
Heim >Technologie-Peripheriegeräte >KI >Die Taotian Group und Aicheng Technology arbeiten zusammen, um das Open-Source-Modell-Trainingsframework Megatron-LLaMA zu veröffentlichen
Die Taotian Group und Aicheng Technology arbeiten zusammen, um das Open-Source-Modell-Trainingsframework Megatron-LLaMA zu veröffentlichen

- 王林nach vorne
- 2023-09-19 19:05:07675Durchsuche
Am 12. September haben die Taotian Group und Aicheng Technology das Trainings-Framework für große Modelle – Megatron-LLaMA – offiziell als Open-Source-Lösung bereitgestellt. Ziel ist es, Technologieentwicklern die Möglichkeit zu geben, die Trainingsleistung großer Sprachmodelle bequemer zu verbessern, die Trainingskosten zu senken und die Kompatibilität mit LLaMA aufrechtzuerhalten Gemeinschaft. Tests zeigen, dass Megatron-LLaMA im Vergleich zur direkt von HuggingFace erhaltenen Codeversion eine Beschleunigung von 176 % erreichen kann. Im Vergleich zu 32 Karten weist Megatron-LLaMA eine nahezu lineare Skalierbarkeit auf für Netzwerkinstabilität. Derzeit ist Megatron-LLaMA in der Open-Source-Community online.
Open-Source-Adresse: https://github.com/alibaba/Megatron-LLaMA
Im 32-Karten-Training kann Megatron-LLaMA im Vergleich zur direkt von HuggingFace erhaltenen Codeversion eine Beschleunigung von 176 % erreichen; selbst mit der durch DeepSpeed und FlashAttention optimierten Version kann Megatron-LLaMA immer noch eine Beschleunigung erzielen erreichen Reduzieren Sie die Schulungszeit um mindestens 19 %. - Im groß angelegten Training verfügt Megatron-LLaMA im Vergleich zu 32 Karten über eine
nahezu lineare Skalierbarkeit. Wenn beispielsweise 512 A100 zur Reproduktion des Trainings von LLaMA-13B verwendet wird, kann der umgekehrte Mechanismus von Megatron-LLaMA im Vergleich zum DistributedOptimizer des nativen Megatron-LM mindestens zwei Tage einsparen, ohne dass es zu Genauigkeitsverlusten kommt. - Megatron-LLaMA weist eine hohe Toleranz gegenüber Netzwerkinstabilität auf. Selbst auf dem aktuellen kostengünstigen 8xA100-80GB-Trainingscluster mit 4x200 Gbit/s Kommunikationsbandbreite (diese Umgebung ist normalerweise eine gemischte Bereitstellungsumgebung, das Netzwerk kann nur die Hälfte der Bandbreite nutzen, die Netzwerkbandbreite stellt einen ernsthaften Engpass dar, aber der Mietpreis ist relativ niedrig) kann Megatron-LLaMA immer noch eine lineare Expansionsfähigkeit von 0,85 erreichen, Megatron-LM kann bei diesem Indikator jedoch nur weniger als 0,7 erreichen. -MEGATRON-LM-Technologie bietet leistungsstarke LLAMA-Trainingsmöglichkeiten
Lama ist eine wichtige Aufgabe in der Open-Source-Community des großen Sprachmodells. LLaMA führt Optimierungstechnologien wie BPE-Zeichenkodierung, RoPE-Positionskodierung, SwiGLU-Aktivierungsfunktion, RMSNorm-Regularisierung und Untied Embedding in die Struktur von LLM ein und hat in vielen objektiven und subjektiven Bewertungen hervorragende Ergebnisse erzielt. LLaMA bietet die Versionen 7B, 13B, 30B, 65B/70B, die für verschiedene Szenarien geeignet sind, die große Modelle erfordern, und auch von Entwicklern bevorzugt werden. Da der Beamte wie bei vielen großen Open-Source-Modellen nur die Inferenzversion des Codes bereitstellt, gibt es kein Standardparadigma für die Durchführung eines effizienten Trainings zu den niedrigsten Kosten. Megatron-LM ist eine elegante Hochleistungs-Trainingslösung.Megatron-LM bietet Tensorparallelität (Tensor Parallel, TP, das große Multiplikationen mehreren Karten für paralleles Rechnen zuweist), Pipeline-Parallelität (Pipeline Parallel, PP, das verschiedene Schichten des Modells verschiedenen Karten zur Verarbeitung zuweist) und Sequenzparallelität ( Sequenzparallel, SP, verschiedene Teile der Sequenz werden von verschiedenen Karten verarbeitet, wodurch Videospeicher gespart wird), DistributedOptimizer-Optimierung (ähnlich wie DeepSpeed Zero Stage-2, Aufteilung von Gradienten- und Optimierungsparametern auf alle Rechenknoten) und andere Technologien können dies erheblich reduzieren Reduzieren Sie die Videospeichernutzung und verbessern Sie die GPU-Auslastung. Megatron-LM betreibt eine aktive Open-Source-Community und neue Optimierungstechnologien und funktionale Designs werden weiterhin in das Framework integriert.Allerdings ist die Entwicklung auf Basis von Megatron-LM nicht einfach, und das Debuggen und die Funktionsüberprüfung auf teuren Multi-Card-Maschinen ist noch teurer. Megatron-LLaMA stellt zunächst eine Reihe von LLaMA-Trainingscodes bereit, die auf dem Megatron-LM-Framework basieren, unterstützt Modellversionen verschiedener Größen und kann leicht angepasst werden, um verschiedene Varianten von LLaMA zu unterstützen, einschließlich der direkten Unterstützung für den Tokenizer im HuggingFace-Format. Daher kann Megatron-LLaMA ohne übermäßige Anpassung problemlos auf bestehende Offline-Trainingsverbindungen angewendet werden. In kleinen und mittelgroßen Trainings-/Feinabstimmungsszenarien für LLaMA-7b und LLaMA-13b kann Megatron-LLaMA problemlos eine branchenführende Hardwareauslastung (MFU) von 54 % und mehr erreichen.
Umkehrprozessoptimierung von Megatron-Llama Reverse-Prozessoptimierung Deepspeed Zero ist eine Reihe verteilter Trainingsrahmen, die von Microsoft gestartet wurden. Wirkung erzielen. DeepSpeed ZeRO Stage-2 (im Folgenden als ZeRO-2 bezeichnet) ist eine Technologie im Framework, die Speicherverbrauch spart, ohne zusätzlichen Rechen- und Kommunikationsaufwand hinzuzufügen. Wie in der Abbildung oben gezeigt, muss jeder Rang aufgrund der Berechnungsanforderungen über alle Parameter verfügen. Für den Optimiererstatus ist jedoch jeder Rang nur für einen Teil davon verantwortlich, und es ist nicht erforderlich, dass alle Ränge vollständig wiederholte Vorgänge gleichzeitig ausführen. Daher schlägt ZeRO-2 vor, den Optimiererstatus gleichmäßig auf jeden Rang aufzuteilen (beachten Sie, dass nicht sichergestellt werden muss, dass jede Variable gleichmäßig aufgeteilt ist oder in einem bestimmten Rang vollständig erhalten bleibt. Jeder Rang muss nur während des Trainingsprozesses verwendet werden). Verantwortlich für die Aktualisierung des Optimiererstatus und der Modellparameter des entsprechenden Teils. In dieser Einstellung können auch Farbverläufe auf diese Weise aufgeteilt werden. Standardmäßig verwendet ZeRO-2 die Reduce-Methode, um Gradienten zwischen allen Ranks in umgekehrter Reihenfolge zu aggregieren, und dann muss jeder Rank nur den Teil der Parameter behalten, für den er verantwortlich ist, was nicht nur redundante wiederholte Berechnungen eliminiert, sondern auch den Speicher reduziert Verwendung. Megatron-lm verteiltoptimizer Wie in der Abbildung oben gezeigt, verwendet DistributedOptimizer den ReduceScatter-Operator, um alle zuvor akkumulierten Farbverläufe auf verschiedene Ränge zu verteilen, nachdem alle durch den voreingestellten Farbverlauf aggregierten Farbverläufe erhalten wurden. Jeder Rang erhält nur einen Teil des Gradienten, den er verarbeiten muss, und aktualisiert dann den Optimiererstatus und die entsprechenden Parameter. Schließlich erhält jeder Rang über AllGather aktualisierte Parameter von anderen Knoten und erhält schließlich alle Parameter. Die tatsächlichen Trainingsergebnisse zeigen, dass die Gradienten- und Parameterkommunikation von Megatron-LM in Reihe mit anderen Berechnungen durchgeführt wird. Bei umfangreichen Vortrainingsaufgaben ist dies normalerweise nicht möglich, um sicherzustellen, dass die Gesamtstapeldatengröße unverändert bleibt Öffnen Sie eine größere GA. Daher wird der Anteil der Kommunikation mit der Zunahme der Maschinen zunehmen. Derzeit führen die Eigenschaften der seriellen Kommunikation zu einer sehr schwachen Skalierbarkeit. Auch innerhalb der Gemeinschaft ist der Bedarf akut.
Deepspeed Zero ist eine Reihe verteilter Trainingsrahmen, die von Microsoft gestartet wurden. Wirkung erzielen. DeepSpeed ZeRO Stage-2 (im Folgenden als ZeRO-2 bezeichnet) ist eine Technologie im Framework, die Speicherverbrauch spart, ohne zusätzlichen Rechen- und Kommunikationsaufwand hinzuzufügen. Wie in der Abbildung oben gezeigt, muss jeder Rang aufgrund der Berechnungsanforderungen über alle Parameter verfügen. Für den Optimiererstatus ist jedoch jeder Rang nur für einen Teil davon verantwortlich, und es ist nicht erforderlich, dass alle Ränge vollständig wiederholte Vorgänge gleichzeitig ausführen. Daher schlägt ZeRO-2 vor, den Optimiererstatus gleichmäßig auf jeden Rang aufzuteilen (beachten Sie, dass nicht sichergestellt werden muss, dass jede Variable gleichmäßig aufgeteilt ist oder in einem bestimmten Rang vollständig erhalten bleibt. Jeder Rang muss nur während des Trainingsprozesses verwendet werden). Verantwortlich für die Aktualisierung des Optimiererstatus und der Modellparameter des entsprechenden Teils. In dieser Einstellung können auch Farbverläufe auf diese Weise aufgeteilt werden. Standardmäßig verwendet ZeRO-2 die Reduce-Methode, um Gradienten zwischen allen Ranks in umgekehrter Reihenfolge zu aggregieren, und dann muss jeder Rank nur den Teil der Parameter behalten, für den er verantwortlich ist, was nicht nur redundante wiederholte Berechnungen eliminiert, sondern auch den Speicher reduziert Verwendung. Megatron-lm verteiltoptimizer Wie in der Abbildung oben gezeigt, verwendet DistributedOptimizer den ReduceScatter-Operator, um alle zuvor akkumulierten Farbverläufe auf verschiedene Ränge zu verteilen, nachdem alle durch den voreingestellten Farbverlauf aggregierten Farbverläufe erhalten wurden. Jeder Rang erhält nur einen Teil des Gradienten, den er verarbeiten muss, und aktualisiert dann den Optimiererstatus und die entsprechenden Parameter. Schließlich erhält jeder Rang über AllGather aktualisierte Parameter von anderen Knoten und erhält schließlich alle Parameter. Die tatsächlichen Trainingsergebnisse zeigen, dass die Gradienten- und Parameterkommunikation von Megatron-LM in Reihe mit anderen Berechnungen durchgeführt wird. Bei umfangreichen Vortrainingsaufgaben ist dies normalerweise nicht möglich, um sicherzustellen, dass die Gesamtstapeldatengröße unverändert bleibt Öffnen Sie eine größere GA. Daher wird der Anteil der Kommunikation mit der Zunahme der Maschinen zunehmen. Derzeit führen die Eigenschaften der seriellen Kommunikation zu einer sehr schwachen Skalierbarkeit. Auch innerhalb der Gemeinschaft ist der Bedarf akut.
Megatron-LLaMA OverlappedDistributedOptimizer
Um dieses Problem zu lösen, verbessert Megatron-LLaMA das DistributedOpt des nativen Megatron-LM-Imizers, sodass sein Gradientenkommunikationsoperator mit der Berechnung parallelisiert werden kann. Im Vergleich zur ZeRO-Implementierung verwendet Megatron-LLaMA insbesondere eine skalierbarere kollektive Kommunikationsmethode, um die Skalierbarkeit durch geschickte Optimierung der Optimierer-Partitionierungsstrategie unter der Prämisse der Parallelität zu verbessern.Das Hauptdesign von OverlappedDistributedOptimizer gewährleistet die folgenden Punkte: a) Das Datenvolumen eines einzelnen Kommunikationsbetreibers ist groß genug, um die Kommunikationsbandbreite vollständig auszunutzen. b) Die für die neue Segmentierungsmethode erforderliche Kommunikationsdatenmenge sollte dem Minimum entsprechen Kommunikationsdatenvolumen, das für die Datenparallelität erforderlich ist; c) Während des Konvertierungsprozesses von vollständigen Parametern oder Verläufen und segmentierten Parametern oder Verläufen können nicht zu viele Videospeicherkopien eingeführt werden.Konkret verbessert Megatron-LLaMA den Mechanismus von DistributedOptimizer und schlägt OverlappedDistributedOptimizer vor, der in Kombination mit der neuen Segmentierungsmethode zur Optimierung des umgekehrten Prozesses im Training verwendet wird. Wie in der Abbildung oben gezeigt, werden bei der Initialisierung von OverlappedDistributedOptimizer alle Parameter dem Bucket vorab zugewiesen, zu dem sie gehören. Die Parameter in einem Bucket sind vollständig. Ein Parameter gehört nur zu einem Bucket. Es können mehrere Parameter in einem Bucket vorhanden sein. Logischerweise wird jeder Bucket fortlaufend in P (P ist die Anzahl der parallelen Datengruppen) gleichen Teile unterteilt, und jeder Rang in der parallelen Datengruppe ist für einen von ihnen verantwortlich. Bucket wird in eine lokale Warteschlange (lokale Grad-Bucket-Warteschlange) gestellt, um die Kommunikationsreihenfolge sicherzustellen. Während des Trainings und der Berechnung tauschen die datenparallelen Gruppen die benötigten Gradienten durch kollektive Kommunikation in Bucket-Einheiten aus. Die Implementierung von Bucket in Megatron-LLaMA nutzt die Adressindizierung so weit wie möglich und weist Speicherplatz nur dann neu zu, wenn sich der erforderliche Wert ändert, wodurch eine Verschwendung von Videospeicher vermieden wird. Das obige Design, kombiniert mit einer Vielzahl technischer Optimierungen, ermöglicht es Megatron-LLaMA, die Hardware während groß angelegter Schulungen voll auszunutzen und eine bessere Beschleunigung als natives Megatron-LM zu erreichen. Beim Training von 32 A100-Karten auf 512 A100-Karten kann Megatron-LLaMA in einer häufig verwendeten gemischten Netzwerkumgebung immer noch ein Erweiterungsverhältnis von 0,85 erreichen. -Megatron-Llamas Zukunftsplan
Megatron-Llama ist ein Schulungsrahmen, der gemeinsam von der Tao Tian Group und Ai Orange Technology geöffnet wird und anschließende Wartungsunterstützung bietet. Es verfügt über weit verbreitete interne Anwendungen. Da immer mehr Entwickler zur Open-Source-Community von LLaMA strömen und Erfahrungen einbringen, aus denen man voneinander lernen kann, glaube ich, dass es in Zukunft auf der Ebene des Trainingsframeworks mehr Herausforderungen und Möglichkeiten geben wird. Megatron-LLaMA wird die Entwicklung der Community genau beobachten und mit Entwicklern zusammenarbeiten, um die folgenden Richtungen voranzutreiben:
Adaptive optimale KonfigurationsauswahlUnterstützung für mehr Modellstruktur oder lokale Designänderungen - Mehr ultimatives Leistungstraining Lösung unter verschiedenen HardwareumgebungenProjektadresse: https://github.com/alibaba/Megatron-LLaMA
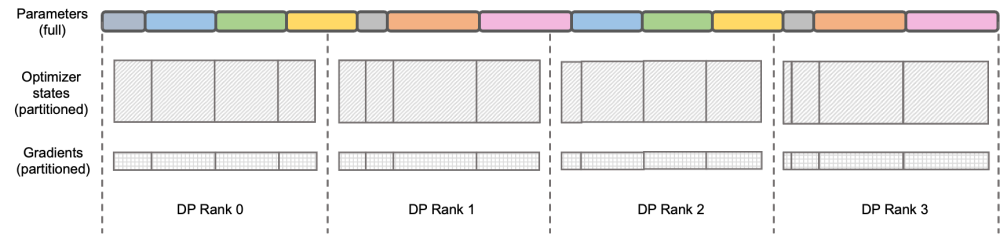 Deepspeed Zero ist eine Reihe verteilter Trainingsrahmen, die von Microsoft gestartet wurden. Wirkung erzielen. DeepSpeed ZeRO Stage-2 (im Folgenden als ZeRO-2 bezeichnet) ist eine Technologie im Framework, die Speicherverbrauch spart, ohne zusätzlichen Rechen- und Kommunikationsaufwand hinzuzufügen. Wie in der Abbildung oben gezeigt, muss jeder Rang aufgrund der Berechnungsanforderungen über alle Parameter verfügen. Für den Optimiererstatus ist jedoch jeder Rang nur für einen Teil davon verantwortlich, und es ist nicht erforderlich, dass alle Ränge vollständig wiederholte Vorgänge gleichzeitig ausführen. Daher schlägt ZeRO-2 vor, den Optimiererstatus gleichmäßig auf jeden Rang aufzuteilen (beachten Sie, dass nicht sichergestellt werden muss, dass jede Variable gleichmäßig aufgeteilt ist oder in einem bestimmten Rang vollständig erhalten bleibt. Jeder Rang muss nur während des Trainingsprozesses verwendet werden). Verantwortlich für die Aktualisierung des Optimiererstatus und der Modellparameter des entsprechenden Teils. In dieser Einstellung können auch Farbverläufe auf diese Weise aufgeteilt werden. Standardmäßig verwendet ZeRO-2 die Reduce-Methode, um Gradienten zwischen allen Ranks in umgekehrter Reihenfolge zu aggregieren, und dann muss jeder Rank nur den Teil der Parameter behalten, für den er verantwortlich ist, was nicht nur redundante wiederholte Berechnungen eliminiert, sondern auch den Speicher reduziert Verwendung. Megatron-lm verteiltoptimizer Wie in der Abbildung oben gezeigt, verwendet DistributedOptimizer den ReduceScatter-Operator, um alle zuvor akkumulierten Farbverläufe auf verschiedene Ränge zu verteilen, nachdem alle durch den voreingestellten Farbverlauf aggregierten Farbverläufe erhalten wurden. Jeder Rang erhält nur einen Teil des Gradienten, den er verarbeiten muss, und aktualisiert dann den Optimiererstatus und die entsprechenden Parameter. Schließlich erhält jeder Rang über AllGather aktualisierte Parameter von anderen Knoten und erhält schließlich alle Parameter. Die tatsächlichen Trainingsergebnisse zeigen, dass die Gradienten- und Parameterkommunikation von Megatron-LM in Reihe mit anderen Berechnungen durchgeführt wird. Bei umfangreichen Vortrainingsaufgaben ist dies normalerweise nicht möglich, um sicherzustellen, dass die Gesamtstapeldatengröße unverändert bleibt Öffnen Sie eine größere GA. Daher wird der Anteil der Kommunikation mit der Zunahme der Maschinen zunehmen. Derzeit führen die Eigenschaften der seriellen Kommunikation zu einer sehr schwachen Skalierbarkeit. Auch innerhalb der Gemeinschaft ist der Bedarf akut.
Deepspeed Zero ist eine Reihe verteilter Trainingsrahmen, die von Microsoft gestartet wurden. Wirkung erzielen. DeepSpeed ZeRO Stage-2 (im Folgenden als ZeRO-2 bezeichnet) ist eine Technologie im Framework, die Speicherverbrauch spart, ohne zusätzlichen Rechen- und Kommunikationsaufwand hinzuzufügen. Wie in der Abbildung oben gezeigt, muss jeder Rang aufgrund der Berechnungsanforderungen über alle Parameter verfügen. Für den Optimiererstatus ist jedoch jeder Rang nur für einen Teil davon verantwortlich, und es ist nicht erforderlich, dass alle Ränge vollständig wiederholte Vorgänge gleichzeitig ausführen. Daher schlägt ZeRO-2 vor, den Optimiererstatus gleichmäßig auf jeden Rang aufzuteilen (beachten Sie, dass nicht sichergestellt werden muss, dass jede Variable gleichmäßig aufgeteilt ist oder in einem bestimmten Rang vollständig erhalten bleibt. Jeder Rang muss nur während des Trainingsprozesses verwendet werden). Verantwortlich für die Aktualisierung des Optimiererstatus und der Modellparameter des entsprechenden Teils. In dieser Einstellung können auch Farbverläufe auf diese Weise aufgeteilt werden. Standardmäßig verwendet ZeRO-2 die Reduce-Methode, um Gradienten zwischen allen Ranks in umgekehrter Reihenfolge zu aggregieren, und dann muss jeder Rank nur den Teil der Parameter behalten, für den er verantwortlich ist, was nicht nur redundante wiederholte Berechnungen eliminiert, sondern auch den Speicher reduziert Verwendung. Megatron-lm verteiltoptimizer Wie in der Abbildung oben gezeigt, verwendet DistributedOptimizer den ReduceScatter-Operator, um alle zuvor akkumulierten Farbverläufe auf verschiedene Ränge zu verteilen, nachdem alle durch den voreingestellten Farbverlauf aggregierten Farbverläufe erhalten wurden. Jeder Rang erhält nur einen Teil des Gradienten, den er verarbeiten muss, und aktualisiert dann den Optimiererstatus und die entsprechenden Parameter. Schließlich erhält jeder Rang über AllGather aktualisierte Parameter von anderen Knoten und erhält schließlich alle Parameter. Die tatsächlichen Trainingsergebnisse zeigen, dass die Gradienten- und Parameterkommunikation von Megatron-LM in Reihe mit anderen Berechnungen durchgeführt wird. Bei umfangreichen Vortrainingsaufgaben ist dies normalerweise nicht möglich, um sicherzustellen, dass die Gesamtstapeldatengröße unverändert bleibt Öffnen Sie eine größere GA. Daher wird der Anteil der Kommunikation mit der Zunahme der Maschinen zunehmen. Derzeit führen die Eigenschaften der seriellen Kommunikation zu einer sehr schwachen Skalierbarkeit. Auch innerhalb der Gemeinschaft ist der Bedarf akut. 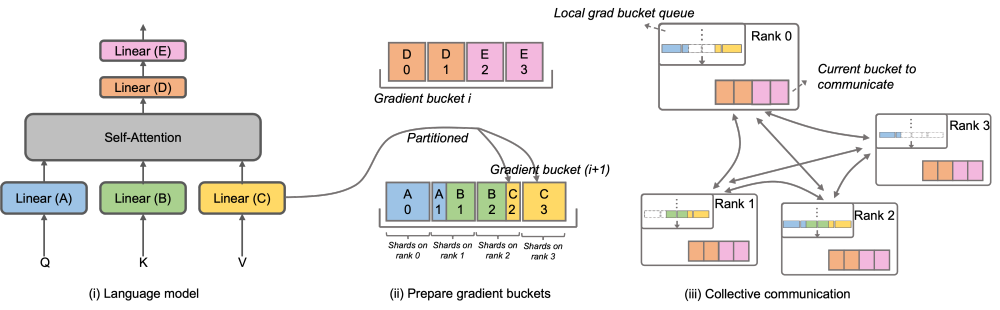
Das obige ist der detaillierte Inhalt vonDie Taotian Group und Aicheng Technology arbeiten zusammen, um das Open-Source-Modell-Trainingsframework Megatron-LLaMA zu veröffentlichen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was macht ein Datenpflegeingenieur?
- Was macht ein Softwaretestingenieur?
- Was ist ein Linux-Betriebs- und Wartungsingenieur?
- Detaillierte Erläuterung der Schritte zum Erstellen eines Projekts mit Keil
- Lassen Sie uns darüber sprechen, wie Sie das Springboot-Projekt ordnungsgemäß in vscode ausführen können