
Heim >Technologie-Peripheriegeräte >KI >Gartner veröffentlicht im Jahr 2023 Chinas Reifekurve für Datenanalyse und künstliche Intelligenz
Gartner veröffentlicht im Jahr 2023 Chinas Reifekurve für Datenanalyse und künstliche Intelligenz

- PHPznach vorne
- 2023-09-14 15:37:10689Durchsuche
Gartner prognostiziert, dass bis 2026 mehr als 30 % der Angestelltenjobs in China neu definiert werden und die Fähigkeiten zur Nutzung und Verwaltung generativer KI sehr beliebt sein werden.
Gartners China Data Analytics and AI Technology Hype Cycle 2023 enthüllt vier grundlegende Themen im Zusammenhang mit Chinas Daten, Analysen und KI: Chinas Datenstrategie, die Geschäftsergebnisse priorisiert, regionale Daten und Analysen sowie ein KI-Ökosystem, Daten, der Zusammenbruch von China und Taiwan und Künstliche Intelligenz wird zum neuen Symbol nationaler Macht.
In dieser Kurve stehen die meisten Technologien kurz vor dem Eintritt in eine Phase der erwarteten Expansion. Zhang Tong, leitender Forschungsdirektor bei Gartner, sagte: „Innovation wird oft als Lösung für traditionelle Engpässe angepriesen und soll häufige Probleme chinesischer CIOs lösen, wie etwa Hardware-Ressourcenknappheit, Skalierbarkeit, nachhaltige Abläufe, Minderung von Sicherheitsrisiken und technologische Probleme.“ Unabhängigkeit. Kontrolle und domänenübergreifende Anwendbarkeit von KI-Modellen, was zu einem klaren Geschäftswert führt. Endbenutzer schätzen jedoch greifbare Auswirkungen mehr als abstrakte strategische Konzepte Data Weaving ist ein Design-Framework zum Erhalten flexibler und wiederverwendbarer Datenpipelines, Dienste und Semantik, das Datenintegration, aktive Metadaten, Wissensgraphen, Datenprofilierung, maschinelles Lernen und Datenklassifizierung umfasst. Data Weaving untergräbt den bestehenden vorherrschenden Ansatz des Datenmanagements. Es ist nicht mehr „maßgeschneidert“ für Daten und Anwendungsfälle, sondern „zuerst Beobachtung und dann Nutzung“.
Zhang Tong, leitender Forschungsdirektor bei Gartner, sagte: „Das Aufkommen von Daten-, Analyse- und KI-Anwendungsfällen sowie sich schnell ändernde Datensicherheitsvorschriften haben zu einer Komplexität und Unsicherheit des Datenmanagements in China geführt. Datenweberei kann.“ Nutzen Sie versunkene Kosten voll aus und bieten Sie gleichzeitig Hinweise zur Priorisierung und Kostenkontrolle für neue Ausgaben für die Datenverwaltungsinfrastruktur zum Geschäftsablauf. Das Daten-Asset-Management gilt für eine Vielzahl von Datenformen – beispielsweise Bilder, Videos, Dateien, Materialien und Transaktionsdaten im System – und deckt den gesamten Datenlebenszyklus von der Datenerfassung bis zur Datenvernichtung ab Art und Weise als Vermögenswerte nutzen und daraus Wert schaffen. 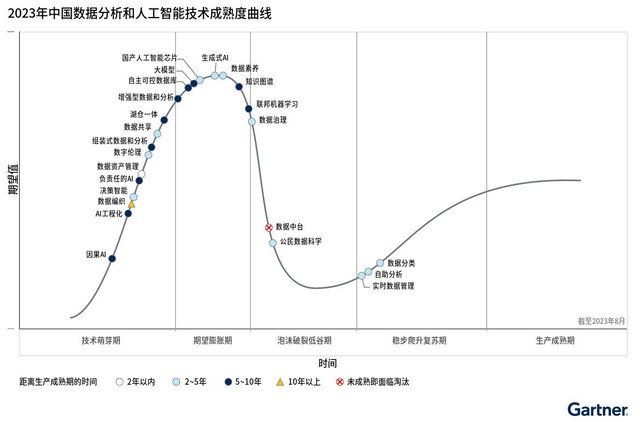
Als neuer Produktionsfaktor sind Daten zu einem Wettbewerbsvorteil für Unternehmen geworden. Daten sind schnell, vielfältig, umfangreich und sachlich, daher müssen Unternehmen Prozesse integrieren, um Dateneinblicke zu generieren.
Zhang Tong, Senior Research Director bei Gartner, sagte: „Datenbestände können nicht nur die Qualität von Abläufen und Entscheidungen verbessern, sondern auch mehr Geschäftswert schaffen. Sie können auch neue Geschäftsmodelle generieren und Daten zur direkten Monetarisierung nutzen.“ Obwohl sich die Wertschöpfung beschleunigt, bergen Unternehmensorganisationen immer noch potenzielle Risiken, um Verstöße gegen Vorschriften und versehentliche Datenlecks zu vermeiden. „Assembled Data and Analysis (D&A) nutzt Container.“ basierte oder geschäftliche Microservices, die vorhandene Assets zu flexiblen, modularen und benutzerfreundlichen Funktionen für Datenanalyse und künstliche Intelligenz (KI) zusammenfügen. Diese Technologie kann eine Reihe von Technologien nutzen, um Datenverwaltungs- und Analyseanwendungen in Datenanalyse- und KI-Komponenten oder andere Anwendungsmodule umzuwandeln, unterstützt durch Low-Code- und No-Code-Funktionen und unterstützt adaptive und intelligente Entscheidungsfindung. Angesichts des sich schnell verändernden Geschäftsumfelds müssen chinesische Unternehmen und Institutionen ihre Agilität verbessern und die Gewinnung von Erkenntnissen beschleunigen. Assembled D&A hilft Unternehmen dabei, modulare Daten- und Analysefunktionen zu nutzen, um mehrere Erkenntnisse und Referenzinformationen in verschiedene Maßnahmen zu integrieren und so eine fragmentierte Entwicklung zu vermeiden. Unternehmen können die Bereitstellungsflexibilität weiter verbessern, indem sie D&A-Funktionen zusammenstellen oder neu organisieren, um unterschiedliche Nutzungsszenarien zu bewältigen. Große ModelleGroße Modelle sind große Parametermodelle, die selbstüberwacht auf einer Vielzahl von Datensätzen trainiert werden, von denen die meisten auf der Transformer-Architektur oder der Diffusion Deep Neural Network-Architektur basieren und zu Multimodalität werden können. Der Name „Big Model“ rührt von seiner Bedeutung und breiten Eignung für eine Vielzahl nachgelagerter Nutzungsszenarien her. Diese Fähigkeit zur Anpassung an eine Vielzahl von Szenarien profitiert von einem ausreichenden und umfassenden Vortraining des Modells. Große Modelle sind mittlerweile zur bevorzugten Architektur für die Verarbeitung natürlicher Sprache geworden und werden in den Bereichen Computer Vision, Audio- und Videoverarbeitung, Softwareentwicklung, Chemie, Finanzen und Recht eingesetzt. Ein beliebtes Unterkonzept, das von großen Modellen abgeleitet wird, sind große Sprachmodelle, die auf Texttraining basieren. Zhang Tong, leitender Forschungsdirektor bei Gartner, sagte: „Große Modelle haben das Potenzial, verbesserte Effekte für Anwendungen in verschiedenen Anwendungsfällen natürlicher Sprache bereitzustellen und werden daher tiefgreifende Auswirkungen auf vertikale Branchen und Geschäftsfunktionen haben. Sie können die Mitarbeiter verbessern.“ Produktivität und ermöglichen Kundenerlebnisse. Automatisieren, erweitern und erstellen Sie neue Produkte und Dienstleistungen kosteneffektiv und beschleunigen Sie so die digitale Transformation.“Data Middle Office
Data Middle Office (DMO) ist eine Praxis für Organisationsstrategie und -technologie. Über das Rechenzentrum können Benutzer in verschiedenen Geschäftsbereichen Unternehmensdaten effizient nutzen, um Entscheidungen auf der Grundlage einer einzigen Informationsquelle zu treffen. Die Einrichtung eines Rechenzentrums kann eine Möglichkeit sein, zusammensetzbare und wiederverwendbare Daten- und Analysefunktionen für Unternehmen aufzubauen. Diese Funktionen können einzigartige digitale Abläufe bereitstellen und digitale Abläufe über die gesamte Wertschöpfungskette hinweg integrieren.
Der Grund, warum viele chinesische Unternehmen Data-Middle-End-Praktiken einführen, besteht darin, die technische Redundanz ihrer Daten- und Analysearchitektur zu reduzieren, Dateninseln verschiedener Systeme zu öffnen und wiederverwendbare Daten- und Analysefunktionen zu fördern. Allerdings hat das Rechenzentrum in vielen Fällen sein Versprechen hinsichtlich der zusammengestellten agilen D&A-Fähigkeiten nicht eingehalten, wodurch seine Position auf dem Markt geschwächt wurde. Viele Organisationen und Anbieter zögern, dieses Konzept intern zu übernehmen oder es einfach aus ihrer Werbung zu entfernen.
Das obige ist der detaillierte Inhalt vonGartner veröffentlicht im Jahr 2023 Chinas Reifekurve für Datenanalyse und künstliche Intelligenz. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was ist KI-Bildung mit künstlicher Intelligenz?
- Was sind die Hauptantriebskräfte für die Entwicklung künstlicher Intelligenz?
- Welche Anwendungen gibt es von künstlicher Intelligenz im Leben?
- Künstliche Intelligenz ist nach populärwissenschaftlicher Definition ein dem Menschen ähnliches Computerprogramm.
- Wie heißt Honors Assistent für künstliche Intelligenz?