
Heim >Technologie-Peripheriegeräte >KI >Die umfassendste Übersicht über multimodale Großmodelle finden Sie hier! 7 Microsoft-Forscher arbeiteten intensiv zusammen, 5 Hauptthemen, 119 Seiten Dokument
Die umfassendste Übersicht über multimodale Großmodelle finden Sie hier! 7 Microsoft-Forscher arbeiteten intensiv zusammen, 5 Hauptthemen, 119 Seiten Dokument

- 王林nach vorne
- 2023-09-25 16:49:06829Durchsuche
Der umfassendste Testbericht zu multimodalen Großmodellenist da!
Geschrieben von7 chinesischen Forschern von Microsoft, 119 Seiten——

derzeit perfektioniert und immer noch an der Spitzezwei Arten multimodaler Forschungsrichtungen für große Modelle. Beginnend mit dem Zu Beginn werden fünf spezifische Forschungsthemen umfassend zusammengefasst:
- Visuelles Verständnis
- Visuelle Generierung
- Unified Vision Model
- LLM-gestütztes multimodales großes Modell
- Multimodaler Agent

Multimodale Grundmodelle haben sich von spezialisierten zuPs. Aus diesem Grund hat der Autor am Anfang des Artikels direkt ein Bild vonuniversellen entwickelt.
Doraemon gezeichnet.
Wer ist geeignet, diese Rezension(Bericht) zu lesen?
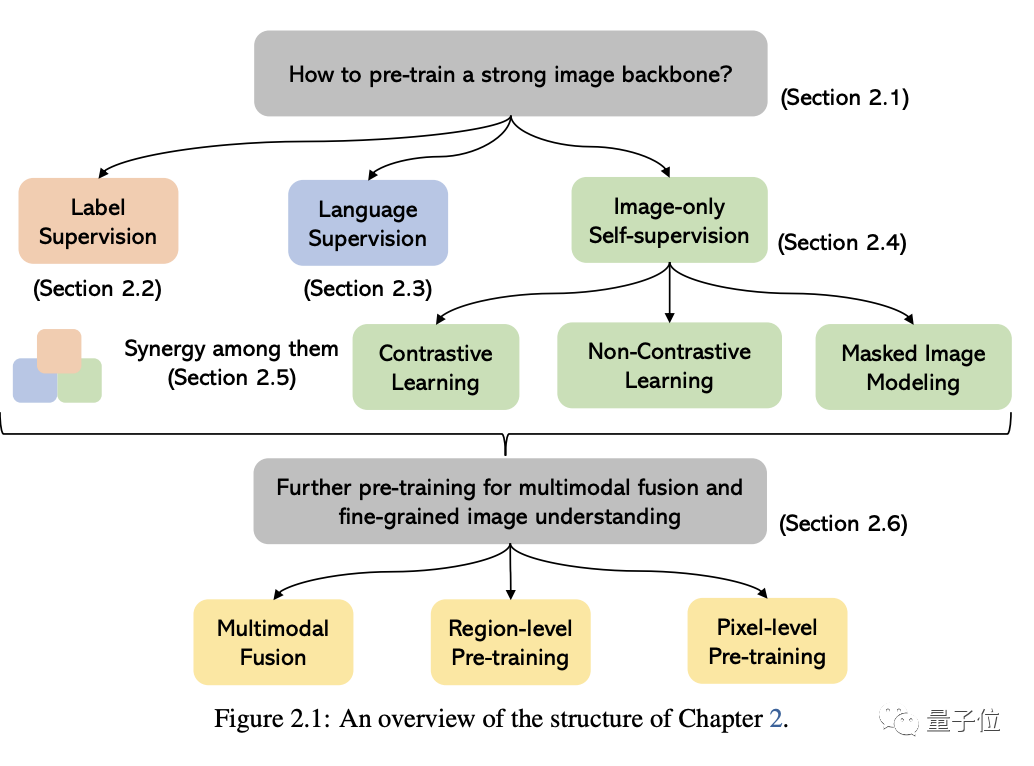
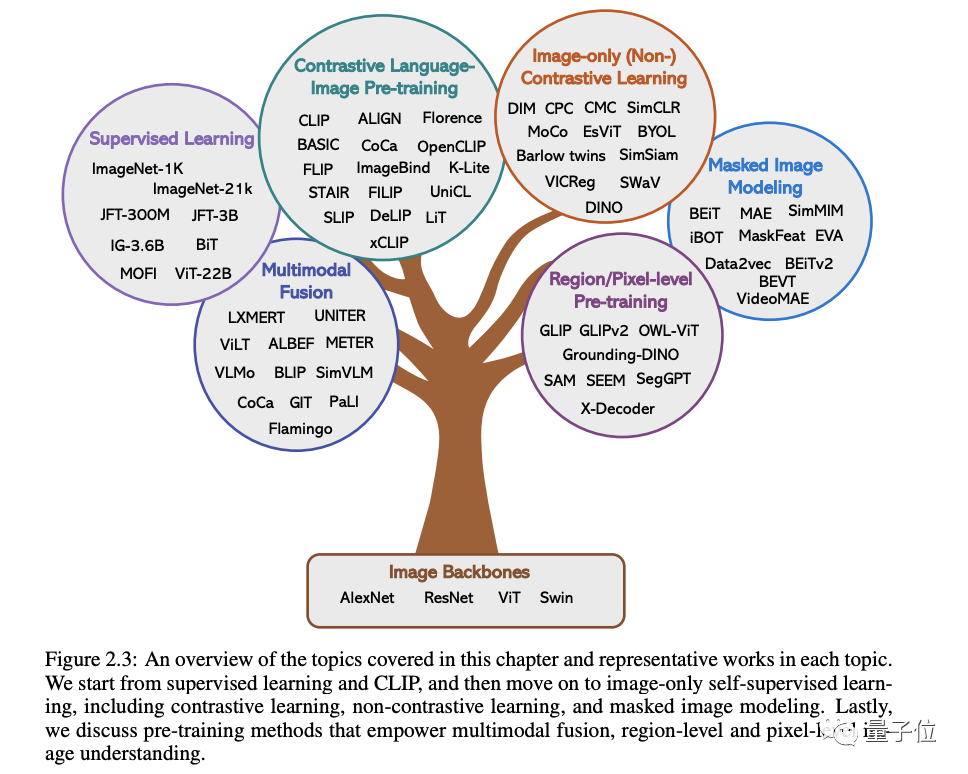
Mit den Originalworten von Microsoft: Solange Sie daran interessiert sind, das Grundwissen und die neuesten Fortschritte multimodaler Grundmodelle zu erlernen, egal ob Sie ein professioneller Forscher oder ein Student sind, ist dieser Inhalt sehr gut für Sie geeignetLassen Sie uns einen Blick darauf werfen ~Ein Artikel, um den aktuellen Status multimodaler Großmodelle herauszufindenDie ersten beiden dieser fünf spezifischen Themen sind derzeit ausgereifte Bereiche, während die letzten drei hochmoderne Bereiche sind1 . Visuelles VerständnisIn diesem Teil geht es darum, wie man ein leistungsstarkes Bildverständnis-Grundgerüst vorab trainiert. Wie in der Abbildung unten gezeigt, können wir die Methoden entsprechend den verschiedenen Überwachungssignalen, die zum Trainieren des Modells verwendet werden, in drei Kategorien einteilen:
Label-Überwachung, Sprachüberwachung
(dargestellt durch CLIP) und Nur-Bild-Selbstüberwachung .
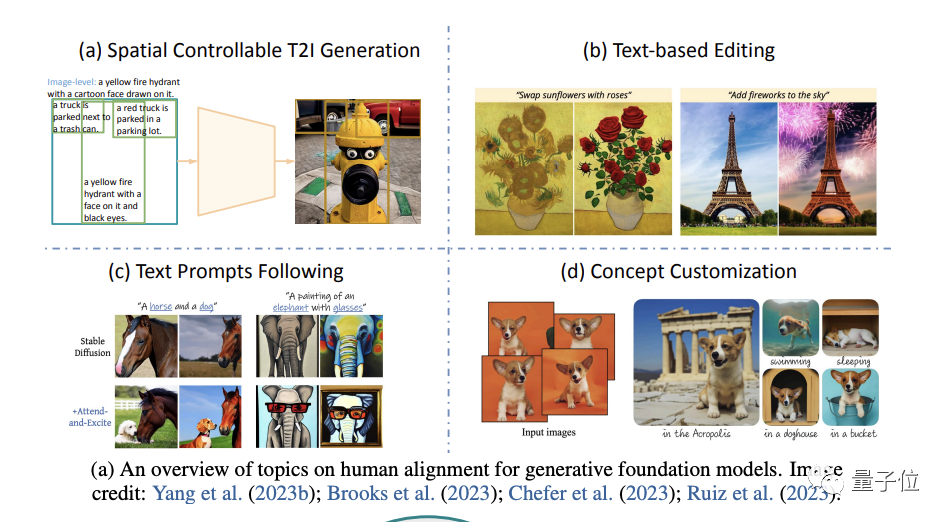
(Schwerpunkt auf der Bilderzeugung) .
Konkret geht es von vier Aspekten aus: räumlich kontrollierbare Generierung, textbasierte Nachbearbeitung, bessere Befolgung von Textaufforderungen und Anpassung des Generierungskonzepts(Konzeptanpassung).
Zum Beispiel variieren die Kosten für verschiedene Arten von Beschriftungsanmerkungen stark und die Erfassungskosten sind viel höher als die für Textdaten, was dazu führt, dass die Größe visueller Daten normalerweise viel kleiner ist als die von Textkorpora.
Trotz der vielen Herausforderungen weist der Autor jedoch darauf hin:
Der CV-Bereich ist zunehmend an der Entwicklung allgemeiner und einheitlicher Visionssysteme interessiert, und es haben sich drei Arten von Trends herauskristallisiert:
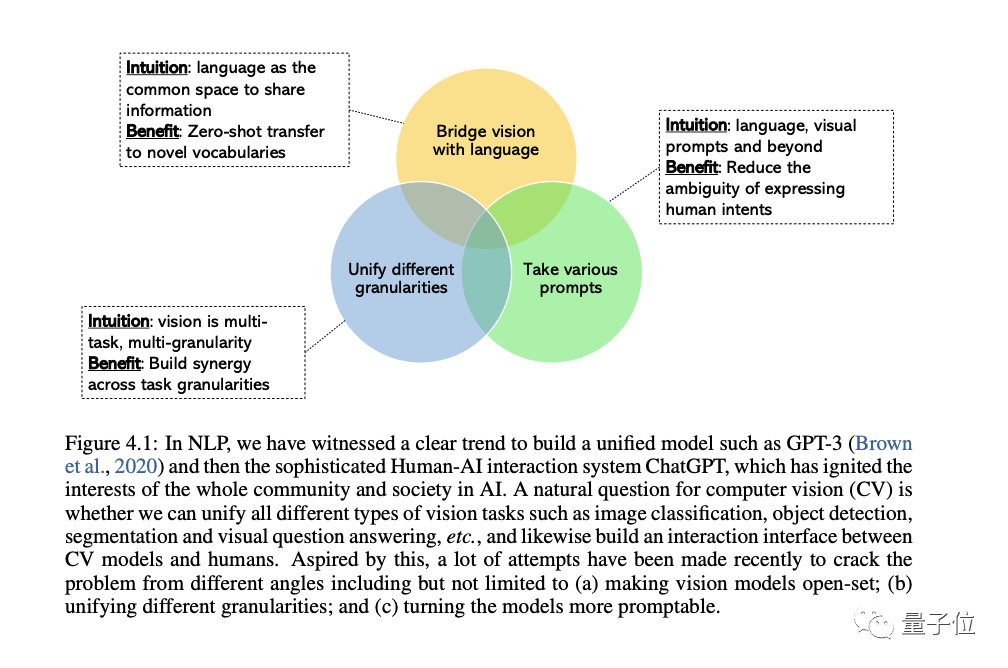
Erstens aus geschlossenen Mengen( geschlossene Menge) in offene Menge(offene Menge), wodurch Text und Bild besser zusammenpassen können.
Der wichtigste Grund für die Verlagerung von spezifischen Aufgaben zu allgemeinen Fähigkeiten besteht darin, dass die Kosten für die Entwicklung eines neuen Modells für jede neue Aufgabe zu hoch sind.
Der dritte Grund ist, dass LLM von statischen Modellen zu aufforderungsfähigen Modellen wechseln kann und verschiedene Sprachen übernehmen kann und kontextbezogene Eingabeaufforderungen als Eingabe und erzeugen die vom Benutzer gewünschte Ausgabe ohne Feinabstimmung. Das allgemeine Visionsmodell, das wir erstellen möchten, sollte über die gleichen kontextbezogenen Lernfähigkeiten verfügen.
4. Von LLM unterstützte multimodale große Modelle
In diesem Abschnitt werden multimodale große Modelle ausführlich besprochen.
Zunächst werden wir den Hintergrund und repräsentative Beispiele eingehend untersuchen, den multimodalen Forschungsfortschritt von OpenAI diskutieren und bestehende Forschungslücken in diesem Bereich identifizieren.
Als nächstes untersucht der Autor im Detail die Bedeutung der Feinabstimmung des Unterrichts in großen Sprachmodellen.
Anschließend diskutiert der Autor die Feinabstimmung von Anweisungen in multimodalen großen Modellen, einschließlich Prinzipien, Bedeutung und Anwendungen.
Abschließend werden wir für ein tieferes Verständnis auch einige fortgeschrittene Themen im Bereich multimodaler Modelle behandeln, darunter:
Mehr Modalitäten über Vision und Sprache hinaus, multimodales Kontextlernen, Parameter-effizientes Training sowie Benchmark und andere Inhalt.
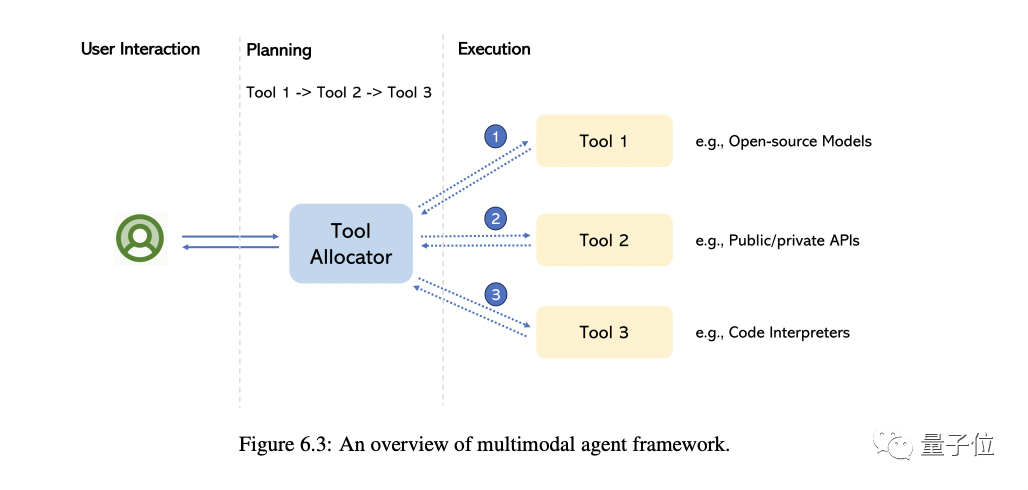
5. Multimodaler Agent
Der sogenannte Multimodal-Agent ist eine Methode, die verschiedene multimodale Experten mit LLM verbindet, um komplexe multimodale Verständnisprobleme zu lösen.
In diesem Teil führt Sie der Autor hauptsächlich zu einer Überprüfung der Transformation dieses Modells und fasst die grundlegenden Unterschiede zwischen dieser Methode und der traditionellen Methode zusammen.
Am Beispiel von MM-REACT stellen wir detailliert vor, wie diese Methode funktioniert.
Darüber hinaus fassen wir einen umfassenden Ansatz zum Aufbau multimodaler Agenten sowie die daraus entstehenden Fähigkeiten zum multimodalen Verständnis zusammen. Wir besprechen auch, wie man diese Fähigkeit einfach erweitern kann, einschließlich des neuesten und besten LLM und möglicherweise Millionen von Tools
Natürlich werden am Ende auch einige hochrangige Themen besprochen, darunter die Verbesserung/Bewertung von Multimodalitätsagenten, verschiedene daraus erstellte Anwendungen usw.
Vorstellung des Autors
Dieser Bericht enthält 7 Autoren
Initiator und Gesamtverantwortlicher ist Chunyuan Li.
Er ist leitender Forscher bei Microsoft Redmond und hat einen Doktortitel von der Duke University. Seine jüngsten Forschungsinteressen sind umfangreiche Vorschulungen in Lebenslauf und NLP.
Er war verantwortlich für die Eröffnungseinleitung und Schlusszusammenfassung sowie für das Verfassen des Kapitels „Multimodale große Modelle trainiert mit LLM“. Neu geschriebener Inhalt: Er war für das Schreiben des Anfangs und Endes des Artikels sowie des Kapitels „Mit LLM trainierte multimodale große Modelle“ verantwortlich
 ist jetzt Apple AI/ML beigetreten und für groß angelegte Vision- und multimodale Grundlagenmodellforschung verantwortlich. Zuvor war er leitender Forscher für Microsoft Azure AI. Er schloss sein Studium an der Peking University mit einem Ph.D. ab.
ist jetzt Apple AI/ML beigetreten und für groß angelegte Vision- und multimodale Grundlagenmodellforschung verantwortlich. Zuvor war er leitender Forscher für Microsoft Azure AI. Er schloss sein Studium an der Peking University mit einem Ph.D. ab.
Zhengyuan YangEr ist leitender Forscher bei Microsoft. Er schloss sein Studium an der University of Rochester ab und erhielt den ACM SIGMM Outstanding Doctoral Award und andere Auszeichnungen. Er studierte als Student an der University of Science and Technology of China
- Jianwei Yang
Principal Researcher der Deep Learning Group bei Microsoft Research Redmond. Doktortitel am Georgia Institute of Technology.
- Linjie Li
- Forscherin in der Microsoft Cloud & AI Computer Vision Group, Abschluss mit einem Master-Abschluss von der Purdue University.
Sie waren jeweils für das Schreiben der restlichen vier Themenkapitel verantwortlich.
- Bewertungsadresse: https://arxiv.org/abs/2309.10020
Das obige ist der detaillierte Inhalt vonDie umfassendste Übersicht über multimodale Großmodelle finden Sie hier! 7 Microsoft-Forscher arbeiteten intensiv zusammen, 5 Hauptthemen, 119 Seiten Dokument. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!