
Heim >Technologie-Peripheriegeräte >KI >Google DeepMind: Kombination großer Modelle mit verstärkendem Lernen, um ein intelligentes Gehirn zu schaffen, damit Roboter die Welt wahrnehmen können
Google DeepMind: Kombination großer Modelle mit verstärkendem Lernen, um ein intelligentes Gehirn zu schaffen, damit Roboter die Welt wahrnehmen können

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-09-22 09:53:141190Durchsuche
Wenn wir bei der Entwicklung von Roboterlernmethoden große und unterschiedliche Datensätze integrieren und leistungsstarke Ausdrucksmodelle (wie Transformer) verwenden können, können wir damit rechnen, Strategien zu entwickeln, die über Generalisierungsfähigkeiten verfügen und breit anwendbar sind. Roboter können lernen, mit einer Vielzahl umzugehen unterschiedlicher Aufgaben sehr gut. Diese Strategien ermöglichen es Robotern beispielsweise, Anweisungen in natürlicher Sprache zu befolgen, mehrstufige Verhaltensweisen auszuführen, sich an verschiedene Umgebungen und Ziele anzupassen und sogar auf verschiedene Roboterformen anzuwenden.
Die leistungsstarken Modelle, die kürzlich im Bereich des Roboterlernens aufgetaucht sind, werden jedoch alle mit überwachten Lernmethoden trainiert. Daher wird die Leistung der resultierenden Strategie durch das Ausmaß begrenzt, in dem menschliche Demonstratoren qualitativ hochwertige Demonstrationsdaten liefern können. Für diese Einschränkung gibt es zwei Gründe.
- Erstens wollen wir, dass Robotersysteme leistungsfähiger sind als menschliche Teleoperatoren und das volle Potenzial der Hardware ausschöpfen, um Aufgaben schnell, reibungslos und zuverlässig zu erledigen.
- Zweitens hoffen wir, dass das Robotersystem besser darin ist, Erfahrungen automatisch zu sammeln, anstatt sich ausschließlich auf qualitativ hochwertige Demonstrationen zu verlassen.
Grundsätzlich kann Reinforcement Learning diese beiden Fähigkeiten gleichzeitig vermitteln.
In letzter Zeit gab es einige vielversprechende Entwicklungen, die zeigen, dass groß angelegtes Lernen zur Verstärkung von Robotern in einer Vielzahl von Anwendungsszenarien erfolgreich sein kann, z. B. beim Greifen und Stapeln von Robotern, beim Erlernen verschiedener Aufgaben mit vom Menschen festgelegten Belohnungen und beim Lernen mehrerer -Aufgabenrichtlinien, zielbasierte Lernrichtlinien und Roboternavigation. Untersuchungen zeigen jedoch, dass es schwieriger ist, leistungsstarke Modelle wie Transformer effizient zu instanziieren, wenn Reinforcement Learning zum Trainieren leistungsstarker Modelle wie Transformer verwendet wird. Weltdaten Kombination von groß angelegtem Roboterlernen mit einer modernen politischen Architektur basierend auf leistungsstarkem Transformer

- Projekt: https://q-transformer.github.io/
- Obwohl im Prinzip die direkte Verwendung von Transformer zum Ersetzen bestehender Architekturen wie ResNets oder kleinerer Faltungen (neuronale Netze) konzeptionell einfach ist , aber es ist sehr schwierig, ein Schema zu entwerfen, das diese Architektur effektiv nutzen kann. Große Modelle können nur dann effektiv sein, wenn sie große, vielfältige Datensätze nutzen können – kleine Modelle mit engem Umfang benötigen diese Fähigkeit nicht und profitieren auch nicht davon
Obwohl frühere Forschungen Simulationsdaten verwendet haben, um solche Datensätze zu erstellen , aber die repräsentativsten Daten stammen aus der realen Welt.
Daher gab DeepMind an, dass der Schwerpunkt dieser Forschung darin liegt, Transformer durch Offline-Lernen zur Verstärkung zu nutzen und zuvor gesammelte große Datensätze zu integrieren besteht darin, die effizienteste mögliche Strategie für einen bestimmten Datensatz abzuleiten. Natürlich kann dieser Datensatz auch um zusätzliche automatisch erfasste Daten erweitert werden, der Trainingsprozess ist jedoch vom Datenerfassungsprozess getrennt, was einen zusätzlichen Workflow für groß angelegte Roboteranwendungen bietet.
Implementiert mithilfe des Transformer-Modells beim Reinforcement Learning Ein weiteres großes Problem besteht darin, ein verstärkendes Lernsystem zu entwerfen, mit dem ein solches Modell effektiv trainiert werden kann. Effektive Offline-Lernmethoden zur Verstärkung führen häufig eine Q-Funktionsschätzung über Zeitdifferenzaktualisierungen durch. Da Transformer eine diskrete Token-Sequenz modelliert, kann das Problem der Q-Funktionsschätzung in ein Modellierungsproblem für diskrete Token-Sequenzen umgewandelt werden, und für jedes Token in der Sequenz kann eine geeignete Verlustfunktion entworfen werden.
Die von DeepMind angewandte Methode ist ein Diskretisierungsschema nach Dimensionen. Dies dient dazu, die exponentielle Explosion der Aktionsbasis zu vermeiden. Insbesondere wird jede Dimension des Aktionsraums beim verstärkenden Lernen als unabhängiger Zeitschritt behandelt. Unterschiedliche Bins in der Diskretisierung entsprechen unterschiedlichen Aktionen. Dieses dimensionale Diskretisierungsschema ermöglicht es uns, eine einfache Q-Learning-Methode mit diskreten Aktionen und einem konservativen Regularisierer zu verwenden, um Verteilungstransformationssituationen zu bewältigen.
DeepMind schlägt einen speziellen Regularisierer vor, der darauf abzielt, den Wert ungenutzter Aktionen zu minimieren. Studien haben gezeigt, dass diese Methode effektiv einen schmalen Bereich Demo-ähnlicher Daten lernen kann, aber auch einen größeren Datenbereich mit Explorationsrauschen lernen kann
Schließlich verwenden sie auch einen Hybrid-Update-Mechanismus, der Monte-Carlo- und n-Schritt-Regression mit zeitlichen Differenzsicherungen kombiniert. Die Ergebnisse zeigen, dass dieser Ansatz die Leistung transformatorbasierter Offline-Lernmethoden zur Verstärkung bei großen Roboterlernproblemen verbessern kann.
Der Hauptbeitrag dieser Forschung ist Q-Transformer, eine Methode zum Offline-Lernen von Robotern basierend auf der Transformer-Architektur. Q-Transformer tokenisiert Q-Werte nach Dimensionen und wurde erfolgreich auf große und vielfältige Robotik-Datensätze, einschließlich realer Daten, angewendet. Abbildung 1 zeigt die Komponenten von Q-Transformer

DeepMind führte experimentelle Auswertungen durch, darunter Simulationsexperimente und groß angelegte Experimente in der realen Welt, mit dem Ziel eines strengen Vergleichs und einer praktischen Verifizierung. Darunter haben wir eine groß angelegte textbasierte Multitasking-Strategie zum Lernen übernommen und die Wirksamkeit von Q-Transformer überprüft
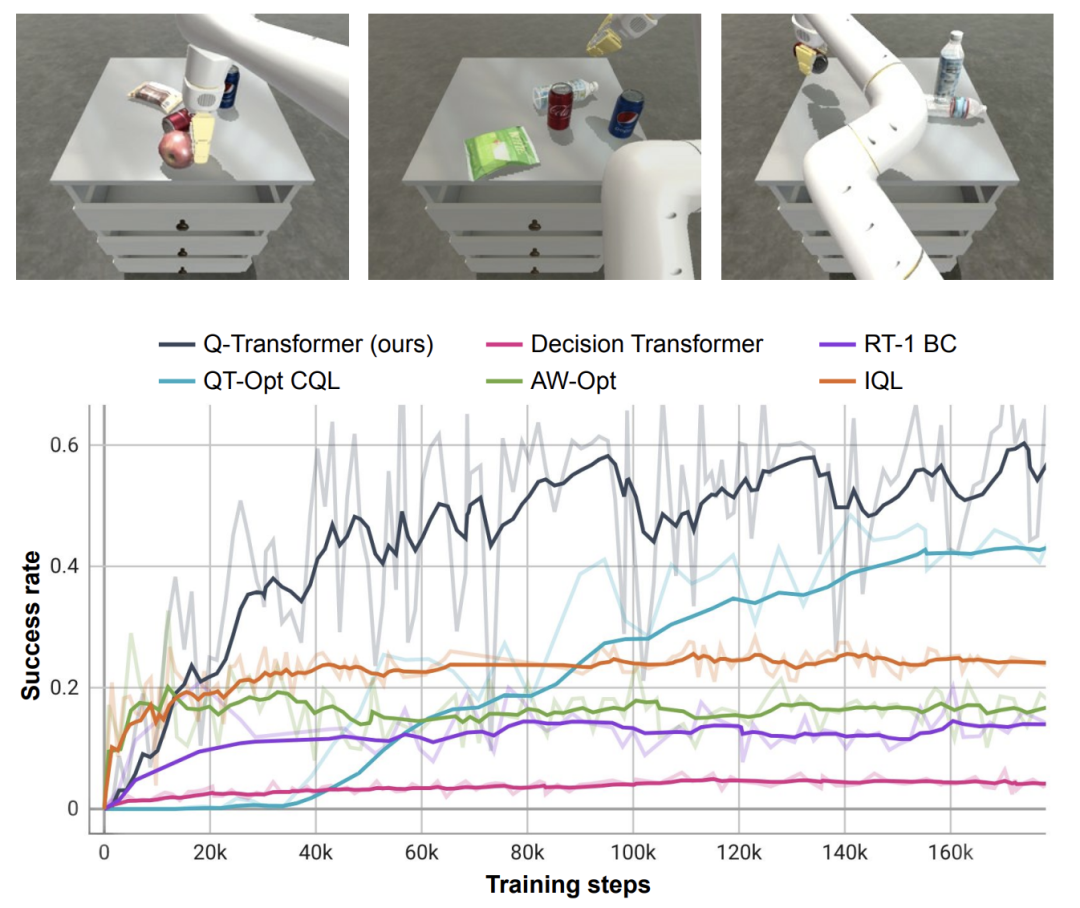
In realen Experimenten enthielt der von ihnen verwendete Datensatz 38.000 erfolgreiche Demonstrationen und 20.000 Ein Szenario von Die automatische Erfassung ist fehlgeschlagen. Die Daten wurden von 13 Robotern bei mehr als 700 Aufgaben erfasst. Q-Transformer übertrifft zuvor vorgeschlagene Architekturen für umfangreiches robotergestütztes Verstärkungslernen sowie Transformer-basierte Modelle wie den zuvor vorgeschlagenen Decision Transformer.
Übersicht der Methoden
Um Transformer für Q-Learning zu nutzen, besteht der Ansatz von DeepMind darin, den Aktionsraum zu diskretisieren und autoregressiv zu verarbeiten.
Um eine Q-Funktion mithilfe von TD-Learning zu lernen, basiert die klassische Methode zur Bell-Mann-Aktualisierungsregel
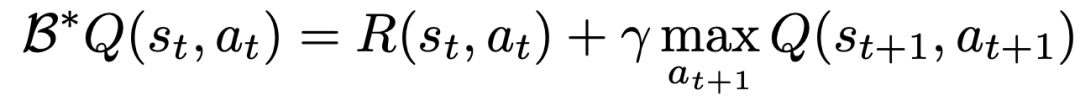
Die Forscher haben das Bellman-Update so modifiziert, dass es für jede Aktionsdimension durchgeführt werden kann, indem sie den ursprünglichen MDP des Problems in jede als Q behandelte Aktionsdimension umwandeln. Lernen Sie eine Schritt-für-Schritt-Anleitung -Schritt-MDP.
Konkret kann die neue Bellman-Aktualisierungsregel für eine gegebene Aktionsdimension d_A wie folgt ausgedrückt werden:
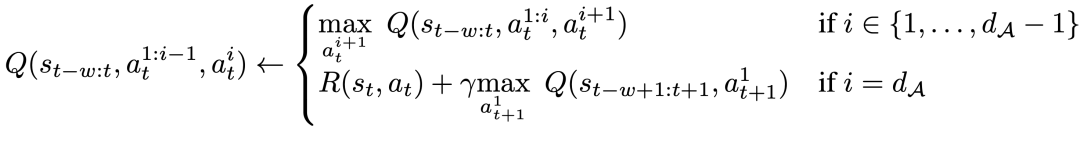
Dies bedeutet, dass für jede dazwischenliegende Aktionsdimension bei gleichen Bedingungen Folgendes gilt: Maximieren Sie die nächste Aktionsdimension und verwenden Sie für die letzte Aktionsdimension die erste Aktionsdimension des nächsten Zustands. Durch diese Zerlegung wird sichergestellt, dass die Maximierung im Bellman-Update nachvollziehbar bleibt und gleichzeitig sichergestellt wird, dass das ursprüngliche MDP-Problem weiterhin gelöst werden kann.
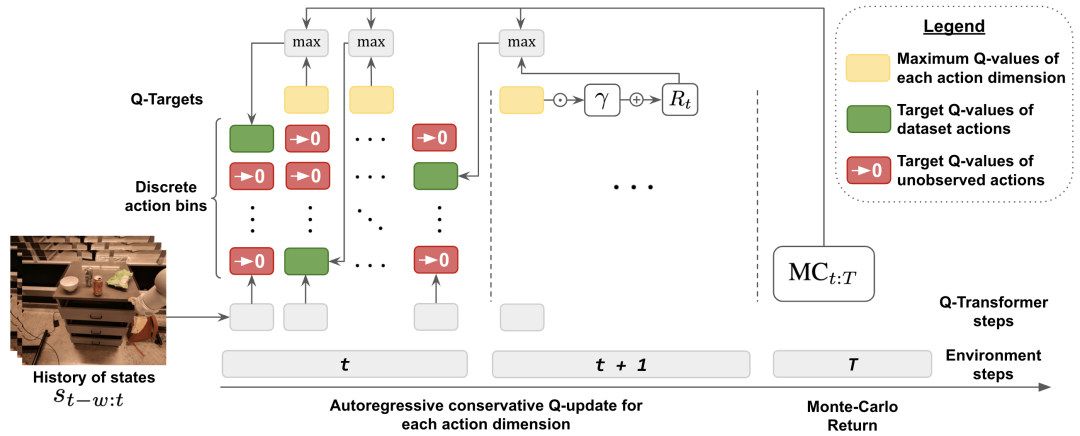
Um Verteilungsänderungen beim Offline-Lernen zu berücksichtigen, führt DeepMind außerdem eine einfache Regularisierungstechnik ein, die den Wert unsichtbarer Aktionen minimiert.
Um das Lernen zu beschleunigen, verwendeten sie auch die Monte-Carlo-Rückgabemethode. Dieser Ansatz verwendet nicht nur Return-to-Go für eine bestimmte Episode (Episode), sondern auch N-Schritt-Returns, die dimensional maximiert werden können eine Reihe realer Aufgaben. Gleichzeitig beschränkten sie die Daten auf nur 100 menschliche Demos pro Aufgabe
In den Demos fügten sie zusätzlich zu den Demos auch automatisch gesammelte Fehlerereignis-Snippets hinzu, um einen Datensatz zu erstellen. Dieser Datensatz enthält 38.000 positive Beispiele aus der Demo und 20.000 automatisch gesammelte negative Beispiele
Im Vergleich zu Basismethoden wie RT-1, IQL und Decision Transformer (DT) kann Q-Transformer automatische Ereignisfragmente effektiv nutzen, um seine Fähigkeit, Fertigkeiten einzusetzen, einschließlich des Aufnehmens und Platzierens von Gegenständen aus Schubladen sowie des Bewegens von Gegenständen in die Nähe, deutlich zu verbessern Ziele, Schubladen öffnen und schließen.
Die Forscher testeten die neu vorgeschlagene Methode auch an einer schwierigen simulierten Objektabrufaufgabe – bei dieser Aufgabe waren nur etwa 8 % der Daten positive Beispiele und der Rest waren negative Beispiele voller Rauschbeispiele.
Bei dieser Aufgabe schneiden Q-Learning-Methoden wie QT-Opt, IQL, AW-Opt und Q-Transformer in der Regel besser ab, da sie dynamische Programmierung nutzen können, um Richtlinien zu lernen und Negativbeispiele zur Optimierung zu nutzen
Basierend auf dieser Objektabrufaufgabe führten die Forscher Ablationsexperimente durch und stellten fest, dass sowohl der konservative Regularisierer als auch die MC-Rückkehr wichtig sind, um die Leistung aufrechtzuerhalten. Deutlich schlechter wird die Performance, wenn man auf den Softmax-Regularizer umsteigt, da dieser die Policy zu sehr auf die Datenverteilung einschränkt. Dies zeigt, dass der hier von DeepMind ausgewählte Regularisierer diese Aufgabe besser bewältigen kann.
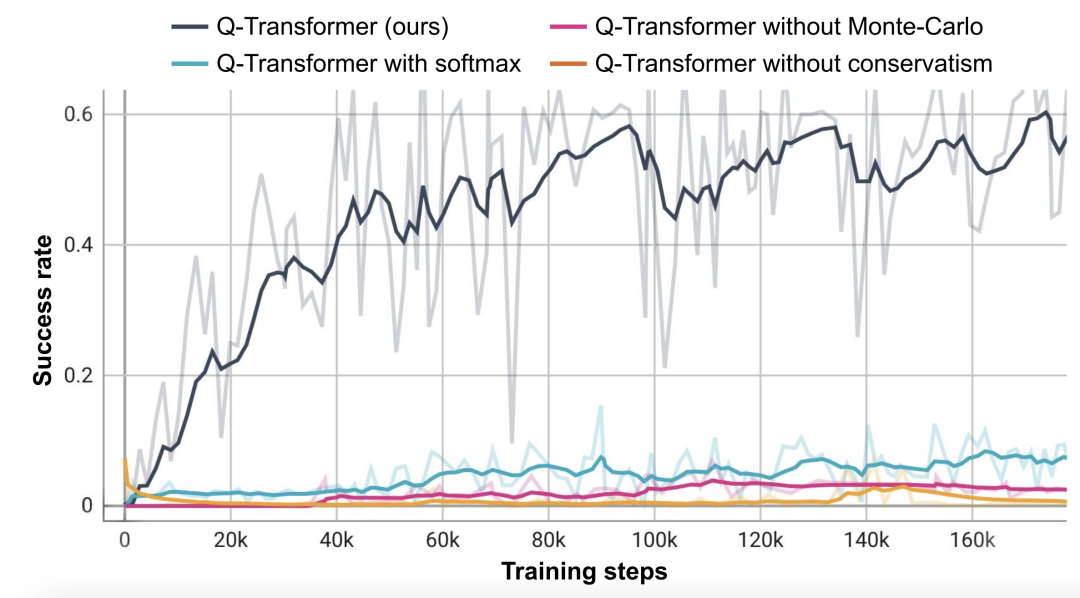
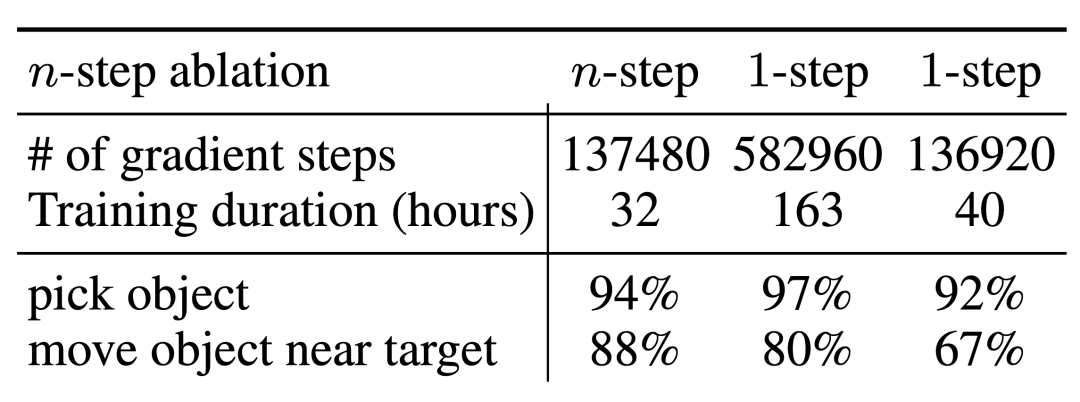
Ihre Ablationsexperimente für n-stufige Renditen ergaben, dass diese Methode zwar zu einer Verzerrung führen kann, diese Methode jedoch in deutlich weniger Gradientenschritten eine gleich hohe Leistung erzielen und so viele Probleme effektiv lösen kann
Die Forscher haben auch versucht, Q-Transformer für größere Datensätze auszuführen. Sie erweiterten die Anzahl der positiven Beispiele auf 115.000 und die Anzahl der negativen Beispiele auf 185.000, was zu einem Datensatz mit 300.000 Ereignisclips führte. Mithilfe dieses großen Datensatzes konnte Q-Transformer immer noch lernen und eine noch bessere Leistung erbringen als der RT-1 BC-Benchmark. kombiniert mit einem Sprachplaner, ähnlich wie SayCan

Q-Transformer Der Effekt der Erschwinglichkeitsschätzung ist auf die zuvor mit QT-Opt trainierte Q-Funktion zurückzuführen. Wenn sie nicht mehr abgetastet wird, wird die Aufgabe erneut durchgeführt. Während des Trainings als negatives Beispiel für die aktuelle Aufgabe gekennzeichnet, kann die Wirkung sogar noch besser sein. Da für Q-Transformer nicht das beim QT-Opt-Training verwendete Sim-to-Real-Training erforderlich ist, ist es einfacher, Q-Transformer zu verwenden, wenn eine geeignete Simulation fehlt.
Um das komplette „Planung + Ausführung“-System zu testen, experimentierten sie mit der Verwendung von Q-Transformer für die gleichzeitige Kostenschätzung und tatsächliche Richtlinienausführung, und die Ergebnisse zeigten, dass es die vorherige Kombination von QT-Opt und RT-1 übertraf. 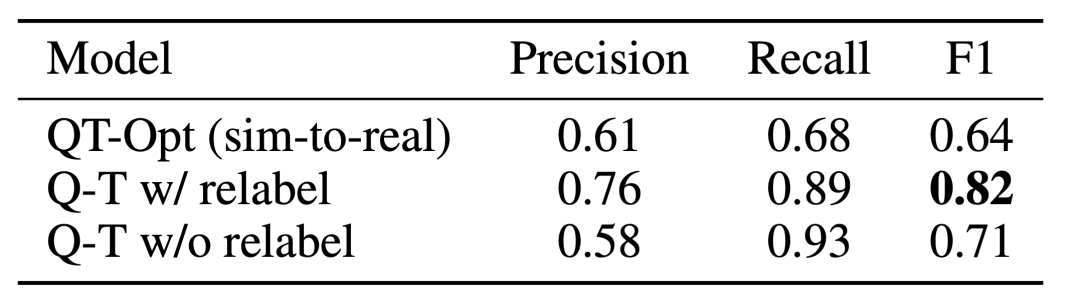
Wie aus dem Aufgaben-Affordance-Wert-Beispiel des gegebenen Bildes ersichtlich ist, kann Q-Transformer qualitativ hochwertige Affordance-Werte im nachgelagerten „Planung + Ausführung“-Framework bereitstellen
Bitte Weitere Informationen finden Sie im Originalartikel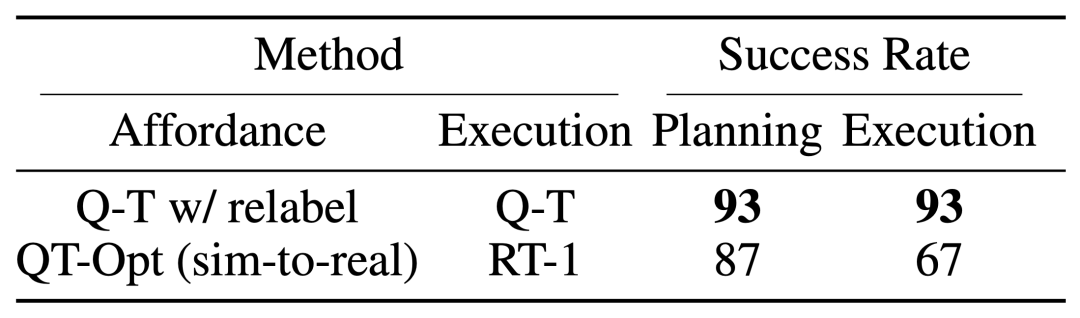
Das obige ist der detaillierte Inhalt vonGoogle DeepMind: Kombination großer Modelle mit verstärkendem Lernen, um ein intelligentes Gehirn zu schaffen, damit Roboter die Welt wahrnehmen können. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!