
Heim >Technologie-Peripheriegeräte >KI >ICCV 2023 Oral |. Wie führt man ein Testsegment-Training in der offenen Welt durch? Selbsttrainingsmethode basierend auf dynamischer Prototypenerweiterung
ICCV 2023 Oral |. Wie führt man ein Testsegment-Training in der offenen Welt durch? Selbsttrainingsmethode basierend auf dynamischer Prototypenerweiterung

- 王林nach vorne
- 2023-09-17 21:21:06750Durchsuche
Bei der Förderung der Implementierung visionsbasierter Wahrnehmungsmethoden ist die Verbesserung der Generalisierungsfähigkeit des Modells eine wichtige Grundlage. Testzeit-Training/Anpassung (Testzeit-Training/Anpassung) ermöglicht es dem Modell, sich an die unbekannte Zieldomänen-Datenverteilung anzupassen, indem die Modellparametergewichte während der Testphase angepasst werden. Bestehende TTT/TTA-Methoden konzentrieren sich normalerweise auf die Verbesserung der Testsegment-Trainingsleistung unter Zieldomänendaten in einer geschlossenen Umgebung. In vielen Anwendungsszenarien wird die Zieldomäne jedoch leicht durch starke Daten außerhalb der Domäne kontaminiert (Strong OOD). , semantisch irrelevante Datenkategorien. In diesem Fall, auch bekannt als Open World Test Segment Training (OWTTT), klassifizieren bestehende TTT/TTA starke Daten außerhalb der Domäne normalerweise zwangsweise in bekannte Kategorien, was letztendlich zu Störungen bei schwachen Daten außerhalb der Domäne (Weak OOD) führt, z Erkennungsfähigkeit von durch Rauschen gestörten Bildern
Kürzlich haben die South China University of Technology und das A*STAR-Team erstmals die Einrichtung eines Open-World-Testsegmenttrainings vorgeschlagen und die entsprechende Trainingsmethode auf den Markt gebracht

- Papier : https://arxiv.org/abs/2308.09942
- Der Inhalt, der neu geschrieben werden muss, ist: Code-Link: https://github.com/Yushu-Li/OWTTT
- Dieser Artikel schlägt zunächst a vor Starke adaptive Schwelle Die Filtermethode für Datenproben außerhalb der Domäne verbessert die Robustheit der selbsttrainingenden TTT-Methode in der offenen Welt. Die Methode schlägt außerdem eine Methode zur Charakterisierung starker Stichproben außerhalb der Domäne basierend auf dynamisch erweiterten Prototypen vor, um den schwachen/starken Datentrennungseffekt außerhalb der Domäne zu verbessern. Schließlich wird das Selbsttraining durch die Verteilungsausrichtung eingeschränkt.
Die Methode in diesem Artikel erzielt eine optimale Leistung bei 5 verschiedenen OWTTT-Benchmarks und bietet eine neue Richtung für die nachfolgende Forschung zu TTT, um robustere TTT-Methoden zu erkunden. Die Forschung wurde als mündliche Arbeit im ICCV 2023 angenommen.
EinführungTestsegmenttraining (TTT) kann nur während der Inferenzphase auf Zieldomänendaten zugreifen und eine spontane Inferenz auf Testdaten mit Verteilungsverschiebungen durchführen. Der Erfolg von TTT wurde an einer Reihe künstlich ausgewählter, synthetisch beschädigter Zieldomänendaten nachgewiesen. Allerdings sind die Leistungsgrenzen bestehender TTT-Methoden noch nicht vollständig erforscht.
Um TTT-Anwendungen in offenen Szenarien zu fördern, hat sich der Schwerpunkt der Forschung auf die Untersuchung von Szenarien verlagert, in denen TTT-Methoden versagen könnten. Es wurden viele Anstrengungen unternommen, um stabile und robuste TTT-Methoden in realistischeren Open-World-Umgebungen zu entwickeln. In dieser Arbeit befassen wir uns mit einem häufigen, aber übersehenen Open-World-Szenario, bei dem die Zieldomäne möglicherweise Testdatenverteilungen enthält, die aus deutlich unterschiedlichen Umgebungen stammen, z. B. andere semantische Kategorien als die Quelldomäne oder einfach zufälliges Rauschen.
Wir nennen die oben genannten Testdaten starke Out-of-Distribution-Daten (starke OOD). Was in dieser Arbeit als schwache OOD-Daten bezeichnet wird, sind Testdaten mit Verteilungsverschiebungen, wie beispielsweise häufigen synthetischen Schäden. Daher motiviert uns der Mangel an vorhandener Arbeit in dieser realen Umgebung, die Verbesserung der Robustheit des Open World Test Segment Training (OWTTT) zu untersuchen, bei dem die Testdaten durch starke OOD-Proben verunreinigt werden
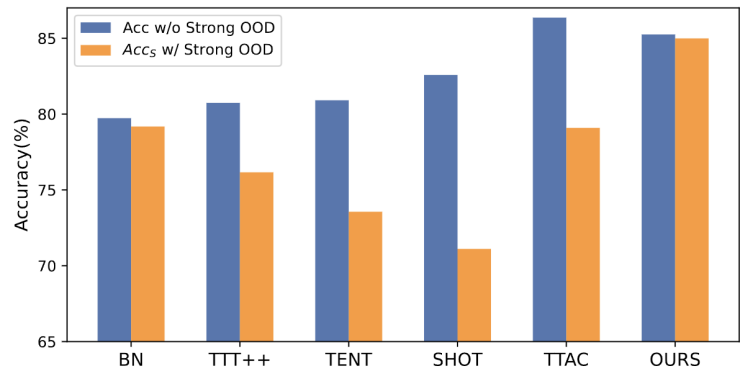
Was muss umgeschrieben werden Es ist: Abbildung 1: Die Ergebnisse der Bewertung der vorhandenen TTT-Methode unter der OWTTT-EinstellungWie in Abbildung 1 gezeigt, haben wir zunächst die vorhandene TTT-Methode unter der OWTTT-Einstellung bewertet und festgestellt, dass sowohl Selbsttraining als auch Verteilungsorientierte TTT-Methoden werden durch starke OOD-Proben beeinflusst. Diese Ergebnisse deuten darauf hin, dass ein sicheres Testtraining durch die Anwendung der vorhandenen TTT-Technologie in der offenen Welt nicht erreicht werden kann. Wir führen ihr Scheitern auf die folgenden zwei Gründe zurück:
- Das auf Selbsttraining basierende TTT hat Schwierigkeiten mit starken OOD-Proben, da es Testproben bekannten Klassen zuordnen muss. Obwohl einige Stichproben mit geringer Konfidenz durch Anwendung des beim halbüberwachten Lernen verwendeten Schwellenwerts herausgefiltert werden können, gibt es immer noch keine Garantie dafür, dass alle starken OOD-Stichproben herausgefiltert werden.
- Methoden, die auf der Verteilungsausrichtung basieren, sind betroffen, wenn starke OOD-Stichproben berechnet werden, um die Zieldomänenverteilung abzuschätzen. Sowohl die globale Verteilungsausrichtung [1] als auch die Klassenverteilungsausrichtung [2] können beeinträchtigt werden und zu einer ungenauen Ausrichtung der Merkmalsverteilung führen.
- Um die Robustheit von Open-World-TTT im Rahmen des Selbsttrainings zu verbessern, haben wir die möglichen Gründe für das Scheitern bestehender TTT-Methoden berücksichtigt und eine Lösung vorgeschlagen, die zwei Technologien kombiniert.
Zuerst werden wir die Basislinie festlegen von TTT basierend auf der Variante, das heißt, der Quelldomänenprototyp wird als Clusterzentrum für das Clustering in der Zieldomäne verwendet. Um die Auswirkungen von starkem OOD auf das Selbsttraining durch falsche Pseudo-Labels abzuschwächen, schlagen wir eine hyperparameterfreie Methode zum Zurückweisen starker OOD-Proben vor Durch Auswahl isolieren Eine starke OOD-Probenerweiterung. Daher ermöglicht das Selbsttraining, dass starke OOD-Proben enge Cluster um den neu erweiterten starken OOD-Prototyp bilden. Dies erleichtert die Verteilungsausrichtung zwischen Quell- und Zieldomänen. Wir schlagen außerdem vor, das Selbsttraining durch eine globale Verteilungsausrichtung zu regulieren, um das Risiko einer Bestätigungsverzerrung zu verringern
Um das Open-World-TTT-Szenario zu synthetisieren, übernehmen wir schließlich die Datensätze CIFAR10-C, CIFAR100-C, ImageNet-C, VisDA-C, ImageNet-R, Tiny-ImageNet, MNIST und SVHN und verwenden Daten auf Schwache OOD eingestellt, andere legen Benchmark-Datensätze für starke OOD fest. Wir bezeichnen diesen Benchmark als „Open World Test Segment Training Benchmark“ und hoffen, dass dies dazu anregt, dass sich künftig mehr Arbeiten auf die Robustheit des Testsegmenttrainings in realistischeren Szenarien konzentrieren.
Methode
Das Papier ist in vier Teile unterteilt, um die vorgeschlagene Methode vorzustellen.
1) Übersicht über die Einstellungen von Trainingsaufgaben im Testsegment in der offenen Welt.
2) Einführung in die Verwendung vonPrototyp-Clustering ist ein unbeaufsichtigter Lernalgorithmus, der zum Clustern von Stichproben in einem Datensatz in verschiedene Kategorien verwendet wird. Beim Prototypen-Clustering wird jede Kategorie durch einen oder mehrere Prototypen repräsentiert, die Beispiele im Datensatz sein oder nach bestimmten Regeln generiert werden können. Das Ziel der Prototypen-Clusterbildung besteht darin, eine Clusterbildung zu erreichen, indem der Abstand zwischen den Stichproben und den Prototypen der Kategorien, zu denen sie gehören, minimiert wird. Zu den gängigen Prototyp-Clustering-Algorithmen gehören K-Means-Clustering und Gaußsche Mischungsmodelle. Diese Algorithmen werden häufig in Bereichen wie Data Mining, Mustererkennung und Bildverarbeitung eingesetzt. Implementieren Sie TTT und erfahren Sie, wie Sie den Prototyp für Open-World-Testzeittraining erweitern können.
3) Einführung in die Verwendung von Zieldomänendaten fürDer Inhalt, der neu geschrieben werden muss, ist: dynamische Prototypenerweiterung.
4) Einführung vonDistribution Alignment mit Prototype Clustering ist ein unbeaufsichtigter Lernalgorithmus, der zum Clustern von Stichproben in einem Datensatz in verschiedene Kategorien verwendet wird. Beim Prototypen-Clustering wird jede Kategorie durch einen oder mehrere Prototypen repräsentiert, die Beispiele im Datensatz sein oder nach bestimmten Regeln generiert werden können. Das Ziel der Prototypen-Clusterbildung besteht darin, eine Clusterbildung zu erreichen, indem der Abstand zwischen den Stichproben und den Prototypen der Kategorien, zu denen sie gehören, minimiert wird. Zu den gängigen Prototyp-Clustering-Algorithmen gehören K-Means-Clustering und Gaußsche Mischungsmodelle. Diese Algorithmen, die in Bereichen wie Data Mining, Mustererkennung und Bildverarbeitung weit verbreitet sind, werden kombiniert, um ein leistungsstarkes Open-World-Testzeittraining zu ermöglichen.
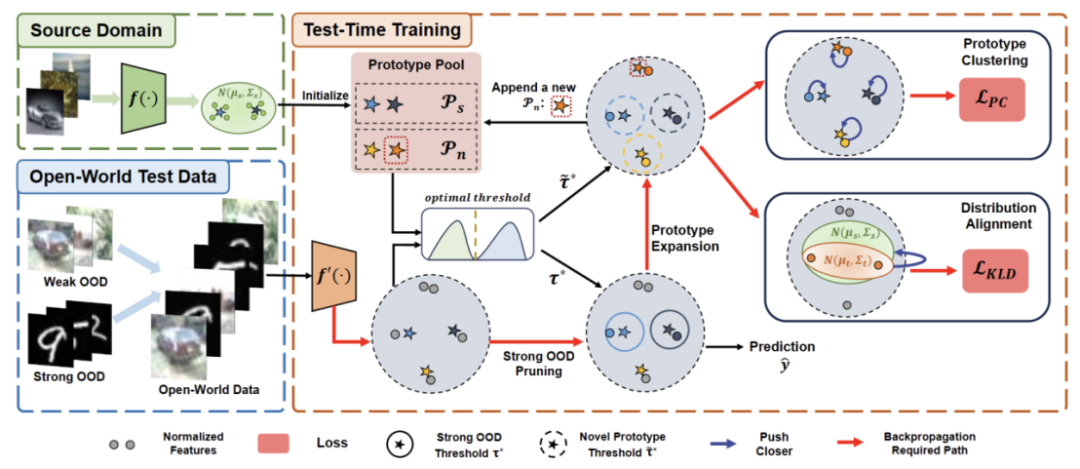
Der Inhalt, der neu geschrieben werden muss, ist: Abbildung 2: Methodenübersichtsdiagramm
Aufgabeneinstellung
Das Ziel von TTT besteht darin, das vorab trainierte Modell der Quelldomäne an die Zieldomäne anzupassen , wobei die Zieldomäne relativ sein kann. In der Quelldomäne findet eine Verteilungsmigration statt. Im standardmäßigen Closed-World-TTT sind die Beschriftungsräume der Quell- und Zieldomänen gleich. Im Open-World-TTT enthält der Beschriftungsraum der Zieldomäne jedoch den Zielraum der Quelldomäne, was bedeutet, dass die Zieldomäne über bisher unbekannte neue semantische Kategorien verfügtUm Verwechslungen zwischen TTT-Definitionen zu vermeiden, übernehmen wir TTAC [2] Das vorgeschlagene sTTT-Protokoll (Sequential Test Time Training) wird evaluiert. Im Rahmen des sTTT-Protokolls werden Testproben nacheinander getestet und Modellaktualisierungen nach Beobachtung kleiner Testprobenchargen durchgeführt. Die Vorhersage für jede Testprobe, die zum Zeitstempel t ankommt, wird nicht von jeder Testprobe beeinflusst, die zum Zeitpunkt t+k ankommt (deren k größer als 0 ist).Prototyp-Clustering ist ein unbeaufsichtigter Lernalgorithmus, der verwendet wird, um Stichproben in einem Datensatz in verschiedene Kategorien zu gruppieren. Beim Prototypen-Clustering wird jede Kategorie durch einen oder mehrere Prototypen repräsentiert, die Beispiele im Datensatz sein oder nach bestimmten Regeln generiert werden können. Das Ziel der Prototypen-Clusterbildung besteht darin, eine Clusterbildung zu erreichen, indem der Abstand zwischen den Stichproben und den Prototypen der Kategorien, zu denen sie gehören, minimiert wird. Zu den gängigen Prototyp-Clustering-Algorithmen gehören K-Means-Clustering und Gaußsche Mischungsmodelle. Diese Algorithmen werden häufig in Bereichen wie Data Mining, Mustererkennung und Bildverarbeitung eingesetzt.
Inspiriert durch die Arbeit mit Clustering in Domänenanpassungsaufgaben [3,4] behandeln wir das Testsegmenttraining als Entdeckung von Clustern in der Datenstruktur der Zieldomäne . Durch die Identifizierung repräsentativer Prototypen als Clusterzentren werden Clusterstrukturen in der Zieldomäne identifiziert und Testproben werden dazu ermutigt, in der Nähe eines der Prototypen einzubetten. Prototyp-Clustering ist ein unbeaufsichtigter Lernalgorithmus, mit dem Stichproben in einem Datensatz in verschiedene Kategorien gruppiert werden. Beim Prototypen-Clustering wird jede Kategorie durch einen oder mehrere Prototypen repräsentiert, die Beispiele im Datensatz sein oder nach bestimmten Regeln generiert werden können. Das Ziel der Prototypen-Clusterbildung besteht darin, eine Clusterbildung zu erreichen, indem der Abstand zwischen den Stichproben und den Prototypen der Kategorien, zu denen sie gehören, minimiert wird. Zu den gängigen Prototyp-Clustering-Algorithmen gehören K-Means-Clustering und Gaußsche Mischungsmodelle. Das Ziel dieser Algorithmen, die in Bereichen wie Data Mining, Mustererkennung und Bildverarbeitung weit verbreitet sind, besteht darin, den negativen Log-Likelihood-Verlust der Kosinusähnlichkeit zwischen der Stichprobe und dem Clusterzentrum zu minimieren, wie in gezeigt folgende Gleichung.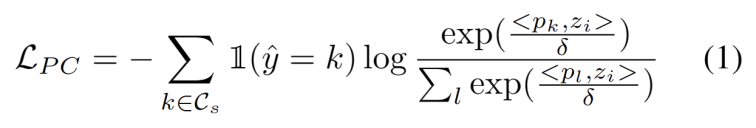
Abbildung 3 Der Gruppenwert ist in Doppelspitzen verteilt 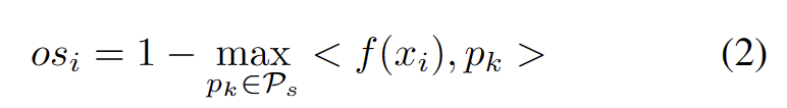
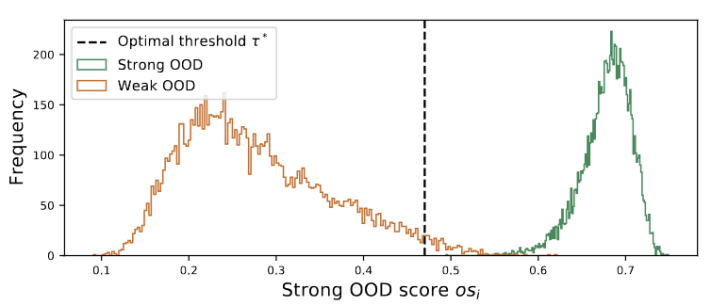
Was neu geschrieben werden muss, ist: Dynamische Prototypenerweiterung
Bei der Erweiterung des Pools starker OOD-Prototypen müssen sowohl die Quelldomäne als auch der starke OOD-Prototyp berücksichtigt werden, um das Testmuster zu bewerten. Um die Anzahl der Cluster anhand von Daten dynamisch abzuschätzen, wurden in früheren Studien ähnliche Probleme untersucht. Der deterministische Hard-Clustering-Algorithmus DP-means [5] wurde entwickelt, indem der Abstand von Datenpunkten zu bekannten Clusterzentren gemessen wurde. Ein neuer Cluster wird initialisiert, wenn der Abstand über einem Schwellenwert liegt. DP-means entspricht nachweislich der Optimierung des K-means-Ziels, allerdings mit einem zusätzlichen Nachteil bei der Anzahl der Cluster, was eine praktikable Lösung für die dynamische Prototypenerweiterung darstellt, bei der ein Umschreiben erforderlich ist.
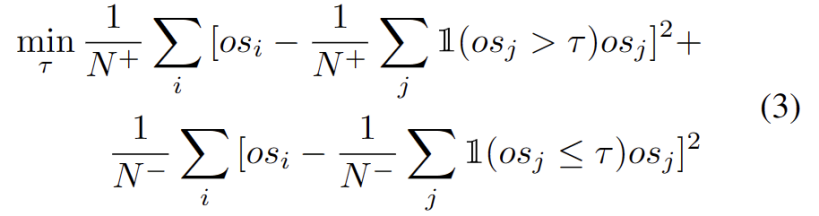
Mit anderen identifizierten starken OOD-Prototypen haben wir Prototypen zum Testen von Proben definiert. Clustering ist ein unbeaufsichtigter Lernalgorithmus, der verwendet wird, um Proben in einem Datensatz in verschiedene Kategorien zu gruppieren. Beim Prototypen-Clustering wird jede Kategorie durch einen oder mehrere Prototypen repräsentiert, die Beispiele im Datensatz sein oder nach bestimmten Regeln generiert werden können. Das Ziel des Prototyp-Clustering besteht darin, eine Clusterbildung zu erreichen, indem der Abstand zwischen Stichproben und den Prototypen der Kategorien, zu denen sie gehören, minimiert wird. Zu den gängigen Prototyp-Clustering-Algorithmen gehören K-Means-Clustering und Gaußsche Mischungsmodelle. Diese Algorithmen werden häufig in Bereichen wie Data Mining, Mustererkennung und Bildverarbeitung verwendet. Der Verlust berücksichtigt zwei Faktoren. Erstens sollten in bekannte Klassen klassifizierte Testmuster näher an Prototypen und weiter entfernt von anderen Prototypen eingebettet werden, was die K-Klassen-Klassifizierungsaufgabe definiert. Zweitens sollten Testproben, die als starke OOD-Prototypen klassifiziert sind, weit von Prototypen der Quelldomäne entfernt sein, was die K+1-Klassenklassifizierungsaufgabe definiert. Mit diesen Zielen vor Augen entwickeln wir einen Prototyp für Clustering, einen unbeaufsichtigten Lernalgorithmus, der zum Clustern von Stichproben in einem Datensatz in verschiedene Kategorien verwendet wird. Beim Prototypen-Clustering wird jede Kategorie durch einen oder mehrere Prototypen repräsentiert, die Beispiele im Datensatz sein oder nach bestimmten Regeln generiert werden können. Das Ziel der Prototypen-Clusterbildung besteht darin, eine Clusterbildung zu erreichen, indem der Abstand zwischen den Stichproben und den Prototypen der Kategorien, zu denen sie gehören, minimiert wird. Zu den gängigen Prototyp-Clustering-Algorithmen gehören K-Means-Clustering und Gaußsche Mischungsmodelle. Diese Algorithmen werden häufig in Bereichen wie Data Mining, Mustererkennung und Bildverarbeitung verwendet. Der Verlust wird wie folgt definiert.
Einschränkungen bei der Verteilungsausrichtung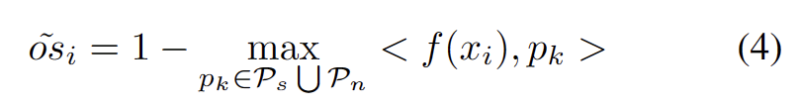
Es ist bekannt, dass Selbsttraining anfällig für fehlerhafte Pseudobezeichnungen ist. Die Situation wird noch schlimmer, wenn die Zieldomäne aus OOD-Proben besteht. Um das Risiko eines Ausfalls zu verringern, verwenden wir außerdem die Verteilungsausrichtung [1] wie folgt als Regularisierung für das Selbsttraining.
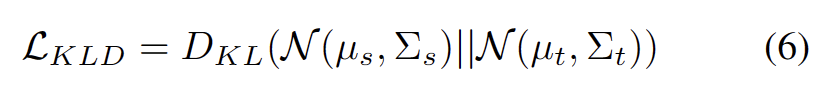


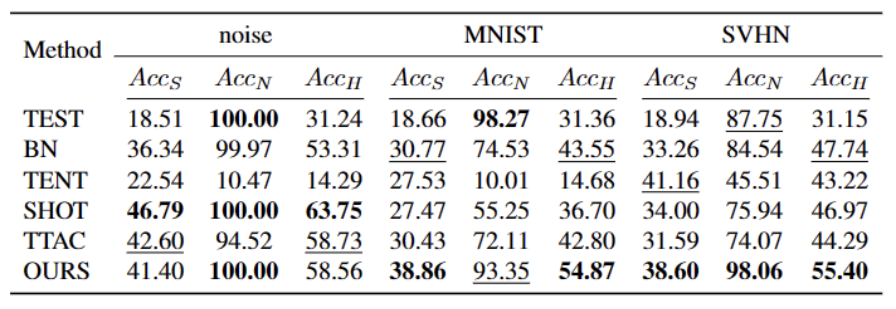
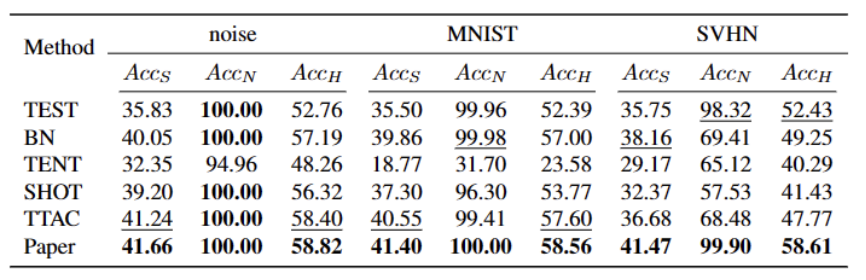 In diesem Artikel werden erstmals die Probleme und Einstellungen des Open World Test Segment Training (OWTTT) vorgestellt und darauf hingewiesen, dass diese vorhanden sind Methoden sind bei der Verarbeitung der enthaltenden und Quelldomänendaten von starken OOD-Proben mit semantischen Offsets oft auf Schwierigkeiten gestoßen, und es wird eine Selbsttrainingsmethode vorgeschlagen, die auf der Notwendigkeit basiert, den Inhalt neu zu schreiben, um die oben genannten Probleme zu lösen. Wir hoffen, dass diese Arbeit neue Wege für die nachfolgende TTT-Forschung zur Erforschung robusterer TTT-Methoden liefern kann.
In diesem Artikel werden erstmals die Probleme und Einstellungen des Open World Test Segment Training (OWTTT) vorgestellt und darauf hingewiesen, dass diese vorhanden sind Methoden sind bei der Verarbeitung der enthaltenden und Quelldomänendaten von starken OOD-Proben mit semantischen Offsets oft auf Schwierigkeiten gestoßen, und es wird eine Selbsttrainingsmethode vorgeschlagen, die auf der Notwendigkeit basiert, den Inhalt neu zu schreiben, um die oben genannten Probleme zu lösen. Wir hoffen, dass diese Arbeit neue Wege für die nachfolgende TTT-Forschung zur Erforschung robusterer TTT-Methoden liefern kann. 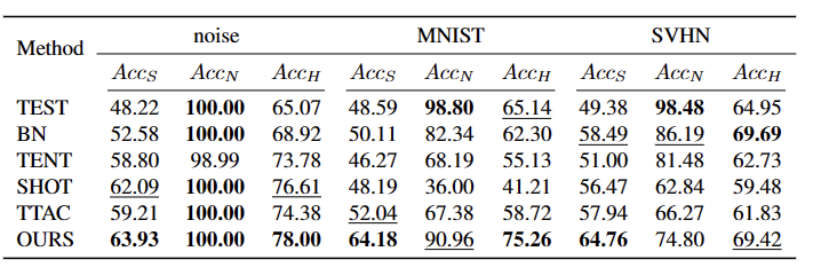
[5] Brian Kulis und Michael I Jordan. k-means revisited: ein neuer Algorithmus über Bayesianische nichtparametrische Methoden. In der Internationalen Konferenz über maschinelles Lernen, 2012
Das obige ist der detaillierte Inhalt vonICCV 2023 Oral |. Wie führt man ein Testsegment-Training in der offenen Welt durch? Selbsttrainingsmethode basierend auf dynamischer Prototypenerweiterung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Ist PHP schwer zu erlernen? Wie lange dauert es, PHP vom Einstieg bis zur Beherrschung zu erlernen?
- Eine Einführung in WeChat-Minispiele basierend auf WeChat-Entwicklungstools
- Welche Bücher sollte ich lesen, um Java von Grund auf zu lernen? Empfohlene fortgeschrittene Java-Bücher
- Welche Bücher sollte ich lesen, um mit Java zu beginnen?
- Erste Schritte mit PS: Wie man Bildern granulare Effekte hinzufügt (Skill-Sharing)