
Heim >Technologie-Peripheriegeräte >KI >Implementieren Sie die Generierung von Suchverbesserungen basierend auf Langchain, ChromaDB und GPT 3.5
Implementieren Sie die Generierung von Suchverbesserungen basierend auf Langchain, ChromaDB und GPT 3.5

- 王林nach vorne
- 2023-09-14 14:21:111817Durchsuche
„Übersetzer“ | Generation)
Aufforderungen Engineering-Technologie und werden auf einer Kombination aus Langchain, ChromaDB und GPT 3.5
basieren, um diese Technologie zu implementieren.
MotivationMit dem Aufkommen transformatorbasierter Big-Data-Modelle wie GPT-3 hat der Bereich der Verarbeitung natürlicher Sprache (NLP) große Durchbrüche erzielt. Diese Sprachmodelle sind in der Lage, menschenähnlichen Text zu generieren und verfügen bereits über eine Vielzahl von Anwendungen wie Chatbots, Inhaltsgenerierung und Übersetzung usw. . Wenn es jedoch um betriebliche Anwendungsszenarien von Fach- und kundenspezifischen Informationen geht, können herkömmliche Sprachmodelle
die Anforderungen nicht erfüllen. Andererseits die Feinabstimmung dieser Modelle mithilfe neuer Korpora kann teuer und zeitaufwändig sein. Um dieser Herausforderung zu begegnen, können wir eine Technik namens Retrieval Augmented Generation (RAG: Retrieval Augmented Generation) verwenden. In diesem Blog werden wir untersuchen, wie diese Retrieval Enhanced Generation (RAG) -Technologie funktioniert. und bestehen Sie ein Real-Life
Anhand vonKampfbeispielen wird 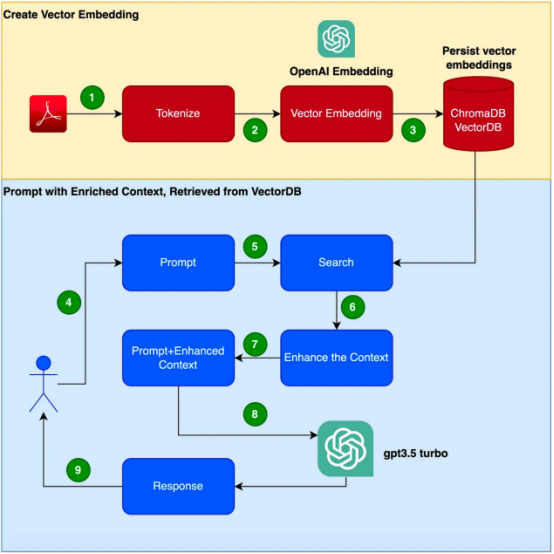
Wirksamkeit dieser Technologie nachgewiesen. Es ist zu beachten, dass in diesem Beispiel GPT-3.5 Turbo als zusätzlicher Korpus verwendet wird, um auf das Produkthandbuch zu reagieren. Stellen Sie sich vor, Sie haben die Aufgabe, einen Chatbot zu entwickeln, der auf Fragen zu einem bestimmten Produkt antworten kann. Das Produkt verfügt über ein eigenes, einzigartiges Benutzerhandbuch, speziell für Unternehmensprodukte. Herkömmliche Sprachmodelle wie GPT-3 werden häufig anhand allgemeiner Daten trainiert und verstehen dieses spezifische Produkt möglicherweise nicht. Andererseits scheint die Feinabstimmung des Modells mithilfe eines neuen Korpus eine Lösung zu sein ; dieser Ansatz wird jedoch erhebliche Kosten- und Ressourcenanforderungen mit sich bringen. Einführung in Retrieval Augmented Generation (RAG) Retrieval Augmented Generation (RAG) bietet eine effizientere Möglichkeit, das Problem der Generierung geeigneter kontextbezogener Antworten in einer bestimmten Domäne zu lösen. Anstatt ein neues Korpus zur Feinabstimmung des gesamten Sprachmodells zu verwenden, nutzt RAG die Fähigkeit des Abrufs, um bei Bedarf auf relevante Informationen zuzugreifen. Durch die Kombination von Abrufmechanismen mit Sprachmodellen nutzt RAG den externen Kontext, um die Antworten zu verbessern. Dieser externe Kontext kann als Vektoreinbettung bereitgestellt werden
Die folgenden Schritte werden zum Erstellen der Anwendung in diesem Artikel beschrieben. das Focusrite Clarett-Benutzerhandbuch als zusätzlichen Korpus verwenden werden. Focusrite Clarett ist ein einfaches USB-Audio-Interface zum Aufnehmen und Abspielen von Audio. Sie können es über den -Link https://fael-downloads-prod.focusrite.com/customer/prod/downloads/Clarett%208Pre%20USB%20User%20Guide%20V2%20English%20-%20EN.pdf herunterladen Benutzerhandbuch. 🔜 das kann im System vorkommen Versions-/Bibliotheks-/Abhängigkeitskonflikt. Jetzt führen wir den folgenden Befehl aus neue virtuelle Python-Umgebung zu erstellen :
Es ist zu beachten, dass wir in diesem Beispiel , um
eine
pip install virtualenvpython3 -m venv ./venvsource venv/bin/activate
OpenAI-Schlüssel erstellen Als nächstes benötigen wir eine OpenAI Schlüssel für den Zugriff auf GPT. Lassen Sie uns einen OpenAI-Schlüssel erstellen. Sie können kostenlos einen OpenAIKey erstellen, indem Sie sich unter Link https://platform.openai.com/apps für OpenAI registrieren. Melden Sie sich nach der Registrierung an und wählen Sie die API-Option aus, wie im Screenshot gezeigt (Aus zeitlichen Gründen kann es sein, dass das Bildschirmdesign beim Öffnen dieses nicht mit mir übereinstimmt Derzeit
Machen Sie Screenshots
mit Änderungen).
Gehen Sie dann zu Ihren Kontoeinstellungen und wählen Sie „API-Schlüssel anzeigen“: Dann wählen Sie „Neuen Schlüssel erstellen“ (Erstellen neuer geheimer Schlüssel )“ wird ein Popup-Fenster wie unten gezeigt angezeigt. Sie müssen einen Namen angeben und dadurch wird ein Schlüssel generiert.

Diese Aktion generiert einen eindeutigen Schlüssel, den Sie in Ihre Zwischenablage kopieren und an einem sicheren Ort
aufbewahren sollten 
Als nächstes schreiben wir Python-Code, um alle im obigen Flussdiagramm gezeigten Schritte zu implementieren. Abhängigkeitsbibliotheken installierenZunächst
installieren wir die verschiedenen Abhängigkeiten, die wir benötigen. Wir werden die folgenden Bibliotheken verwenden: 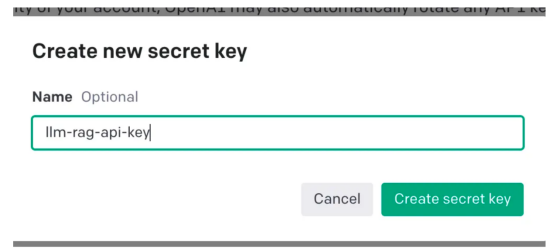
一旦成功安装了这些依赖项,请创建一个环境变量来存储在最后一步中创建的OpenAI密钥。 接下来,让我们开始编程。 在下面的代码中,我们会引入所有需要使用的依赖库和函数 在下面的代码中,阅读PDF,将文档标记化并拆分为标记。 在下面的代码中,我们将创建一个色度集合,一个用于存储色度数据库的本地目录。然后,我们创建一个向量嵌入并将其存储在ChromaDB数据库中。 执行此代码后,您应该会看到创建了一个存储向量嵌入的文件夹。 现在,我们将向量嵌入存储在ChromaDB中。下面,让我们使用LangChain中的ConversationalRetrievalChain API来启动聊天历史记录组件。我们将传递由GPT 3.5 Turbo启动的OpenAI对象和我们创建的VectorDB。我们将传递ConversationBufferMemory,它用于存储消息。 既然我们已经初始化了会话检索链,那么接下来我们就可以使用它进行聊天/问答了。在下面的代码中,我们接受用户输入(问题),直到用户键入“done”。然后,我们将问题传递给LLM以获得回复并打印出来。 这是输出的屏幕截图。 正如你从本文中所看到的,检索增强生成是一项伟大的技术,它将GPT-3等语言模型的优势与信息检索的能力相结合。通过使用特定于上下文的信息丰富输入,检索增强生成使语言模型能够生成更准确和与上下文相关的响应。在微调可能不实用的企业应用场景中,检索增强生成提供了一种高效、经济高效的解决方案,可以与用户进行量身定制、知情的交互。 朱先忠是51CTO社区的编辑,也是51CTO专家博客和讲师。他还是潍坊一所高校的计算机教师,是自由编程界的老兵 原文标题:Prompt Engineering: Retrieval Augmented Generation(RAG),作者:A B Vijay Kumar
pip install langchainpip install unstructuredpip install pypdfpip install tiktokenpip install chromadbpip install openai
export OPENAI_API_KEY=<openai-key></openai-key>
从用户手册PDF创建向量嵌入并将其存储在ChromaDB中
import osimport openaiimport tiktokenimport chromadbfrom langchain.document_loaders import OnlinePDFLoader, UnstructuredPDFLoader, PyPDFLoaderfrom langchain.text_splitter import TokenTextSplitterfrom langchain.memory import ConversationBufferMemoryfrom langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import Chromafrom langchain.llms import OpenAIfrom langchain.chains import ConversationalRetrievalChain
loader = PyPDFLoader("Clarett.pdf")pdfData = loader.load()text_splitter = TokenTextSplitter(chunk_size=1000, chunk_overlap=0)splitData = text_splitter.split_documents(pdfData)
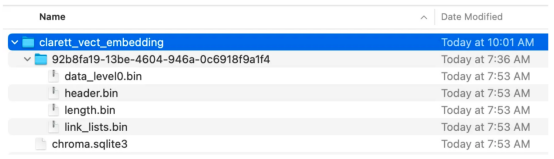
collection_name = "clarett_collection"local_directory = "clarett_vect_embedding"persist_directory = os.path.join(os.getcwd(), local_directory)openai_key=os.environ.get('OPENAI_API_KEY')embeddings = OpenAIEmbeddings(openai_api_key=openai_key)vectDB = Chroma.from_documents(splitData, embeddings, collection_name=collection_name, persist_directory=persist_directory )vectDB.persist()
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)chatQA = ConversationalRetrievalChain.from_llm( OpenAI(openai_api_key=openai_key, temperature=0, model_name="gpt-3.5-turbo"), vectDB.as_retriever(), memory=memory)
chat_history = []qry = ""while qry != 'done': qry = input('Question: ') if qry != exit: response = chatQA({"question": qry, "chat_history": chat_history}) print(response["answer"])

小结
译者介绍
Das obige ist der detaillierte Inhalt vonImplementieren Sie die Generierung von Suchverbesserungen basierend auf Langchain, ChromaDB und GPT 3.5. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Welche Wissenschaft ist die Verarbeitung natürlicher Sprache?
- Wie verwende ich die Go-Sprache für die Entwicklung der Verarbeitung natürlicher Sprache?
- Verwenden Sie die Python-Programmierung, um das Andocken der Baidu-Schnittstelle für die Verarbeitung natürlicher Sprache zu implementieren, um Sie bei der Entwicklung intelligenter Verarbeitungsprogramme zu unterstützen
- Techniken zur Verarbeitung natürlicher Sprache in C++
- Wie erfolgt die Mensch-Computer-Interaktion und die Verarbeitung natürlicher Sprache in C++?