
Heim >Technologie-Peripheriegeräte >KI >Implementierung von OpenAI CLIP für benutzerdefinierte Datensätze
Implementierung von OpenAI CLIP für benutzerdefinierte Datensätze

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-09-14 11:57:04882Durchsuche
Im Januar 2021 kündigte OpenAI zwei neue Modelle an: DALL-E und CLIP. Bei beiden Modellen handelt es sich um multimodale Modelle, die Text und Bilder auf irgendeine Weise verbinden. Der vollständige Name von CLIP lautet Contrastive Language-Image Pre-training (Contrastive Language-Image Pre-training), eine Vortrainingsmethode, die auf kontrastierenden Text-Bild-Paaren basiert. Warum CLIP einführen? Denn die derzeit beliebte Stable Diffusion ist kein einzelnes Modell, sondern besteht aus mehreren Modellen. Eine der Schlüsselkomponenten ist der Text-Encoder, der zum Codieren der Texteingabe des Benutzers verwendet wird. Dieser Text-Encoder ist der Text-Encoder im CLIP-Modell
Wenn das CLIP-Modell trainiert ist, können Sie ihm einen Eingabesatz geben und extrahieren Sie die relevantesten Bilder dazu. CLIP lernt die Beziehung zwischen einem vollständigen Satz und dem Bild, das er beschreibt. Das heißt, es wird auf vollständige Sätze trainiert und nicht auf einzelne Kategorien wie „Auto“, „Hund“ usw. Dies ist für die Anwendung von entscheidender Bedeutung. Wenn das Modell anhand vollständiger Phrasen trainiert wird, kann es mehr lernen und Muster zwischen Fotos und Text erkennen. Sie zeigten auch, dass das Modell als Klassifikator funktioniert, wenn es mit einem umfangreichen Datensatz aus Fotos und entsprechenden Sätzen trainiert wird. Als CLIP veröffentlicht wurde, übertraf seine Klassifizierungsleistung im ImageNet-Datensatz nach der Feinabstimmung ohne Feinabstimmung (Zero-Shot) die von ResNets-50, was bedeutet, dass es sehr nützlich ist.
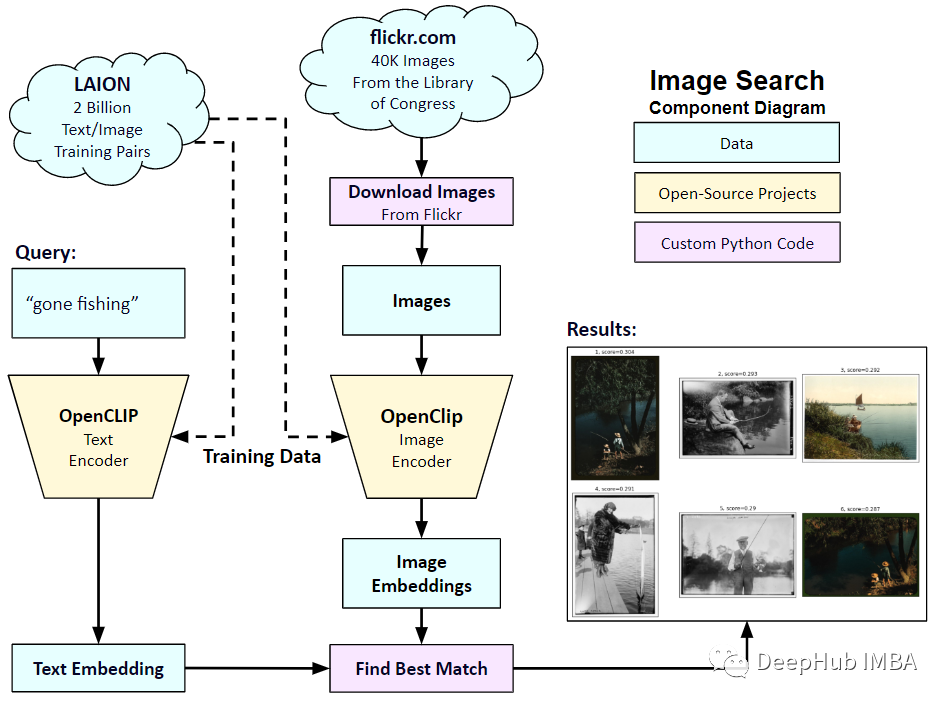
In diesem Artikel werden wir also PyTorch verwenden, um das CLIP-Modell von Grund auf zu implementieren, damit wir CLIP besser verstehen können
Sie müssen hier zwei Bibliotheken verwenden: timm und Transformers, Let's Importieren Sie zuerst den Code
import os import cv2 import gc import numpy as np import pandas as pd import itertools from tqdm.autonotebook import tqdm import albumentations as A import matplotlib.pyplot as plt import torch from torch import nn import torch.nn.functional as F import timm from transformers import DistilBertModel, DistilBertConfig, DistilBertTokenizer
Der nächste Schritt besteht darin, die Daten und die allgemeine Konfigurationskonfiguration vorzuverarbeiten. config ist eine gewöhnliche Python-Datei, in die wir alle Hyperparameter einfügen. Bei Verwendung von Jupyter Notebook handelt es sich um eine Klasse, die am Anfang von Notebook definiert wird.
class CFG:debug = Falseimage_path = "../input/flickr-image-dataset/flickr30k_images/flickr30k_images"captions_path = "."batch_size = 32num_workers = 4head_lr = 1e-3image_encoder_lr = 1e-4text_encoder_lr = 1e-5weight_decay = 1e-3patience = 1factor = 0.8epochs = 2device = torch.device("cuda" if torch.cuda.is_available() else "cpu") model_name = 'resnet50'image_embedding = 2048text_encoder_model = "distilbert-base-uncased"text_embedding = 768text_tokenizer = "distilbert-base-uncased"max_length = 200 pretrained = True # for both image encoder and text encodertrainable = True # for both image encoder and text encodertemperature = 1.0 # image sizesize = 224 # for projection head; used for both image and text encodersnum_projection_layers = 1projection_dim = 256 dropout = 0.1
Es gibt auch einige Hilfsklassen für unsere benutzerdefinierten Indikatoren
class AvgMeter:def __init__(self, name="Metric"):self.name = nameself.reset() def reset(self):self.avg, self.sum, self.count = [0] * 3 def update(self, val, count=1):self.count += countself.sum += val * countself.avg = self.sum / self.count def __repr__(self):text = f"{self.name}: {self.avg:.4f}"return text def get_lr(optimizer):for param_group in optimizer.param_groups:return param_group["lr"]
Unser Ziel ist es, Bilder und Sätze zu beschreiben. Der Datensatz muss also sowohl Sätze als auch Bilder zurückgeben. Sie müssen also den DistilBERT-Tagger verwenden, um den Satz (Titel) zu markieren, und dann DistilBERT die Tag-ID (input_ids) und die Aufmerksamkeitsmaske bereitstellen. DistilBERT ist kleiner als das BERT-Modell, aber die Ergebnisse der Modelle sind ähnlich, daher haben wir uns für die Verwendung entschieden.
Der nächste Schritt ist die Tokenisierung mit dem HuggingFace-Tokenizer. Das in __init__ erhaltene Tokenizer-Objekt wird geladen, wenn das Modell ausgeführt wird. Der Titel wird aufgefüllt und auf eine vorgegebene maximale Länge gekürzt. Bevor wir das relevante Bild laden, laden wir eine codierte Beschriftung in __getitem__, einem Wörterbuch mit den Schlüsseln input_ids und Attention_mask, und transformieren und erweitern sie (falls vorhanden). Verwandeln Sie es dann in einen Tensor und speichern Sie ihn in einem Wörterbuch mit „image“ als Schlüssel. Abschließend tragen wir den Originaltext des Titels zusammen mit dem Schlüsselwort „Titel“ in das Wörterbuch ein.
class CLIPDataset(torch.utils.data.Dataset):def __init__(self, image_filenames, captions, tokenizer, transforms):"""image_filenames and cpations must have the same length; so, if there aremultiple captions for each image, the image_filenames must have repetitivefile names """ self.image_filenames = image_filenamesself.captions = list(captions)self.encoded_captions = tokenizer(list(captions), padding=True, truncatinotallow=True, max_length=CFG.max_length)self.transforms = transforms def __getitem__(self, idx):item = {key: torch.tensor(values[idx])for key, values in self.encoded_captions.items()} image = cv2.imread(f"{CFG.image_path}/{self.image_filenames[idx]}")image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)image = self.transforms(image=image)['image']item['image'] = torch.tensor(image).permute(2, 0, 1).float()item['caption'] = self.captions[idx] return item def __len__(self):return len(self.captions) def get_transforms(mode="train"):if mode == "train":return A.Compose([A.Resize(CFG.size, CFG.size, always_apply=True),A.Normalize(max_pixel_value=255.0, always_apply=True),])else:return A.Compose([A.Resize(CFG.size, CFG.size, always_apply=True),A.Normalize(max_pixel_value=255.0, always_apply=True),])
Bild- und Text-Encoder: Wir werden ResNet50 als Bild-Encoder verwenden.
class ImageEncoder(nn.Module):"""Encode images to a fixed size vector""" def __init__(self, model_name=CFG.model_name, pretrained=CFG.pretrained, trainable=CFG.trainable):super().__init__()self.model = timm.create_model(model_name, pretrained, num_classes=0, global_pool="avg")for p in self.model.parameters():p.requires_grad = trainable def forward(self, x):return self.model(x)
Verwenden Sie DistilBERT als Textencoder. Verwenden Sie die endgültige Darstellung des CLS-Tokens, um die gesamte Darstellung des Satzes zu erhalten.
class TextEncoder(nn.Module):def __init__(self, model_name=CFG.text_encoder_model, pretrained=CFG.pretrained, trainable=CFG.trainable):super().__init__()if pretrained:self.model = DistilBertModel.from_pretrained(model_name)else:self.model = DistilBertModel(cnotallow=DistilBertConfig()) for p in self.model.parameters():p.requires_grad = trainable # we are using the CLS token hidden representation as the sentence's embeddingself.target_token_idx = 0 def forward(self, input_ids, attention_mask):output = self.model(input_ids=input_ids, attention_mask=attention_mask)last_hidden_state = output.last_hidden_statereturn last_hidden_state[:, self.target_token_idx, :]
Der obige Code hat das Bild und den Text in Vektoren fester Größe codiert (Bild 2048, Text 768). Wir benötigen, dass Bild und Text ähnliche Abmessungen haben, um sie vergleichen zu können, also setzen wir die Dimension 2048 und 768 Dimensionsvektoren Projiziert auf 256 Dimensionen (projection_dim), können wir sie nur vergleichen, wenn die Dimensionen gleich sind.
class ProjectionHead(nn.Module):def __init__(self,embedding_dim,projection_dim=CFG.projection_dim,dropout=CFG.dropout):super().__init__()self.projection = nn.Linear(embedding_dim, projection_dim)self.gelu = nn.GELU()self.fc = nn.Linear(projection_dim, projection_dim)self.dropout = nn.Dropout(dropout)self.layer_norm = nn.LayerNorm(projection_dim) def forward(self, x):projected = self.projection(x)x = self.gelu(projected)x = self.fc(x)x = self.dropout(x)x = x + projectedx = self.layer_norm(x)return x
Unser endgültiges CLIP-Modell sieht also so aus:
class CLIPModel(nn.Module):def __init__(self,temperature=CFG.temperature,image_embedding=CFG.image_embedding,text_embedding=CFG.text_embedding,):super().__init__()self.image_encoder = ImageEncoder()self.text_encoder = TextEncoder()self.image_projection = ProjectionHead(embedding_dim=image_embedding)self.text_projection = ProjectionHead(embedding_dim=text_embedding)self.temperature = temperature def forward(self, batch):# Getting Image and Text Featuresimage_features = self.image_encoder(batch["image"])text_features = self.text_encoder(input_ids=batch["input_ids"], attention_mask=batch["attention_mask"])# Getting Image and Text Embeddings (with same dimension)image_embeddings = self.image_projection(image_features)text_embeddings = self.text_projection(text_features) # Calculating the Losslogits = (text_embeddings @ image_embeddings.T) / self.temperatureimages_similarity = image_embeddings @ image_embeddings.Ttexts_similarity = text_embeddings @ text_embeddings.Ttargets = F.softmax((images_similarity + texts_similarity) / 2 * self.temperature, dim=-1)texts_loss = cross_entropy(logits, targets, reductinotallow='none')images_loss = cross_entropy(logits.T, targets.T, reductinotallow='none')loss = (images_loss + texts_loss) / 2.0 # shape: (batch_size)return loss.mean() #这里还加了一个交叉熵函数 def cross_entropy(preds, targets, reductinotallow='none'):log_softmax = nn.LogSoftmax(dim=-1)loss = (-targets * log_softmax(preds)).sum(1)if reduction == "none":return losselif reduction == "mean":return loss.mean()
Hier muss erklärt werden, dass CLIP symmetrische Kreuzentropie als Verlustfunktion verwendet, was den Einfluss von Rauschen reduzieren und die Robustheit des Modells verbessern kann Der Einfachheit halber verwenden wir einfach die Kreuzentropie.
Wir können Folgendes testen:
# A simple Example batch_size = 4 dim = 256 embeddings = torch.randn(batch_size, dim) out = embeddings @ embeddings.T print(F.softmax(out, dim=-1))
Der nächste Schritt ist das Training. Es gibt einige Funktionen, die uns beim Laden des Trainings- und Verifizierungsdatenladers helfen können Das ist alles
def make_train_valid_dfs():dataframe = pd.read_csv(f"{CFG.captions_path}/captions.csv")max_id = dataframe["id"].max() + 1 if not CFG.debug else 100image_ids = np.arange(0, max_id)np.random.seed(42)valid_ids = np.random.choice(image_ids, size=int(0.2 * len(image_ids)), replace=False)train_ids = [id_ for id_ in image_ids if id_ not in valid_ids]train_dataframe = dataframe[dataframe["id"].isin(train_ids)].reset_index(drop=True)valid_dataframe = dataframe[dataframe["id"].isin(valid_ids)].reset_index(drop=True)return train_dataframe, valid_dataframe def build_loaders(dataframe, tokenizer, mode):transforms = get_transforms(mode=mode)dataset = CLIPDataset(dataframe["image"].values,dataframe["caption"].values,tokenizer=tokenizer,transforms=transforms,)dataloader = torch.utils.data.DataLoader(dataset,batch_size=CFG.batch_size,num_workers=CFG.num_workers,shuffle=True if mode == "train" else False,)return dataloader
App: Bilder einbetten und Übereinstimmungen finden.
Wie kann man es nach Abschluss der Schulung in der Praxis anwenden? Wir müssen eine Funktion schreiben, die das trainierte Modell lädt, es mit Bildern aus dem Validierungssatz versorgt und die Form (valid_set_size, 256) und die image_embeddings des Modells selbst zurückgibt. Die Aufrufmethode von
def train_epoch(model, train_loader, optimizer, lr_scheduler, step):loss_meter = AvgMeter()tqdm_object = tqdm(train_loader, total=len(train_loader))for batch in tqdm_object:batch = {k: v.to(CFG.device) for k, v in batch.items() if k != "caption"}loss = model(batch)optimizer.zero_grad()loss.backward()optimizer.step()if step == "batch":lr_scheduler.step() count = batch["image"].size(0)loss_meter.update(loss.item(), count) tqdm_object.set_postfix(train_loss=loss_meter.avg, lr=get_lr(optimizer))return loss_meter def valid_epoch(model, valid_loader):loss_meter = AvgMeter() tqdm_object = tqdm(valid_loader, total=len(valid_loader))for batch in tqdm_object:batch = {k: v.to(CFG.device) for k, v in batch.items() if k != "caption"}loss = model(batch) count = batch["image"].size(0)loss_meter.update(loss.item(), count) tqdm_object.set_postfix(valid_loss=loss_meter.avg)return loss_meter
lautet wie folgt:
def main():train_df, valid_df = make_train_valid_dfs()tokenizer = DistilBertTokenizer.from_pretrained(CFG.text_tokenizer)train_loader = build_loaders(train_df, tokenizer, mode="train")valid_loader = build_loaders(valid_df, tokenizer, mode="valid") model = CLIPModel().to(CFG.device)params = [{"params": model.image_encoder.parameters(), "lr": CFG.image_encoder_lr},{"params": model.text_encoder.parameters(), "lr": CFG.text_encoder_lr},{"params": itertools.chain(model.image_projection.parameters(), model.text_projection.parameters()), "lr": CFG.head_lr, "weight_decay": CFG.weight_decay}]optimizer = torch.optim.AdamW(params, weight_decay=0.)lr_scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode="min", patience=CFG.patience, factor=CFG.factor)step = "epoch" best_loss = float('inf')for epoch in range(CFG.epochs):print(f"Epoch: {epoch + 1}")model.train()train_loss = train_epoch(model, train_loader, optimizer, lr_scheduler, step)model.eval()with torch.no_grad():valid_loss = valid_epoch(model, valid_loader) if valid_loss.avg <p><span></span></p><p> Wir können sehen, dass der Effekt unserer Anpassung gut ist (aber auf dem Bild ist eine Katze, haha). Mit anderen Worten: Die CLIP-Methode kann auch an kleine Datensätze angepasst werden<span></span></p><p style="text-align:center;">Das Folgende ist der Code und Datensatz dieses Artikels:<img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/887/227/169466383022304.png" class="lazy" alt="在自定义数据集上实现OpenAI CLIP"></p><p>https://www.kaggle.com/code/jyotidabas/simple -openai-clip-implementierung<span></span></p>Das obige ist der detaillierte Inhalt vonImplementierung von OpenAI CLIP für benutzerdefinierte Datensätze. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Google hat den LLM-Kampf verloren! Immer mehr Spitzenforscher wechseln den Job bei OpenAI
- Endlich ist es soweit: OpenAI öffnet offiziell die ChatGPT-API
- Unkonventionelle Aufteilungstechniken für Zeitreihen-Datensätze für maschinelles Lernen
- OpenAI bringt die erste generative künstliche Intelligenz-Mobilanwendung ChatGPT auf den Markt und eröffnet damit eine neue Ära der intelligenten Kommunikation