

 Technologie-PeripheriegeräteKICross-modal Transformer: für schnelle und robuste 3D-Objekterkennung
Technologie-PeripheriegeräteKICross-modal Transformer: für schnelle und robuste 3D-Objekterkennung

Derzeit sind autonome Fahrzeuge mit einer Vielzahl von Informationserfassungssensoren wie Lidar, Millimeterwellenradar und Kamerasensoren ausgestattet. Aus heutiger Sicht weisen verschiedene Sensoren große Entwicklungsperspektiven bei den Wahrnehmungsaufgaben des autonomen Fahrens auf. Beispielsweise erfassen die von der Kamera gesammelten 2D-Bildinformationen umfangreiche semantische Merkmale, und die von Lidar gesammelten Punktwolkendaten können dem Wahrnehmungsmodell genaue Positionsinformationen und geometrische Informationen des Objekts liefern. Durch die vollständige Nutzung der von verschiedenen Sensoren erhaltenen Informationen kann das Auftreten von Unsicherheitsfaktoren im Wahrnehmungsprozess des autonomen Fahrens reduziert und gleichzeitig die Erkennungsrobustheit des Wahrnehmungsmodells verbessert werden. Heute stellen wir ein Papier zur Wahrnehmung des autonomen Fahrens von Megvii vor. und wurde in die diesjährige ICCV2023 Visual Conference aufgenommen. Das Hauptmerkmal dieses Artikels ist ein End-to-End-BEV-Wahrnehmungsalgorithmus ähnlich wie PETR (er erfordert nicht mehr die Verwendung von NMS-Nachbearbeitungsvorgängen, um redundante Boxen in den Wahrnehmungsergebnissen zu filtern). ) Gleichzeitig werden die Punktwolkeninformationen von Lidar zusätzlich verwendet, um die Wahrnehmungsleistung des Modells zu verbessern. Es handelt sich um einen sehr guten Artikel zur Wahrnehmung des autonomen Fahrens Der Link lautet wie folgt:
Papier-Link: https://arxiv.org/pdf/2301.01283.pdf- Code-Link: https://github.com/junjie18/CMT
Als nächstes werden wir uns die Netzwerkstruktur des CMT-Wahrnehmungsmodells ansehen. Es wird eine allgemeine Einführung gegeben, wie in der folgenden Abbildung dargestellt:
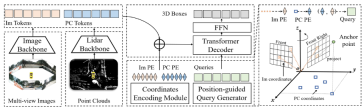 Wie aus dem gesamten Algorithmusblockdiagramm ersichtlich ist, ist das gesamte Algorithmusmodell Besteht hauptsächlich aus drei Teilen: Lidar-Backbone-Netzwerk + Kamera-Backbone-Netzwerk (Bild-Backbone + Lidar-Backbone): Verwendung Um die Eigenschaften von Punktwolken- und Surround-Bildern zu erhalten, können wir Punktwolken-Token** (PC-Token)
Wie aus dem gesamten Algorithmusblockdiagramm ersichtlich ist, ist das gesamte Algorithmusmodell Besteht hauptsächlich aus drei Teilen: Lidar-Backbone-Netzwerk + Kamera-Backbone-Netzwerk (Bild-Backbone + Lidar-Backbone): Verwendung Um die Eigenschaften von Punktwolken- und Surround-Bildern zu erhalten, können wir Punktwolken-Token** (PC-Token)
(Im Tokens)**
- Generierung der Positionscodierung: Für die von verschiedenen Sensoren erfassten Dateninformationen generieren
- Im Tokens den entsprechenden Koordinatenpositionscode Im PE ,
- PC Tokens generieren den entsprechenden Koordinatenpositionscode PC PE und Object Queries generieren auch den entsprechenden KoordinatenpositionscodeQuery EmbeddingTransformer Decoder + FFN-Netzwerk: Die Eingabe ist Object Queries + Query Embedding und die positionscodierten
- Im Tokens und PC-Tokens werden zur Berechnung der Queraufmerksamkeit verwendet, und FFN wird verwendet, um die endgültigen 3D-Boxen + Kategorievorhersage zu generieren. Das Netzwerk im Detail vorstellen. Nach der Gesamtstruktur werden die drei oben genannten Unterteile im Detail vorgestellt Lidar-Backbone-Netzwerk + Kamera-Backbone-Netzwerk (Bild-Backbone + Lidar-Backbone)
Lidar-Backbone-Netzwerk
Üblicherweise verwendete Lidar-Backbone-Netzwerk-Extraktion. Punktwolkendatenfunktionen umfassen die folgenden fünf Teile- Punktwolkeninformations-Voxelisierung
Voxel-Feature-Kodierung
- 3D Backbone (häufig verwendetes VoxelResBackBone8x-Netzwerk) extrahiert 3D-Features aus dem Ergebnis der Voxel-Feature-Codierung
- Das 3D-Backbone extrahiert die Z-Achse des Features und komprimiert es, um die Features im BEV-Raum zu erhalten.
- Verwenden Sie das 2D-Backbone, um Führen Sie eine weitere Feature-Anpassung an den Features durch, die in den BEV-Raum projiziert werden Anzahl der Kanäle (für das Modell in diesem Artikel wird eine Ausrichtung der Anzahl der Kanäle durchgeführt, diese gehört jedoch nicht zur ursprünglichen Kategorie der Extraktion von Punktwolkeninformationen)
- Kamera-Backbone-Netzwerk
- Das im Allgemeinen verwendete Kamera-Backbone-Netzwerk Das Extrahieren von 2D-Bildfunktionen umfasst die folgenden zwei Teile:
- Eingabe: 16-fache und 32-fache Downsampling-Feature-Maps-Ausgabe vom 2D-Backbone
-
Ausgabe: 16-fache und 32-fache Downsampling-Fusion von Bild-Features, um eine Feature-Map zu erhalten, die 16-mal heruntergesampelt wurde -
Tensor([bs * N, 1024, H / 16, W / 16]) -
Tensor([bs *N, 2048, H/16]) code> Tensor([bs * N, 1024, H / 16, W / 16])Tensor([bs * N,2048,H / 16,W / 16])需要重新写的内容是:张量([bs * N,256,H / 16,W / 16])Der Inhalt, der neu geschrieben werden muss, ist: tensor ([bs * N, 256, H/16, W/16])Umgeschriebener Inhalt: Verwenden Sie das ResNet-50-Netzwerk um Merkmale des Surround-Bildes zu extrahieren
Ausgabe: 16-fach und 32-fach heruntergerechnete Bildmerkmale ausgeben
Eingabetensor:
Tensor([bs * N, 3, H, W])Tensor([bs * N,3,H,W])输出张量:
Tensor([bs * N,1024,H / 16,W / 16])输出张量:``Tensor([bs * N,2048,H / 32,W / 32])`
需要进行改写的内容是:2D骨架提取图像特征
Neck(CEFPN)
位置编码的生成
根据以上介绍,位置编码的生成主要包括三个部分,分别是图像位置嵌入、点云位置嵌入和查询嵌入。下面将逐一介绍它们的生成过程
- Image Position Embedding(Im PE)
Image Position Embedding的生成过程与PETR中图像位置编码的生成逻辑是一样的(具体可以参考PETR论文原文,这里不做过多的阐述),可以总结为以下四个步骤:
- 在图像坐标系下生成3D图像视锥点云
- 3D图像视锥点云利用相机内参矩阵变换到相机坐标系下得到3D相机坐标点
- 相机坐标系下的3D点利用cam2ego坐标变换矩阵转换到BEV坐标系下
- 将转换后的BEV 3D 坐标利用MLP层进行位置编码得到最终的图像位置编码
- Point Cloud Position Embedding(PC PE)
Point Cloud Position Embedding的生成过程可以分为以下两个步骤 -
在BEV空间的网格坐标点利用
pos2embed()
Ausgabetensor:Generierung von PositionscodeGemäß der obigen Einführung umfasst die Generierung von Positionscodes hauptsächlich drei Teile, nämlich Bildpositionseinbettung und Punktwolke Standorteinbettung und Abfrageeinbettung. Im Folgenden wird der Generierungsprozess nacheinander vorgestelltBildpositionseinbettung (Im PE)Der Generierungsprozess der Bildpositionseinbettung ist derselbe wie die Generierungslogik der Bildpositionskodierung in PETR (Einzelheiten finden Sie unter das ursprüngliche PETR-Papier, das hier nicht gemacht wird Zu viel Ausarbeitung), das in den folgenden vier Schritten zusammengefasst werden kann:
Erzeugen Sie eine 3D-Bild-Frustum-Punktwolke in das Bildkoordinatensystem3D-Bildkegelstumpfpunktwolke Verwenden Sie die interne Parametermatrix der Kamera, um sie in das Kamerakoordinatensystem umzuwandeln, um den 3D-Kamerakoordinatenpunkt zu erhalten.
Der 3D-Punkt im Kamerakoordinatensystem wird mithilfe von in das BEV-Koordinatensystem konvertiert cam2ego-Koordinatentransformationsmatrix
Verwenden Sie die konvertierten BEV-3D-Koordinaten, um eine Positionscodierung mithilfe der MLP-Ebene durchzuführen. Erhalten Sie die endgültige Bildpositionscodierung- Point Cloud Position Embedding (PC PE)
Der Generierungsprozess der Punktwolke Die Positionseinbettung kann in die folgenden zwei Schritte unterteilt werden: Gitterkoordinatenpunkte im BEV-Raum. Verwenden Sie: 237); padding: 1px 3px; overflow-wrap: break-word; display: inline-block;">pos2embed() dimensionale horizontale und vertikale Koordinatenpunkte in einen hochdimensionalen Merkmalsraum
AbfrageeinbettungUm ähnliche Berechnungen zwischen Objektabfragen, Bild-Token und Lidar-Token durchzuführen. Die Einbettung von Abfragen in das Papier wird mithilfe der Logik von Lidar und Kamera erstellt, um insbesondere die Abfrageeinbettung zu generieren = Bildpositionseinbettung (wie rv_query_embeds unten) + Punktwolkenpositionseinbettung (wie bev_query_embeds unten).
-
bev_query_embeds-GenerierungslogikDa die Objektabfrage im Artikel ursprünglich im BEV-Raum initialisiert wurde, werden die Positionskodierung und die bev_embedding()-Funktion in der Point Cloud Position Embedding-Generierungslogik direkt wiederverwendet. Ja, der entsprechende Schlüsselcode lautet wie folgt:
# 点云位置编码`bev_pos_embeds`的生成bev_pos_embeds = self.bev_embedding(pos2embed(self.coords_bev.to(device), num_pos_feats=self.hidden_dim))def coords_bev(self):x_size, y_size = (grid_size[0] // downsample_scale,grid_size[1] // downsample_scale)meshgrid = [[0, y_size - 1, y_size], [0, x_size - 1, x_size]]batch_y, batch_x = torch.meshgrid(*[torch.linspace(it[0], it[1], it[2]) for it in meshgrid])batch_x = (batch_x + 0.5) / x_sizebatch_y = (batch_y + 0.5) / y_sizecoord_base = torch.cat([batch_x[None], batch_y[None]], dim=0) # 生成BEV网格.coord_base = coord_base.view(2, -1).transpose(1, 0)return coord_base# shape: (x_size *y_size, 2)def pos2embed(pos, num_pos_feats=256, temperature=10000):scale = 2 * math.pipos = pos * scaledim_t = torch.arange(num_pos_feats, dtype=torch.float32, device=pos.device)dim_t = temperature ** (2 * (dim_t // 2) / num_pos_feats)pos_x = pos[..., 0, None] / dim_tpos_y = pos[..., 1, None] / dim_tpos_x = torch.stack((pos_x[..., 0::2].sin(), pos_x[..., 1::2].cos()), dim=-1).flatten(-2)pos_y = torch.stack((pos_y[..., 0::2].sin(), pos_y[..., 1::2].cos()), dim=-1).flatten(-2)posemb = torch.cat((pos_y, pos_x), dim=-1)return posemb# 将二维的x,y坐标编码成512维的高维向量
🎜🎜rv_query_embeds-Generierungslogik muss neu geschrieben werden🎜🎜🎜🎜Im oben genannten Inhalt ist Object Query der Ausgangspunkt im BEV-Koordinatensystem. Um den Generierungsprozess der Bildpositionseinbettung zu verfolgen, muss das Papier zunächst die 3D-Raumpunkte im BEV-Koordinatensystem auf das Bildkoordinatensystem projizieren und dann die Verarbeitungslogik der vorherigen Generation der Bildpositionseinbettung verwenden, um dies sicherzustellen Die Logik des Generierungsprozesses ist dieselbe. Das Folgende ist der Kerncode: 🎜def _bev_query_embed(self, ref_points, img_metas):bev_embeds = self.bev_embedding(pos2embed(ref_points, num_pos_feats=self.hidden_dim))return bev_embeds# (bs, Num, 256)
🎜Durch die obige Transformation wird der Punkt im BEV-Raumkoordinatensystem zuerst auf das Bildkoordinatensystem projiziert, und dann wird der Prozess der Generierung von rv_query_embeds unter Verwendung der vorherigen Verarbeitungslogik zur Generierung der Bildpositionseinbettung durchgeführt vollendet. 🎜🎜Letzte Abfrageeinbettung = rv_query_embeds + bev_query_embeds🎜🎜🎜🎜
Transformer-Decoder + FFN-Netzwerk
- Transformer-Decoder
Die Berechnungslogik hier ist genau die gleiche wie beim Decoder in Transformer, aber die Eingabedaten sind etwas anders
- Der erste Punkt ist Speicher: Speicher ist hier Bild Token Das Ergebnis nach Concat mit Lidar-Token (kann als Verschmelzung der beiden Modalitäten verstanden werden
- Der zweite Punkt ist die Positionscodierung: Die Positionscodierung hier ist das Ergebnis der Concat zwischen rv_query_embeds und bev_query_embeds, query_embed ist rv_query_embeds + bev_query_embeds;
- FFN-Netzwerk
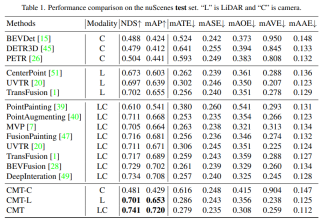
Die Funktion dieses FFN-Netzwerks ist genau die gleiche wie in PETR. Die spezifischen Ausgabeergebnisse finden Sie im Original-PETR-Text, daher werde ich hier nicht zu sehr ins Detail gehen Die experimentellen Ergebnisse des Papiers werden an erster Stelle stehen. Die Autoren des Papiers haben Vergleiche mit den Test- und Validierungssätzen von nuScenes durchgeführt
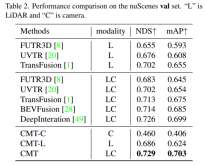
In der Tabelle stellt Modalität die Sensorkategorie dar, die in den Wahrnehmungsalgorithmus eingegeben wird, C stellt den Kamerasensor dar und das Modell speist nur Kameradaten ein. L stellt den Lidar dar Sensor, und das Modell speist nur Punktwolkendaten, und das Modell gibt mehrere Modaldaten ein. Aus den experimentellen Ergebnissen ist ersichtlich, dass die Leistung des CMT-C-Modells höher ist BEVDet und DETR3D. Die Leistung des CMT-L-Modells ist höher als die von reinen Lidar-Wahrnehmungsalgorithmusmodellen wie CenterPoint und UVTR. Nach der Verwendung von Lidar-Punktwolkendaten und Kameradaten übertraf es alle vorhandenen Einzelmodalmethoden und erzielte SOTA-Ergebnisse .Vergleich der Wahrnehmungsergebnisse des Modells mit dem Val-Satz von nuScenes. Es ist ersichtlich, dass die Leistung des Wahrnehmungsmodells von CMT-L die von FUTR3D und UVTR übertrifft. CMT übertrifft bestehende multimodale Wahrnehmungsalgorithmen bei weitem. Multimodale Algorithmen wie FUTR3D, UVTR, TransFusion und BEVFusion haben SOTA-Ergebnisse für den Val-Satz erzielt
- Der nächste Schritt ist der Ablationsexperimentteil der CMT-Innovation
Zuerst führten wir eine Reihe von Ablationsexperimenten durch, um zu bestimmen, ob die Positionskodierung verwendet werden sollte. Durch die experimentellen Ergebnisse wurde festgestellt, dass bei gleichzeitiger Verwendung der Positionskodierung von Bild und Lidar NDS und mAP verwendet wurden Als nächstes haben wir in (c) und (c) des Ablationsexperiments mit verschiedenen Typen und Voxelgrößen des Punktwolken-Backbone-Netzwerks experimentiert. In den Ablationsexperimenten in den Teilen (d) und (e) haben wir verschiedene Versuche hinsichtlich der Art des Kamera-Backbone-Netzwerks und der Größe der Eingangsauflösung unternommen. Das Obige ist nur eine kurze Zusammenfassung des experimentellen Inhalts. Wenn Sie detailliertere Ablationsexperimente erfahren möchten, lesen Sie bitte den Originalartikel.
Abschließend finden Sie hier eine Anzeige der visuellen Ergebnisse der CMT-Wahrnehmungsergebnisse im nuScenes-Datensatz. Aus den experimentellen Ergebnissen ist ersichtlich, dass CMT Es gibt immer noch bessere Wahrnehmungsergebnisse.
Zusammenfassung
Derzeit ist die Zusammenführung verschiedener Modalitäten zur Verbesserung der Wahrnehmungsleistung des Modells zu einer beliebten Forschungsrichtung geworden (insbesondere bei autonomen Fahrzeugen, die mit einer Vielzahl von Sensoren ausgestattet sind). Mittlerweile ist CMT ein vollständiger End-to-End-Wahrnehmungsalgorithmus, der keine zusätzlichen Nachbearbeitungsschritte erfordert und mit dem nuScenes-Datensatz höchste Genauigkeit erreicht. In diesem Artikel wird dieser Artikel ausführlich vorgestellt. Ich hoffe, dass er für alle hilfreich ist. Der Inhalt, der neu geschrieben werden muss, ist: Originallink: https://mp.weixin.qq.com/s/Fx7dkv8f2ibkfO66-5hEXA
Das obige ist der detaillierte Inhalt vonCross-modal Transformer: für schnelle und robuste 3D-Objekterkennung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 So erstellen Sie Ihren persönlichen KI -Assistenten mit Smollm mit Umarmung. SmollmApr 18, 2025 am 11:52 AM
So erstellen Sie Ihren persönlichen KI -Assistenten mit Smollm mit Umarmung. SmollmApr 18, 2025 am 11:52 AMNutzen Sie die Kraft von AI On-Device: Bauen eines persönlichen Chatbot-Cli In der jüngeren Vergangenheit schien das Konzept eines persönlichen KI -Assistenten wie Science -Fiction zu sein. Stellen Sie sich Alex vor, ein Technik -Enthusiast, der von einem klugen, lokalen KI -Begleiter träumt - einer, der nicht angewiesen ist
 KI für psychische Gesundheit wird aufmerksam durch aufregende neue Initiative an der Stanford University analysiertApr 18, 2025 am 11:49 AM
KI für psychische Gesundheit wird aufmerksam durch aufregende neue Initiative an der Stanford University analysiertApr 18, 2025 am 11:49 AMIhre Eröffnungseinführung von AI4MH fand am 15. April 2025 statt, und Luminary Dr. Tom Insel, M. D., berühmter Psychiater und Neurowissenschaftler, diente als Kick-off-Sprecher. Dr. Insel ist bekannt für seine herausragende Arbeit in der psychischen Gesundheitsforschung und für Techno
 Die 2025 WNBA -Entwurfsklasse tritt in eine Liga ein, die wächst und gegen Online -Belästigung kämpftApr 18, 2025 am 11:44 AM
Die 2025 WNBA -Entwurfsklasse tritt in eine Liga ein, die wächst und gegen Online -Belästigung kämpftApr 18, 2025 am 11:44 AM"Wir möchten sicherstellen, dass die WNBA ein Raum bleibt, in dem sich alle, Spieler, Fans und Unternehmenspartner sicher fühlen, geschätzt und gestärkt sind", erklärte Engelbert und befasste sich mit dem, was zu einer der schädlichsten Herausforderungen des Frauensports geworden ist. Die Anno
 Umfassende Anleitung zu Python -integrierten Datenstrukturen - Analytics VidhyaApr 18, 2025 am 11:43 AM
Umfassende Anleitung zu Python -integrierten Datenstrukturen - Analytics VidhyaApr 18, 2025 am 11:43 AMEinführung Python zeichnet sich als Programmiersprache aus, insbesondere in der Datenwissenschaft und der generativen KI. Eine effiziente Datenmanipulation (Speicherung, Verwaltung und Zugriff) ist bei der Behandlung großer Datensätze von entscheidender Bedeutung. Wir haben zuvor Zahlen und ST abgedeckt
 Erste Eindrücke von OpenAIs neuen Modellen im Vergleich zu AlternativenApr 18, 2025 am 11:41 AM
Erste Eindrücke von OpenAIs neuen Modellen im Vergleich zu AlternativenApr 18, 2025 am 11:41 AMVor dem Eintauchen ist eine wichtige Einschränkung: KI-Leistung ist nicht deterministisch und sehr nutzungsgewohnt. In einfacherer Weise kann Ihre Kilometerleistung variieren. Nehmen Sie diesen (oder einen anderen) Artikel nicht als endgültiges Wort - testen Sie diese Modelle in Ihrem eigenen Szenario
 AI -Portfolio | Wie baue ich ein Portfolio für eine KI -Karriere?Apr 18, 2025 am 11:40 AM
AI -Portfolio | Wie baue ich ein Portfolio für eine KI -Karriere?Apr 18, 2025 am 11:40 AMErstellen eines herausragenden KI/ML -Portfolios: Ein Leitfaden für Anfänger und Profis Das Erstellen eines überzeugenden Portfolios ist entscheidend für die Sicherung von Rollen in der künstlichen Intelligenz (KI) und des maschinellen Lernens (ML). Dieser Leitfaden bietet Rat zum Erstellen eines Portfolios
 Welche Agenten KI könnte für Sicherheitsvorgänge bedeutenApr 18, 2025 am 11:36 AM
Welche Agenten KI könnte für Sicherheitsvorgänge bedeutenApr 18, 2025 am 11:36 AMDas Ergebnis? Burnout, Ineffizienz und eine Erweiterung zwischen Erkennung und Wirkung. Nichts davon sollte für jeden, der in Cybersicherheit arbeitet, einen Schock erfolgen. Das Versprechen der Agenten -KI hat sich jedoch als potenzieller Wendepunkt herausgestellt. Diese neue Klasse
 Google versus openai: Der KI -Kampf für SchülerApr 18, 2025 am 11:31 AM
Google versus openai: Der KI -Kampf für SchülerApr 18, 2025 am 11:31 AMSofortige Auswirkungen gegen langfristige Partnerschaft? Vor zwei Wochen hat Openai ein leistungsstarkes kurzfristiges Angebot vorangetrieben und bis Ende Mai 2025 den kostenlosen Zugang zu Chatgpt und Ende Mai 2025 gewährt. Dieses Tool enthält GPT-4O, A A A.


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

ZendStudio 13.5.1 Mac
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

mPDF
mPDF ist eine PHP-Bibliothek, die PDF-Dateien aus UTF-8-codiertem HTML generieren kann. Der ursprüngliche Autor, Ian Back, hat mPDF geschrieben, um PDF-Dateien „on the fly“ von seiner Website auszugeben und verschiedene Sprachen zu verarbeiten. Es ist langsamer und erzeugt bei der Verwendung von Unicode-Schriftarten größere Dateien als Originalskripte wie HTML2FPDF, unterstützt aber CSS-Stile usw. und verfügt über viele Verbesserungen. Unterstützt fast alle Sprachen, einschließlich RTL (Arabisch und Hebräisch) und CJK (Chinesisch, Japanisch und Koreanisch). Unterstützt verschachtelte Elemente auf Blockebene (wie P, DIV),

EditPlus chinesische Crack-Version
Geringe Größe, Syntaxhervorhebung, unterstützt keine Code-Eingabeaufforderungsfunktion

Dreamweaver CS6
Visuelle Webentwicklungstools

