
Heim >Technologie-Peripheriegeräte >KI >Wie überholt DSA die NVIDIA-GPU in einer Kurve?
Wie überholt DSA die NVIDIA-GPU in einer Kurve?

- 王林nach vorne
- 2023-09-20 18:09:091779Durchsuche
Vielleicht haben Sie die folgenden scharfen Meinungen gehört:
1 Wenn Sie dem technischen Weg von NVIDIA folgen, werden Sie möglicherweise nie mit NVIDIA mithalten können.
2. DSA hat vielleicht eine Chance, zu NVIDIA aufzuschließen, aber die aktuelle Situation ist, dass DSA vom Aussterben bedroht ist und es keine Hoffnung in Sicht ist.
Andererseits wissen wir alle, dass es große Modelle jetzt sind Im Vordergrund stehen viele Leute in der Branche, die Chips für große Modelle herstellen wollen. Es gibt auch viele Leute, die in Chips für große Modelle investieren möchten.
Aber was ist der Schlüssel zum Design großer Modellchips? Jeder scheint zu wissen, wie wichtig große Bandbreite und großer Speicher sind, aber wie unterscheidet sich der Chip von NVIDIA?
Bei Fragen versucht dieser Artikel, Ihnen Inspiration zu geben.
Artikel, die rein auf Meinungen basieren, wirken oft formalistisch. Wir können dies anhand eines Architekturbeispiels veranschaulichen.
SambaNova Systems gilt als eines der Top-Ten-Einhornunternehmen in den Vereinigten Staaten. Im April 2021 erhielt das Unternehmen eine von SoftBank angeführte Serie-D-Investition in Höhe von 678 Millionen US-Dollar mit einer Bewertung von 5 Milliarden US-Dollar, was es zu einem Super-Einhorn-Unternehmen macht. Zu den Investoren von SambaNova gehörten zuvor die weltweit führenden Risikokapitalfonds wie Google Ventures, Intel Capital, SK und Samsung Catalytic Fund. Welche disruptiven Dinge tut dieses Super-Einhorn-Unternehmen, das die Gunst der weltweit führenden Investmentinstitute auf sich gezogen hat? Wenn wir uns ihre frühen Werbematerialien ansehen, können wir feststellen, dass SambaNova einen anderen Entwicklungspfad als der KI-Gigant NVIDIA gewählt hat. Ist das nicht ein bisschen schockierend? Ein 1024 V100-Cluster, der mit beispielloser Leistung auf der NVIDIA-Plattform aufgebaut ist, entspricht tatsächlich einer einzelnen Maschine von SambaNova? ! Dies ist das Produkt der ersten Generation, ein eigenständiger 8-Karten-Automat auf Basis von SN10 RDU.
Manche Leute mögen sagen, dass dieser Vergleich nicht fair ist. Hat NVIDIA das nicht selbst erkannt? Mit einer Leistung von 5 PetaFLOPS verfügt SambaNovas DataScale der zweiten Generation ebenfalls über eine Rechenleistung von 5 PetaFLOPS. Speichervergleich von 320 GB HBM vs. 8 TB DDR4 (der Herausgeber vermutet, dass er den Artikel möglicherweise falsch geschrieben hat, es sollten 3 TB * 8 sein). 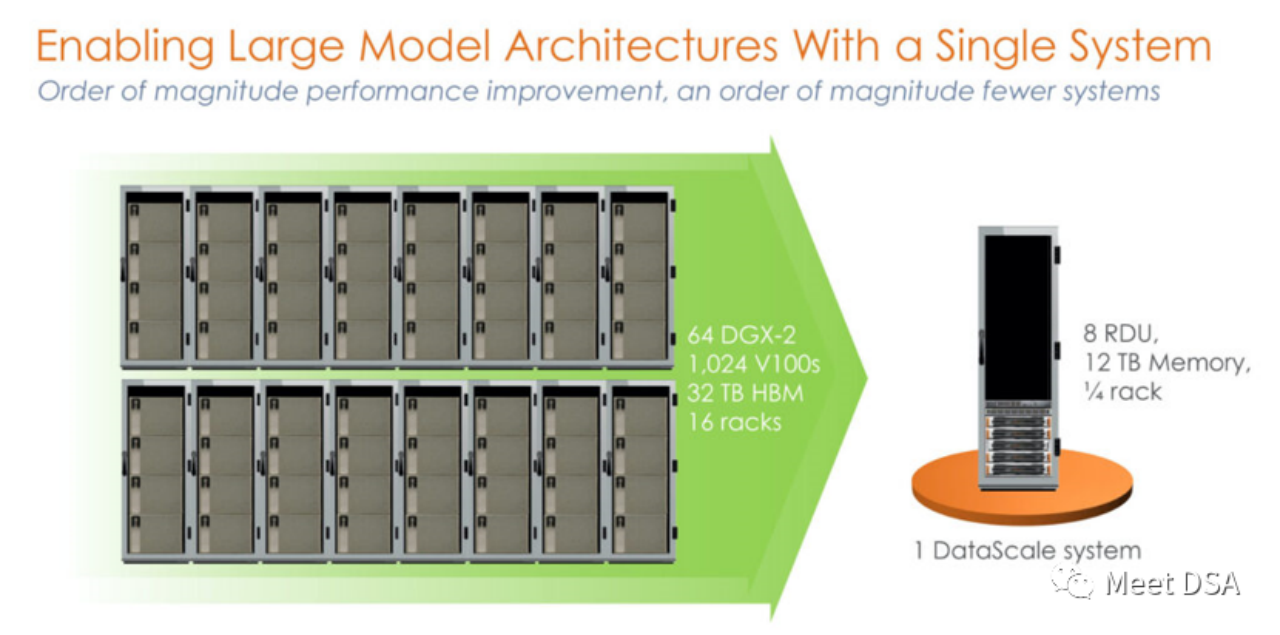
Schlüssel Extrahierte Punkte :
:
Wenn Sie auf DGX H100 umsteigen, können Sie den Abstand nur verringern, selbst wenn Sie auf Technologien mit geringer Präzision wie FP8 umsteigen.
„Und selbst wenn der DGX-H100 bei 16-Bit-Gleitkommaberechnung die dreifache Leistung bietet als der DGX-A100, wird er die Lücke zum SambaNova-System nicht schließen. Bei FP8-Daten mit geringerer Präzision könnte dies jedoch der Fall sein.“ Wir können die Leistungslücke schließen. Es ist unklar, wie viel Präzision durch die Umstellung auf Daten und Verarbeitung mit geringerer Präzision verloren geht.“
Wenn jemand einen solchen Effekt erzielen könnte, wäre das nicht eine perfekte Lösung mit großen Chips? Und es kann sich auch direkt mit der Konkurrenz von NVIDIA messen! (Vielleicht werden Sie sagen, dass die Grace-CPU auch an LPDDR angeschlossen werden kann, was zur Kapazitätserhöhung hilfreich ist. Wie sieht andererseits SambaNova diese Angelegenheit: Grace ist nur ein großer Speichercontroller, der aber nur 512 GB bringen kann zu Hopper. Und ein SN30 hat 3 TB DRAM. Wir haben immer gescherzt, dass Nvidias „Grace“-Arm-CPU nur ein überbewerteter Speichercontroller für die Hopper-GPU war, und in vielen Fällen war es wirklich nur ein Speichercontroller. Und die Hopper-GPU in jedem Grace-Hopper-Superchip-Paket verfügt nur über maximal 512 GB Speicher. Das ist immer noch viel weniger als die 3 TB Speicher, die SambaNova bietet. Die Geschichte lehrt uns, dass selbst das wohlhabendste Imperium dies tun muss Vorsicht. Dieser unauffällige Riss
Xia He, der Meister von Huawei, spekulierte kürzlich, dass eine Schwäche des NVIDIA-Imperiums aus Kostensicht in den Kosten pro GB liegen könnte. Er schlug eine verrückte Stapelung von billigem DDR-Speicher für große interne Eingaben/Ausgaben vor könnte einen revolutionären Einfluss auf NVIDIA haben $/GBps (Datenbewegung) ist HBM kostengünstiger, da LLM zwar einen relativ großen Bedarf an Speicherkapazität hat, aber auch einen großen Bedarf an Speicherbandbreite hat. Das Training erfordert eine große Anzahl von Parametern, die im DRAM ausgetauscht werden müssen .
(Erweiterung: https://www.php.cn/link/a56ee48e5c142c26cf645b2cc23d78fc)
Nach dem Architekturbeispiel von SambaNova zu urteilen, kann ein preisgünstiges DDR mit großer Kapazität das Problem von LLM lösen, was dies bestätigt Das Urteil von Xia Core!Aber aus Sicht von Mackler ist auch der Bedarf an enormer Bandbreite für die Datenmigration ein Problem. Wie löst SambaNova dieses Problem? Sie müssen die Merkmale der RDU-Architektur besser verstehen. Tatsächlich ist es leicht zu verstehen:
A ist das Paradigma des Datenaustauschs in der traditionellen GPU-Architektur. Dieser Hin- und Her-Austausch sollte leichter zu verstehen sein, da er eine große Menge an DDR-Bandbreite beansprucht. B ist das, was die Architektur von SambaNova erreichen kann. Während des Modellberechnungsprozesses bleibt ein großer Teil der Datenbewegung auf dem Chip und es besteht keine Notwendigkeit, zum Austausch hin und her zum DRAM zu gehen.
DaherWenn Sie den Effekt wie B erzielen können, das Problem der Wahl zwischen großer Bandbreite und großer Kapazität, können Sie sicher eine große Kapazität wählen
. So heißt es in der folgenden Passage: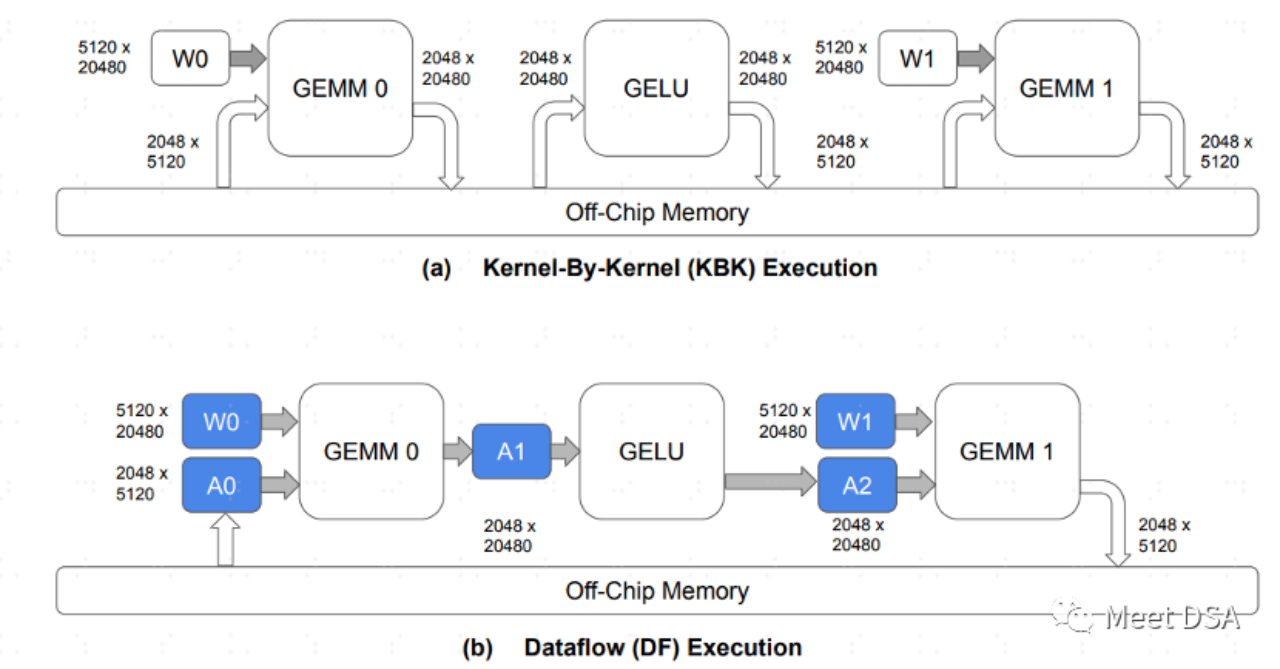 „Die Frage, die wir haben, ist diese: Was ist bei einer hybriden Speicherarchitektur, die Basismodelle unterstützt, wichtiger? Speicherkapazität oder Speicherbandbreite. Sie können nicht beides auf einer einzigen Speichertechnologie haben.“ Jede Architektur, und selbst wenn Sie eine Mischung aus schnellen und dünnen und langsamen und fetten Speichern haben, sind Nvidia und SambaNova unterschiedlich. Allerdings ist es möglicherweise nicht möglich, der GPGPU-Strategie von NVIDIA zu folgen. Es scheint, dass die richtige Idee für große Chips darin besteht, kostengünstigeres DRAM zu verwenden. Bei gleichen Rechenleistungsspezifikationen kann die Leistung mehr als das Sechsfache von NVIDIA erreichen!
„Die Frage, die wir haben, ist diese: Was ist bei einer hybriden Speicherarchitektur, die Basismodelle unterstützt, wichtiger? Speicherkapazität oder Speicherbandbreite. Sie können nicht beides auf einer einzigen Speichertechnologie haben.“ Jede Architektur, und selbst wenn Sie eine Mischung aus schnellen und dünnen und langsamen und fetten Speichern haben, sind Nvidia und SambaNova unterschiedlich. Allerdings ist es möglicherweise nicht möglich, der GPGPU-Strategie von NVIDIA zu folgen. Es scheint, dass die richtige Idee für große Chips darin besteht, kostengünstigeres DRAM zu verwenden. Bei gleichen Rechenleistungsspezifikationen kann die Leistung mehr als das Sechsfache von NVIDIA erreichen!
[2]https://www.nextplatform.com/2022/09/17/sambanova-doubles-up-chips-to-chase -ai-foundation-models/
[3]https://hc33.hotchips.org/assets/program/conference/day2/SambaNova%20HotChips%202021%20Aug%2023%20v1.pdf
[ 4] 《Schulung Großsprachmodelle effizient mit Sparsity und DataFlow》[5] https://www.php.cn/link/617974172720b96de92525536de581fa
der Inhalt, der neu geschrieben werden muss, ist: [6] Https https ist: [6] https ist: [6] https ist: [6] https ist: [6] https ist: [6] https ist: [6] https ist: [6] https ist: [6] http ://www.php.cn/link/a56ee48e5c142c26cf645b2cc23d78fc
Das obige ist der detaillierte Inhalt vonWie überholt DSA die NVIDIA-GPU in einer Kurve?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Die Xiamen Yuanverse Industry Expo wird eröffnet, um die innovativen Errungenschaften von Yuanverse zu präsentieren
- Mit dem „Exhibition Express' erkundet der Qingdao Artificial Intelligence Industrial Park neue Wege, um Investitionen anzuziehen
- Ronglian Cloud wurde in die Global Generative AI Industry Map 2023 aufgenommen
- Die Nachfrage nach KI-Rechenleistung ist stark gestiegen, und Shanghai Lingang wird eine Rechenleistungsindustrie im zweistelligen Milliardenbereich aufbauen
- Untersuchung der Anwendung der Go-Sprache in der Smart-Car-Branche