
Heim >Technologie-Peripheriegeräte >KI >Keine Notwendigkeit für 4 H100! Code Llama mit 34 Milliarden Parametern kann auf dem Mac ausgeführt werden, 20 Token pro Sekunde, beste Codegenerierung
Keine Notwendigkeit für 4 H100! Code Llama mit 34 Milliarden Parametern kann auf dem Mac ausgeführt werden, 20 Token pro Sekunde, beste Codegenerierung

- PHPznach vorne
- 2023-09-19 13:05:01945Durchsuche
Ein Entwickler in der Open-Source-Community, Georgi Gerganov, stellte fest, dass er das 34B Code Llama-Modell mit voller F16-Präzision auf M2 Ultra ausführen konnte und die Inferenzgeschwindigkeit 20 Token/s überstieg.
M2 Ultra hat eine Bandbreite von 800 GB/s, wofür andere normalerweise 4 High-End-GPUs benötigen, um diese zu erreichen.
Und die eigentliche Antwort dahinter ist: Speculative Sampling.
Georges Entdeckung löste sofort eine Diskussion unter den ganz Großen in der Branche der künstlichen Intelligenz aus.
Karpathy retweetete und kommentierte: „Die spekulative Ausführung von LLM ist eine hervorragende Optimierung der Inferenzzeit.“

„Speculative Sampling“ beschleunigt die Inferenz
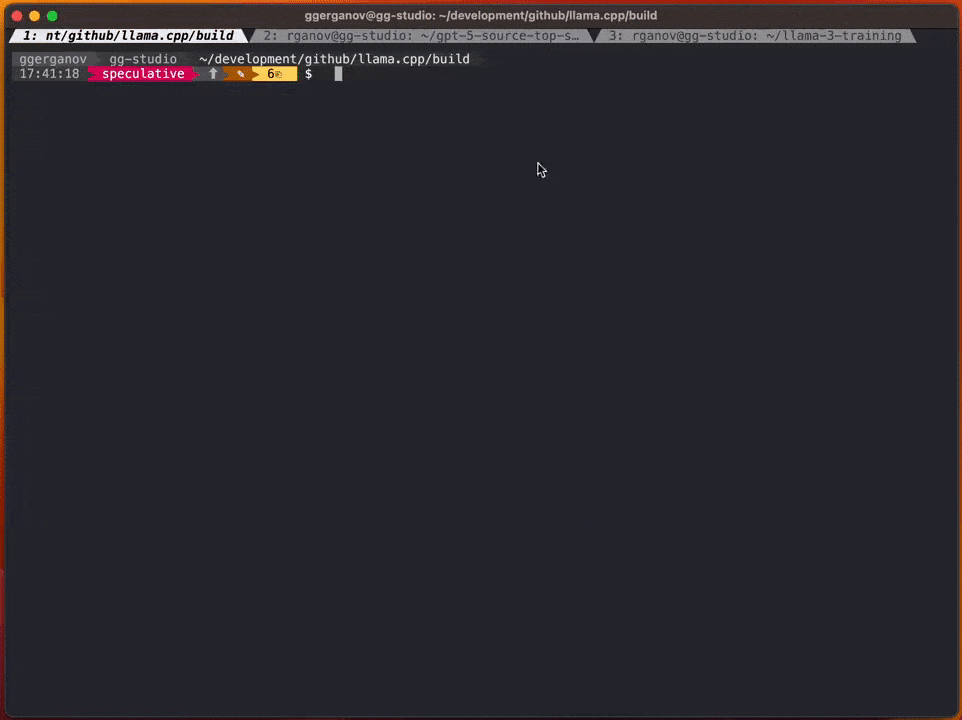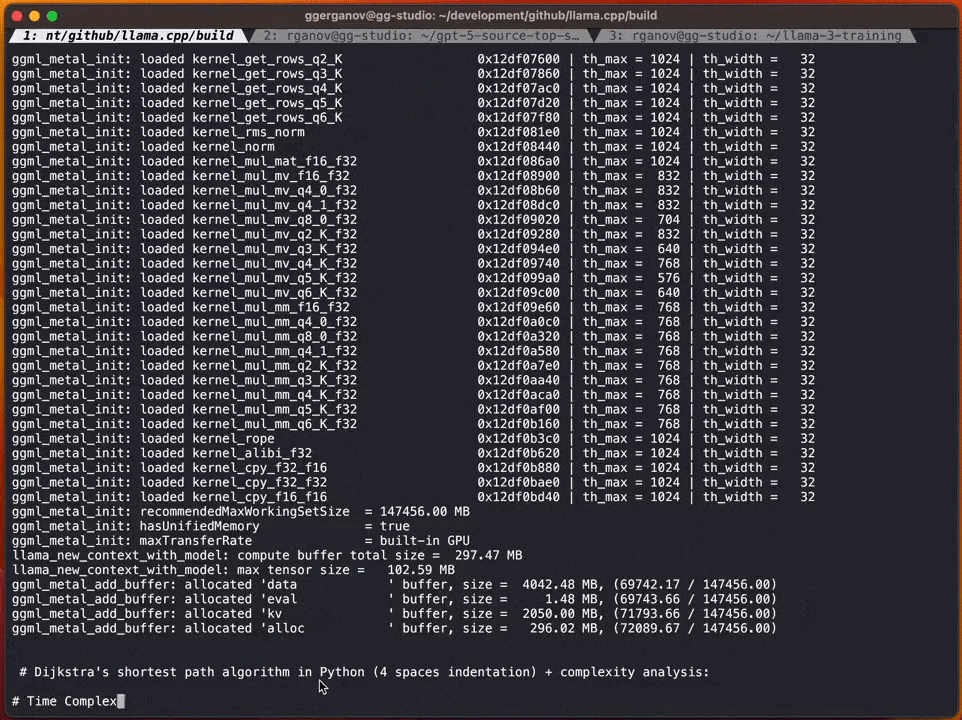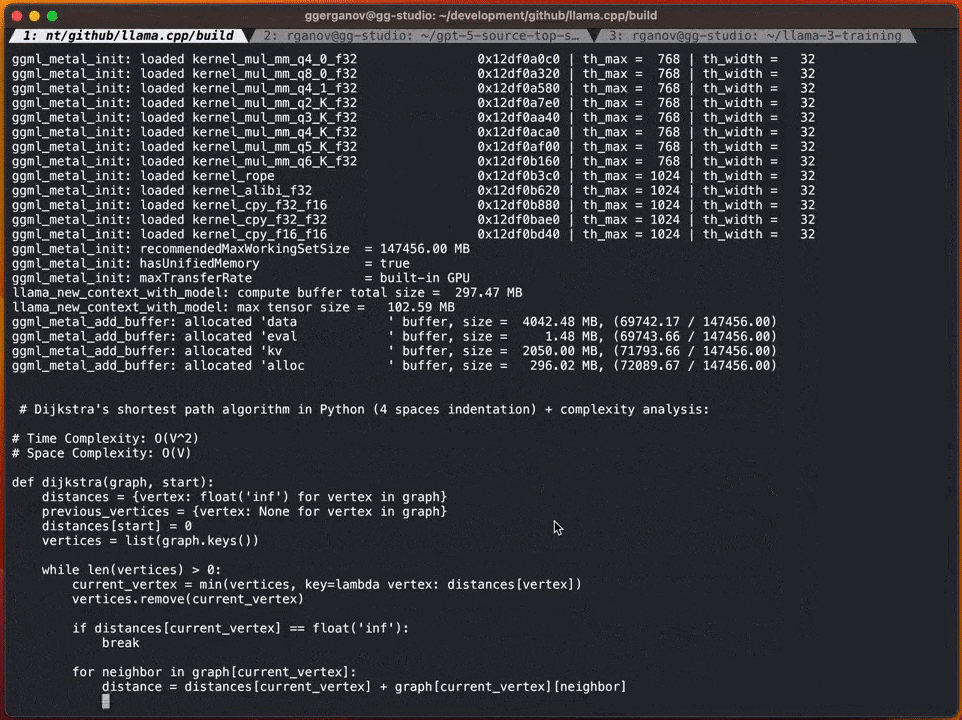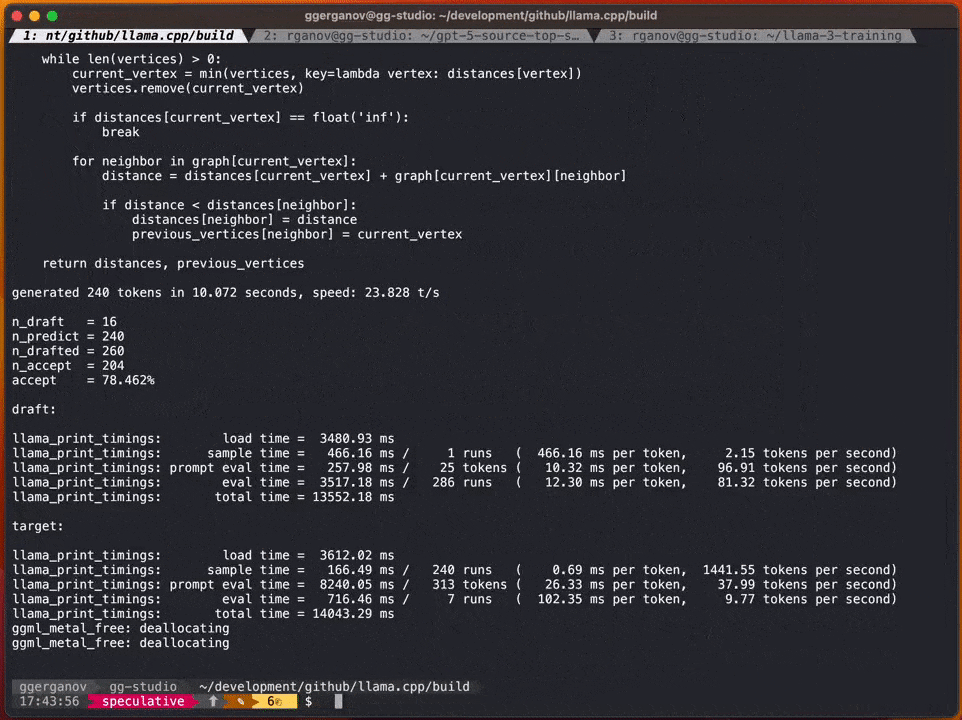
In diesem Beispiel verwendete Georgi das Quantenentwurfsmodell Q4 7B (d. h. Code Llama 7B), um spekulative Dekodierung durchzuführen, und verwendete dann Code Llama34B auf M2 Ultra erzeugen.
Um es einfach auszudrücken: Verwenden Sie ein „kleines Modell“, um einen Entwurf zu erstellen, und verwenden Sie dann das „große Modell“, um zu überprüfen und Korrekturen vorzunehmen, um den gesamten Prozess zu beschleunigen.

GitHub-Adresse: https://twitter.com/ggerganov/status/1697262700165013689
Laut Georgi sind die Geschwindigkeiten dieser Modelle wie folgt:
F1 6 34B: Ca. pro Sekunde 10 Token
Was umgeschrieben werden muss, ist: Q4 7B: ~80 Token pro Sekunde
Hier ist ein Standard-F16-Sampling-Beispiel ohne spekulatives Sampling: .
Nach Hinzunahme der spekulativen Sampling-Strategie kann die Geschwindigkeit etwa 20 Mark pro Sekunde erreichen
Laut Georgi kann die Geschwindigkeit der Inhaltsgenerierung variieren. Allerdings scheint dieser Ansatz im Hinblick auf die Codegenerierung sehr effektiv zu sein, da der Großteil des Vokabulars durch das Entwurfsmodell richtig erraten werden kann
Auch Anwendungsfälle, die „Grammar Sampling“ verwenden, werden wahrscheinlich stark davon profitieren

Spekulation Wie ermöglicht die Stichprobenziehung eine schnelle Schlussfolgerung?
Karpathy hat eine Erklärung abgegeben, die auf drei früheren Studien von Google Brain, UC Berkeley und DeepMind basiert.

Bitte klicken Sie auf den folgenden Link, um das Papier anzusehen: https://arxiv.org/pdf/2211.17192.pdf

Papieradresse: https://arxiv.org/pdf/ 1811.03115.pdf

Papieradresse: https://arxiv.org/pdf/2302.01318.pdf
Dies hängt von der folgenden unintuitiven Beobachtung ab:
Erforderlich für die Weiterleitung von LLM ein einziger Eingang token Die Zeit ist dieselbe wie die Zeit, die für die Stapelweiterleitung von LLM auf K Eingabe-Tokens erforderlich ist (K ist größer als Sie denken).
Diese unintuitive Tatsache ist darauf zurückzuführen, dass die Abtastung stark durch den Speicher begrenzt ist und der Großteil der „Arbeit“ nicht berechnet wird, sondern die Gewichte des Transformers zur Verarbeitung aus dem VRAM in den On-Chip-Cache gelesen werden.

Um die Aufgabe des Lesens aller Gewichte zu erfüllen, ist es besser, sie auf den Eingabevektor des gesamten Stapels anzuwenden.
Der Grund, warum wir diese Tatsache nicht naiv ausnutzen und K-Token auf einmal abtasten können, liegt darin, dass alle N-Token vorhanden sind Es hängt alles von dem Token ab, das wir in Schritt N-1 abgetastet haben. Da es sich um eine serielle Abhängigkeit handelt, erfolgt die Basisimplementierung einfach eine nach der anderen von links nach rechts.
Eine clevere Idee besteht nun darin, mit einem kleinen und kostengünstigen Entwurfsmodell zunächst eine Kandidatensequenz aus K Markern zu generieren – einen „Entwurf“. Anschließend speisen wir alle diese Informationen stapelweise in das große Modell ein
Nach der oben genannten Methode ist dies fast so schnell wie die Eingabe nur eines Tokens.
Dann untersuchen wir das Modell von links nach rechts und die vom Beispieltoken vorhergesagten Logits. Jedes Beispiel, das mit dem Entwurf übereinstimmt, ermöglicht es uns, sofort zum nächsten Token zu springen.
Wenn es zu Meinungsverschiedenheiten kommt, geben wir das Entwurfsmodell auf und tragen die Kosten für die Durchführung einiger einmaliger Arbeiten (Probenahme des Entwurfsmodells und Weiterleitung nachfolgender Token).
Das funktioniert in der Praxis gut Der Grund dafür ist, dass Draft-Token in den meisten Fällen akzeptiert werden und da es sich um einfache Token handelt, können sie auch von kleineren Draft-Modellen akzeptiert werden.
Wenn diese einfachen Token akzeptiert werden, überspringen wir diese Teile. Schwierigkeitsmarker, mit denen das große Modell nicht einverstanden ist, fallen auf die ursprüngliche Geschwindigkeit zurück, sind aber aufgrund der zusätzlichen Arbeit tatsächlich langsamer.
Also, zusammenfassend: Dieser seltsame Trick funktioniert, weil LLM während der Inferenz speicherbeschränkt ist. Bei „Batchgröße 1“ wird eine einzelne interessierende Sequenz abgetastet, was bei den meisten „lokalen LLM“-Anwendungsfällen der Fall ist. Darüber hinaus sind die meisten Token „einfach“.
Der Mitbegründer von HuggingFace sagte, dass das 34-Milliarden-Parameter-Modell vor anderthalb Jahren außerhalb des Rechenzentrums sehr groß und unüberschaubar aussah. Jetzt kann es ganz einfach mit nur einem Laptop gehandhabt werden

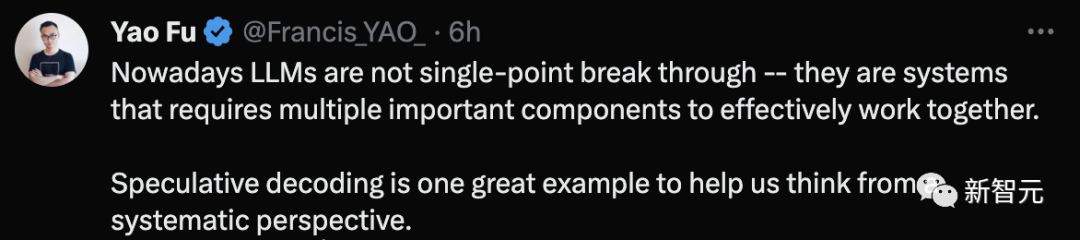
Das heutige LLM ist kein einzelner Durchbruch, sondern ein System, das mehrere wichtige Komponenten benötigt, um effektiv zusammenzuarbeiten. Speculative Decoding ist ein großartiges Beispiel, das uns hilft, aus einer Systemperspektive zu denken.
Das obige ist der detaillierte Inhalt vonKeine Notwendigkeit für 4 H100! Code Llama mit 34 Milliarden Parametern kann auf dem Mac ausgeführt werden, 20 Token pro Sekunde, beste Codegenerierung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!