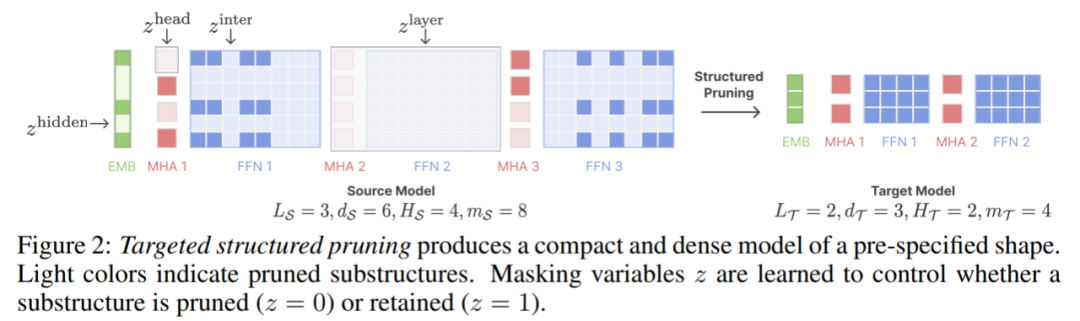
Strukturierte BeschneidungStrukturierte Beschneidung kann eine große Anzahl von Parametern des Modells entfernen, wodurch der Effekt einer Komprimierung des Modells und einer Beschleunigung der Inferenz erzielt wird. Allerdings können bestehende strukturierte Bereinigungsmethoden dazu führen, dass Modelle von herkömmlichen Architekturkonfigurationen abweichen. Beispielsweise erzeugt die CoFiPruning-Methode Modelle mit uneinheitlichen Schichtkonfigurationen, was im Vergleich zu standardmäßigen einheitlichen Schichtkonfigurationen einen zusätzlichen Inferenzaufwand mit sich bringt. Dieser Artikel erweitert CoFiPruning, um das Beschneiden des Quellmodells auf jede angegebene Zielkonfiguration zu ermöglichen. In diesem Artikel wird beispielsweise die INCITE-Base-3B-Architektur als Zielstruktur beim Generieren des 2.7B-Modells verwendet. Darüber hinaus lernt dieser Artikel auch eine Reihe von Beschneidungsmasken (Beschneidungsmasken) für Modellparameter unterschiedlicher Granularität kennen. Die Maskenvariablen lauten wie folgt:
Jede Maskenvariable steuert, ob relevante Unterstrukturen beschnitten werden sollen bleiben erhalten. Wenn beispielsweise die entsprechende z^layer= 0 ist, muss diese Ebene gelöscht werden. Abbildung 2 unten zeigt, wie Beschneidungsmasken steuern, welche Strukturen beschnitten werden.
Nach dem Bereinigen finalisieren wir die beschnittene Architektur, indem wir die Komponenten mit der höchsten Bewertung in Bezug auf die Maskenvariablen in jeder Unterstruktur beibehalten und fahren mit der Vorbereinigung des beschnittenen Modells mithilfe des Sprachmodellierungsziels fort. Diese Studie geht davon aus, dass ein umfassendes Vortraining der beschnittenen Modelle erforderlich ist, um die Modellleistung wiederherzustellen. Inspiriert von anderen Forschungsergebnissen schlägt dieses Papier einen effizienteren Algorithmus vor, das dynamische Stapelladen, mit dem die Domänenskala einfach basierend auf der Modellleistung dynamisch angepasst werden kann. Der Algorithmus lautet wie folgt:
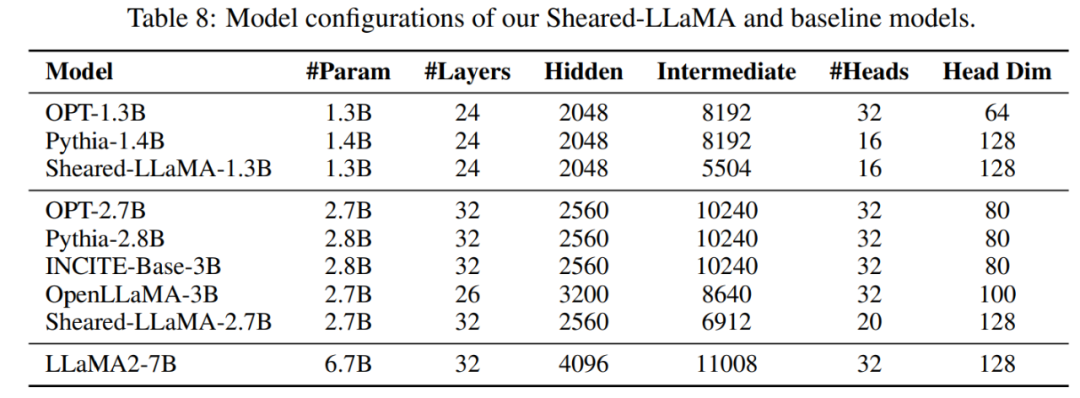
Experimente und ErgebnisseModellkonfiguration: Dieser Artikel verwendet das LLaMA2-7B-Modell als Quellmodell und führt dann strukturierte Bereinigungsexperimente durch zwei kleinere. Die Zielgröße beträgt 2,7B und 1,3B, und die Leistung des gescherten Modells wird mit Modellen derselben Größe verglichen, einschließlich OPT-1.3B, Pythia-1.4B, OPT-2.7B, Pythia-2.8 B, INCITE-Base -3B, OpenLLaMA-3B-v1, OpenLLaMA-3B-v2. Tabelle 8 fasst die Modellarchitekturdetails für alle diese Modelle zusammen.
Daten: Da die Trainingsdaten von LLaMA2 nicht öffentlich zugänglich sind, verwendet dieser Artikel den RedPajama-Datensatz. Tabelle 1 enthält die von unserem Modell und Basismodell verwendeten Vortrainingsdaten.
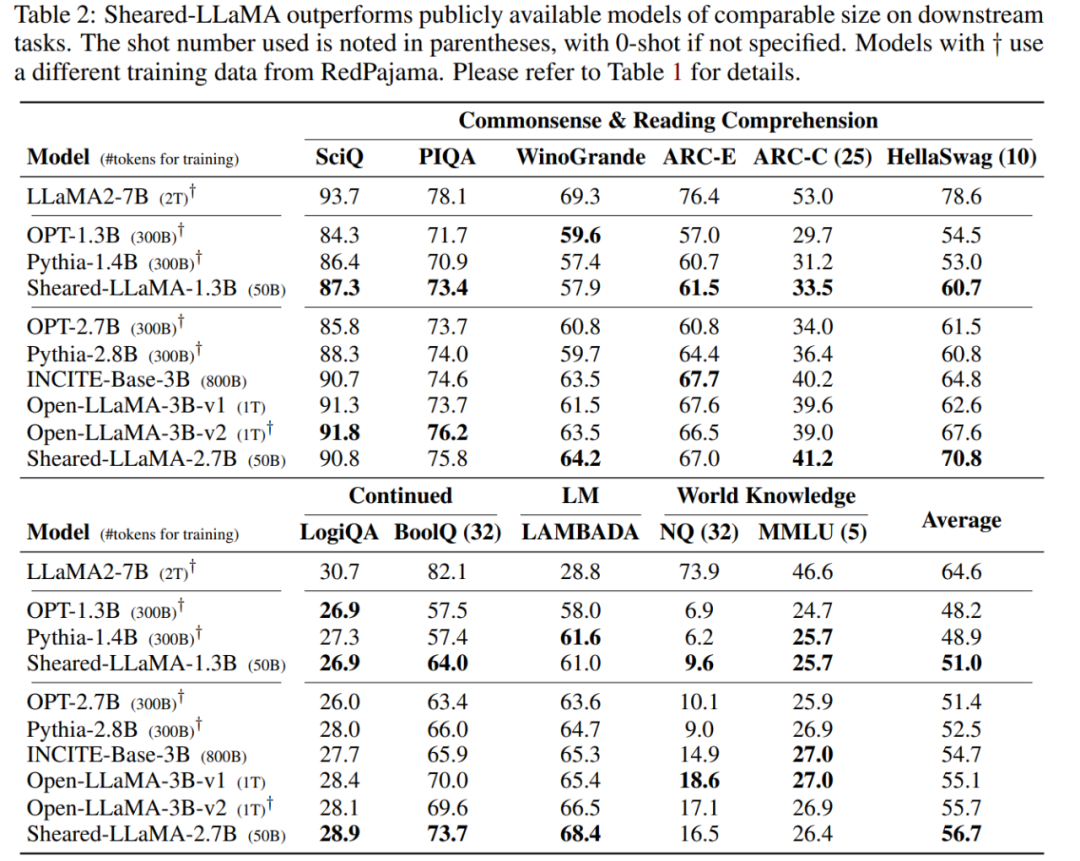
Training: Die Forscher verwendeten in allen Experimenten bis zu 16 Nvidia A100 GPUs (80 GB). SHEARED-LLAMA übertrifft LMs vergleichbarer GrößeDieser Artikel zeigt, dass Sheared-LLaMA bestehende LLMs ähnlicher Größe deutlich übertrifft und dabei nur einen Bruchteil des Rechenbudgets verbraucht, um diese Modelle von Grund auf zu trainieren. Downstream-Aufgaben: Tabelle 2 zeigt die Null-Schuss- und Wenig-Schuss-Leistung von Sheared-LLaMA und vorhandenen vorab trainierten Modellen ähnlicher Größe bei Downstream-Aufgaben.
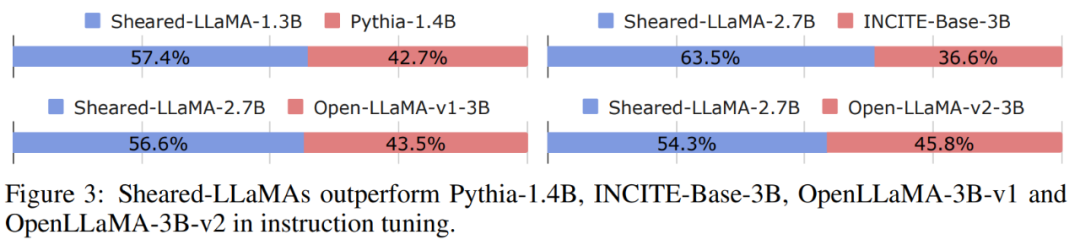
Anweisungsabstimmung: Wie in Abbildung 3 dargestellt, erzielt das auf Anweisungen abgestimmte Sheared-LLaMA eine höhere Gewinnquote im Vergleich zu allen anderen vorab trainierten Modellen desselben Maßstabs.
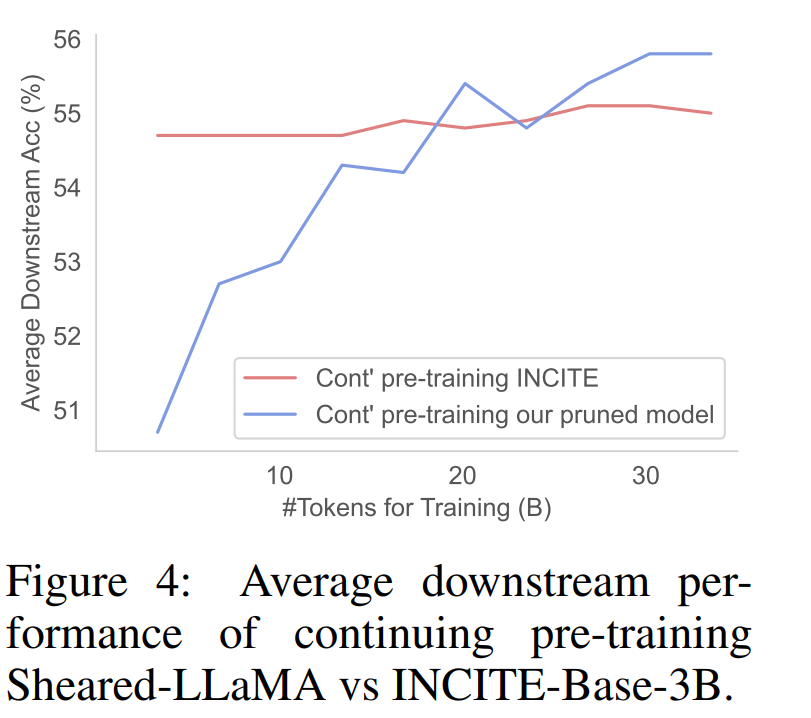
Abbildung 4 zeigt, dass das INCITEBase-3B-Modell mit einer viel höheren Genauigkeit beginnt, seine Leistung jedoch während des laufenden Vortrainingsprozesses abflacht.
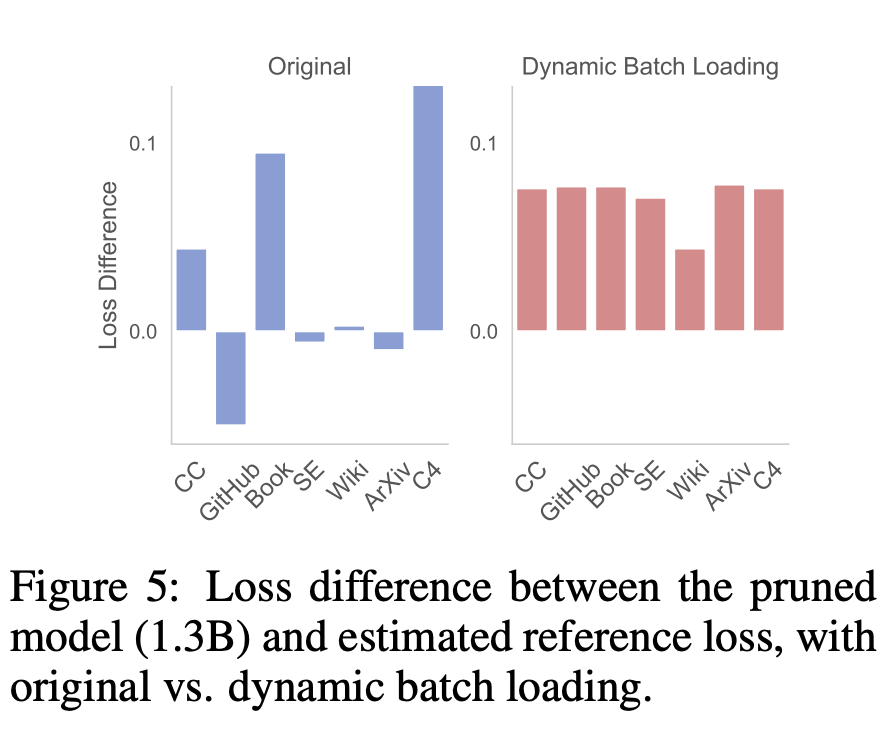
Abschließend analysierte der Forscher die Vorteile dieser Methode. Wirksamkeit des dynamischen StapelladensUnter anderem analysieren Forscher die Wirksamkeit des dynamischen Stapelladens anhand der folgenden drei Aspekte: (1) domänenübergreifender endgültiger LM-Verlust, (2) Datennutzung für jede Domäne während des gesamten Trainingsprozesses, (3) nachgelagerte Aufgabenleistung. Die Ergebnisse basieren auf dem Sheared-LaMA-1.3B-Algorithmus. Domainübergreifender Verlustunterschied. Der Zweck des dynamischen Stapelladens besteht darin, die Verlustreduzierungsrate jeder Domäne so auszugleichen, dass der Verlust den Referenzwert in ungefähr derselben Zeit erreicht. Der Unterschied zwischen dem Modellverlust (ursprüngliches Batch-Laden und dynamisches Batch-Laden) und dem Referenzverlust ist in Abbildung 5 dargestellt. Im Gegensatz dazu reduziert das dynamische Batch-Laden den Verlust gleichmäßig und der Verlustunterschied zwischen den Domänen ist ebenfalls sehr ähnlich, was dies zeigt die Daten effizienter nutzen.
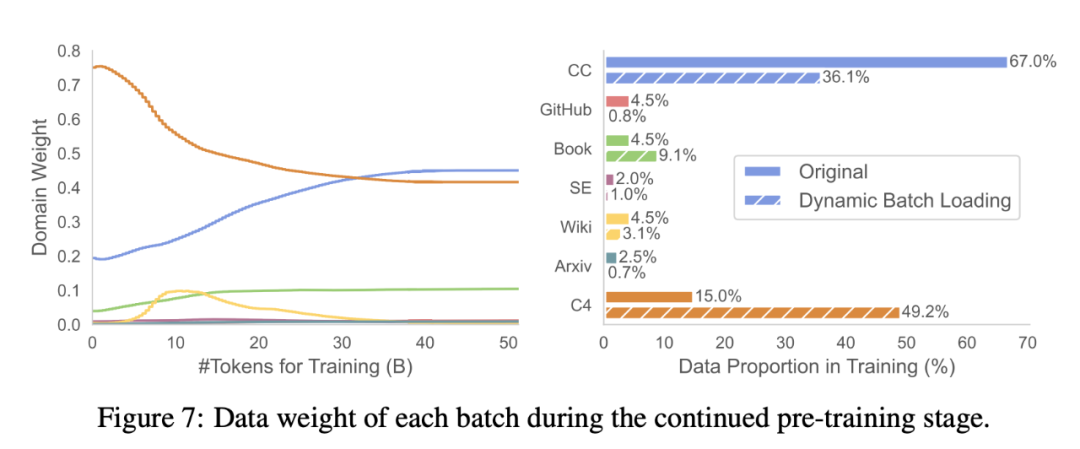
Datennutzung. Tabelle 3 vergleicht die Rohdatenanteile von RedPajama und die Nutzung dynamisch geladener Domänendaten (Abbildung 7 zeigt die Änderungen der Domänengewichte während des Trainingsprozesses). Dynamisches Massenladen erhöht die Gewichtung der Book- und C4-Domänen im Vergleich zu anderen Domänen, was darauf hindeutet, dass diese Domänen aus dem bereinigten Modell schwieriger wiederherzustellen sind.
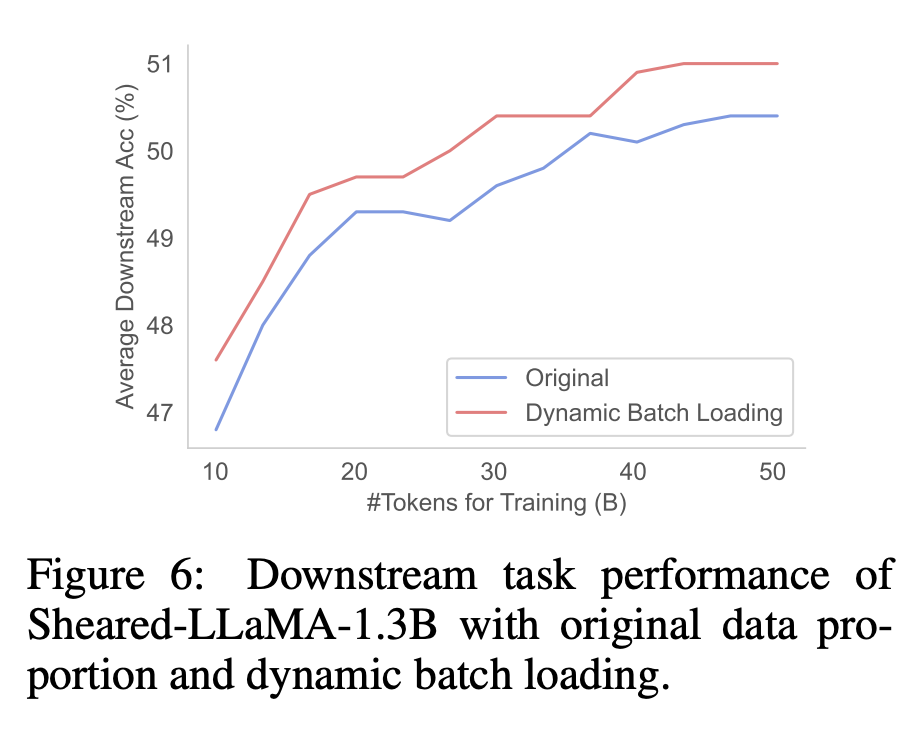
Downstream-Leistung. Wie in Abbildung 6 dargestellt, erzielte das bereinigte Modell, das mit dynamischem Batch-Laden trainiert wurde, eine bessere Downstream-Leistung im Vergleich zu dem Modell, das mit der ursprünglichen RedPajama-Verteilung trainiert wurde. Dies deutet darauf hin, dass die ausgewogenere Verlustreduzierung durch dynamisches Batch-Laden die Downstream-Leistung verbessern kann.
Vergleich mit anderen BeschneidungsmethodenDarüber hinaus verglichen die Forscher die LLM-Schermethode mit anderen Beschneidungsmethoden und berichteten über die Validierungsperplexität, die ein Maß für die Gesamtfähigkeit des Modells und ein aussagekräftiger Indikator ist. Aufgrund rechnerischer Einschränkungen steuern die folgenden Experimente das gesamte Rechenbudget aller verglichenen Methoden, anstatt jede Methode bis zum Ende auszuführen. Wie in Tabelle 4 gezeigt, ist der Inferenzdurchsatz des Zielbeschneidungsmodells in diesem Artikel bei gleicher Sparsity höher als der des CoFiPruning-Modells mit ungleichmäßigem Beschneiden, aber die Verwirrung ist etwas höher.
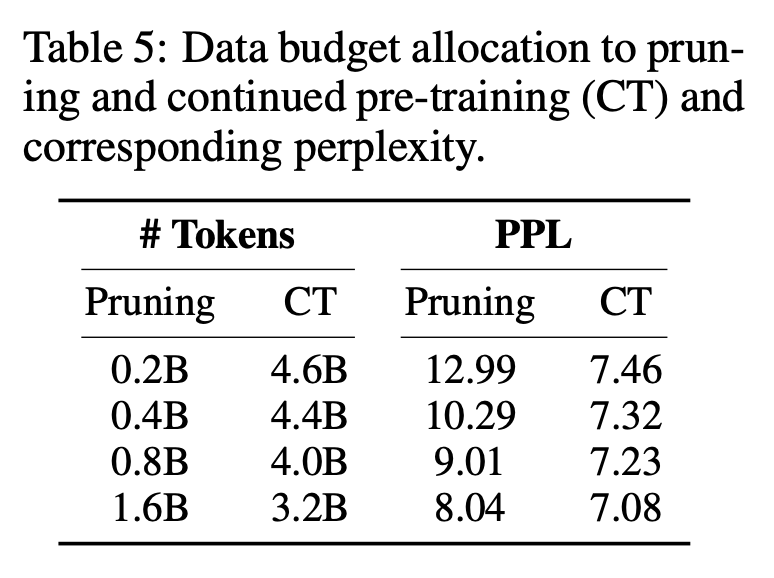
Tabelle 5 zeigt, dass eine Erhöhung des Beschneidungsaufwands die Perplexität kontinuierlich verbessern und gleichzeitig die Gesamtmenge der Token kontrollieren kann. Da das Beschneiden jedoch teurer ist als ein kontinuierliches Vortraining, weisen die Forscher dem Beschneiden 0,4 Milliarden Token zu.
Weitere Forschungsdetails finden Sie im Originalpapier. Das obige ist der detaillierte Inhalt vonDas Team von Chen Danqi bringt Ihnen Schritt für Schritt bei, wie man „Alpaka' schert, und schlägt die LLM-Shearing-Methode zum Beschneiden großer Modelle vor. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!