

 Technologie-PeripheriegeräteKINeuer Titel: ADAPT: Eine vorläufige Untersuchung der Erklärbarkeit von End-to-End-Autonomem Fahren
Technologie-PeripheriegeräteKINeuer Titel: ADAPT: Eine vorläufige Untersuchung der Erklärbarkeit von End-to-End-Autonomem FahrenNeuer Titel: ADAPT: Eine vorläufige Untersuchung der Erklärbarkeit von End-to-End-Autonomem Fahren

Dieser Artikel wird mit Genehmigung des öffentlichen Kontos von Autonomous Driving Heart nachgedruckt. Bitte wenden Sie sich für einen Nachdruck an die Quelle.
Die persönlichen Gedanken des Autors
End-to-End ist dieses Jahr eine sehr beliebte Richtung, die auch an UniAD vergeben wurde, aber es gibt auch viele Probleme im End-to-End-Bereich, z Da die Interpretierbarkeit gering ist, die Ausbildung schwierig zu konvergieren ist usw., haben einige Wissenschaftler auf diesem Gebiet ihre Aufmerksamkeit nach und nach auf die End-to-End-Interpretierbarkeit gerichtet. Heute werde ich Ihnen die neueste Arbeit zur End-to-End-Interpretierbarkeit vorstellen, ADAPT. Diese Methode basiert auf der Transformer-Architektur und nutzt Multitasking. Die gemeinsame Trainingsmethode gibt Fahrzeugaktionsbeschreibungen und Begründungen für jede Entscheidung durchgängig aus. Einige der Gedanken des Autors zu ADAPT sind wie folgt:
- Hier ist die Vorhersage mit der 2D-Funktion des Videos. Es ist möglich, dass der Effekt nach der Konvertierung der 2D-Funktion in eine Bev-Funktion besser ist In Kombination mit LLM ist dies möglicherweise besser. Beispielsweise wird der Textgenerierungsteil durch LLM ersetzt.
- Die aktuelle Arbeit verwendet historische Videos als Eingabe, und die vorhergesagten Aktionen und ihre Beschreibungen sind ebenfalls historisch. Wenn dies der Fall ist, ist dies möglicherweise aussagekräftiger geändert, um zukünftige Aktionen und die Gründe für die Aktionen vorherzusagen.
- Der durch die Tokenisierung des Bildes erhaltene
- Token ist etwas zu viel und es können viele nutzlose Informationen vorhanden sein.
Durchgängiges autonomes Fahren hat großes Potenzial in der Transportbranche, und die Forschung in diesem Bereich ist derzeit heiß begehrt. UniAD, das beste Papier von CVPR2023, befasst sich beispielsweise mit durchgängigem automatischem Fahren. Allerdings wird die mangelnde Transparenz und Erklärbarkeit des automatisierten Entscheidungsprozesses seine Entwicklung behindern. Denn Sicherheit steht bei realen Fahrzeugen im Straßenverkehr an erster Stelle. Es gab einige frühe Versuche, Aufmerksamkeitskarten oder Kostenvolumina zu verwenden, um die Interpretierbarkeit von Modellen zu verbessern, aber diese Methoden sind schwer zu verstehen. Der Ausgangspunkt dieser Arbeit besteht also darin, eine leicht verständliche Möglichkeit zu finden, die Entscheidungsfindung zu erklären. Das Bild unten ist ein Vergleich mehrerer Methoden. Offensichtlich ist es in Worten einfacher zu verstehen.
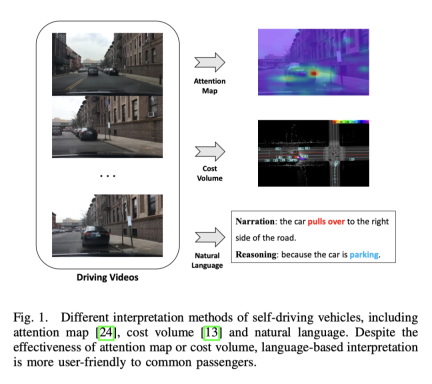
Kann Fahrzeugaktionsbeschreibungen und Begründungen für jede Entscheidung ausgeben.
- Diese Methode basiert auf der Transformatornetzwerkstruktur und führt gemeinsames Training durch Multitask-Methoden durch.
- In BDD-X (Berkeley). DeepDrive eXplanation) erzielte einen SOTA-Effekt auf den Datensatz.
- Um die Wirksamkeit des Systems in realen Szenarien zu überprüfen, wurde ein einsetzbares System eingerichtet, das das Originalvideo eingeben und die Beschreibung und Begründung der Aktion in realen Situationen ausgeben kann Zeit. ;
 Der Effekt ist immer noch sehr gut, besonders in der dritten dunklen Nachtszene fallen die Ampeln auf.
Der Effekt ist immer noch sehr gut, besonders in der dritten dunklen Nachtszene fallen die Ampeln auf.
Videountertitelung
Das Hauptziel der Videobeschreibung besteht darin, die Objekte und ihre Beziehungen in einem bestimmten Video in natürlicher Sprache zu beschreiben. Frühe Forschungsarbeiten generierten Sätze mit spezifischen syntaktischen Strukturen, indem identifizierte Elemente in feste Vorlagen eingefügt wurden, die unflexibel waren und denen es an Fülle mangelte.
Um natürliche Sätze mit flexiblen syntaktischen Strukturen zu generieren, verwenden einige Methoden Sequenzlerntechniken. Konkret nutzen diese Methoden Video-Encoder zum Extrahieren von Funktionen und Sprachdecoder zum Erlernen der visuellen Textausrichtung. Um Beschreibungen umfangreicher zu gestalten, verwenden diese Methoden auch Darstellungen auf Objektebene, um detaillierte objektbewusste Interaktionsfunktionen in Videos zu erhalten.
Obwohl bestehende Architekturen bestimmte Ergebnisse in der allgemeinen Richtung der Videountertitelung erzielt haben, können sie aus einfachen Gründen nicht direkt auf die Darstellung von Aktionen angewendet werden Durch die Übertragung von Videobeschreibungen auf Darstellungen autonomer Fahrhandlungen gehen einige wichtige Informationen verloren, wie z. B. Fahrzeuggeschwindigkeit usw., die für autonome Fahraufgaben von entscheidender Bedeutung sind. Wie diese multimodalen Informationen effektiv zur Bildung von Sätzen genutzt werden können, wird noch untersucht. PaLM-E leistet gute Arbeit in multimodalen Sätzen.
Durchgängiges autonomes FahrenLernbasiertes autonomes Fahren ist ein aktives Forschungsfeld. Der jüngste CVPR2023-Best-Paper UniAD, einschließlich des nachfolgenden FusionAD, und Wayves Arbeit basierend auf dem Weltmodell MILE arbeiten alle in diese Richtung. Das Ausgabeformat umfasst Flugbahnpunkte wie UniAD und direkte Fahrzeugaktionen wie MILE.
Darüber hinaus modellieren einige Methoden das zukünftige Verhalten von Verkehrsteilnehmern wie Fahrzeugen, Radfahrern oder Fußgängern, um die Wegpunkte des Fahrzeugs vorherzusagen, während andere Methoden die Steuersignale des Fahrzeugs direkt auf der Grundlage von Sensoreingaben vorhersagen, ähnlich der Teilaufgabe „Vorhersage von Steuersignalen“ in diese Arbeit
Interpretierbarkeit des autonomen Fahrens
Im Bereich des autonomen Fahrens basieren die meisten Interpretationsmethoden auf Vision, einige basieren auf LiDAR-Arbeit. Einige Methoden nutzen Aufmerksamkeitskarten, um unbedeutende Bildbereiche herauszufiltern und so das Verhalten autonomer Fahrzeuge nachvollziehbar und erklärbar erscheinen zu lassen. Die Aufmerksamkeitskarte kann jedoch einige weniger wichtige Regionen enthalten. Es gibt auch Methoden, die Lidar- und hochpräzise Karten als Eingabe verwenden, die Begrenzungsrahmen anderer Verkehrsteilnehmer vorhersagen und Ontologie verwenden, um den Entscheidungsprozess zu erklären. Darüber hinaus gibt es eine Möglichkeit, Online-Karten durch Segmentierung zu erstellen, um die Abhängigkeit von HD-Karten zu verringern. Obwohl visionäre oder Lidar-basierte Methoden gute Ergebnisse liefern können, lässt das Fehlen einer verbalen Erklärung das gesamte System komplex und schwer verständlich erscheinen. Eine Studie untersucht erstmals die Möglichkeit der Textinterpretation für autonome Fahrzeuge, indem Videofunktionen offline extrahiert werden, um Steuersignale vorherzusagen und die Aufgabe der Videobeschreibung auszuführen.
Multitasking-Lernen beim autonomen Fahren. End-Framework Multitasking-Lernen wird übernommen, um das Modell gemeinsam mit den beiden Aufgaben Textgenerierung und Vorhersage von Steuersignalen zu trainieren. Multitasking-Lernen wird häufig beim autonomen Fahren eingesetzt. Aufgrund einer besseren Datennutzung und gemeinsamer Funktionen verbessert das gemeinsame Training verschiedener Aufgaben die Leistung jeder Aufgabe. Daher wird in dieser Arbeit das gemeinsame Training der beiden Aufgaben der Steuersignalvorhersage und der Textgenerierung verwendet.
ADAPT-Methode
Das Folgende ist das Netzwerkstrukturdiagramm:
Die gesamte Struktur ist in zwei Aufgaben unterteilt: 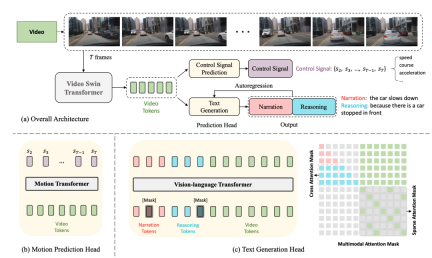
Driving Caption Generation (DCG): Videos eingeben, zwei Sätze ausgeben, den ersten Satz Beschreibung: Die Aktion des Autos, der zweite Satz beschreibt die Gründe für diese Aktion, z. B. „Das Auto beschleunigt, weil die Ampel grün wird“
- Control Signal Prediction (CSP): Geben Sie die gleichen Videos ein und geben Sie a aus Reihe von Steuersignalen, zum Beispiel Geschwindigkeit, Richtung, Beschleunigung
- Unter diesen teilen sich die beiden Aufgaben von DCG und CSP den Video-Encoder, verwenden jedoch unterschiedliche Vorhersageköpfe, um unterschiedliche Endausgaben zu erzeugen.
Video-Encoder. Der Video-Swin-Transformer wird hier verwendet, um die eingegebenen Videobilder in Video-Feature-Tokens umzuwandeln.
Eingabe 桢Bild, die Form ist
, die Größe des Features ist
, wobei die Dimension des Kanals ist darüber Feature Nach der Tokenisierung werden Video-Tokens mit Abmessungen
erhalten, und dann wird ein MLP verwendet, um die Abmessungen anzupassen, um sie an die Einbettung von Text-Tokens anzupassen, und dann werden die Text-Tokens und Video-Tokens der Vision zugeführt -Sprachtransformator-Encoder zusammen, um Aktionsbeschreibungen und Begründungen zu generieren.Steuersignal-Vorhersagekopf
und der Eingang
桢Video entsprechen dem Steuersignal. Jedes Steuersignal ist hier nicht unbedingt eindimensional, sondern kann mehrdimensional sein -dimensional, wie Geschwindigkeit, Beschleunigung, Richtung usw. gleichzeitig. Der Ansatz hier besteht darin, die Videofunktionen zu tokenisieren und über den Bewegungstransformator eine Reihe von Ausgangssignalen zu generieren. Es ist zu beachten, dass der erste Frame hier nicht enthalten ist, da der erste Frame bereitgestellt wird ist zu wenig dynamische Informationen
Gemeinsames Training
In diesem Rahmen wird aufgrund des gemeinsam genutzten Video-Encoders tatsächlich davon ausgegangen, dass die beiden Aufgaben von CSP und DCG auf der Ebene der Videodarstellung aufeinander abgestimmt sind. Der Ausgangspunkt ist, dass Aktionsbeschreibungen und Steuersignale unterschiedliche Ausdrücke feinkörniger Fahrzeugaktionen sind und sich Erklärungen zur Aktionsbegründung hauptsächlich auf die Fahrumgebung konzentrieren, die die Fahrzeugaktionen beeinflusst. Training mit gemeinsamem Training
Es ist zu beachten, dass es sich zwar um einen gemeinsamen Trainingsplatz handelt, dieser jedoch während der Inferenz leicht verständlich ist. Die Videos werden direkt gemäß dem Flussdiagramm eingegeben Ausgabesteuerung Das Signal reicht für die DCG-Aufgabe aus, die Beschreibung und Begründung wird Wort für Wort basierend auf der autoregressiven Methode generiert, beginnend bei [CLS] und endend bei [SEP] die Längenschwelle.Experimentelles Design und Vergleich
Datensatz
Der verwendete Datensatz ist BDD-X. Dieser Datensatz enthält 7000 gepaarte Videos und Steuersignale. Jedes Video dauert etwa 40 Sekunden, die Bildgröße beträgt und die Frequenz beträgt FPS. Jedes Video weist 1 bis 5 Fahrzeugverhalten auf, z. B. Beschleunigen, Rechtsabbiegen und Zusammenfahren. Alle diese Aktionen wurden mit Text kommentiert, einschließlich Handlungserzählungen (z. B. „Das Auto hielt an“) und Begründungen (z. B. „Weil die Ampel rot war“). Insgesamt gibt es etwa 29.000 Verhaltensanmerkungspaare.
Spezifische Implementierungsdetails
- Der Video-Swin-Transformator ist auf Kinetics-600 vorab trainiert.
- Vision-Sprachtransformator und Bewegungstransformator werden zufällig initialisiert. bis zum Ende Die
- -Eingabevideobildgröße wird in der Größe geändert und zugeschnitten, und die endgültige Eingabe in das Netzwerk ist 224x224
- Zur Beschreibung und Begründung werden WordPiece-Einbettungen [75] anstelle ganzer Wörter verwendet (z. B. „stoppt“) Auf „Stopp“ und „#s“ zugeschnitten, beträgt die maximale Länge jedes Satzes 15 Wenn ein Wort zum [MASK]-Token wird, besteht eine Wahrscheinlichkeit von 10 %, dass ein Wort zufällig ausgewählt wird, und die verbleibende Wahrscheinlichkeit von 10 % bleibt unverändert.
- Der AdamW-Optimierer wird verwendet und in den ersten 10 % der Trainingsschritte gibt es einen Aufwärmmechanismus
- Das Training mit 4 V100-GPUs dauert etwa 13 Stunden
- Die Auswirkungen des gemeinsamen Trainings
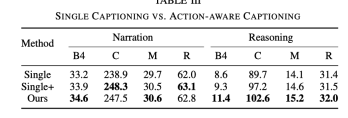
Drei Experimente werden hier verglichen, um die Wirksamkeit des gemeinsamen Trainings zu veranschaulichen. Single
bezieht sich auf das Entfernen der CSP-Aufgabe und das Beibehalten nur der DCG-Aufgabe, was dem Training nur des Untertitelmodells entspricht Die Aufgabe ist immer noch nicht vorhanden, aber wenn Sie das DCG-Modul eingeben, müssen Sie zusätzlich zum Video-Tag auch das Steuersignal-Tag eingeben Der Argumentationseffekt ist deutlich besser. Obwohl der Effekt bei einem Steuersignaleingang verbessert wird, ist er immer noch nicht so gut wie der Effekt beim Hinzufügen einer CSP-Aufgabe. Nach dem Hinzufügen der CSP-Aufgabe ist die Fähigkeit, das Video auszudrücken und zu verstehen, stärker
Darüber hinaus zeigt die folgende Tabelle auch, dass sich auch die Wirkung des gemeinsamen Trainings auf CSP verbessert.
Hierkann so verstanden werden Genauigkeit, insbesondere wird das vorhergesagte Steuersignal abgeschnitten und die Formel lautet wie folgt
Der Einfluss verschiedener Arten von Steuersignalen
Im Experiment werden Geschwindigkeit und Kurs als grundlegende Signale verwendet. Experimente ergaben jedoch, dass die Wirkung bei Verwendung nur eines der Signale nicht so gut ist wie bei der gleichzeitigen Verwendung beider Signale. Die spezifischen Daten sind in der folgenden Tabelle aufgeführt:
Dies zeigt, dass die beiden Signale Geschwindigkeit und Richtung können dem Netzwerk helfen, die Handlungsbeschreibung und Argumentation besser zu lernen
Interaktion zwischen Handlungsbeschreibung und Argumentation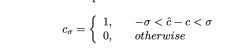
Im Vergleich zu allgemeinen Beschreibungsaufgaben besteht die Generierung von Fahrbeschreibungsaufgaben aus zwei Sätzen, nämlich Handlungsbeschreibung und Argumentation. Dies kann der folgenden Tabelle entnommen werden:
Die Zeilen 1 und 3 zeigen, dass die Wirkung der Queraufmerksamkeit besser ist, was leicht zu verstehen ist und für das Modelltraining von Vorteil ist Austauschschlussfolgerung Die Reihenfolge von Beschreibung und Beschreibung ist ebenfalls nicht in Ordnung, was zeigt, dass die Argumentation von der Beschreibung abhängtDer Einfluss der Abtastraten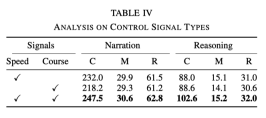
Dieses Ergebnis lässt sich erraten. Je mehr Frames verwendet werden, desto besser wird das Ergebnis, aber die entsprechende Geschwindigkeit wird auch langsamer, wie in der folgenden Tabelle gezeigt
- Erforderlich Der neu geschriebene Inhalt ist: Originallink: https://mp.weixin.qq.com/s/MSTyr4ksh0TOqTdQ2WnSeQ
Das obige ist der detaillierte Inhalt vonNeuer Titel: ADAPT: Eine vorläufige Untersuchung der Erklärbarkeit von End-to-End-Autonomem Fahren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Gemma Scope: Das Mikroskop von Google, um in den Denkprozess von AI zu blickenApr 17, 2025 am 11:55 AM
Gemma Scope: Das Mikroskop von Google, um in den Denkprozess von AI zu blickenApr 17, 2025 am 11:55 AMErforschen der inneren Funktionsweise von Sprachmodellen mit Gemma -Umfang Das Verständnis der Komplexität von KI -Sprachmodellen ist eine bedeutende Herausforderung. Die Veröffentlichung von Gemma Scope durch Google, ein umfassendes Toolkit, bietet Forschern eine leistungsstarke Möglichkeit, sich einzuschütteln
 Wer ist ein Business Intelligence Analyst und wie kann man einer werden?Apr 17, 2025 am 11:44 AM
Wer ist ein Business Intelligence Analyst und wie kann man einer werden?Apr 17, 2025 am 11:44 AMErschließung des Geschäftserfolgs: Ein Leitfaden zum Analyst für Business Intelligence -Analyst Stellen Sie sich vor, Rohdaten verwandeln in umsetzbare Erkenntnisse, die das organisatorische Wachstum vorantreiben. Dies ist die Macht eines Business Intelligence -Analysts (BI) - eine entscheidende Rolle in Gu
 Wie füge ich eine Spalte in SQL hinzu? - Analytics VidhyaApr 17, 2025 am 11:43 AM
Wie füge ich eine Spalte in SQL hinzu? - Analytics VidhyaApr 17, 2025 am 11:43 AMSQL -Änderungstabellanweisung: Dynamisches Hinzufügen von Spalten zu Ihrer Datenbank Im Datenmanagement ist die Anpassungsfähigkeit von SQL von entscheidender Bedeutung. Müssen Sie Ihre Datenbankstruktur im laufenden Flug anpassen? Die Änderungstabelleerklärung ist Ihre Lösung. Diese Anleitung Details Hinzufügen von Colu
 Business Analyst vs. Data AnalystApr 17, 2025 am 11:38 AM
Business Analyst vs. Data AnalystApr 17, 2025 am 11:38 AMEinführung Stellen Sie sich ein lebhaftes Büro vor, in dem zwei Fachleute an einem kritischen Projekt zusammenarbeiten. Der Business Analyst konzentriert sich auf die Ziele des Unternehmens, die Ermittlung von Verbesserungsbereichen und die strategische Übereinstimmung mit Markttrends. Simu
 Was sind Count und Counta in Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AM
Was sind Count und Counta in Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AMExcel -Datenzählung und -analyse: Detaillierte Erläuterung von Count- und Counta -Funktionen Eine genaue Datenzählung und -analyse sind in Excel kritisch, insbesondere bei der Arbeit mit großen Datensätzen. Excel bietet eine Vielzahl von Funktionen, um dies zu erreichen. Die Funktionen von Count- und Counta sind wichtige Instrumente zum Zählen der Anzahl der Zellen unter verschiedenen Bedingungen. Obwohl beide Funktionen zum Zählen von Zellen verwendet werden, sind ihre Designziele auf verschiedene Datentypen ausgerichtet. Lassen Sie uns mit den spezifischen Details der Count- und Counta -Funktionen ausgrenzen, ihre einzigartigen Merkmale und Unterschiede hervorheben und lernen, wie Sie sie in der Datenanalyse anwenden. Überblick über die wichtigsten Punkte Graf und Cou verstehen
 Chrome ist hier mit KI: Tag zu erleben, täglich etwas Neues !!Apr 17, 2025 am 11:29 AM
Chrome ist hier mit KI: Tag zu erleben, täglich etwas Neues !!Apr 17, 2025 am 11:29 AMDie KI -Revolution von Google Chrome: Eine personalisierte und effiziente Browsing -Erfahrung Künstliche Intelligenz (KI) verändert schnell unser tägliches Leben, und Google Chrome leitet die Anklage in der Web -Browsing -Arena. Dieser Artikel untersucht die Exciti
 Die menschliche Seite von Ai: Wohlbefinden und VierfacheApr 17, 2025 am 11:28 AM
Die menschliche Seite von Ai: Wohlbefinden und VierfacheApr 17, 2025 am 11:28 AMImpacting Impact: Das vierfache Endergebnis Zu lange wurde das Gespräch von einer engen Sicht auf die Auswirkungen der KI dominiert, die sich hauptsächlich auf das Gewinn des Gewinns konzentrierte. Ein ganzheitlicherer Ansatz erkennt jedoch die Vernetzung von BU an
 5 verwendende Anwendungsfälle für Quantum Computing, über die Sie wissen solltenApr 17, 2025 am 11:24 AM
5 verwendende Anwendungsfälle für Quantum Computing, über die Sie wissen solltenApr 17, 2025 am 11:24 AMDie Dinge bewegen sich stetig zu diesem Punkt. Die Investition, die in Quantendienstleister und Startups einfließt, zeigt, dass die Industrie ihre Bedeutung versteht. Und eine wachsende Anzahl realer Anwendungsfälle entsteht, um seinen Wert zu demonstrieren


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

SublimeText3 Englische Version
Empfohlen: Win-Version, unterstützt Code-Eingabeaufforderungen!

SecLists
SecLists ist der ultimative Begleiter für Sicherheitstester. Dabei handelt es sich um eine Sammlung verschiedener Arten von Listen, die häufig bei Sicherheitsbewertungen verwendet werden, an einem Ort. SecLists trägt dazu bei, Sicherheitstests effizienter und produktiver zu gestalten, indem es bequem alle Listen bereitstellt, die ein Sicherheitstester benötigen könnte. Zu den Listentypen gehören Benutzernamen, Passwörter, URLs, Fuzzing-Payloads, Muster für vertrauliche Daten, Web-Shells und mehr. Der Tester kann dieses Repository einfach auf einen neuen Testcomputer übertragen und hat dann Zugriff auf alle Arten von Listen, die er benötigt.

SAP NetWeaver Server-Adapter für Eclipse
Integrieren Sie Eclipse mit dem SAP NetWeaver-Anwendungsserver.

VSCode Windows 64-Bit-Download
Ein kostenloser und leistungsstarker IDE-Editor von Microsoft

EditPlus chinesische Crack-Version
Geringe Größe, Syntaxhervorhebung, unterstützt keine Code-Eingabeaufforderungsfunktion

