
Heim >Technologie-Peripheriegeräte >KI >Praktische Anwendung des Kaltstart-Empfehlungsmodells für Kuaishou-Inhalte
Praktische Anwendung des Kaltstart-Empfehlungsmodells für Kuaishou-Inhalte

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-10-12 08:17:151088Durchsuche

1. Welche Probleme löst Kuaishous Kaltstart?
Kurzfristig muss die Plattform zunächst dafür sorgen, dass mehr neue Videos Traffic generieren, also verbreitet werden können. Gleichzeitig muss der ausgesendete Verkehr effizienter werden. Langfristig werden wir auch weitere neue Videos mit hohem Potenzial erkunden und auswerten, um dem gesamten beliebten Pool mehr frisches Blut zu verleihen und den ökologischen Matthew-Effekt zu mildern. Stellen Sie mehr qualitativ hochwertige Inhalte bereit, verbessern Sie das Benutzererlebnis und erhöhen Sie außerdem die Dauer und DAU. 
Verwenden Sie Kaltstart, um UGC-Autoren zu fördern und interaktive Feedback-Anreize zu erhalten, um die Bindung des gesamten Produzenten aufrechtzuerhalten. In diesem Prozess gibt es zwei Einschränkungen. Erstens sollten die gesamten Explorations- und Verkehrskosten im Großen und Ganzen relativ stabil sein. Zweitens greifen wir nur im niedrigen VV-Stadium in die Verbreitung neuer Videos ein. Wie können wir also unter diesen Einschränkungen den Gesamtnutzen maximieren?
Die Kaltstartverteilung von Videos hat einen wichtigen Einfluss auf ihren Wachstumsraum, insbesondere wenn die Arbeit an Personen verteilt wird, die nicht ihren Interessen entsprechen, hat dies zwei Auswirkungen. Erstens wird das Wachstum des Autors beeinträchtigt. Auf lange Sicht wird er keine wirksamen interaktiven Verkehrsanreize erhalten, was zu Änderungen in seiner Einreichungsrichtung und -bereitschaft führen wird. Zweitens wird das System aufgrund des Fehlens einer effektiven Conversion-Rate im frühen Traffic den Inhalt als minderwertig einstufen und daher auf lange Sicht keine ausreichende Traffic-Unterstützung erhalten und somit kein Wachstum erzielen können
Wenn es so weitergeht, wird das Ökosystem in einen vergleichsweise schlechten Zustand geraten. Wenn es beispielsweise ein Werk über lokales Essen gibt, muss es die am besten geeignete Zielgruppe A haben und die Gesamtaktionsrate ist am höchsten. Darüber hinaus kann es eine völlig unabhängige Personengruppe C geben. Bei der Abstimmung für diese Personengruppe liegt ein gewisses Maß an Selektivität vor und die Aktionsquote kann äußerst niedrig sein. Natürlich gibt es auch eine dritte Art von Gruppe B, bei der es sich um eine Gruppe mit sehr breiten Interessen handelt. Obwohl diese Personengruppe einen großen Zustrom aufweist, wird die Gesamtaktionsrate dieser Personengruppe niedrig sein.
Wenn wir die Kerngruppe A so früh wie möglich erreichen, um die frühe Interaktionsrate der Inhalte zu erhöhen, können wir eine wirksame Verteilung des natürlichen Traffics bewirken. Wenn wir jedoch in der Anfangsphase zu viel Traffic für Crowd C oder Crowd B bereitstellen, führt dies zu einer niedrigen Gesamtaktionsrate und begrenzt deren Wachstum. Alles in allem ist die Verbesserung der Effizienz der Kaltstartverteilung der wichtigste Weg, um Content-Wachstum zu erreichen. Um die Iteration der Kaltstarteffizienz von Inhalten abzuschließen, werden wir einige Zwischenprozessindikatoren und endgültige Langzeitindikatoren festlegen.
Der neu geschriebene Inhalt ist: Die Prozessindikatoren sind hauptsächlich in zwei Teile unterteilt Erkundungsrichtung, Nutzungsorientierung und ökologische Ausrichtung. Die Explorationsrichtung besteht darin, sicherzustellen, dass hochwertige neue Videos nicht ignoriert werden, wobei vor allem das Wachstum der Anzahl von Videos mit Belichtungen über 0 und Belichtungen über 100 beobachtet wird. Verwenden Sie Xiangsi, um das Wachstum der Anzahl beliebter Videos mit hohem VV und hochwertiger neuer Videos zu beobachten. Die ökologische Richtung beobachtet hauptsächlich die Benutzerpenetrationsrate beliebter Schwimmbäder. Da es sich hierbei um eine langfristige Veränderung handelt, die durch ökologische Auswirkungen verursacht wird, werden wir letztendlich Combo-Experimente verwenden, um langfristig die sich ändernden Trends einiger Kernindikatoren zu beobachten, darunter APP-Dauer, Autor-DAU und Gesamt-DAU
2. Herausforderungen und Lösungen für die Kaltstartmodellierung
Im Allgemeinen gibt es drei Hauptschwierigkeiten beim Kaltstart von Inhalten. Erstens gibt es einen großen Unterschied zwischen dem Beispielraum des Inhaltskaltstarts und dem realen Lösungsraum. Zweitens sind die Stichproben des Kaltstarts von Inhalten sehr spärlich, was zu ungenauen Lernergebnissen und sehr großen Abweichungen führt, insbesondere im Hinblick auf die Belichtungsverzerrung. Drittens stellt auch die Modellierung des Wachstumswerts von Videos eine Schwierigkeit dar, an deren Lösung wir derzeit ebenfalls hart arbeiten. Dieser Artikel konzentriert sich auf die Schwierigkeiten in den ersten beiden Aspekten
1. Das Problem, dass der Probenraum viel kleiner ist als der tatsächliche Lösungsraum
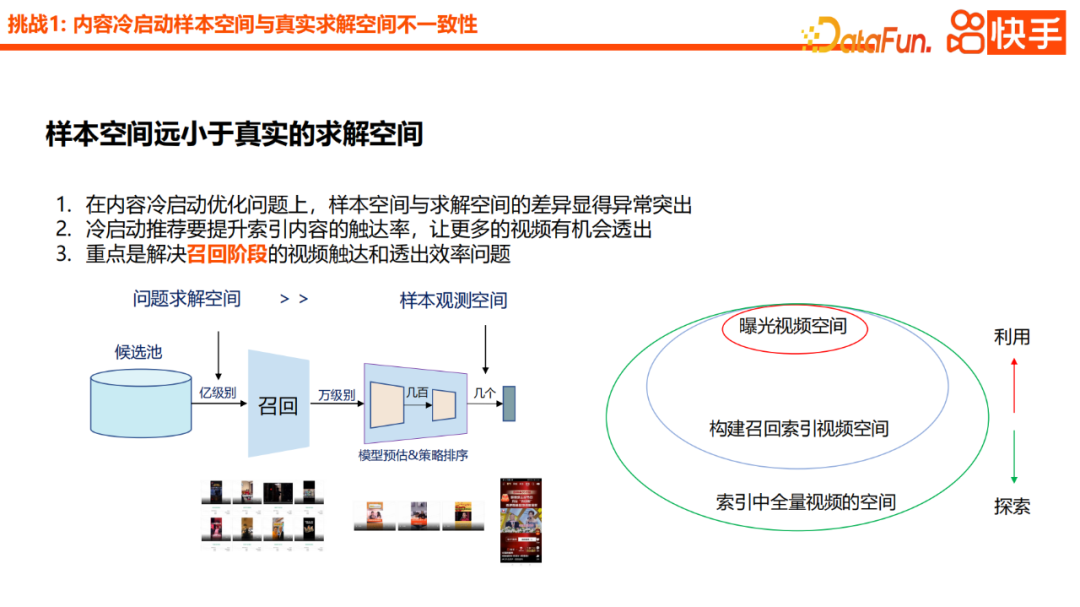
Bei der Optimierung des Inhaltskaltstartproblems ist es ein sehr wichtiges Problem, dass der Probenraum kleiner ist als der Lösungsraum. Insbesondere im Hinblick auf den Kaltstart empfohlener Inhalte ist es notwendig, die Reichweite indizierter Inhalte zu erhöhen, damit mehr Videos angezeigt werden können
Wir glauben, dass es zur Lösung dieses Problems am wichtigsten ist, die Reichweite zu erhöhen die Reichweitenrate von Videos während der Recall-Phase. Um die Rückrufreichweite von Kaltstartvideos zu ermitteln. Der in der Branche übliche Ansatz basiert auf Content-Based, einschließlich Attributinversion, einigen auf semantischer Ähnlichkeit basierenden Rückrufmethoden oder einem auf Zwillingstürmen plus Generalisierungsfunktionen basierenden Rückrufmodell oder der Einführung einer Zuordnung zwischen Verhaltensraum und Inhaltsraum, ähnlich Basierend auf dem Ansatz von CB2CF.
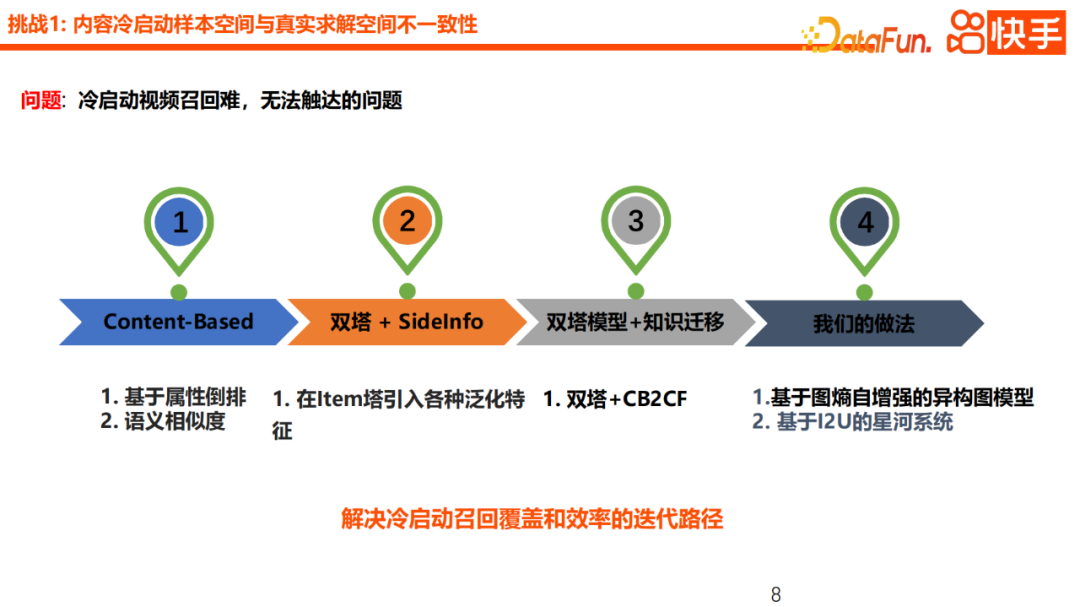
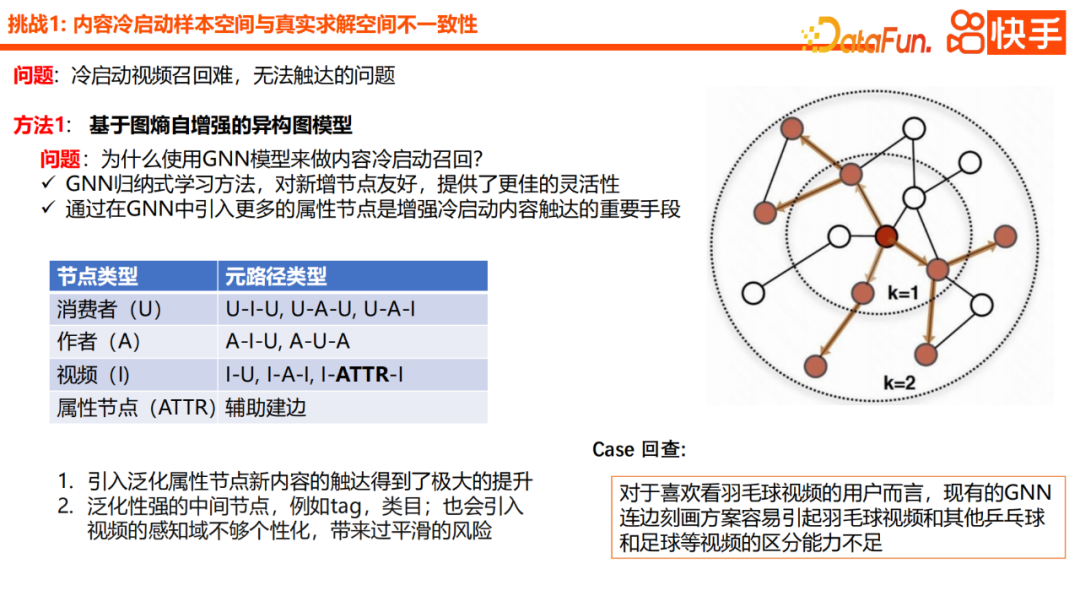
Dieses Mal konzentrieren wir uns auf zwei interessante neue Methoden, nämlich das heterogene Graphnetzwerk basierend auf Graph Entropy Self-Enhancement und das Galaxienmodell basierend auf I2U. In Bezug auf die Technologieauswahl verwenden wir zunächst GNN als Basismodell für den Kaltstart von U2I-Inhalten. Da wir GNN insgesamt als eine induktive Lernmethode betrachten, ist es sehr freundlich zu neuen Knoten und bietet mehr Flexibilität. Darüber hinaus führt GNN weitere Attributknoten ein, was ein wichtiges Mittel zur Verbesserung des Zugriffs auf Kaltstartinhalte darstellt. Im Hinblick auf die konkrete Praxis werden wir auch Benutzerknoten, Autorenknoten und Artikelknoten einführen und die Aggregation von Informationen abschließen. Nach der Einführung dieses verallgemeinerten Attributknotens wurde die Gesamtreichweite neuer Inhalte erheblich verbessert. Zu allgemeine Zwischenknoten wie Tag-Kategorien führen jedoch auch dazu, dass der Wahrnehmungsbereich des Videos nicht ausreichend personalisiert ist, was die Gefahr einer übermäßigen Glättung mit sich bringt. Bei der Fallbesprechung haben wir herausgefunden, dass das bestehende GNN-Charakterisierungsschema bei einigen Benutzern, die gerne Badminton-Videos ansehen, leicht zu einer schlechten Unterscheidung zwischen Badminton-Videos und anderen Tischtennis-, Fußball- und anderen Videos führen kann.
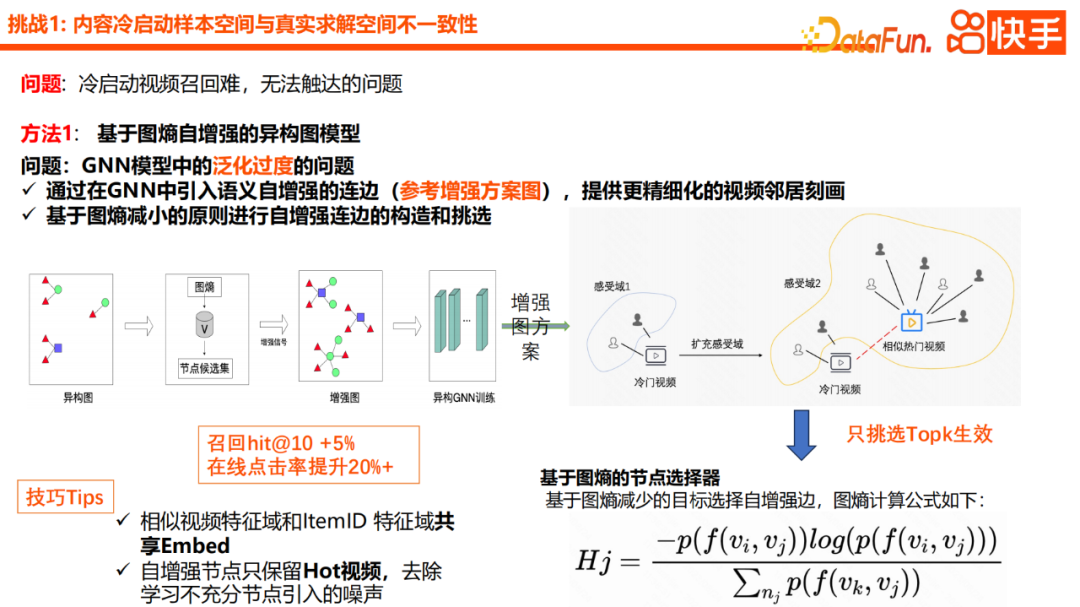
Um das Problem der Übergeneralisierung zu lösen, das durch die Einführung zu vieler Generalisierungsinformationen in den GNN-Modellierungsprozess verursacht wird, besteht unsere Hauptidee darin, ein detaillierteres Nachbarschaftscharakterisierungsschema einzuführen. Insbesondere werden wir semantische Automatisierung einführen GNN. Kanten verbessern. Wie Sie auf dem Bild in der unteren rechten Ecke sehen können, verwenden wir das unbeliebte Video, um ähnliche beliebte Videos im beliebten Bereich zu finden, und verwenden dann die beliebten ähnlichen Videos als Anfangsknoten der Kaltstartverbindung. Im spezifischen Aggregationsprozess werden wir selbstverstärkende Kanten basierend auf dem Prinzip der Graphentropiereduktion konstruieren und auswählen. Der spezifische Auswahlplan ist aus der Formel ersichtlich, die hauptsächlich die obige Beschreibung des verbundenen Nachbarknotens und die aktuellen Knoteninformationen berücksichtigt. Wenn die Ähnlichkeit zwischen zwei Knoten höher ist, ist ihre Informationsentropie kleiner. Der Knotennenner unten stellt das Gesamtwahrnehmungsfeld des Nachbarknotens dar. Es kann auch verstanden werden, dass wir im Auswahlprozess lieber einen Nachbarknoten mit stärkerer Wahrnehmung finden. In der Praxis haben wir hauptsächlich zwei Tipps: Einer davon ist das Merkmal Die Domäne ähnlicher Videos und die Funktionsdomäne der Artikel-ID sollten sich den Einbettungsraum teilen, und dann behält der Selbstverbesserungsknoten nur beliebte Videos bei, um das durch unzureichende Lernknoten verursachte Rauschen zu beseitigen. Mit diesem Upgrade ist die allgemeine Generalisierung vollständig gewährleistet, was den Grad der Personalisierung des Modells effektiv verbessert und verbesserte Offline- und Online-Effekte mit sich bringt.
Die oben genannten Methoden stellen tatsächlich eine Verbesserung bei der Modellierung der Inhaltsreichweite aus U2I-Perspektive dar, können jedoch das Problem der Nichterreichbarkeit von Videos nicht grundsätzlich lösen Richtige Leute, das heißt, wechseln Sie zur I2U-Perspektive. Theoretisch hat jedes Video Platz, um Traffic zu erhalten.
Der spezifische Ansatz besteht darin, dass wir einen I2U-Abrufdienst trainieren und diesen Abrufdienst verwenden müssen, um interessierte Gruppen für jedes Video dynamisch abzurufen. Durch diese I2U-Kompositionsmethode wird der invertierte Index von U2I umgekehrt erstellt und schließlich wird die Artikelliste gemäß der Echtzeitanforderung des Benutzers als Kaltstart-Empfehlungsliste zurückgegeben

Der neu geschriebene Inhalt ist: Der Fokus besteht darin, ein I2U zu trainieren. Unsere erste Version des Rückholdienstes war ein Zwei-Turm-Modell. Um das Problem einer übermäßigen Benutzerkonzentration zu vermeiden, werden wir in der Praxis zunächst UID aufgeben und Aktionslisten und Selbstaufmerksamkeit verwenden, um das Problem der Benutzerkonzentration wirksam zu lindern. Gleichzeitig werden wir die Item-ID aufgeben und allgemeinere Funktionen wie semantische Vektoren, Kategorien, Tags und AuthorID einführen, um die durch die Item-ID während des Lernprozesses verursachte Lernexpositionsverzerrung zu vermeiden, um die Item-ID effektiv zu entlasten. Aggregation von IDs. Aus Sicht des Benutzers wird diese Art von Debias-Verlust eingeführt, und dann wird eine negative Probenahme innerhalb der Charge eingeführt, um das Problem der Benutzerkonzentration besser zu vermeiden
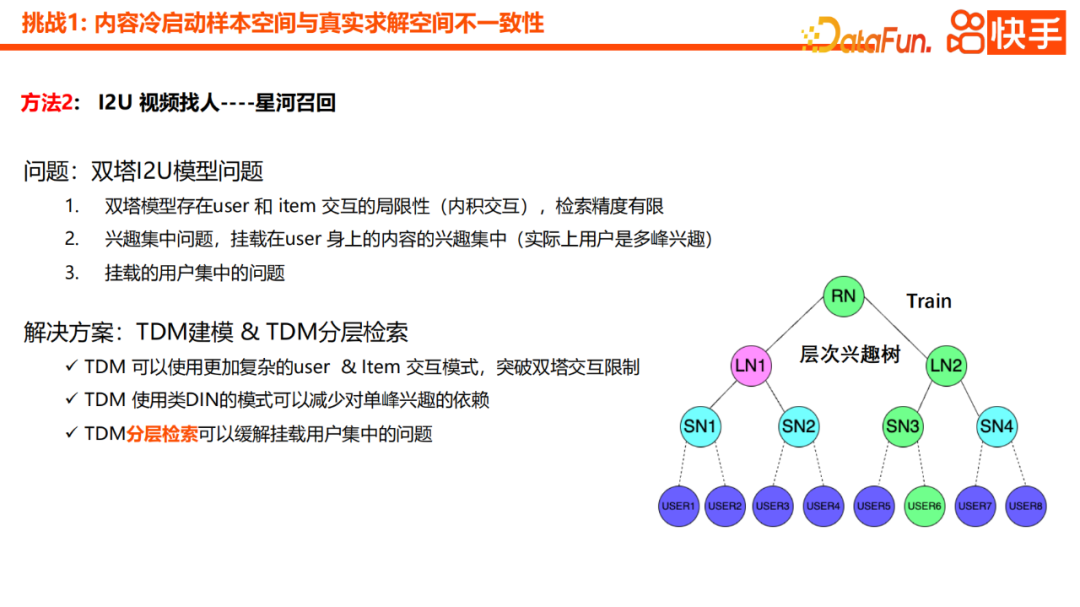
Unsere erste Version der Praxis ist das Twin-Tower-I2U-Modell . Einige Probleme wurden auch während der Praxis entdeckt. Erstens weist das Zwei-Turm-Modell Einschränkungen bei der Interaktion zwischen Benutzern und Artikeln auf, und die allgemeine Abrufgenauigkeit ist begrenzt. Darüber hinaus besteht auch das Problem der Konzentration von Interessen. Inhalte, die auf Benutzer zugeschnitten sind, weisen häufig sehr konzentrierte Interessen auf, tatsächlich sind die Interessen der Benutzer jedoch multimodal verteilt. Wir haben auch festgestellt, dass die meisten Kaltstartvideos bei einigen Top-Benutzern installiert sind, da schließlich auch die Inhalte, die Top-Benutzer täglich konsumieren können, begrenzt sind Für die oben genannten drei Probleme besteht die neue Lösung in der TDM-Modellierung und der hierarchischen TDM-Abrufmethode. Ein Vorteil von TDM besteht darin, dass es komplexere Benutzer-Objekt-Interaktionsmodi einführen und die Interaktionsbeschränkungen der Twin Towers überwinden kann. Die zweite besteht darin, ein DIN-ähnliches Muster zu verwenden, das die Abhängigkeit von unimodalen Zinsen verringert. Schließlich kann die Einführung des hierarchischen Abrufs in TDM das Problem der zunehmenden Benutzerkonzentration sehr effektiv lindern.
Darüber hinaus haben wir einen effektiveren Optimierungspunkt, der darin besteht, die aggregierte Darstellung der untergeordneten Knoten zum übergeordneten Knoten hinzuzufügen. Dies kann die Merkmalsverallgemeinerung und die Unterscheidungsgenauigkeit des übergeordneten Knotens verbessern. Mit anderen Worten, wir werden untergeordnete Knoten über den Aufmerksamkeitsmechanismus zu übergeordneten Knoten aggregieren, und durch schichtweise Übertragung können die Zwischenknoten auch über bestimmte semantische Generalisierungsfähigkeiten verfügen Zusätzlich zum I2U-Modell haben wir auch das U2U-Zinserweiterungsmodul eingeführt. Mit anderen Worten: Wenn einige Benutzer im Kaltstartvideo gut abschneiden, werden wir das Video schnell verbreiten 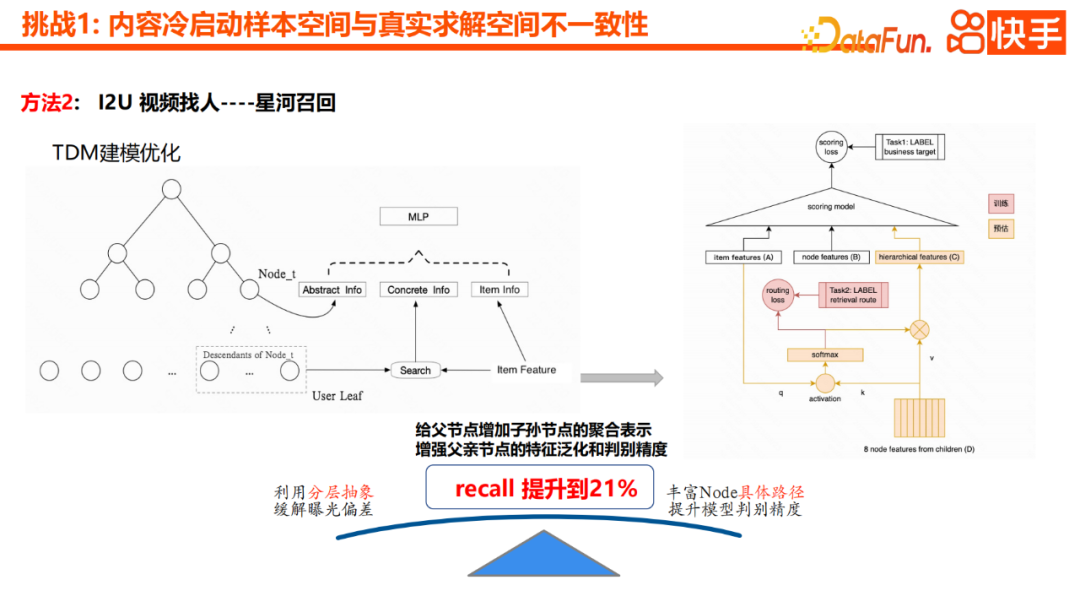
Die Einzelheiten ähneln einigen aktuellen Methoden in der Branche, aber das U2U-Interessenerweiterungsmodul bietet hier drei Hauptvorteile: . Erstens ist die TDM-Baumstruktur relativ solide und das Hinzufügen dieses U2U-Moduls kann näher an den Echtzeitpräferenzen des Benutzers liegen. Zweitens können wir durch die Verbreitung von Interessen in Echtzeit die Beschränkungen des Modells durchbrechen und Inhalte durch die Zusammenarbeit der Benutzer schnell bewerben, was zu mehr Vielfalt führt. Letztendlich kann dies auch die Gesamtabdeckung des Galaxy-Rückrufs verbessern. Dies sind einige unserer Optimierungspunkte im Übungsprozess. Durch diese Lösungen können wir den Beispielraum und den realen Lösungsraum beim Kaltstart von Inhalten effektiv lösen Inkonsistenzproblem, wodurch die Reichweite und der Abdeckungseffekt des Kaltstarts erheblich verbessert werden Frage, das ist die größte Herausforderung. Der Kern dieses Problems ist die Spärlichkeit des Interaktionsverhaltens. Wir erweitern das Problem in drei Richtungen.

Erstens ist das Erlernen der Artikel-ID aufgrund der geringeren Belichtung von Kaltstartproben unzureichend, was sich wiederum auf den Empfehlungseffekt und die Empfehlungseffizienz auswirkt. Zweitens besteht aufgrund von Ungenauigkeiten bei der frühen Verteilung eine hohe Unsicherheit und ein geringes Vertrauen in die gesammelten Etiketten. Drittens führt das aktuelle Trainingsparadigma Beliebtheitsinformationen ohne Korrektur in die Einbettung von Elementen ein, was dazu führt, dass Kaltstartvideos unterschätzt werden und daher nicht vollständig verteilt werden können
Wir gehen hauptsächlich aus vier Richtungen vor, um dieses Problem zu lösen. Das erste ist die Verallgemeinerung, das zweite ist die Übertragung, das dritte ist die Erkundung und das vierte ist die Korrektur. Bei der Generalisierung geht es eher darum, die Modellierung und Aktualisierung aus der Perspektive generalisierter Funktionen abzuschließen. Der Hauptzweck der Migration besteht darin, unpopuläre und beliebte Videos als zwei Domänen zu betrachten und Informationen effektiv aus der beliebten Videodomäne oder der vollständigen Informationsdomäne zu übertragen, um das Erlernen unpopulärer Videos zu unterstützen. Die Erkundung führt hauptsächlich die Idee der Erforschung und Nutzung ein. Das heißt, wenn die frühe Bezeichnung ungenau ist, hoffen wir, die Idee der Erforschung in den Modellierungsprozess einzuführen und dadurch die negativen Auswirkungen des Unglaubens an die Bezeichnung während der Kälte zu mildern Startphase. Beliebtheitskorrektur ist derzeit ein heißer Trend. Wir schränken die Verwendung von Beliebtheitsinformationen hauptsächlich durch Gating und regelmäßige Verluste ein.
Im Folgenden finden Sie eine ausführliche Einführung in unsere Arbeit.
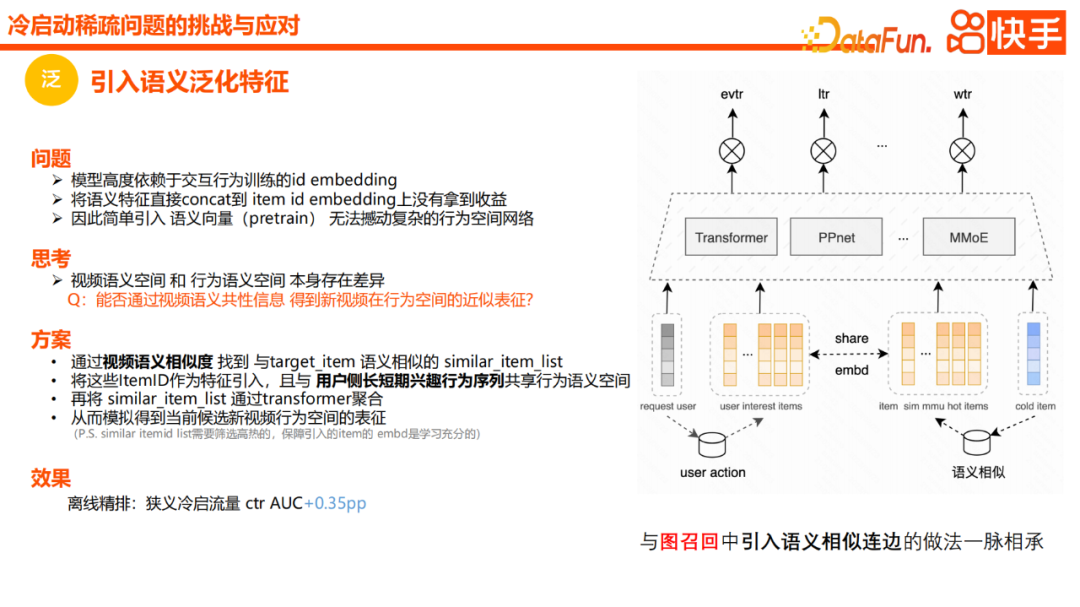
Zuallererst ist die Verallgemeinerung eine sehr häufige Methode zur Lösung des Kaltstartproblems. In der Praxis finden wir jedoch, dass es auch sehr nützlich ist, einige semantische Einbettungen im Vergleich zu Labels und Kategorien einzuführen. Allerdings sind die Vorteile des direkten Hinzufügens semantischer Merkmale zum Gesamtmodell begrenzt. Da es Unterschiede zwischen dem Videosemantikraum und dem Verhaltensraum gibt, können wir die Position des neuen Videos im Verhaltensraum durch die gemeinsamen Informationen der Videosemantik näherungsweise darstellen, um die Verallgemeinerung zu unterstützen. Wir haben bereits einige Methoden erwähnt, beispielsweise CB2CF, das lernt, Generalisierungsinformationen dem realen Verhaltensraum zuzuordnen. Anstatt diesem Ansatz zu folgen, finden wir jedoch eine Liste von Elementen, die dem Zielelement ähnlich sind, basierend auf den semantischen Vektoren des Videos. Erstens teilt es den Verhaltensraum mit dem langfristigen und kurzfristigen Interessenverhalten des Benutzers und wir aggregieren die Liste ähnlicher Elemente, um die Darstellung von Kandidatenvideos im Verhaltensraum zu simulieren. Tatsächlich ähnelt diese Methode der zuvor erwähnten Methode zum Einführen von Kanten, die Kandidaten im Graph-Recall ähneln, und der Effekt ist sehr offensichtlich: Die Offline-AUC wird um 0,35 PP verbessert Das heißt, eine ungenaue frühe Verteilung neuer Videos führt zu einem niedrigen Mittelwert der CTR im hinteren Bereich. Dieser niedrige Mittelwert führt auch dazu, dass das Modell davon ausgeht, dass das Video selbst möglicherweise von schlechter Qualität ist, was letztendlich die Erkundbarkeit von Kaltstartinhalten einschränkt. So können wir die Unsicherheit von PCTR modellieren und die absolute Nutzung und das Vertrauen von Etiketten in der Kaltstartphase verlangsamen. Wir versuchen, die CTR-Schätzung einer Anfrage in eine Beta-verteilte Schätzung umzuwandeln, wobei wir sowohl die Erwartung als auch die Online-Varianz verwenden. Insbesondere werden wir in der Praxis ein α und β der Beta-Verteilung schätzen. Insbesondere ist das Verlustdesign der erwartete Wert des mittleren quadratischen Fehlers des geschätzten Werts und der tatsächlichen Bezeichnung. Nachdem wir den erwarteten Wert erweitert haben, werden wir feststellen, dass wir den Erwartungswert des Quadrats des geschätzten Werts und den Erwartungswert des geschätzten Werts ermitteln müssen. Wir können diese beiden Werte effektiv über die Schätzungen α und β berechnen und den Verlust erzeugen. Dann können wir die Beta-Verteilung trainieren und schließlich eine Warteschlange zum geschätzten Wert der Beta-Verteilung hinzufügen, um Erkundung und Nutzung auszugleichen . Wenn wir den Beta-Verlust im niedrigen vv-Stadium verwenden, gibt es tatsächlich eine gewisse Verbesserung der AUC, die jedoch nicht besonders offensichtlich ist. Wenn wir jedoch die Online-Betaverteilung nutzen, erhöht sich die effektive Penetrationsrate von 0vv-Inhalten um 22 %, während die Gesamtaktionsrate gleich bleibt.

Die nächste Einführung ist das Dual-Domain-Transfer-Lernframework. Der Grundgedanke ist, dass Kaltstart-Inhalte häufig eine stark verzerrte Long-Tail-Verbreitung darstellen und auch eine anfällige Gruppe im Beliebtheitsbias darstellen. Wenn wir nur Kaltstartproben verwenden, kann die Beliebtheitsverzerrung bis zu einem gewissen Grad gemildert werden, es geht jedoch ein großer Teil des Benutzerinteresses verloren, was zu einer Verringerung der Gesamtgenauigkeit führt.
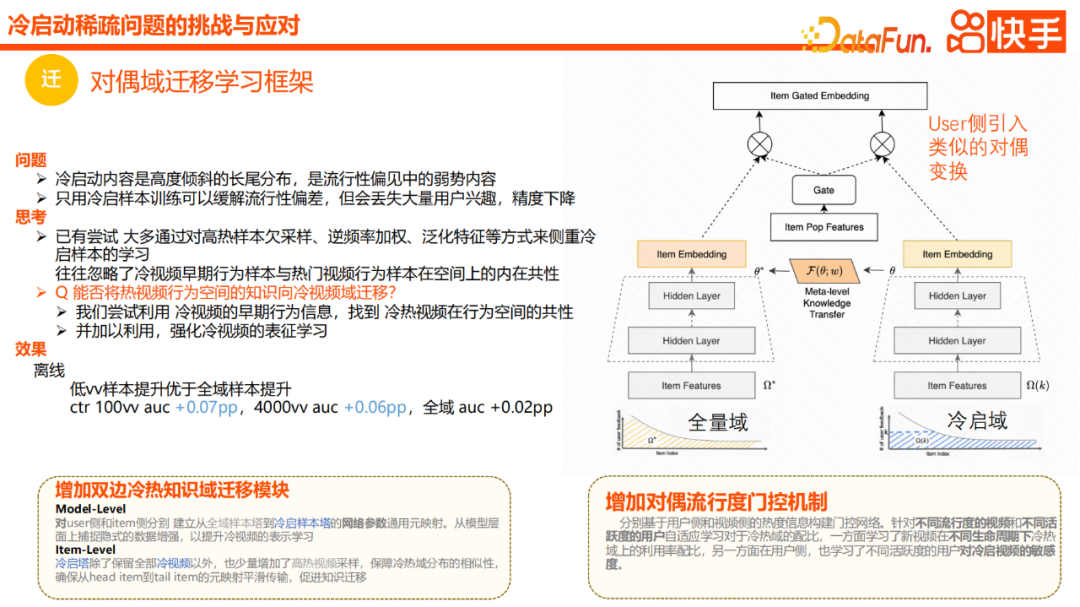 Die meisten unserer aktuellen Versuche konzentrieren sich auf das Lernen von Kaltstartproben durch eine gewisse Unterabtastung von Proben mit hoher Hitze oder durch inverse Frequenzgewichtung oder Verallgemeinerungsfunktionen, ignorieren jedoch häufig die frühen Verhaltensproben von Kaltstarts. Es besteht eine inhärente Gemeinsamkeit darin der Verhaltensraum mit beliebten Videos.
Die meisten unserer aktuellen Versuche konzentrieren sich auf das Lernen von Kaltstartproben durch eine gewisse Unterabtastung von Proben mit hoher Hitze oder durch inverse Frequenzgewichtung oder Verallgemeinerungsfunktionen, ignorieren jedoch häufig die frühen Verhaltensproben von Kaltstarts. Es besteht eine inhärente Gemeinsamkeit darin der Verhaltensraum mit beliebten Videos.
Während des Designprozesses werden wir also die vollständige Probe und die Kaltstartprobe in zwei Domänen unterteilen, nämlich die Vollvolumendomäne und die Kaltstartdomäne im Bild oben. Die Vollvolumendomäne ist für alle Proben wirksam Die Kaltstartdomäne ist nur für den Kaltstart vorgesehen. Es werden nur die bedingten Stichproben wirksam, und dann werden die Migrationsmodule der bilateralen Heiß- und Kalt-Wissensdomänen hinzugefügt. Insbesondere werden Benutzer und Elemente separat modelliert und die Netzwerkzuordnung vom globalen Probenturm zum Kaltstart-Probenturm durchgeführt, wodurch eine implizite Datenverbesserung auf Modellebene erfasst und die Darstellung von Kaltstartvideos verbessert wird. Auf der Artikelseite behalten wir alle Kaltstartbeispiele bei. Darüber hinaus werden wir auch einige heiße Videos basierend auf der Belichtung abtasten, um die Ähnlichkeit der heißen und kalten Domänenverteilung sicherzustellen und letztendlich den reibungslosen Wissenstransfer des gesamten Mappings sicherzustellen.
Darüber hinaus haben wir einen einzigartigen Gating-Mechanismus mit doppelter Beliebtheit hinzugefügt, einige Beliebtheitsfunktionen eingeführt und ihn verwendet, um das Fusionsverhältnis von heißen und kalten Videodomänen zu unterstützen. Einerseits kann das Verhältnis der Kaltstartausdrucksnutzung neuer Videos in verschiedenen Lebenszyklen effektiv erlernt und verteilt werden. Andererseits erfährt die Nutzerseite auch die Sensibilität verschiedener aktiver Nutzer gegenüber Kaltstartvideos. In der Praxis wurde der Offline-Effekt sowohl im niedrigen vv-Stadium als auch bei der AUC von 4000 vv bis zu einem gewissen Grad verbessert.

Abschließend werde ich eine Arbeit zur Korrektur vorstellen, nämlich die Hitzekorrektur. Empfehlungssysteme unterliegen häufig einem Beliebtheitsfehler und sind im Allgemeinen ein Karneval hochexplosiver Produkte. Das Ziel der Paradigmenanpassung bestehender Modelle ist die globale CTR. Die Empfehlung beliebter Artikel kann zu einem geringeren Gesamtverlust führen, aber es werden auch einige beliebte Informationen in die Artikeleinbettung einfließen, was dazu führt, dass sehr beliebte Videos überschätzt werden.
Einige bestehende Methoden verfolgen zu sehr eine unvoreingenommene Schätzung, führen jedoch tatsächlich zu einigen Verbrauchsverlusten. Können wir also einige Artikeleinbettungen von Beliebtheitsinformationen und tatsächlichen Interesseninformationen entkoppeln und Beliebtheitsinformationen und Interesseninformationen effektiv für die Online-Fusion nutzen? In der konkreten Praxis beziehen wir uns auf einige Praktiken unserer Kollegen
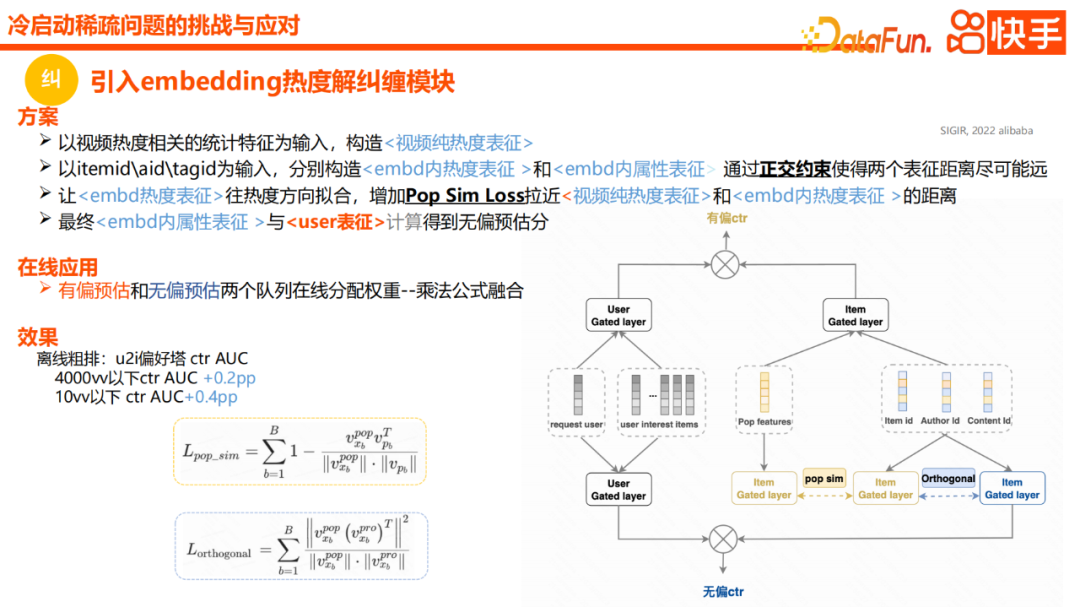
Der Schwerpunkt liegt hauptsächlich auf zwei Modulen. Das eine besteht darin, orthogonale Einschränkungen für die Beliebtheit und das Interesse des Eingabeinhalts festzulegen, beispielsweise die Eingabe der Artikel-ID , Autoren-ID usw. Die Funktionen generieren zwei Darstellungen, die Beliebtheitsdarstellung und die andere die Darstellung des tatsächlichen Interesses. Während des Lösungsprozesses wird eine regelmäßige Einschränkung vorgenommen. Die zweite Möglichkeit besteht darin, dass wir auch Einbettungen der reinen Wärmeinformationen einiger Elemente als reine Wärmedarstellung des Videos generieren. Die reine Wärmedarstellung erstellt eine Ähnlichkeitsbeschränkung basierend auf der tatsächlichen Wärmedarstellung des Videos, sodass wir dies können Holen Sie sich die gerade erwähnte Wärmedarstellung und die Interessendarstellung. Eine davon drückt Beliebtheitsinformationen aus, und die andere drückt Interesseninformationen aus. Basierend auf diesen beiden Darstellungen wird schließlich online eine Warteschlange mit voreingenommener Schätzung und unvoreingenommener Schätzung für die Fusion von Multiplikationsformeln hinzugefügt.
3. Zukünftiger Ausblick

Lassen Sie mich abschließend meinen Ausblick auf die zukünftige Arbeit mitteilen.
Zunächst müssen wir das Crowd-Diffusion-Modell genauer modellieren und anwenden, insbesondere in Echtzeit, einschließlich der aktuellen Verbreitung ähnlicher Crowds. Wir haben bereits einige ähnliche Massendiffusionsschemata in der Kaltstartphase implementiert, beispielsweise eine Diffusionsanwendung von U2U, und wir hoffen, deren Verfeinerung weiter zu verbessern. Das zweite ist das Korrekturschema. Das aktuelle Kausalmodell korrigiert Abweichungen im Kaltstart Auch in China wird viel geforscht, und wir werden weiterhin Forschung und Forschung in dieser Richtung betreiben, insbesondere zur Korrektur von Hitze. Die dritte Möglichkeit besteht in der Probenauswahl Der Start von Proben mit hoher Hitze ist immer noch möglich. Wenn sie einen größeren Wert haben, können wir einige wertvollere Proben aus dem Raum für heiße Proben auswählen und ihnen unterschiedliche Gewichte geben, um die Empfehlungseffizienz des Kaltstartmodells zu verbessern.
Der dritte Punkt ist die Charakterisierung des langfristigen Wachstumswerts des Videos. Jedes Video muss den Prozess des Kaltstarts, des Wachstums, der Stabilität und des Rückgangs durchlaufen , also Wachstum, bei der Modellierung von Videos? Raum, insbesondere im Hinblick auf die Wertschöpfung, wie man den Wertunterschied verschiedener Einzelverteilungen für zukünftiges Wachstum modellieren kann, ist auch eine sehr interessante Arbeit.
Die letzte Lösung ist die Lösung durch Datenverbesserung. Unabhängig davon, ob es sich um eine Beispiel- oder vergleichende Lernlösung handelt, hoffen wir, in diesem Bereich einige Arbeiten einzuführen, um die Effizienz der Kaltstartempfehlung zu verbessern.
4. Frage- und Antwortsitzung
Frage 1: Alle Online-Anfragen sind benutzergranular. Wie wird der Benutzer von I2U online in die Vektor-Engine aufgenommen?
A1: Das I2U-Modell sucht während des Offline-Prozesses kontinuierlich nach den ähnlichsten Benutzern in der Indexbibliothek und wandelt sie dann basierend auf den ähnlichsten Benutzern und gefundenen Elementen in Benutzer-Element-Paare um und erhält schließlich den Benutzer -item-Paar Die Aggregationsergebnisse der Liste werden zur Online-Verwendung in Redis gespeichert
F2: Die andere Seite des Kaltstarts besteht darin, zu verhindern, dass der Header-Inhalt überhitzt und der Probenanteil zu hoch wird, was zu immer mehr führt Gibt es eine Methode?
A2: Im Teilen wurden mehrere Methoden erwähnt. Grundsätzlich lösen wir das Problem immer noch aus der Perspektive der Verallgemeinerung, Erkundung und Korrektur. Beispielsweise, wie man die Element-ID so initialisiert, dass sie einen besseren Anfangspunkt hat, und gleichzeitig einige verallgemeinerte Merkmale einführt, um die verallgemeinerten Merkmale dem verhaltenssemantischen Raum zuzuordnen. Verwenden Sie dann die Beta-Verteilung, um die Erkundbarkeit zu verbessern, und führen Sie reine Inhaltstürme ein, um Funktionen mit starkem Gedächtnis wie PID zu entfernen, wodurch eine reine Generalisierungsschätzung ohne Wärmeverzerrung und Korrekturarbeiten eingeführt wird, in der Hoffnung, das Lernen zu verbessern. Dabei werden die Beliebtheitsfaktoren gelernt und Separat eingeschränkt werden reine Interessenstandards und Beliebtheitsstandards bereitgestellt, und die Nutzungsintensität der Beliebtheitsstandards wird online angemessen verteilt. Zusätzlich zu diesen Methoden versuchen wir natürlich auch, die Spärlichkeit von Kaltstartinhalten durch Datenverbesserung zu verringern und beliebte Inhalte zu verwenden, um das Erlernen von Kaltstartinhalten aus der Perspektive des Transferlernens zu unterstützen.
F3: Wie wird die optimale Rate beliebter Pools berechnet?
A3: Die Optimierungsrate ist tatsächlich eine Aufgabe mit einem sehr hohen Maß an manueller Beteiligung. Es ist für uns unmöglich, das Modell vollständig zur Bewertung der Optimierungsrate eines Videos zu verwenden. Wenn wir ein Modell verwenden können, um einen Inhalt zu bewerten, beispielsweise ein Video mit 50.000 Aufnahmen, ist die manuelle Beteiligung an der Gesamtbewertung für „Ausgezeichnet“ beteiligt, und es wird auf jeden Fall den Rezensenten auferlegt, zu überprüfen, welche Inhalte „ausgezeichnet“ sind.
Das obige ist der detaillierte Inhalt vonPraktische Anwendung des Kaltstart-Empfehlungsmodells für Kuaishou-Inhalte. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Es werden nur 1 % der Einbettungsparameter benötigt, die Hardwarekosten werden um das Zehnfache reduziert und die Open-Source-Lösung mit einer einzelnen GPU trainiert ein großes empfohlenes Modell
- Poisson-Matrix-Zerlegung: Ein Matrix-Zerlegungsalgorithmus, der das Kaltstartproblem von Empfehlungssystemen ohne Daten löst
- Verwendung von PHP zur Implementierung von Click-Through-Rate-Schätzungen und Werbeempfehlungsmodellen
- Wie man mit PHP eine Analyse des Benutzer-Einkaufsverhaltens und ein Empfehlungsmodell erstellt