
Heim >Technologie-Peripheriegeräte >KI >Baidu-Business-Multimodal-Verständnis und AIGC-Innovationspraxis
Baidu-Business-Multimodal-Verständnis und AIGC-Innovationspraxis

- 王林nach vorne
- 2023-09-18 17:33:051175Durchsuche

1. Verständnis multimodaler Rich-Media-Inhalte
Lassen Sie uns zunächst unsere Wahrnehmung multimodaler Inhalte vorstellen.
1. Multimodales Verständnis
Verbesserung der Inhaltsverständnisfähigkeiten, sodass das Werbesystem Inhalte in segmentierten Szenarien besser verstehen kann.

Bei der Verbesserung der Inhaltsverständnisfähigkeiten werden Sie auf viele praktische Probleme stoßen:
- Es gibt viele kommerzielle Geschäftsszenarien und Branchen, unabhängige Modellierung ist überflüssig und führt zu einer Überanpassung und einer Verteilung zwischen Szenarien Wie man Gemeinsamkeit und Spezifität bei der einheitlichen Modellierung in Einklang bringt.
- Schlechter Text rund um kommerzielle Bildmaterialien kann leicht zu schlechten Fallillustrationen führen.
- Das System ist voller bedeutungsloser ID-Funktionen und weist eine schlechte Verallgemeinerung auf.
- Im Zeitalter von Rich Media müssen wir eine Lösung finden, wie wir die visuelle Semantik effektiv nutzen und diese Inhaltsfunktionen, Videofunktionen und andere Funktionen integrieren können, um die Wahrnehmung von Rich Media-Inhalten im System zu verbessern.
Was ist eine gute multimodale Basisdarstellung?
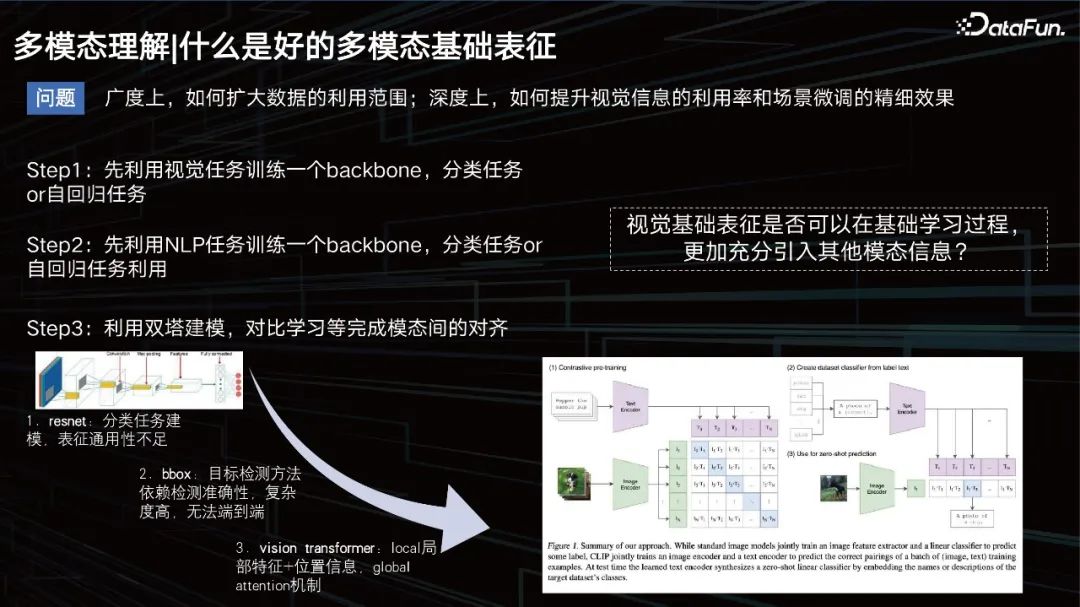
Was ist eine gute multimodale Darstellung?
In der Breite muss der Umfang der Datenanwendung erweitert werden, in der Tiefe müssen die visuellen Effekte verbessert und gleichzeitig die Datenfeinabstimmung der Szene sichergestellt werden.
Früher bestand die herkömmliche Idee darin, ein Modell zu trainieren, um die Modalität von Bildern zu erlernen, eine autoregressive Aufgabe, dann die Textaufgabe auszuführen und dann einige Twin-Tower-Muster anzuwenden, um die modale Beziehung zwischen den beiden zu schließen. Zu dieser Zeit war die Textmodellierung relativ einfach und jeder beschäftigte sich mehr damit, wie man Visionen modelliert. Es begann mit CNN und umfasste später einige auf der Zielerkennung basierende Methoden, um die visuelle Darstellung zu verbessern, wie beispielsweise die Bbox-Methode. Diese Methode verfügt jedoch über begrenzte Erkennungsfähigkeiten und ist zu umfangreich, was für ein umfangreiches Datentraining nicht förderlich ist.
Um 2020 und 2021 ist die VIT-Methode zum Mainstream geworden. Eines der bekannteren Modelle, das ich hier erwähnen muss, ist CLIP, ein 2020 von OpenAI veröffentlichtes Modell, das auf der Twin-Tower-Architektur für Text und visuelle Darstellung basiert. Verwenden Sie dann den Kosinus, um den Abstand zwischen den beiden zu schließen. Dieses Modell eignet sich sehr gut zum Abrufen, ist jedoch bei einigen Aufgaben, die logisches Denken erfordern, wie z. B. VQA-Aufgaben, etwas weniger leistungsfähig.
Darstellung lernen: Verbessern Sie die grundlegende Wahrnehmungsfähigkeit der natürlichen Sprache zum Sehen.
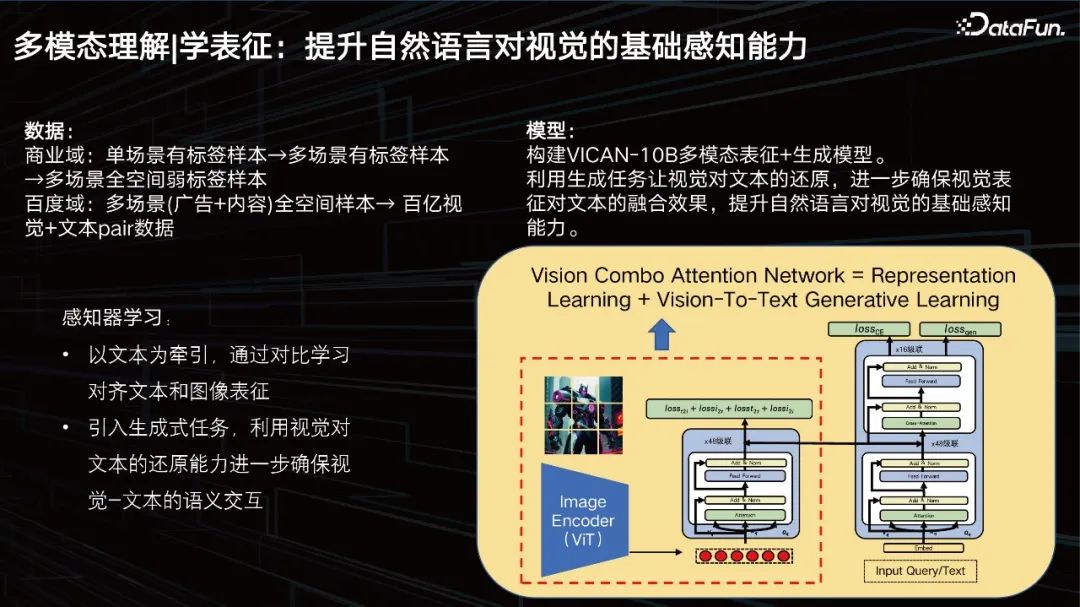
Unser Ziel ist es, die grundlegende Wahrnehmung visueller Sprache durch natürliche Sprache zu verbessern. In Bezug auf die Daten verfügt unser Geschäftsbereich über Milliarden von Daten, aber das reicht immer noch nicht aus. Wir müssen weiter expandieren, frühere Daten aus dem Geschäftsbereich einführen und sie bereinigen und sortieren. Es wurde ein Trainingssatz im Dutzend-Milliarden-Bereich erstellt.
Wir haben das multimodale Darstellungs- und Generierungsmodell VICAN-12B erstellt und dabei die Generierungsaufgabe verwendet, um dem Sehvermögen die Wiederherstellung von Text zu ermöglichen, den Fusionseffekt der visuellen Darstellung auf dem Text weiter sicherzustellen und die grundlegende Wahrnehmung natürlicher Sprache beim Sehen zu verbessern . Das Bild oben zeigt die Gesamtstruktur des Modells. Sie können sehen, dass es sich um eine Verbundstruktur aus Zwillingstürmen und einem einzelnen Turm handelt. Denn das erste, was gelöst werden muss, ist eine groß angelegte Bildabrufaufgabe. Der Teil im Kasten links ist das, was wir das visuelle Perzeptron nennen, eine ViT-Struktur mit einer Skala von 2 Milliarden Parametern. Die rechte Seite kann in zwei Ebenen angezeigt werden. Der untere Teil ist ein Stapel von Texttransformatoren zum Abrufen und der obere Teil dient der Generierung. Das Modell ist in drei Aufgaben unterteilt: Eine ist eine Generierungsaufgabe, eine ist eine Klassifizierungsaufgabe und die andere ist eine Bildvergleichsaufgabe. Das Modell wird auf der Grundlage dieser drei unterschiedlichen Ziele trainiert und hat daher relativ gute Ergebnisse erzielt werde es weiter optimieren.
Eine Reihe effizienter, einheitlicher und übertragbarer globaler Darstellungsschemata für mehrere Szenarien.

In Kombination mit Geschäftsszenariodaten wird das LLM-Modell eingeführt, um die Fähigkeiten zum Modellverständnis zu verbessern. Das CV-Modell ist das Perzeptron und das LLM-Modell ist der Versteher. Unser Ansatz besteht darin, die visuellen Merkmale entsprechend zu übertragen, da die Darstellung, wie gerade erwähnt, multimodal ist und das große Modell auf Text basiert. Wir müssen es nur an das große Modell unseres Wenxin LLM anpassen, also müssen wir Combo-Aufmerksamkeit verwenden, um die entsprechende Feature-Fusion durchzuführen. Wir müssen die logischen Argumentationsfunktionen des großen Modells beibehalten, daher versuchen wir, das große Modell nicht allein zu lassen und nur Feedbackdaten zum Geschäftsszenario hinzuzufügen, um die Integration visueller Funktionen in das große Modell zu fördern. Zur Unterstützung der Aufgabe können wir wenige Schüsse gebrauchen. Zu den Hauptaufgaben gehören:
- Die Beschreibung des Bildes ist tatsächlich nicht nur eine Beschreibung, sondern ein schnelles Reverse Engineering, das als bessere Datenquelle für uns verwendet werden kann Vincent-Diagramme später.
- Bild- und Textkorrelationskontrolle, da Unternehmen die Konfiguration und das Verständnis von Bildinformationen benötigen, müssen die Suchbegriffe und die Bildsemantik unserer Werbebilder tatsächlich kontrolliert werden. Dies ist natürlich eine sehr allgemeine Methode, die Sie erstellen können relevante Urteile zu Bildern und Eingabeaufforderungen.
- Bildrisiko- und Erfahrungskontrolle: Wir konnten den Inhalt des Bildes relativ gut beschreiben, dann müssen wir nur eine kleine Beispieldatenmigration der Risikokontrolle verwenden, um klar zu wissen, ob es sich um einige Risikoprobleme handelt .
Konzentrieren wir uns nun auf die szenenbasierte Feinabstimmung.
2. Szenariobasierte Feinabstimmung
Visuelle Abrufszene, Zwillingsturm-Feinabstimmung basierend auf der Grunddarstellung.
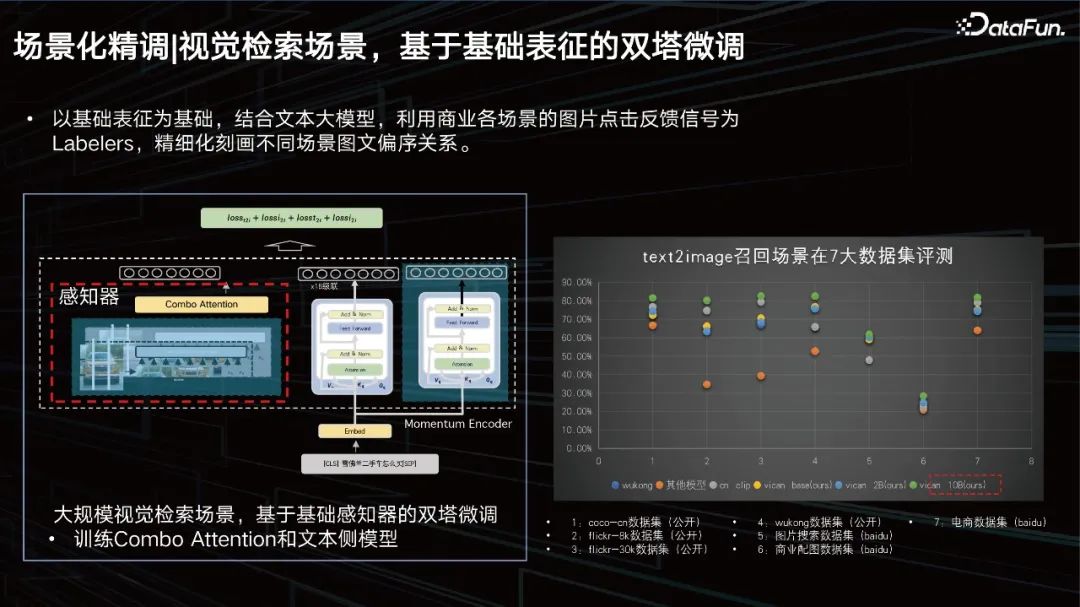
Basierend auf der Grunddarstellung werden in Kombination mit dem großen Textmodell die Bildklick-Feedbacksignale verschiedener Geschäftsszenen als Beschriftungsgeräte verwendet, um die Teilordnungsbeziehung zwischen Bildern und Texten in verschiedenen Szenen zu verfeinern. Wir haben Auswertungen für 7 große Datensätze durchgeführt und alle können SOTA-Ergebnisse erzielen.
Sortierungsszenario, inspiriert von der Textsegmentierung, quantifiziert die Semantik multimodaler Merkmale.
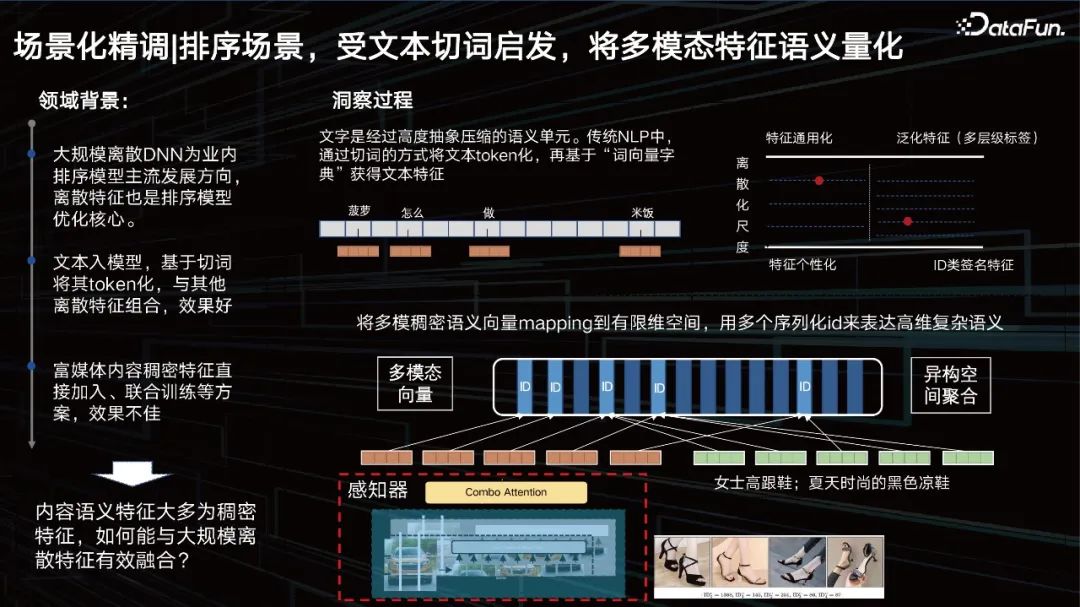
Neben der Darstellung besteht ein weiteres Problem darin, den visuellen Effekt in der Sortierszene zu verbessern. Schauen wir uns zunächst den Hintergrund des Feldes an. Diskretes DNN im großen Maßstab ist die gängige Entwicklungsrichtung von Ranking-Modellen in der Branche, und diskrete Merkmale sind auch der Kern der Optimierung von Ranking-Modellen. Der Text wird in das Modell eingegeben, anhand der Wortsegmentierung tokenisiert und mit anderen diskreten Funktionen kombiniert, um gute Ergebnisse zu erzielen. Was die Vision betrifft, hoffen wir, sie ebenfalls zu tokenisieren.
ID-Typ-Feature ist eigentlich ein sehr personalisiertes Feature, aber je vielseitiger das verallgemeinerte Feature wird, desto schlechter kann seine Charakterisierungsgenauigkeit werden. Wir müssen diesen Gleichgewichtspunkt durch Daten und Aufgaben dynamisch anpassen. Das heißt, wir hoffen, einen Maßstab zu finden, der für die Daten am relevantesten ist, die Features entsprechend in eine ID zu „segmentieren“ und multimodale Features wie Text zu segmentieren. Daher haben wir eine mehrskalige und mehrstufige Lernmethode zur Inhaltsquantifizierung vorgeschlagen, um dieses Problem zu lösen.
Sortieren von Szenen, Fusion multimodaler Funktionen und Modelle MmDict.
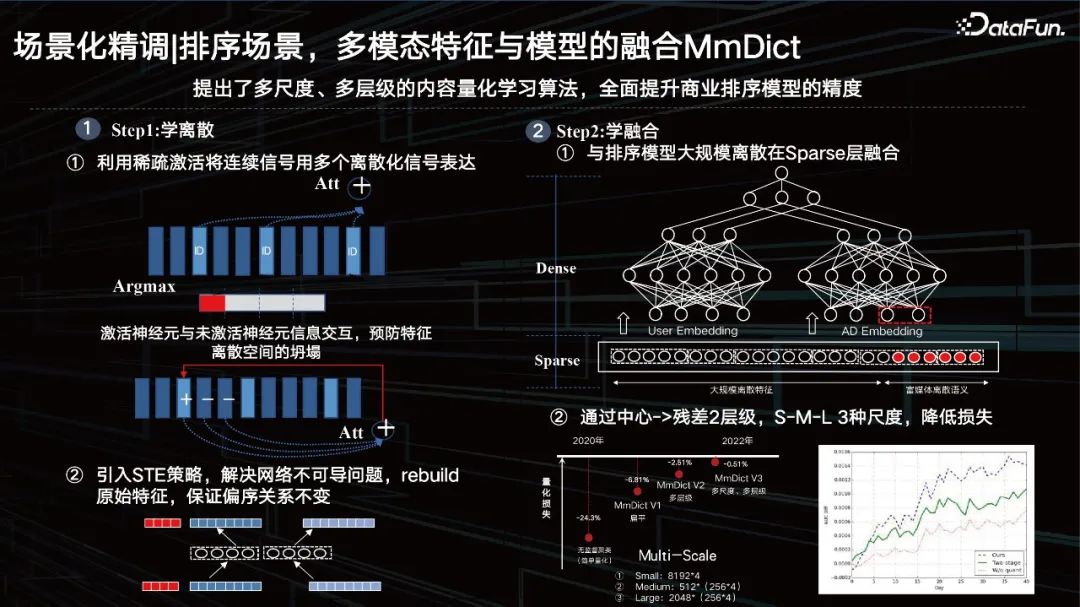
Hauptsächlich in zwei Schritte unterteilt: Der erste Schritt besteht darin, Diskretion zu lernen, und der zweite Schritt besteht darin, Fusion zu lernen.
Schritt 1: Diskret lernen
① Verwenden Sie die Sparse-Aktivierung, um kontinuierliche Signale mit mehreren diskretisierten Signalen auszudrücken. Das heißt, Sie verwenden die Sparse-Aktivierung, um dichte Features zu segmentieren, und aktivieren Sie dann die IDs im entsprechenden multimodalen Codebuch Eigentlich nur die Argmax-Operation, die zu nicht differenzierbaren Problemen führt. Gleichzeitig wird eine Informationsinteraktion zwischen aktivierten Neuronen und inaktiven Neuronen hinzugefügt, um den Zusammenbruch des Merkmalsraums zu verhindern.
② Führen Sie die STE-Strategie ein, um das Problem der Nichtdifferenzierbarkeit des Netzwerks zu lösen, die ursprünglichen Merkmale wiederherzustellen und sicherzustellen, dass die Teilordnungsbeziehung unverändert bleibt.
Verwenden Sie die Encoder-Decoder-Methode, um dichte Features nacheinander zu quantisieren, und stellen Sie die quantisierten Features dann auf die richtige Weise wieder her. Es muss sichergestellt werden, dass die Teilordnungsbeziehung vor und nach der Wiederherstellung unverändert bleibt und der quantitative Verlust von Merkmalen bei bestimmten Aufgaben nahezu auf weniger als 1 % kontrolliert werden kann. Eine solche ID kann nicht nur die aktuelle Datenverteilung personalisieren, sondern auch haben Generalisierungseigenschaften.
Schritt 2: Lernfusion
① wird in großem Maßstab auf der Sparse-Ebene mit dem Sortiermodell fusioniert.
Dann wird die gerade erwähnte Wiederverwendung versteckter Ebenen direkt darüber platziert, aber der Effekt ist eigentlich durchschnittlich. Wenn Sie es identifizieren, quantisieren und mit dem spärlichen Feature-Layer und anderen Feature-Typen verschmelzen, erzielt es eine bessere Wirkung.
② Reduzieren Sie den Verlust durch die Mitte -> Rest 2 Stufen, S-M-L 3 Skalen.
Natürlich verwenden wir auch einige Residuen und Multiskalenmethoden. Ab 2020 haben wir den Quantifizierungsverlust schrittweise gesenkt und sind letztes Jahr unter einen Punkt gesunken. Nachdem das große Modell Merkmale extrahiert hat, können wir diese erlernbare Quantifizierungsmethode verwenden, um den visuellen Inhalt mit semantischer Assoziation zu charakterisieren ID Die Eigenschaften sind tatsächlich sehr sehr Geeignet für unsere aktuellen Geschäftssysteme, einschließlich einer solchen explorativen Forschungsmethode zur ID des Empfehlungssystems.
2. Qingduo
1. Die kommerzielle AIGC ist tief in das Marketing integriert, verbessert die Produktivität von Inhalten und optimiert die Effizienz und Wirkungsverknüpfung. Die Kreativplattform Baidu Marketing AIGC bildet einen perfekten geschlossenen Kreislauf von der Inspiration über die Erstellung bis zur Lieferung . . Durch Dekonstruktion, Generierung und Feedback fördern und optimieren wir unsere AIGC.

Inspiration: KI-Verständnis (Inhalts- und Benutzerverständnis). Kann KI uns dabei helfen, herauszufinden, welche Art von Aufforderung gut ist? Von der materiellen Einsicht zur kreativen Leitung.
- Erstellung: AIGC, wie Textgenerierung, Bildgenerierung, digitale Personen, Videogenerierung usw.
- Lieferung: KI-Optimierung. Vom empirischen Versuch und Irrtum bis zur automatischen Optimierung.
- 2. Erstellung von Marketingtexten = Business-Prompt-System + großes Wenxin-Modell
Ein gutes Business-Prompt besteht aus den folgenden Elementen:

Wissensdiagramm, z. B. Verkauf von Autos, Autos Welche kommerziellen Elemente Auch die Marke allein reicht nicht aus.
- Stil, wie der aktuelle „Literaturstil“, muss tatsächlich in einige Tags abstrahiert werden Bestimmen Sie, um welche Art von Marketingtitel oder Marketingbeschreibung es sich handelt.
- Verkaufsargument, Verkaufsargument ist eigentlich ein Merkmal von Produktattributen, das den stärksten Grund für den Konsum darstellt.
- Benutzerporträts werden basierend auf den Unterschieden in den Verhaltensansichten des Ziels in verschiedene Typen unterteilt, schnell zusammengestellt und dann werden die neu abgeleiteten Typen verfeinert, um einen Typ von Benutzerporträt zu bilden.
- 3. Zusammengesetzte modale Vermarktung digitaler menschlicher Videos, Schaffung eines digitalen Menschen in 3 Minuten
Die Videogenerierung ist mittlerweile relativ ausgereift. Aber es gibt tatsächlich immer noch einige Probleme:
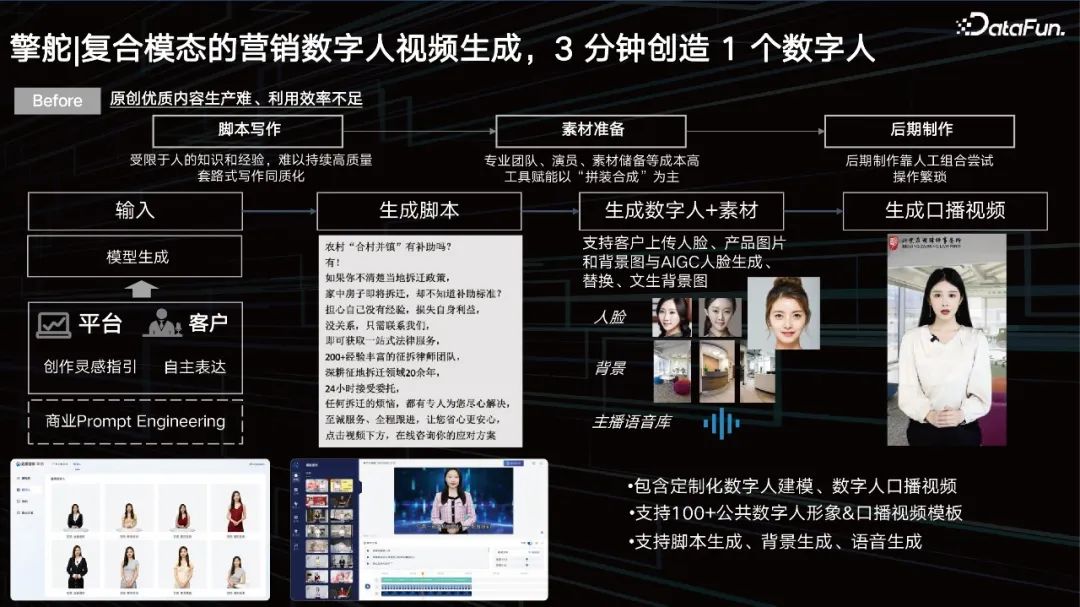
Drehbuchschreiben: Aufgrund des menschlichen Wissens und der Erfahrung ist es schwierig, qualitativ hochwertiges Schreiben aufrechtzuerhalten, und Homogenität ist ein ernstes Problem.
- Materialvorbereitung: Professionelle Teams, Akteure, Materialreserven und andere kostenintensive Werkzeuge werden befähigt, wobei der Schwerpunkt auf „Montage und Synthese“ liegt.
- Postproduktion: Die Postproduktion basiert auf manuellem Ausprobieren und der Vorgang ist umständlich.
- In der Anfangsphase geben wir durch Eingabeaufforderungen ein, welche Art von Video wir erstellen möchten, welche Art von Person wir auswählen möchten und was er sagen soll Steuern Sie unser Video nach Ihren Anforderungen. Große Modelle, um entsprechende Skripte zu generieren.
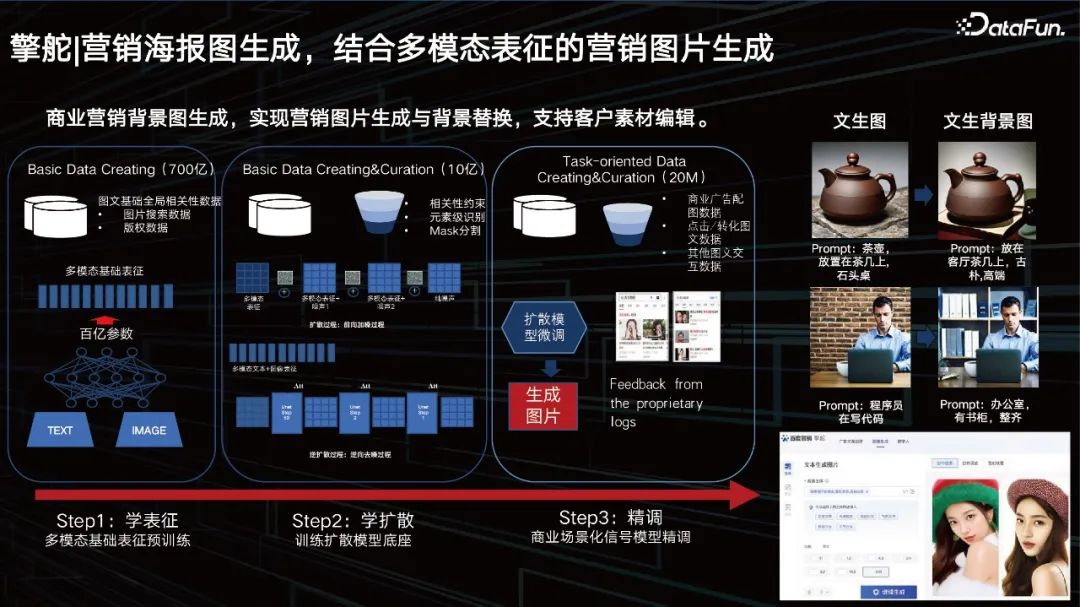
Das große Modell kann Unternehmen auch dabei helfen, Marketingplakate zu erstellen und Produkthintergründe zu ersetzen. Wir haben bereits Dutzende Milliarden multimodaler Darstellungen, die wir auf der Grundlage guter dynamischer Darstellungen gelernt haben. Nach dem Training mit Big Data möchten die Kunden auch etwas besonders Personalisiertes, daher müssen wir auch einige Methoden zur Feinabstimmung hinzufügen. Wir bieten eine Lösung, die Kunden bei der Feinabstimmung unterstützt, eine Lösung zum dynamischen Laden kleiner Parameter für große Modelle, die auch in der Branche eine gängige Lösung ist. Zunächst bieten wir Kunden die Möglichkeit, Bilder zu erstellen. Kunden können den Hintergrund hinter dem Bild durch Bearbeitung oder Aufforderung ändern. 4. Generierung von Marketingplakatbildern, Marketingbildgenerierung kombiniert mit multimodaler Darstellung
Das obige ist der detaillierte Inhalt vonBaidu-Business-Multimodal-Verständnis und AIGC-Innovationspraxis. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Wie ist der umstrittene AIGC zu einem Top-Spieler geworden?
- Google-Wissenschaftler sprechen persönlich: Wie lässt sich verkörpertes Denken umsetzen? Lassen Sie das große Modell die Sprache des Roboters „sprechen'.
- Entdeckung der drei wichtigsten Python-Modelle und der zehn häufigsten Algorithmusbeispiele
- Kingsoft Office WPS AI wird große Modelle in Tabellen, Text, Präsentationen und PDFs einbetten
- Die 0-Code-Feinabstimmung großer Modelle ist beliebt, es sind nur 5 Schritte erforderlich und die Kosten betragen nur 150 Yuan