
Heim >Technologie-Peripheriegeräte >KI >Methode zur Rahmenschätzung in Innenräumen mithilfe eines Panorama-Modells der visuellen Selbstaufmerksamkeit
Methode zur Rahmenschätzung in Innenräumen mithilfe eines Panorama-Modells der visuellen Selbstaufmerksamkeit

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-10-07 09:37:01954Durchsuche

1. Forschungshintergrund
Diese Methode konzentriert sich hauptsächlich auf die Aufgabe zur Schätzung des Innenrahmens (Innenraumschätzung, Layoutschätzung). Die Aufgabe gibt ein 2D-Bild ein und gibt ein dreidimensionales Modell der durch das Bild beschriebenen Szene aus . Angesichts der Komplexität der direkten Ausgabe eines 3D-Modells wird diese Aufgabe im Allgemeinen in die Ausgabe der Informationen von drei Linien: Wandlinien, Deckenlinien und Bodenlinien im 2D-Bild und die anschließende Rekonstruktion des 3D-Modells des Raums durch Nachbearbeitung unterteilt. Verarbeitungsvorgänge basierend auf den Zeileninformationen. Das dreidimensionale Modell kann später in spezifischen Anwendungsszenarien wie der Reproduktion von Innenszenen und der VR-Hausbesichtigung weiter verwendet werden. Im Gegensatz zur Tiefenschätzungsmethode stellt diese Methode die räumliche geometrische Struktur auf der Grundlage der Schätzung von Innenwandlinien wieder her. Der Vorteil besteht darin, dass sie die geometrische Struktur der Wand flacher machen kann Gegenstände wie Sofas und Stühle in Innenszenen.
Je nach Eingabebild kann es in perspektivbasierte und panoramabasierte Methoden unterteilt werden. Im Vergleich zu perspektivischen Ansichten haben Panoramen einen größeren Betrachtungswinkel und umfangreichere Bildinformationen. Mit der Popularisierung von Panoramaerfassungsgeräten werden Panoramadaten immer umfangreicher, daher gibt es derzeit viele Algorithmen zur Innenbildschätzung basierend auf Panoramabildern, die umfassend untersucht wurden
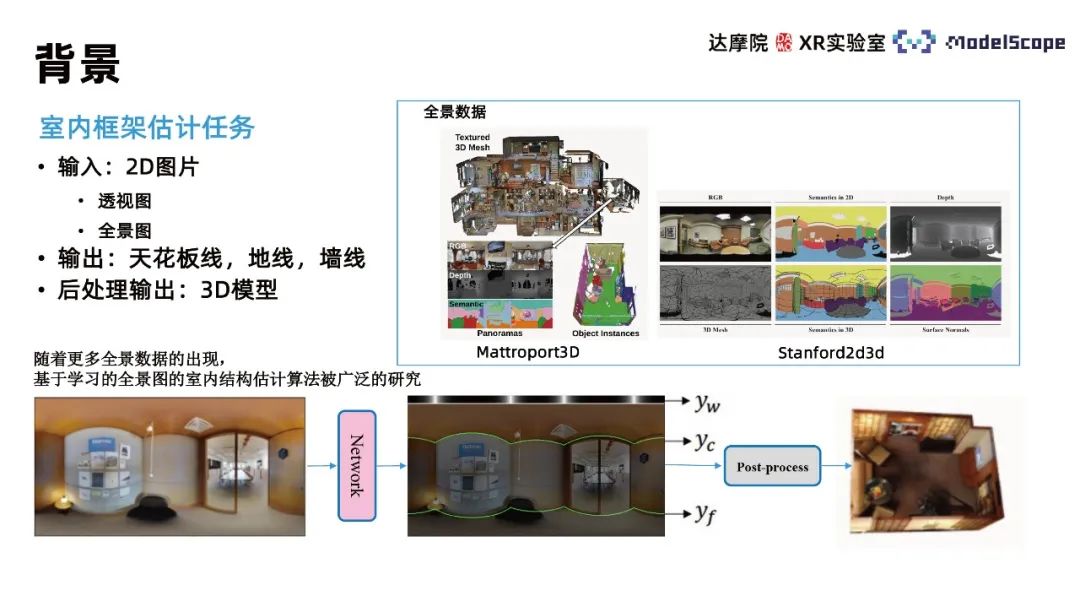
Zu den verwandten Algorithmen gehören hauptsächlich LayoutNet und HorizonNet , HohoNet und Led2-Net usw. Die meisten dieser Methoden basieren auf Faltungs-Neuronalen Netzen, und der Effekt der Wandlinienvorhersage ist an Orten mit komplexen Strukturen schlecht, beispielsweise bei Störungen durch Rauschen, Selbstokklusion usw. Vorhersageergebnisse wie Wandliniendiskontinuität und Wandlinienpositionsfehler werden auftreten. Bei der Aufgabe zur Schätzung der Wandlinienposition führt die ausschließliche Konzentration auf lokale Merkmalsinformationen zu dieser Art von Fehler. Es ist erforderlich, die globalen Informationen im Panorama zu verwenden, um die Positionsverteilung der gesamten Wandlinie für die Schätzung zu berücksichtigen. Die CNN-Methode bietet eine bessere Leistung bei der Extraktion lokaler Merkmale und die Transformer-Methode ist besser bei der Erfassung globaler Informationen. Daher kann die Transformer-Methode auf Aufgaben zur Rahmenschätzung in Innenräumen angewendet werden, um die Aufgabenleistung zu verbessern.
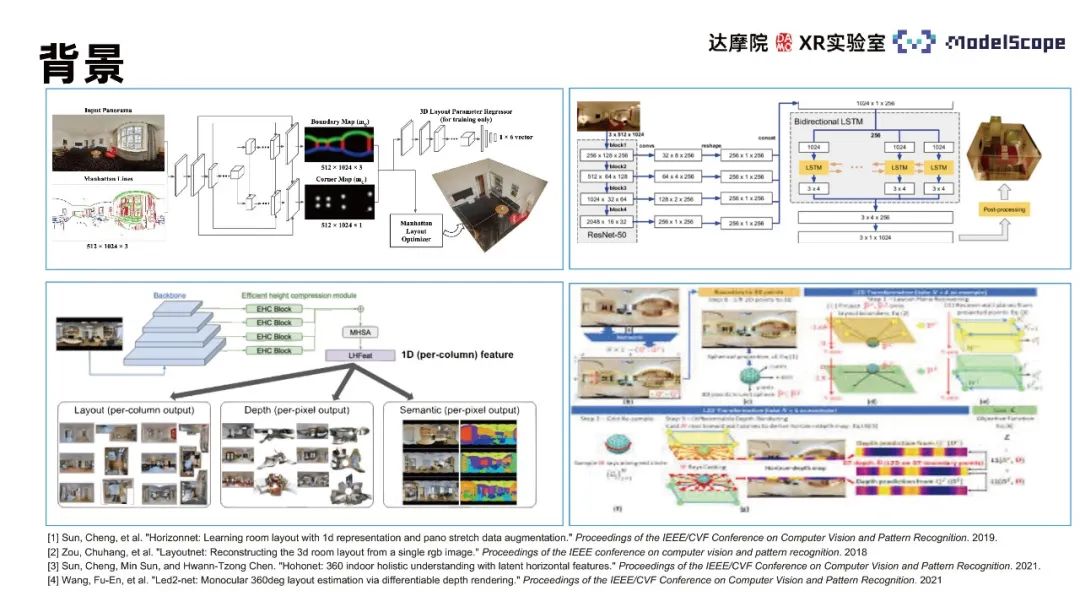
Aufgrund der Abhängigkeit von Trainingsdaten ist der Effekt der Schätzung des Innenrahmens des Panoramas durch Anwendung des Transformers allein auf der Grundlage des perspektivischen Vortrainings nicht ideal. Das PanoViT-Modell ordnet das Panorama im Voraus dem Feature-Raum zu, verwendet den Transformer, um die globalen Informationen des Panoramas im Feature-Raum zu lernen, und berücksichtigt die scheinbaren Strukturinformationen des Panoramas, um die Aufgabe zur Schätzung des Innenrahmens abzuschließen.

2. Methodeneinführung und Ergebnisanzeige
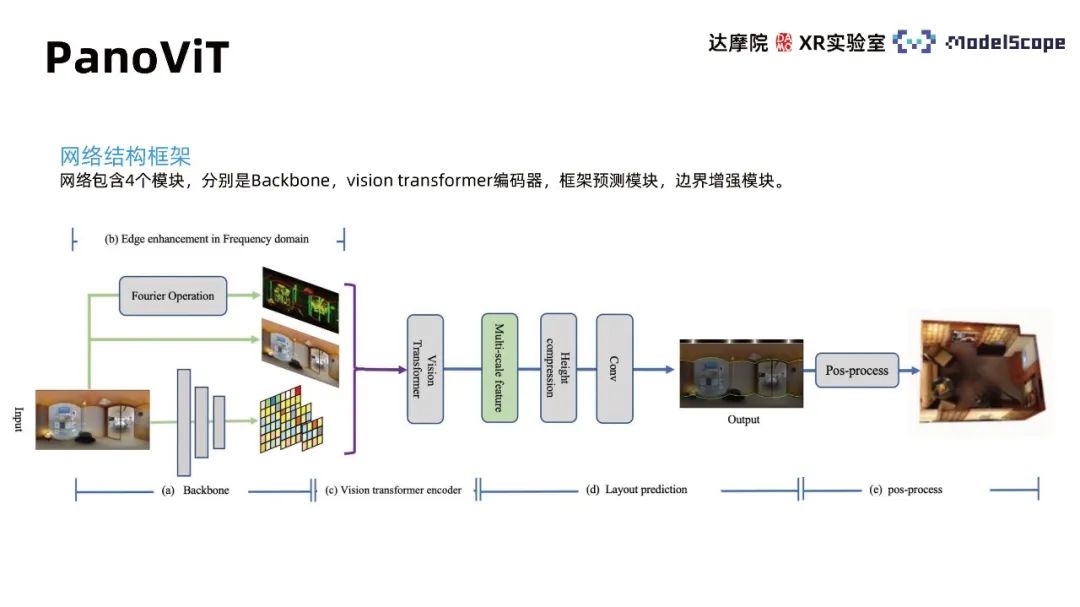
1. PanoViT
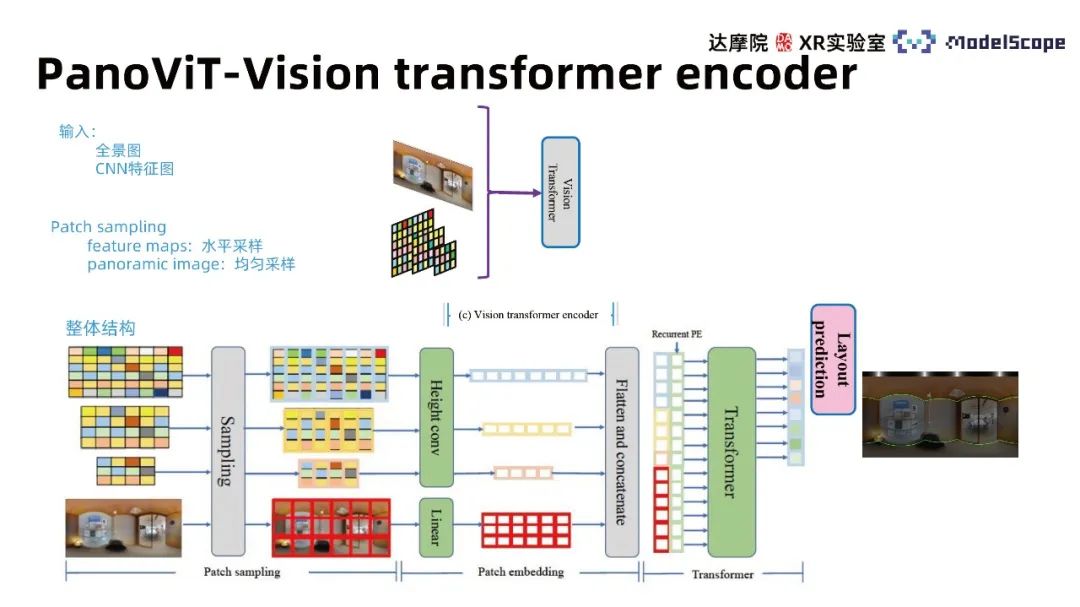
Das Netzwerkstruktur-Framework enthält 4 Module, nämlich Backbone, Vision Transformer Decoder, Frame Prediction Module und Boundary Enhancement Module. Das Backbone-Modul ordnet das Panorama dem Feature-Raum zu. Der Vision-Transformer-Encoder lernt die globale Korrelation im Feature-Raum. Das Frame-Prediction-Modul wandelt die Features in Wandlinien-, Deckenlinien- und Bodenlinieninformationen um -dimensionales Modell des Raums und seiner Grenzen Das Erweiterungsmodul verdeutlicht die Rolle von Grenzinformationen in Panoramabildern für die Rahmenschätzung in Innenräumen.
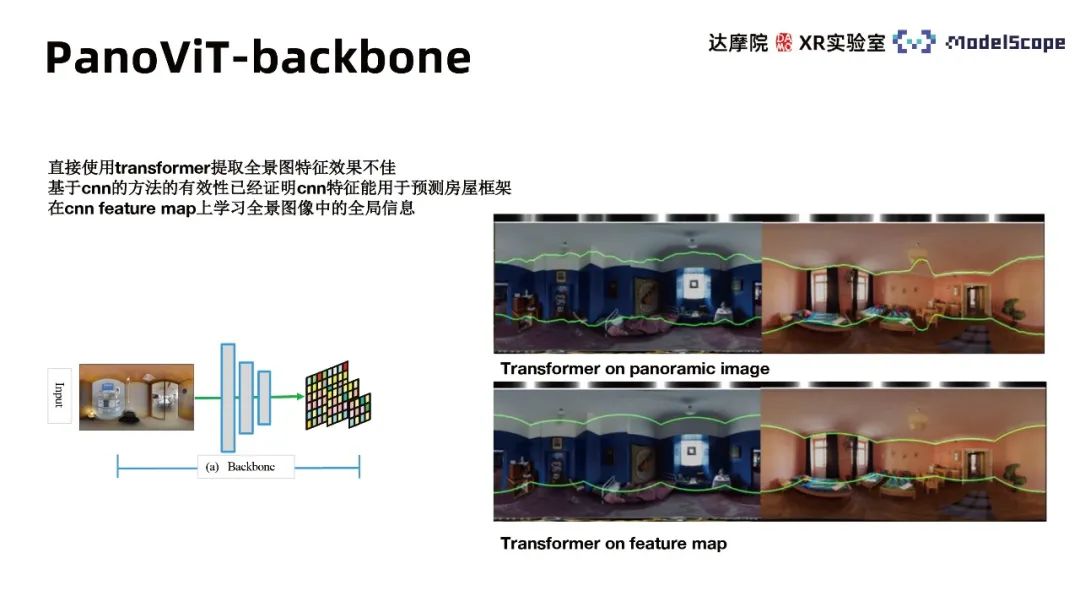
① Backbone-Modul
Da die direkte Verwendung von Transformatoren zum Extrahieren von Panoramamerkmalen nicht gut funktioniert, wurde die Wirksamkeit CNN-basierter Methoden nachgewiesen, dh CNN-Funktionen können zur Vorhersage von Hausrahmen verwendet werden . Daher verwenden wir das Rückgrat von CNN, um Feature-Maps verschiedener Maßstäbe des Panoramas zu extrahieren und die globalen Informationen des Panoramabilds in den Feature-Maps zu lernen. Experimentelle Ergebnisse zeigen, dass die Verwendung von Transformer im Feature-Space deutlich besser ist als die direkte Anwendung auf das Panorama
② Vision-Transformer-Encoder-Modul
Die Hauptarchitektur von Transformer kann hauptsächlich in drei Module unterteilt werden, einschließlich Patch-Sampling, Patch-Einbettung und Multi-Head-Aufmerksamkeit des Transformers. Die Eingabe berücksichtigt sowohl die Panoramabild-Feature-Map als auch das Originalbild und verwendet unterschiedliche Patch-Sampling-Methoden für unterschiedliche Eingaben. Das Originalbild verwendet die einheitliche Abtastmethode und die Feature-Map verwendet die horizontale Abtastmethode. Die Schlussfolgerung von HorizonNet geht davon aus, dass horizontale Merkmale bei der Wandlinienschätzungsaufgabe von größerer Bedeutung sind. In Bezug auf diese Schlussfolgerung werden die Merkmalskartenmerkmale während des Einbettungsprozesses in vertikaler Richtung komprimiert. Die rekurrente PE-Methode wird verwendet, um Merkmale unterschiedlicher Maßstäbe zu kombinieren und im Mehrkopf-Aufmerksamkeitstransformatormodell einen Merkmalsvektor mit der gleichen Länge wie die horizontale Richtung des Originalbilds zu erhalten verschiedene Decoderköpfe.
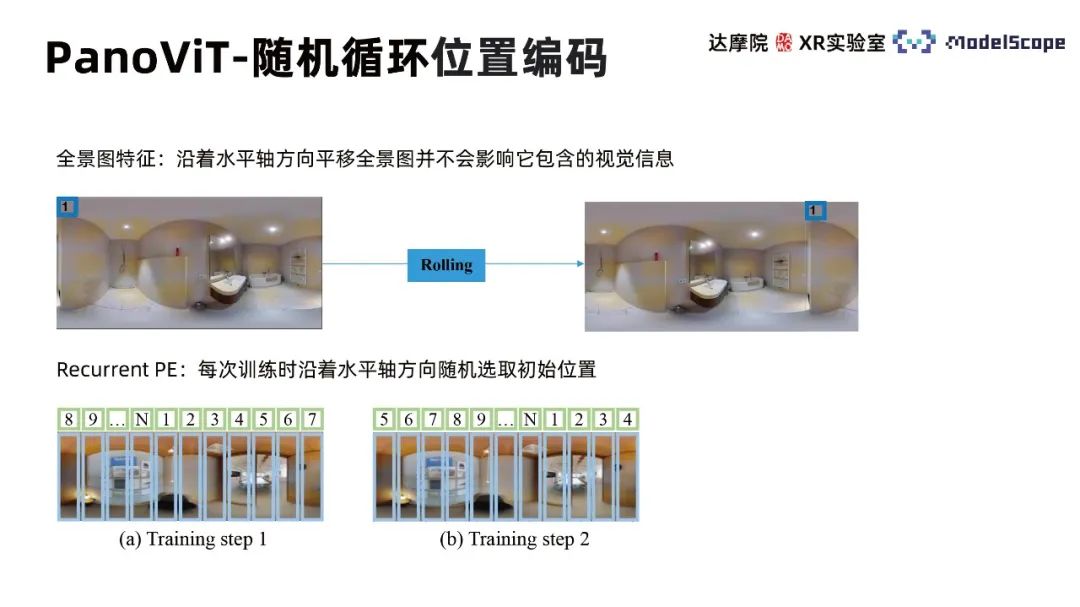
Zufällige zyklische Positionskodierung (Recurrent Position Embedding) berücksichtigt, dass die horizontale Verschiebung des Panoramas die Eigenschaften der visuellen Informationen des Bildes nicht verändert, sodass die Anfangsposition entlang der horizontalen Achse zufällig ausgewählt wird Während jedes Trainings wird der Trainingsprozess durchgeführt. Achten Sie mehr auf die relative Position zwischen verschiedenen Patches als auf die absolute Position.
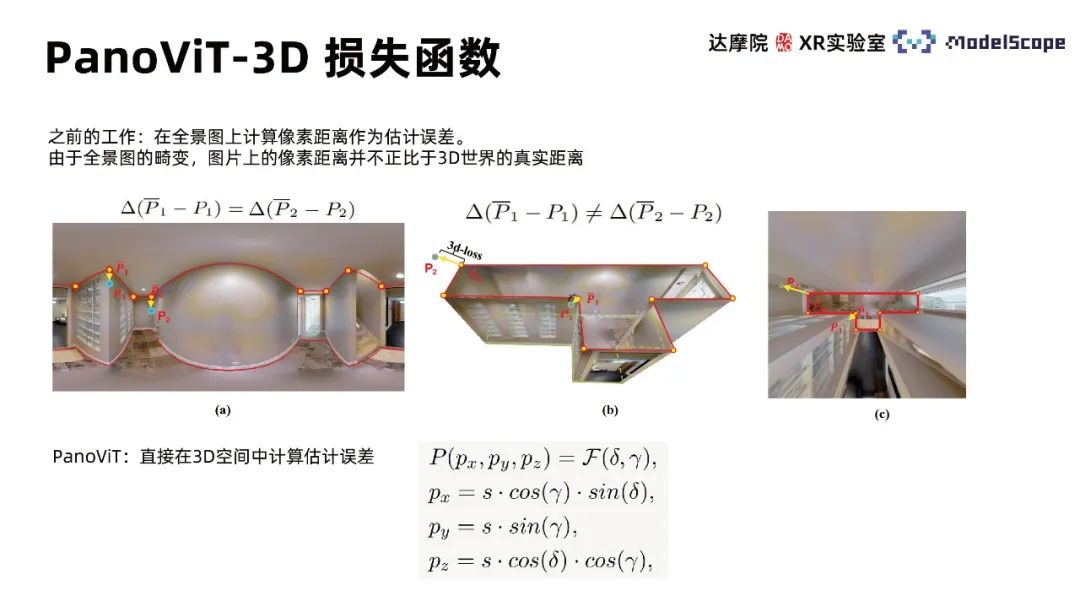
③ Geometrische Informationen des Panoramas
Die vollständige Nutzung der geometrischen Informationen im Panorama kann dazu beitragen, die Leistung von Rahmenschätzungsaufgaben in Innenräumen zu verbessern. Das Grenzverbesserungsmodul im PanoViT-Modell legt Wert darauf, wie die Grenzinformationen im Panorama verwendet werden, und 3D-Verlust trägt dazu bei, die Auswirkungen von Panoramaverzerrungen zu reduzieren.
Das Grenzverbesserungsmodul berücksichtigt die linearen Eigenschaften der Wandlinien bei der Wandlinienerkennungsaufgabe. Die Linieninformationen im Bild sind von herausragender Bedeutung, daher ist es notwendig, die Grenzinformationen hervorzuheben, damit das Netzwerk dies tun kann Verstehen Sie die Verteilung der Linien im Bild. Verwenden Sie die Grenzverstärkungsmethode im Frequenzbereich, um die Panorama-Grenzinformationen hervorzuheben, die Frequenzbereichsdarstellung des Bildes basierend auf der schnellen Fourier-Transformation zu erhalten, eine Maske zum Abtasten im Frequenzbereichsraum zu verwenden und zurück in das Bild mit hervorgehobener Grenze zu transformieren Informationen basierend auf der inversen Fourier-Transformation. Der Kern des Moduls liegt im Maskendesign. Da die Grenze Hochfrequenzinformationen entspricht, wählt die Maske zunächst einen Hochpassfilter aus und tastet unterschiedliche Richtungen im Frequenzbereich ab. Diese Methode ist einfacher zu implementieren und effizienter als die traditionelle LSD-Methode. 
Vorherige Arbeiten berechneten den Pixelabstand auf dem Panorama als Schätzfehler. Aufgrund der Verzerrung des Panoramas ist der Pixelabstand auf dem Bild nicht proportional zum tatsächlichen Abstand in der 3D-Welt. PanoViT nutzt eine 3D-Verlustfunktion, um den Schätzfehler direkt im 3D-Raum zu berechnen.
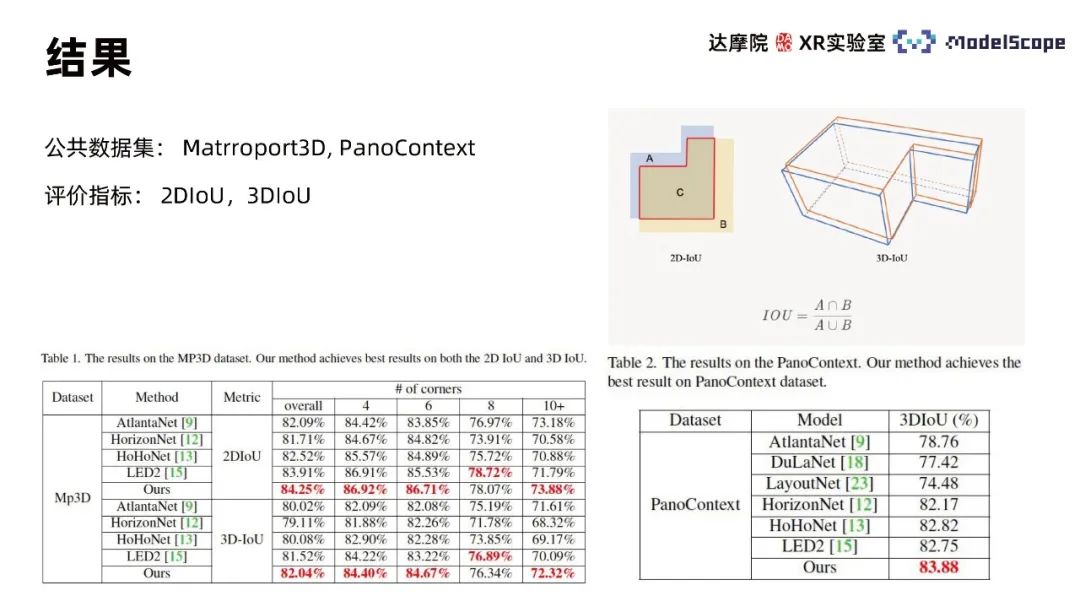
2. Modellergebnisse
Verwendung öffentlicher Datensätze von Martroport3D und PanoContext zur Durchführung von Experimenten, Verwendung von 2DIoU und 3DIoU als Bewertungsindikatoren und Vergleich mit der SOTA-Methode. Die Ergebnisse zeigen, dass die Modellbewertungsindikatoren von PanoViT für die beiden Datensätze grundsätzlich das optimale Niveau erreicht haben und LED2 bei bestimmten Indikatoren nur geringfügig unterlegen sind. Durch den Vergleich der Modellvisualisierungsergebnisse mit Hohonet kann festgestellt werden, dass PanoViT die Richtung von Wandlinien in komplexen Szenen genau identifizieren kann. Durch den Vergleich der Module „Recurrent PE“, „Boundary Enhancement“ und „3D Loss“ in Ablationsexperimenten kann die Wirksamkeit dieser Module überprüft werden Es wurden Panoramen gesammelt. Der selbst erstellte Panoramabilddatensatz enthält verschiedene komplexe Innenszenen und ist nach benutzerdefinierten Regeln annotiert. Als Testdatensatz wurden 5053 Bilder ausgewählt. Die Leistung des PanoViT-Modells und der SOTA-Modellmethode wurde am selbst erstellten Datensatz getestet und es wurde festgestellt, dass sich die Leistung des PanoViT-Modells mit zunehmender Datenmenge erheblich verbessert.
3. So verwenden Sie
- in ModelScope. Öffnen Sie die offizielle Website von modelscope: https://modelscope.cn/home.
- Suchen Sie nach „Panorama-Innenbildschätzung“.
- Klicken Sie auf Quick Use-Online Environment Use-Quick Experience, um das Notizbuch zu öffnen.
- Geben Sie den Beispielcode für die Startseite ein, laden Sie ein 1024*512-Panoramabild hoch, ändern Sie den Bildladepfad und führen Sie den Befehl aus, um die Ergebnisse der Wandlinienvorhersage auszugeben.

Das obige ist der detaillierte Inhalt vonMethode zur Rahmenschätzung in Innenräumen mithilfe eines Panorama-Modells der visuellen Selbstaufmerksamkeit. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!