

 Technologie-PeripheriegeräteKIGNNs-Technologie angewendet auf Empfehlungssysteme und ihre praktischen Anwendungen
Technologie-PeripheriegeräteKIGNNs-Technologie angewendet auf Empfehlungssysteme und ihre praktischen AnwendungenGNNs-Technologie angewendet auf Empfehlungssysteme und ihre praktischen Anwendungen


1. Die Entwicklung der zugrunde liegenden Rechenleistung des GNN-Empfehlungssystems
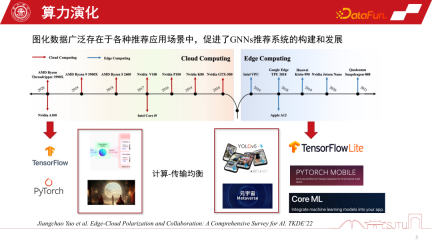
In den letzten 20 Jahren haben sich die Rechenformen ständig weiterentwickelt. Vor 2010 war Cloud Computing besonders beliebt, während andere Computing-Formen relativ schwach waren. Mit der rasanten Entwicklung der Hardware-Rechenleistung und der Einführung von End-Side-Chips ist Edge Computing besonders wichtig geworden. Die beiden aktuellen großen Computerformen haben die Entwicklung der KI in zwei polarisierte Richtungen geprägt. Einerseits können wir im Rahmen der Cloud-Computing-Architektur die Fähigkeiten extrem großer Cluster nutzen, um groß angelegte KI-Modelle wie das Foundation Model zu trainieren oder einige generative Modelle. Andererseits können wir mit der Entwicklung des Edge Computing auch KI-Modelle auf der Terminalseite bereitstellen, um einfachere Dienste bereitzustellen, wie beispielsweise die Ausführung verschiedener Erkennungsaufgaben auf der Terminalseite. Gleichzeitig werden mit der Entwicklung des Metaversums die Berechnungen vieler Modelle auf die Endseite gestellt. Daher ist das Kernproblem, das diese beiden Computerformen in Einklang bringen wollen, das Gleichgewicht zwischen Computer und Übertragung, gefolgt von der polarisierten Entwicklung der künstlichen Intelligenz.
2. Personalisierung des clientseitigen GNNs-Empfehlungssystems
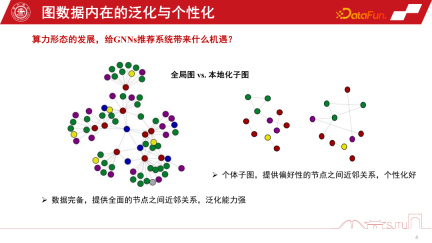
Welche Möglichkeiten bieten diese beiden Computerformen für das GNNs-Empfehlungssystem?
Duanyuns Perspektive kann mit der Perspektive eines globalen Bildes und eines lokalisierten Untergraphen verglichen werden. Im Empfehlungssystem von GNNs ist der globale Subgraph ein globaler Subgraph, der kontinuierlich aus vielen Subgraphen auf Knotenebene gesammelt wird. Sein Vorteil besteht darin, dass die Daten vollständig sind und eine relativ umfassende Beziehung zwischen Knoten bereitgestellt werden kann. Diese Art der induktiven Vorspannung kann universeller sein. Sie fasst die Regeln verschiedener Knoten zusammen und extrahiert die induktive Vorspannung, sodass sie eine starke Verallgemeinerungsfähigkeit aufweist. Der lokalisierte Untergraph ist nicht unbedingt besonders vollständig, aber sein Vorteil besteht darin, dass er die Entwicklung des Verhaltens einer Person auf dem Untergraphen genau beschreiben und eine personalisierte Knotenbeziehungseinrichtung ermöglichen kann. Daher ist die Beziehung zwischen dem Terminal und der Cloud ein bisschen wie ein globaler Untergraph und ein lokalisierter Untergraph. Cloud Computing kann leistungsstarke zentralisierte Rechenleistung für die Bereitstellung von Diensten bereitstellen, während das Terminal einige personalisierte Datendienste bereitstellen kann. Wir können die Vorteile globaler Diagramme und lokalisierter Unterdiagramme kombinieren, um die Leistung des Modells besser zu verbessern. Eine im WSDM2022 veröffentlichte Studie Dieses Jahr habe ich dies untersucht. Es wird ein Ada-GNN-Modell (Anpassung an lokale Muster zur Verbesserung grafischer neuronaler Netzwerke) vorgeschlagen, das über eine Gesamtgraphenmodellierung für den globalen Graphen verfügt und außerdem einige lokale Modelle unter Verwendung von Untergraphen erstellt, um einige Anpassungen vorzunehmen. Der Kern einer solchen Anpassung besteht darin, dem Modell, das das globale Modell und das lokale Modell kombiniert, zu ermöglichen, die Regeln des lokalen Diagramms verfeinert wahrzunehmen und die personalisierte Lernleistung zu verbessern.
Jetzt erklären wir anhand eines konkreten Beispiels, warum wir auf Untergraphen achten sollten. Im E-Commerce-Empfehlungssystem gibt es eine Gruppe digitaler Enthusiasten, die die Beziehung zwischen digitalen Produkten wie Mobiltelefonen, Pads, Kameras und Peripherieprodukten für Mobiltelefone beschreiben können. Sobald er auf eine der Kameras klickte, wurde eine induktive Vorspannung erzeugt. Eine durch die Gruppenbeitragskarte induzierte induktive Bias-Karte kann uns dazu ermutigen, diese Art von Mobiltelefon zu empfehlen. Wenn wir jedoch zur individuellen Perspektive zurückkehren, wenn er ein Fotografie-Enthusiast ist und besonderes Augenmerk auf Fotoprodukte legt, führt dies manchmal zu einem Paradoxon unten dargestellt. Ist die durch die Gruppenbeitragskarte induzierte induktive Verzerrung für bestimmte Gruppen, insbesondere für diese Schwanzgruppe, zu stark? Dies wird oft als Matthew-Effekt bezeichnet. 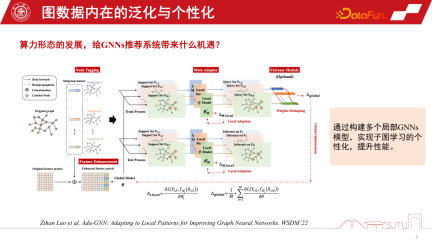
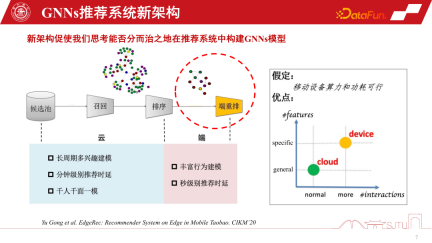
Im Allgemeinen können die vorhandenen polarisierten Rechenformen unsere Modellierung von GNNs-Empfehlungssystemen umgestalten. Herkömmliche Empfehlungssysteme rufen Produkte oder Artikel aus dem Kandidatenpool ab, erkennen die Beziehung zwischen ihnen durch GNN-Modellierung und bewerten und empfehlen dann Benutzer. Aufgrund der Unterstützung von Edge Computing können wir jedoch Personalisierungsmodelle auf der Endseite einsetzen, um eine feinkörnigere Personalisierung wahrzunehmen, indem wir auf Teilgraphen lernen. Natürlich geht diese neue Empfehlungssystemarchitektur für die Zusammenarbeit zwischen Gerät und Cloud davon aus, dass die Rechenleistung und der Stromverbrauch des Geräts machbar sind. Die tatsächliche Situation ist jedoch, dass der Rechenleistungsaufwand eines kleinen Modells nicht groß ist. Wenn Sie ihn auf ein oder zwei Megabyte komprimieren und den Rechenleistungsaufwand auf ein vorhandenes Smartphone übertragen, verbraucht es tatsächlich nicht mehr Rechenleistung als eine Spiele-APP. und große elektrische Energie. Daher bietet es mit der Weiterentwicklung des Edge Computing und der Verbesserung der Endgeräteleistung größere Möglichkeiten für mehr GNNs-Modellierung auf der Endseite Endseitige Rechenleistung und Speicherkapazität müssen berücksichtigt werden. Wir haben die Modellkomprimierung auch bereits erwähnt. Wenn Sie möchten, dass das GNNs-Modell auf der Geräteseite effektiver ist, müssen Sie eine Modellkomprimierung durchführen, wenn Sie ein relativ großes GNNs-Modell darauf platzieren. Die traditionellen Methoden der Modellkomprimierung, -bereinigung und -quantisierung können auf bestehende GNNs-Modelle angewendet werden, führen jedoch zu Leistungseinbußen in Empfehlungssystemen. In diesem Szenario können wir die Leistung nicht opfern, um ein geräteseitiges Modell zu erstellen. Daher sind Bereinigung und Quantisierung zwar nützlich, haben aber nur begrenzte Auswirkungen.
 Eine weitere nützliche Methode zur Modellkomprimierung ist die Destillation. Obwohl es nur um ein Vielfaches reduziert werden kann, sind die Kosten ähnlich. Eine kürzlich in KDD veröffentlichte Studie befasst sich mit der Destillation von GNNs. Bei GNNs steht die Destillation der grafischen Datenmodellierung vor der Herausforderung, dass Abstandsmaße leicht im Logit-Raum, aber im latenten Merkmalsraum definiert werden können, insbesondere schichtweise Abstandsmaße zwischen Lehrer-GNNs und Schüler-GNNs. In dieser Hinsicht bietet diese Forschung zu KDD eine Lösung, um lernbares Design zu erreichen, indem eine Metrik durch kontradiktorische Generierung erlernt wird sehr nützliche Technik. Es hängt eng mit der Modellarchitektur des GNNs-Empfehlungssystems zusammen, da die unterste Schicht von GNNs die Artikeleinbettung des Produkts ist und nach mehreren Schichten nichtlinearer Transformation von MLP die Aggregationsstrategie von GNNs verwendet wird
Eine weitere nützliche Methode zur Modellkomprimierung ist die Destillation. Obwohl es nur um ein Vielfaches reduziert werden kann, sind die Kosten ähnlich. Eine kürzlich in KDD veröffentlichte Studie befasst sich mit der Destillation von GNNs. Bei GNNs steht die Destillation der grafischen Datenmodellierung vor der Herausforderung, dass Abstandsmaße leicht im Logit-Raum, aber im latenten Merkmalsraum definiert werden können, insbesondere schichtweise Abstandsmaße zwischen Lehrer-GNNs und Schüler-GNNs. In dieser Hinsicht bietet diese Forschung zu KDD eine Lösung, um lernbares Design zu erreichen, indem eine Metrik durch kontradiktorische Generierung erlernt wird sehr nützliche Technik. Es hängt eng mit der Modellarchitektur des GNNs-Empfehlungssystems zusammen, da die unterste Schicht von GNNs die Artikeleinbettung des Produkts ist und nach mehreren Schichten nichtlinearer Transformation von MLP die Aggregationsstrategie von GNNs verwendet wird
Sobald ein Model trainiert ist, hat es einen natürlichen Vorteil. Die Basisschicht wird vollständig gemeinsam genutzt und nur die GNNs-Schicht kann angepasst werden. Zur Personalisierung können wir hier das Modell in zwei Teile aufteilen und den öffentlichen Teil des Modells in die Cloud stellen. Da die Rechenleistung ausreicht, kann der personalisierte Teil auf dem Terminal bereitgestellt werden. Auf diese Weise müssen wir nur die GNN des Zwischenkernels im Terminal speichern. In tatsächlichen Empfehlungssystemen kann dieser Ansatz den Speicheraufwand des gesamten Modells erheblich einsparen. Wir haben in Alibabas Szenarien geübt, dass das Modell nach der geteilten Bereitstellung die KB-Ebene erreichen kann. Durch weitere einfache Bitquantisierung kann das Modell sehr klein gemacht werden, und es entsteht fast kein besonders großer Overhead, wenn es auf dem Terminal platziert wird. Dies ist natürlich eine geteilte Methode, die auf Erfahrung basiert. Eine der jüngsten auf KDD veröffentlichten Arbeiten von Huawei ist die automatische Modellaufteilung, die die Leistung von Endgeräten erfassen und dieses Modell automatisch aufteilen kann. Bei der Anwendung auf GNNs kann natürlich eine gewisse Umgestaltung erforderlich sein
Bei der Bereitstellung von Modellen in einigen ernsthaften Verteilungsübertragungsszenarien sind unsere vorab trainierten Modelle bereits relativ alt, bevor sie auf der Endseite bereitgestellt werden. Dies liegt daran, dass die Häufigkeit, mit der tatsächliche Diagrammdaten zum Training zurückfließen, relativ langsam ist und manchmal eine Woche dauern kann. Der Hauptengpass liegt hier in „Ressourcenbeschränkungen“, obwohl dies in der Forschung möglicherweise nicht der Fall ist Engpässe werden in der Praxis auf das Problem veralteter End-Side-Modelle stoßen. Wenn sich die Domäne ändert, ändern sich auch die Daten, das Modell ist nicht mehr anwendbar und die Leistung nimmt ab. Zu diesem Zeitpunkt ist eine Online-Personalisierung des GNNs-Modells erforderlich, aber die Personalisierung am Ende steht vor der Herausforderung der endseitigen Rechenleistung und des Speicheraufwands.
Eine weitere Herausforderung ist die Datenspärlichkeit. Da die Enddaten nur einzelne Knoten haben, ist auch die Datenspärlichkeit eine große Herausforderung. Ein relativ effizienter Ansatz in der neueren Forschung ist der Parameter-effiziente Transfer, der die Anwendung einiger Modell-Patches zwischen Schichten beinhaltet. Er kann mit einem Restnetzwerk verglichen werden, die Patches werden jedoch während des Lernens gelernt. Durch einen Flag-Mechanismus kann es bei Gebrauch eingeschaltet und bei Nichtgebrauch ausgeschaltet werden. Wenn es ausgeschaltet ist, kann es auf das ursprüngliche Basismodell zurückgesetzt werden, was sowohl sicher als auch effizient ist.
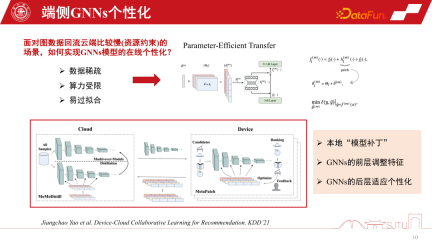
Dies ist ein praktischerer und effizienterer Ansatz, der auf KDD2021 veröffentlicht wurde und eine Online-Personalisierung von GNNs-Modellen erreichen kann. Das Wichtigste ist, dass wir aus einer solchen Praxis herausgefunden haben, dass durch die Erfassung der Teilgrapheninformationen dieses lokalen Modells die Gesamtleistung tatsächlich stetig verbessert werden kann. Es lindert auch den Matthew-Effekt.
In Empfehlungssystemen stehen Endbenutzer immer noch vor dem Problem des Matthew-Effekts auf Diagrammdaten. Wenn wir jedoch einen „Teile-und-Herrsche“-Modellierungsansatz anwenden und Untergraphen personalisieren, können wir das Empfehlungserlebnis für Benutzer mit spärlichem Verhalten verbessern. Insbesondere für die Tail Crowd wird die Leistungsverbesserung bedeutender sein
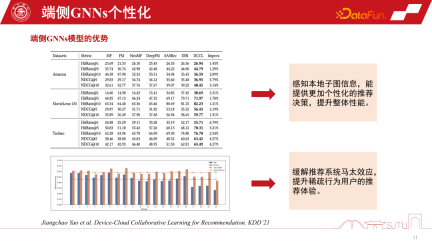
3. Implementierung des geräte-cloud-kollaborativen GNNs-Empfehlungssystems
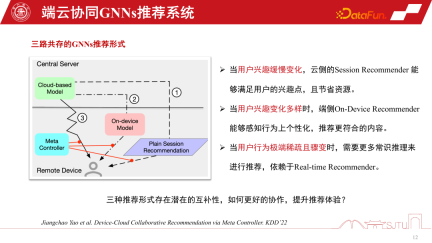
Im GNNs-Empfehlungssystem ist eines das GNNs-Modell des cloudseitigen Dienstes . Es gibt auch ein kleines Modell endseitiger GNNs. Es gibt drei Implementierungsformen von GNNs-Empfehlungssystemdiensten. Die erste ist die Sitzungsempfehlung, eine gängige Batch-Sitzungsempfehlung in Empfehlungssystemen, um Kosten zu sparen Die Empfehlung wird erneut ausgelöst. Die zweite besteht darin, in extremen Fällen jeweils nur eine zu empfehlen. Der dritte Typ ist das von uns erwähnte durchgängig personalisierte Modell. Jede dieser drei Empfehlungssystemmethoden hat ihre eigenen Vorteile. Wenn sich die Benutzerinteressen langsam ändern, muss die Cloud-Seite dies nur genau wahrnehmen. Daher reicht es aus, wenn das Cloud-Seitenmodell Sitzungsempfehlungen ausführt. Wenn sich die Benutzerinteressen immer vielfältiger ändern, kann die personalisierte Empfehlung endseitiger Untergraphen die Empfehlungsleistung relativ verbessern.
In Situationen, in denen das Nutzerverhalten plötzlich sehr spärlich wird, basieren Empfehlungen eher auf dem gesunden Menschenverstand. Um diese drei Empfehlungsverhalten zu koordinieren, kann ein Metakoordinator – Meta Controller – eingerichtet werden, um das GNNs-Empfehlungssystem zu koordinieren der Datensatz, weil Wir wissen nicht, wie wir diese Modelle verwalten und Entscheidungen treffen sollen. Dies ist also nur ein kontrafaktischer Argumentationsmechanismus. Obwohl wir nicht über einen solchen Datensatz verfügen, verfügen wir über einen Einkanal-Datensatz, und wir erstellen einige Proxy-Modelle durch Auswertung, um ihre kausalen Auswirkungen zu bewerten. Wenn der kausale Effekt relativ groß ist, sind die Vorteile einer solchen Entscheidung relativ groß und es können Pseudoetiketten, also kontrafaktische Datensätze, erstellt werden. Die spezifischen Schritte sind wie folgt:
Es gibt drei Modelle D0, D1 und D2 in einem einzigen Kanal, indem man das kausale Modell eines Agenten lernt, seine kausalen Auswirkungen abschätzt, um eine Entscheidungsbezeichnung zu erstellen, und ein kontrafaktisches Modell erstellt Datensatz zum Trainieren des Elementkoordinators. Schließlich können wir beweisen, dass dieser Metakoordinator im Vergleich zu jedem Einkanalmodell eine stabile Leistungsverbesserung aufweist. Es hat erhebliche Vorteile gegenüber Zufallsheuristiken. Auf diese Weise können wir ein Empfehlungssystem für die Zusammenarbeit zwischen Gerät und Cloud aufbauen.
4. Sicherheitsprobleme des geräteseitigen GNNs-Empfehlungssystems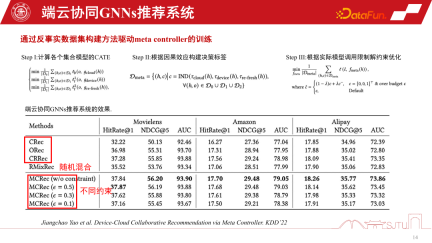
Lassen Sie uns abschließend die Sicherheitsprobleme des geräteseitigen GNNs-Empfehlungssystems besprechen. Sobald das kollaborative GNNs-Empfehlungssystem zwischen Gerät und Cloud zur Verwendung freigegeben wird, wird es in der offenen Umgebung unweigerlich auf Probleme stoßen. Da das Modell zum Lernen personalisiert werden muss, bestehen einige Angriffsrisiken wie Escape-Angriffe, Poisoning-Angriffe, Backdoor-Angriffe usw., die letztendlich dazu führen können, dass das Empfehlungssystem enormen Sicherheitsrisiken ausgesetzt ist
Der zugrunde liegende Rechenleistungstreiber hat die Richtung des aktuellen Cloud-Kollaborations-GNNs-Empfehlungssystems aufgezeigt, befindet sich jedoch noch in einem frühen Entwicklungsstadium und weist einige potenzielle Probleme auf, beispielsweise Sicherheitsprobleme Im Bereich der personalisierten Modellmodellierung gibt es noch viel Luft nach oben.
5. Frage- und Antwortsitzung
F1: Wird der Datenverkehr der Untergraphen am Ende zu stark verteilt?
A1: Das Unterbild wird nicht verteilt, sondern tatsächlich aggregiert. Der erste Punkt besteht darin, dass Unterbilder begleitend verteilt werden. Wenn wir beispielsweise ein Produkt empfehlen, enthält es natürlich die Attributinformationen des Produkts. Hier verursacht die begleitende Ausgabe den gleichen Overhead wie die Attribute. Tatsächlich ist der Overhead nicht sehr hoch. Weil es nicht das gesamte große Bild liefert, sondern nur einige Nachbar-Untergraphen. Die Nachbar-Untergraphen zweiter Ordnung sind höchstens noch sehr klein. Der zweite Punkt besteht darin, dass einige Unterdiagramme am Ende automatisch auf der Grundlage einiger Koexistenzen und Klicks basierend auf dem Feedback des Benutzerverhaltens erstellt werden. Es handelt sich also um eine Form der Double-End-Aggregation, und die Gesamtkosten sind nicht besonders hoch.
Das obige ist der detaillierte Inhalt vonGNNs-Technologie angewendet auf Empfehlungssysteme und ihre praktischen Anwendungen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 So erstellen Sie Ihren persönlichen KI -Assistenten mit Smollm mit Umarmung. SmollmApr 18, 2025 am 11:52 AM
So erstellen Sie Ihren persönlichen KI -Assistenten mit Smollm mit Umarmung. SmollmApr 18, 2025 am 11:52 AMNutzen Sie die Kraft von AI On-Device: Bauen eines persönlichen Chatbot-Cli In der jüngeren Vergangenheit schien das Konzept eines persönlichen KI -Assistenten wie Science -Fiction zu sein. Stellen Sie sich Alex vor, ein Technik -Enthusiast, der von einem klugen, lokalen KI -Begleiter träumt - einer, der nicht angewiesen ist
 KI für psychische Gesundheit wird aufmerksam durch aufregende neue Initiative an der Stanford University analysiertApr 18, 2025 am 11:49 AM
KI für psychische Gesundheit wird aufmerksam durch aufregende neue Initiative an der Stanford University analysiertApr 18, 2025 am 11:49 AMIhre Eröffnungseinführung von AI4MH fand am 15. April 2025 statt, und Luminary Dr. Tom Insel, M. D., berühmter Psychiater und Neurowissenschaftler, diente als Kick-off-Sprecher. Dr. Insel ist bekannt für seine herausragende Arbeit in der psychischen Gesundheitsforschung und für Techno
 Die 2025 WNBA -Entwurfsklasse tritt in eine Liga ein, die wächst und gegen Online -Belästigung kämpftApr 18, 2025 am 11:44 AM
Die 2025 WNBA -Entwurfsklasse tritt in eine Liga ein, die wächst und gegen Online -Belästigung kämpftApr 18, 2025 am 11:44 AM"Wir möchten sicherstellen, dass die WNBA ein Raum bleibt, in dem sich alle, Spieler, Fans und Unternehmenspartner sicher fühlen, geschätzt und gestärkt sind", erklärte Engelbert und befasste sich mit dem, was zu einer der schädlichsten Herausforderungen des Frauensports geworden ist. Die Anno
 Umfassende Anleitung zu Python -integrierten Datenstrukturen - Analytics VidhyaApr 18, 2025 am 11:43 AM
Umfassende Anleitung zu Python -integrierten Datenstrukturen - Analytics VidhyaApr 18, 2025 am 11:43 AMEinführung Python zeichnet sich als Programmiersprache aus, insbesondere in der Datenwissenschaft und der generativen KI. Eine effiziente Datenmanipulation (Speicherung, Verwaltung und Zugriff) ist bei der Behandlung großer Datensätze von entscheidender Bedeutung. Wir haben zuvor Zahlen und ST abgedeckt
 Erste Eindrücke von OpenAIs neuen Modellen im Vergleich zu AlternativenApr 18, 2025 am 11:41 AM
Erste Eindrücke von OpenAIs neuen Modellen im Vergleich zu AlternativenApr 18, 2025 am 11:41 AMVor dem Eintauchen ist eine wichtige Einschränkung: KI-Leistung ist nicht deterministisch und sehr nutzungsgewohnt. In einfacherer Weise kann Ihre Kilometerleistung variieren. Nehmen Sie diesen (oder einen anderen) Artikel nicht als endgültiges Wort - testen Sie diese Modelle in Ihrem eigenen Szenario
 AI -Portfolio | Wie baue ich ein Portfolio für eine KI -Karriere?Apr 18, 2025 am 11:40 AM
AI -Portfolio | Wie baue ich ein Portfolio für eine KI -Karriere?Apr 18, 2025 am 11:40 AMErstellen eines herausragenden KI/ML -Portfolios: Ein Leitfaden für Anfänger und Profis Das Erstellen eines überzeugenden Portfolios ist entscheidend für die Sicherung von Rollen in der künstlichen Intelligenz (KI) und des maschinellen Lernens (ML). Dieser Leitfaden bietet Rat zum Erstellen eines Portfolios
 Welche Agenten KI könnte für Sicherheitsvorgänge bedeutenApr 18, 2025 am 11:36 AM
Welche Agenten KI könnte für Sicherheitsvorgänge bedeutenApr 18, 2025 am 11:36 AMDas Ergebnis? Burnout, Ineffizienz und eine Erweiterung zwischen Erkennung und Wirkung. Nichts davon sollte für jeden, der in Cybersicherheit arbeitet, einen Schock erfolgen. Das Versprechen der Agenten -KI hat sich jedoch als potenzieller Wendepunkt herausgestellt. Diese neue Klasse
 Google versus openai: Der KI -Kampf für SchülerApr 18, 2025 am 11:31 AM
Google versus openai: Der KI -Kampf für SchülerApr 18, 2025 am 11:31 AMSofortige Auswirkungen gegen langfristige Partnerschaft? Vor zwei Wochen hat Openai ein leistungsstarkes kurzfristiges Angebot vorangetrieben und bis Ende Mai 2025 den kostenlosen Zugang zu Chatgpt und Ende Mai 2025 gewährt. Dieses Tool enthält GPT-4O, A A A.


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SecLists
SecLists ist der ultimative Begleiter für Sicherheitstester. Dabei handelt es sich um eine Sammlung verschiedener Arten von Listen, die häufig bei Sicherheitsbewertungen verwendet werden, an einem Ort. SecLists trägt dazu bei, Sicherheitstests effizienter und produktiver zu gestalten, indem es bequem alle Listen bereitstellt, die ein Sicherheitstester benötigen könnte. Zu den Listentypen gehören Benutzernamen, Passwörter, URLs, Fuzzing-Payloads, Muster für vertrauliche Daten, Web-Shells und mehr. Der Tester kann dieses Repository einfach auf einen neuen Testcomputer übertragen und hat dann Zugriff auf alle Arten von Listen, die er benötigt.

PHPStorm Mac-Version
Das neueste (2018.2.1) professionelle, integrierte PHP-Entwicklungstool

Herunterladen der Mac-Version des Atom-Editors
Der beliebteste Open-Source-Editor

ZendStudio 13.5.1 Mac
Leistungsstarke integrierte PHP-Entwicklungsumgebung

